
מטרות
משתמשים ב-Dataproc Hub כדי ליצור סביבת מחברת JupyterLab למשתמש יחיד שפועלת באשכול Dataproc.
יוצרים מחברת ומריצים משימת Spark באשכול Dataproc.
מוחקים את האשכול ושומרים את המחברת ב-Cloud Storage.
לפני שמתחילים
- האדמין צריך להעניק לכם את ההרשאה
notebooks.instances.use(ראו הגדרת תפקידים בניהול זהויות והרשאות גישה (IAM)).
יצירת אשכול Dataproc JupyterLab מ-Dataproc Hub
במסוף Google Cloud , בדף Dataproc→Workbench, לוחצים על הכרטיסייה User-Managed Notebooks.
לוחצים על Open JupyterLab בשורה שבה מופיע מופע Dataproc Hub שנוצר על ידי האדמין.
- אם אין לכם גישה למסוף Google Cloud , צריך להזין בדפדפן האינטרנט את כתובת ה-URL של מופע Dataproc Hub שאדמין שיתף איתכם.
בדף Jupyterhub→Dataproc Options (אפשרויות של Jupyterhub→Dataproc), בוחרים הגדרת אשכול ואזור. אם האפשרות מופעלת, מציינים את ההתאמות האישיות הרצויות ולוחצים על יצירה.
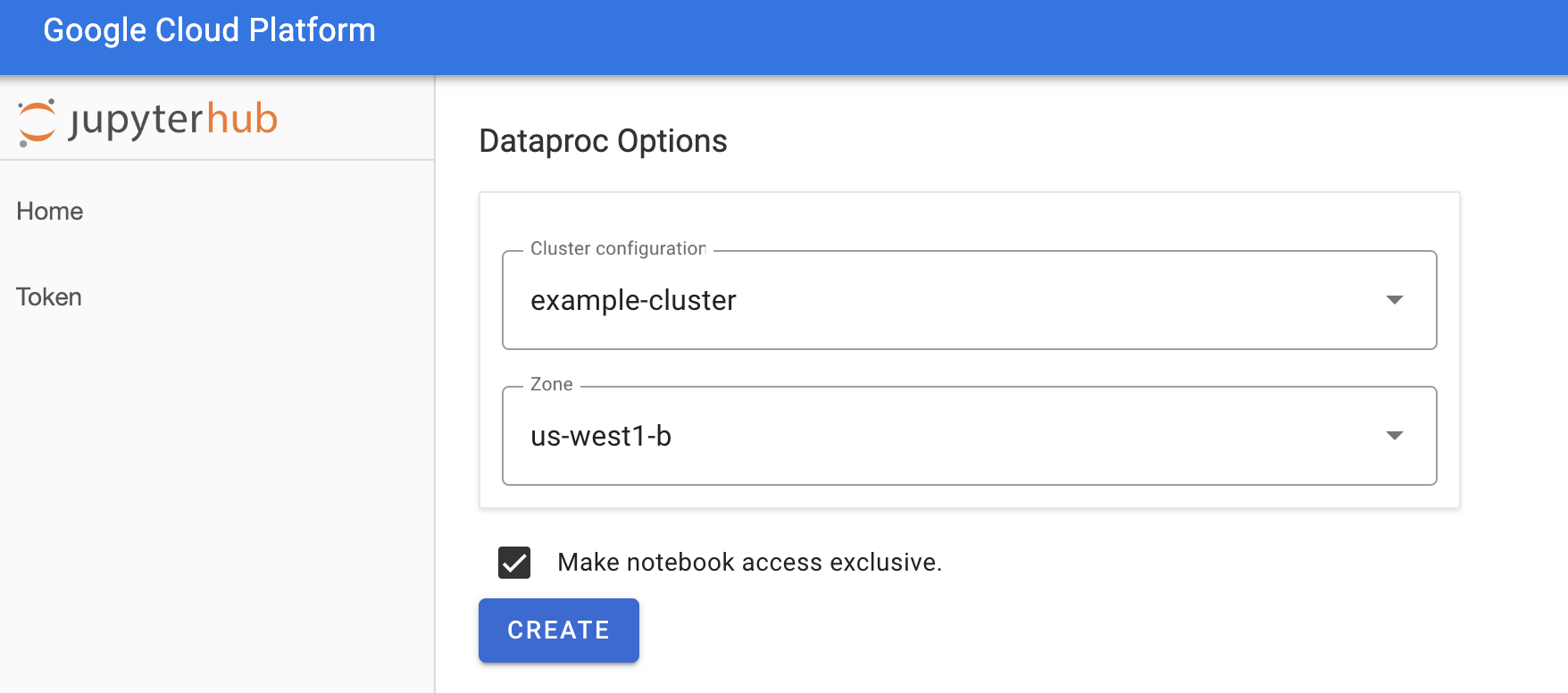
אחרי שאשכול Dataproc נוצר, המערכת מפנה אתכם לממשק JupyterLab שפועל באשכול.
