
Tujuan
Gunakan Dataproc Hub untuk membuat lingkungan notebook JupyterLab satu pengguna yang berjalan di cluster Managed Service for Apache Spark.
Buat notebook dan jalankan tugas Spark di cluster Managed Service for Apache Spark.
Hapus cluster Anda dan pertahankan notebook Anda di Cloud Storage.
Sebelum memulai
- Administrator harus memberi Anda izin
notebooks.instances.use(lihat Menetapkan peran Identity and Access Management (IAM)).
Membuat cluster JupyterLab Dataproc dari Dataproc Hub
Pilih tab User-Managed Notebooks di halaman Dataproc→Workbench di konsol Google Cloud .
Klik Open JupyterLab di baris yang mencantumkan instance Dataproc Hub yang dibuat oleh administrator.
- Jika Anda tidak memiliki akses ke konsol Google Cloud , masukkan URL instance Dataproc Hub yang dibagikan administrator kepada Anda di browser web.
Di halaman Jupyterhub→Dataproc Options, pilih konfigurasi cluster dan zona. Jika diaktifkan, tentukan penyesuaian, lalu klik Buat.
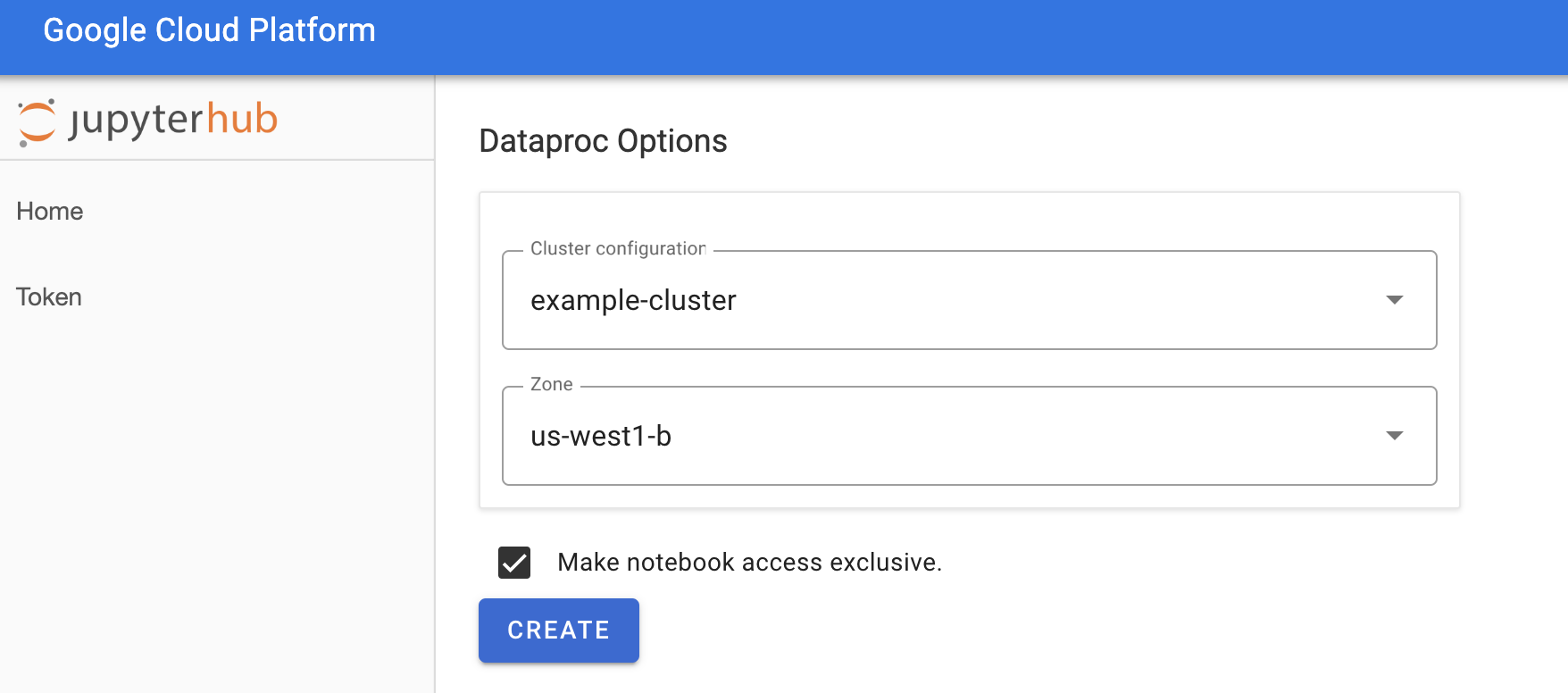
Setelah cluster Managed Service for Apache Spark dibuat, Anda akan dialihkan ke antarmuka JupyterLab yang berjalan di cluster.