יצירת מחברת והרצת משימת Spark
בחלונית הימנית של ממשק JupyterLab, לוחצים על
GCS(Cloud Storage).יוצרים מחברת PySpark מתוך מרכז ההפעלה של JupyterLab.
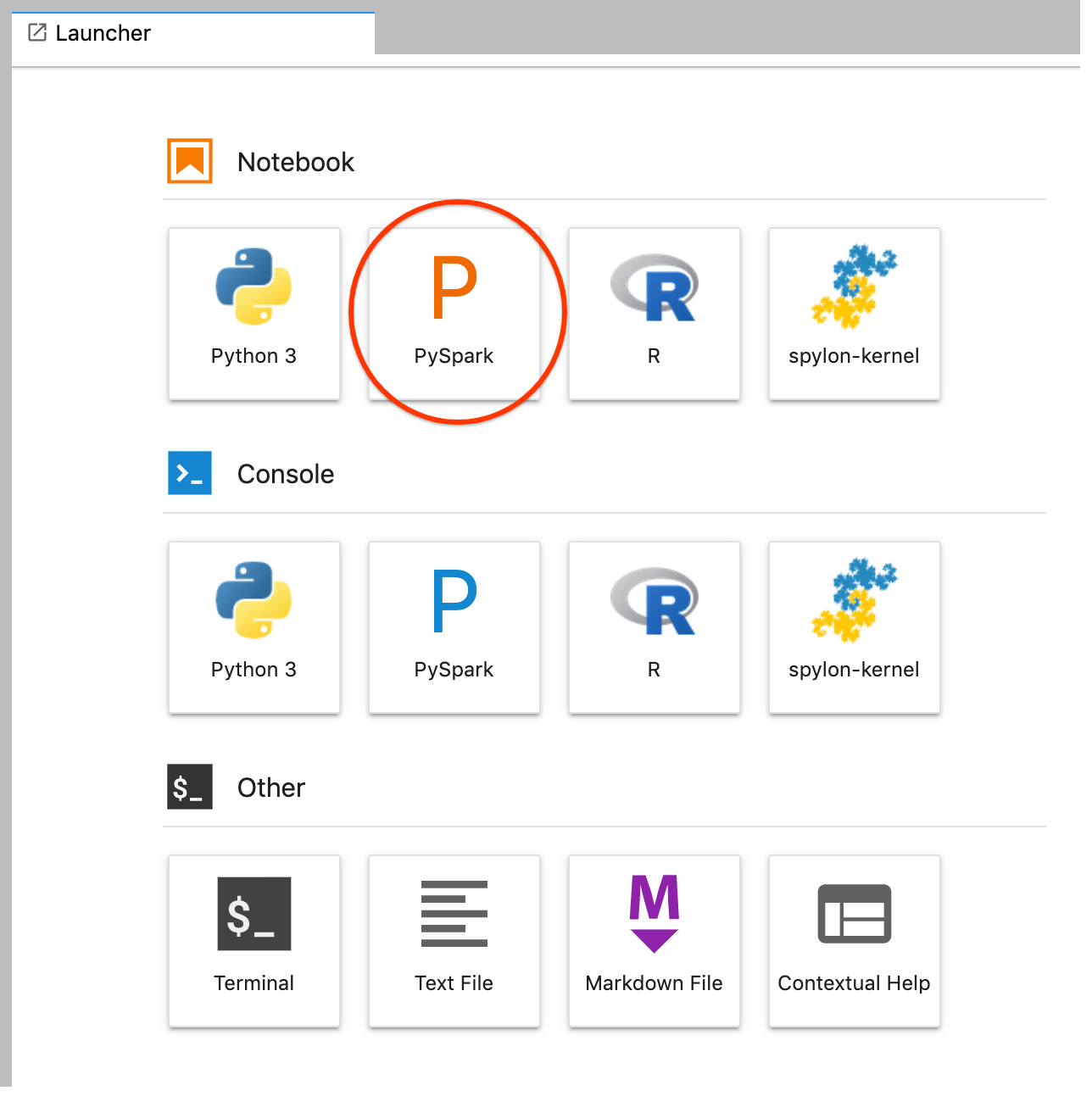
ליבת PySpark מאתחלת SparkContext (באמצעות המשתנה
sc). אפשר לבדוק את SparkContext ולהריץ משימת Spark מתוך המחברת.rdd = (sc.parallelize(['lorem', 'ipsum', 'dolor', 'sit', 'amet', 'lorem']) .map(lambda word: (word, 1)) .reduceByKey(lambda a, b: a + b)) print(rdd.collect())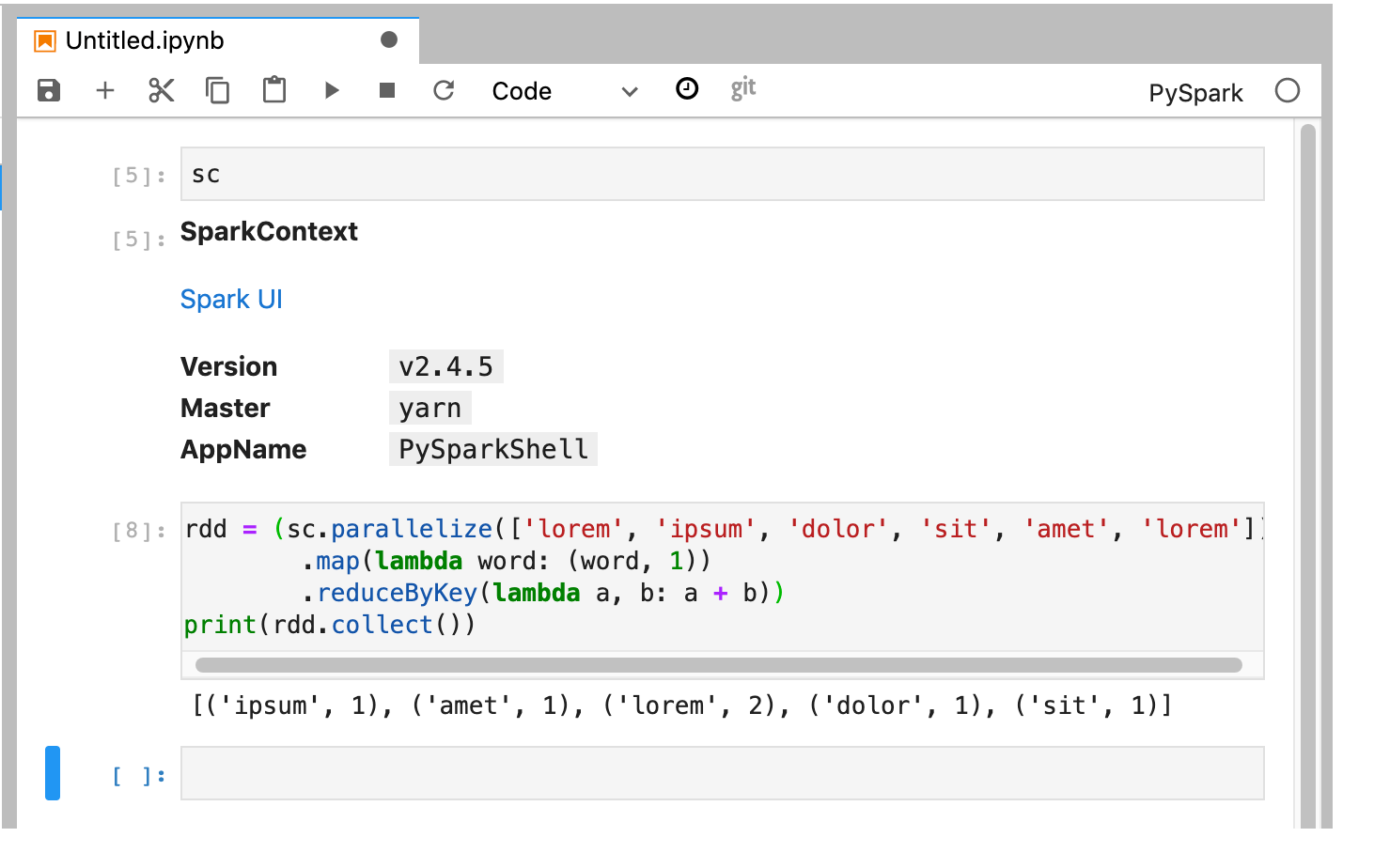
נותנים שם ל-notebook ושומרים אותו. המחברת נשמרת ונשארת ב-Cloud Storage אחרי שמחיקת אשכול Dataproc.
כיבוי של אשכול Dataproc
בממשק של JupyterLab, בוחרים באפשרות File→Hub Control Panel כדי לפתוח את הדף Jupyterhub.
לוחצים על Stop My Cluster (הפסקת האשכול) כדי להשבית (למחוק) את שרת JupyterLab, וכך למחוק את אשכול Dataproc.
המאמרים הבאים
- אפשר לעיין ב-Spark וב-Jupyter Notebooks ב-Dataproc ב-GitHub.