Membuat notebook dan menjalankan tugas Spark
Di panel kiri antarmuka JupyterLab, klik
GCS(Cloud Storage).Buat notebook PySpark dari peluncur JupyterLab.
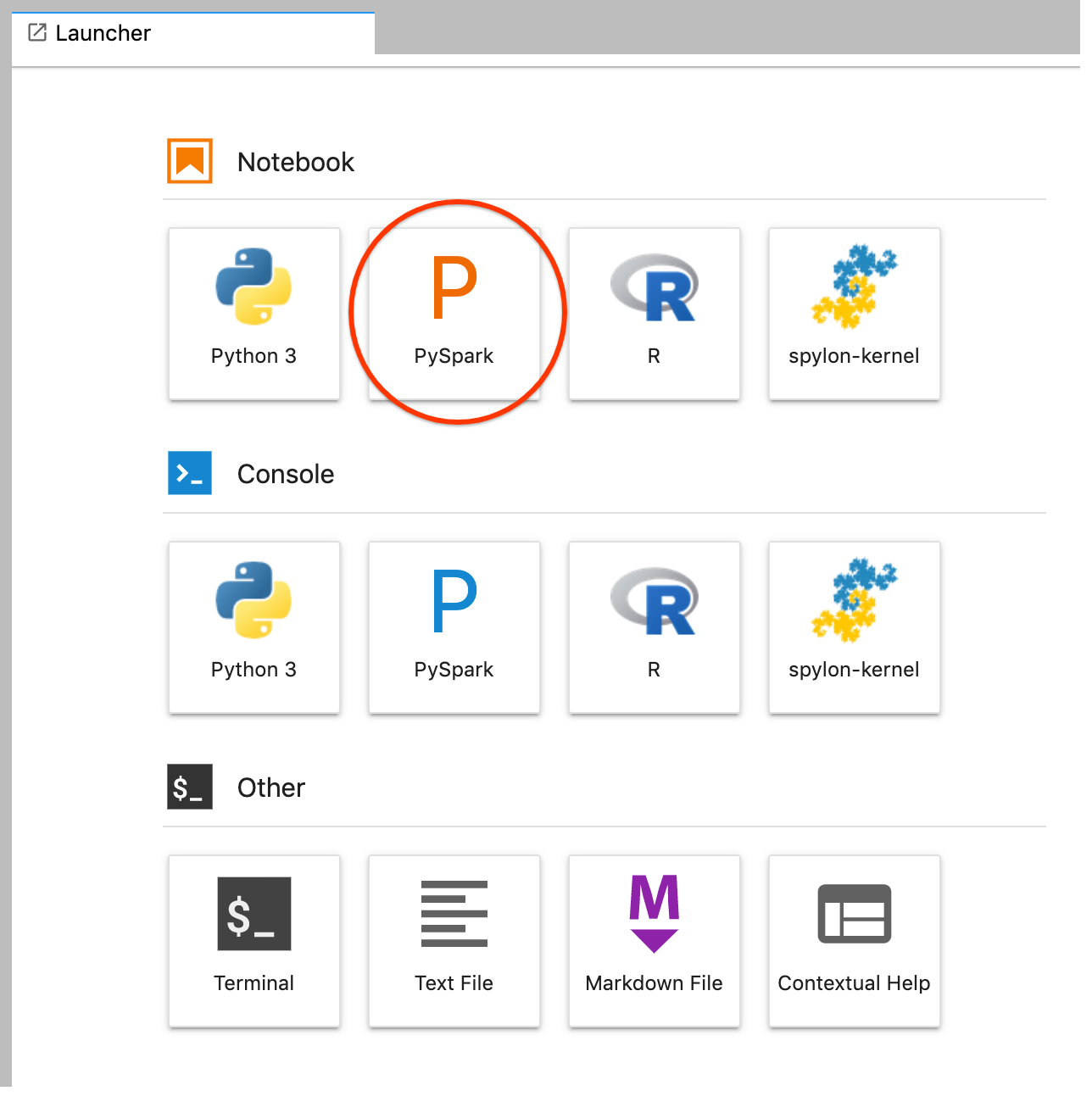
Kernel PySpark menginisialisasi SparkContext (menggunakan variabel
sc). Anda dapat memeriksa SparkContext dan menjalankan tugas Spark dari notebook.rdd = (sc.parallelize(['lorem', 'ipsum', 'dolor', 'sit', 'amet', 'lorem']) .map(lambda word: (word, 1)) .reduceByKey(lambda a, b: a + b)) print(rdd.collect())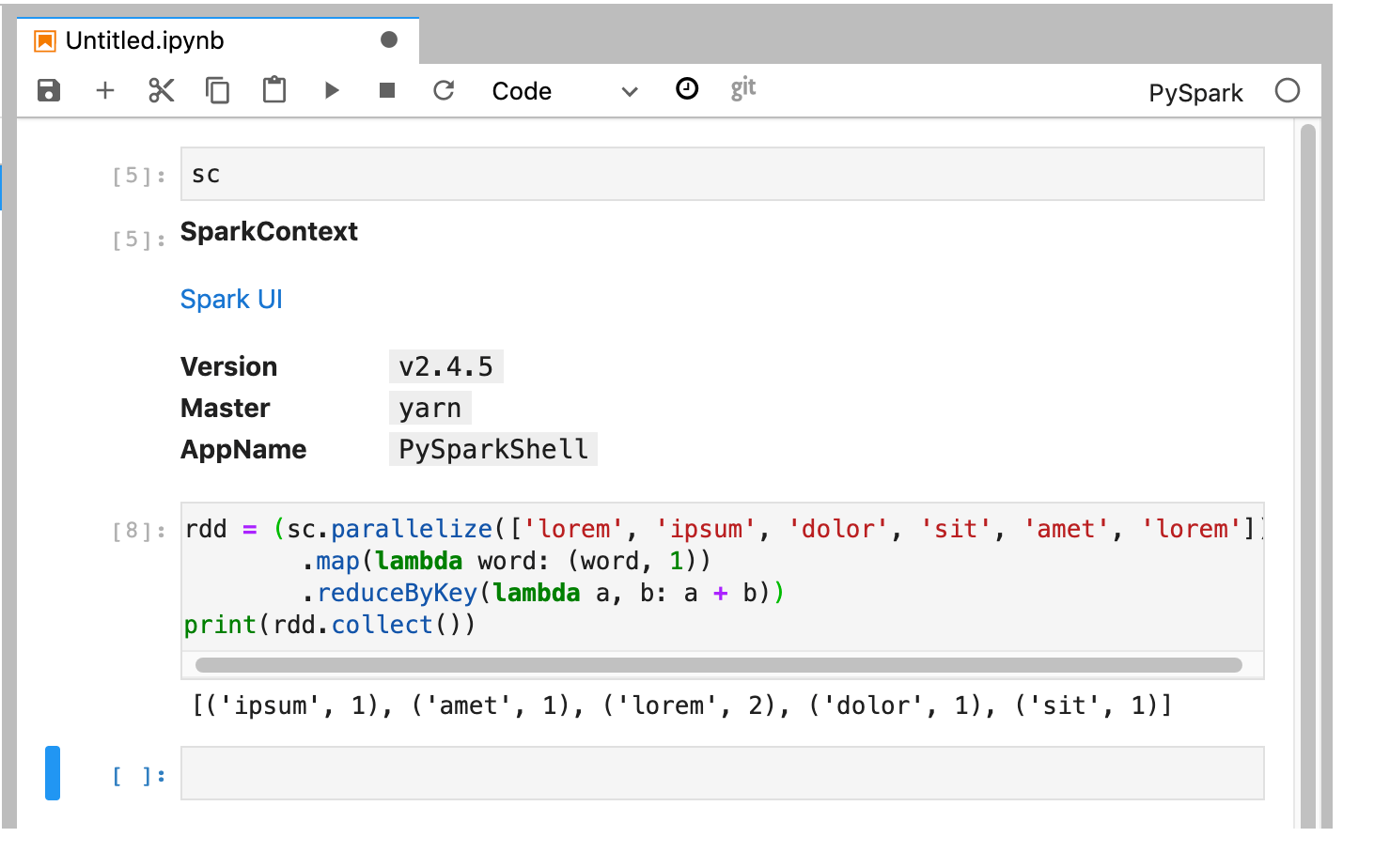
Beri nama dan simpan notebook. Notebook disimpan dan tetap berada di Cloud Storage setelah cluster Managed Service for Apache Spark dihapus.
Mematikan cluster Dataproc
Dari antarmuka JupyterLab, pilih File→Hub Control Panel untuk membuka halaman Jupyterhub.
Klik Stop My Cluster untuk mematikan (menghapus) server JupyterLab, yang menghapus cluster Managed Service for Apache Spark.
Langkah berikutnya
- Pelajari Spark dan Jupyter Notebooks di Dataproc di GitHub.