
O conetor do BigQuery para Apache Spark permite que os cientistas de dados combinem o poder do motor de SQL perfeitamente escalável do BigQuery com as capacidades de aprendizagem automática do Apache Spark. Neste tutorial, mostramos como usar o Dataproc, o BigQuery e o Apache Spark ML para realizar a aprendizagem automática num conjunto de dados.
Objetivos
Use a regressão linear para criar um modelo do peso ao nascer como função de cinco fatores:- semanas de gestação
- idade da mãe
- Idade do pai
- Aumento de peso da mãe durante a gravidez
- Índice de Apgar
Use as seguintes ferramentas:
- BigQuery, para preparar a tabela de entrada de regressão linear, que é escrita no seu Google Cloud projeto
- Python, para consultar e gerir dados no BigQuery
- Apache Spark, para aceder à tabela de regressão linear resultante
- Spark ML, para criar e avaliar o modelo
- Tarefa PySpark do Dataproc para invocar funções do Spark ML
Custos
Neste documento, usa os seguintes componentes faturáveis do Google Cloud:
- Compute Engine
- Dataproc
- BigQuery
Para gerar uma estimativa de custos com base na sua utilização prevista,
use a calculadora de preços.
Antes de começar
Um cluster do Dataproc tem os componentes do Spark, incluindo o Spark ML, instalados. Para configurar um cluster do Dataproc e executar o código neste exemplo, tem de fazer (ou ter feito) o seguinte:
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Enable the Dataproc, BigQuery, Compute Engine APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
Se estiver a usar um fornecedor de identidade (IdP) externo, tem primeiro de iniciar sessão na CLI gcloud com a sua identidade federada.
-
Para inicializar a CLI gcloud, execute o seguinte comando:
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Enable the Dataproc, BigQuery, Compute Engine APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
Se estiver a usar um fornecedor de identidade (IdP) externo, tem primeiro de iniciar sessão na CLI gcloud com a sua identidade federada.
-
Para inicializar a CLI gcloud, execute o seguinte comando:
gcloud init - Crie um cluster do Dataproc no seu projeto. O cluster deve estar a executar uma versão do Dataproc com o Spark 2.0 ou superior (inclui bibliotecas de aprendizagem automática).
Crie um conjunto de dados no seu projeto.
- Aceda à IU Web do BigQuery.
- No painel de navegação do lado esquerdo, clique no nome do projeto e, de seguida, clique em CREATE DATASET (CRIAR CONJUNTO DE DADOS).
- Na caixa de diálogo Criar conjunto de dados:
- Para ID do conjunto de dados, introduza "natality_regression".
- Para Localização de dados, pode escolher uma
localização
para o conjunto de dados. A localização do valor predefinido é
US multi-region. Após a criação de um conjunto de dados, não é possível alterar a localização. - Em Validade predefinida da tabela, escolha uma das seguintes opções:
- Nunca (predefinição): tem de eliminar a tabela manualmente.
- Número de dias: a tabela é eliminada após o número de dias especificado a partir da hora de criação.
- Para Encriptação, escolha uma das seguintes opções:
- Google-owned and Google-managed encryption key (predefinição).
- Chave gerida pelo cliente: consulte o artigo Proteger dados com chaves do Cloud KMS.
- Clique em Criar conjunto de dados.
Execute uma consulta no conjunto de dados público de natalidade e, em seguida, guarde os resultados da consulta numa nova tabela no seu conjunto de dados.
- Copie e cole a seguinte consulta no editor de consultas e, de seguida,
clique em Executar.
CREATE OR REPLACE TABLE natality_regression.regression_input as SELECT weight_pounds, mother_age, father_age, gestation_weeks, weight_gain_pounds, apgar_5min FROM `bigquery-public-data.samples.natality` WHERE weight_pounds IS NOT NULL AND mother_age IS NOT NULL AND father_age IS NOT NULL AND gestation_weeks IS NOT NULL AND weight_gain_pounds IS NOT NULL AND apgar_5min IS NOT NULL
- Após a conclusão da consulta (em aproximadamente um minuto), os resultados são guardados como a tabela do BigQuery "regression_input" no conjunto de dados
natality_regressionno seu projeto.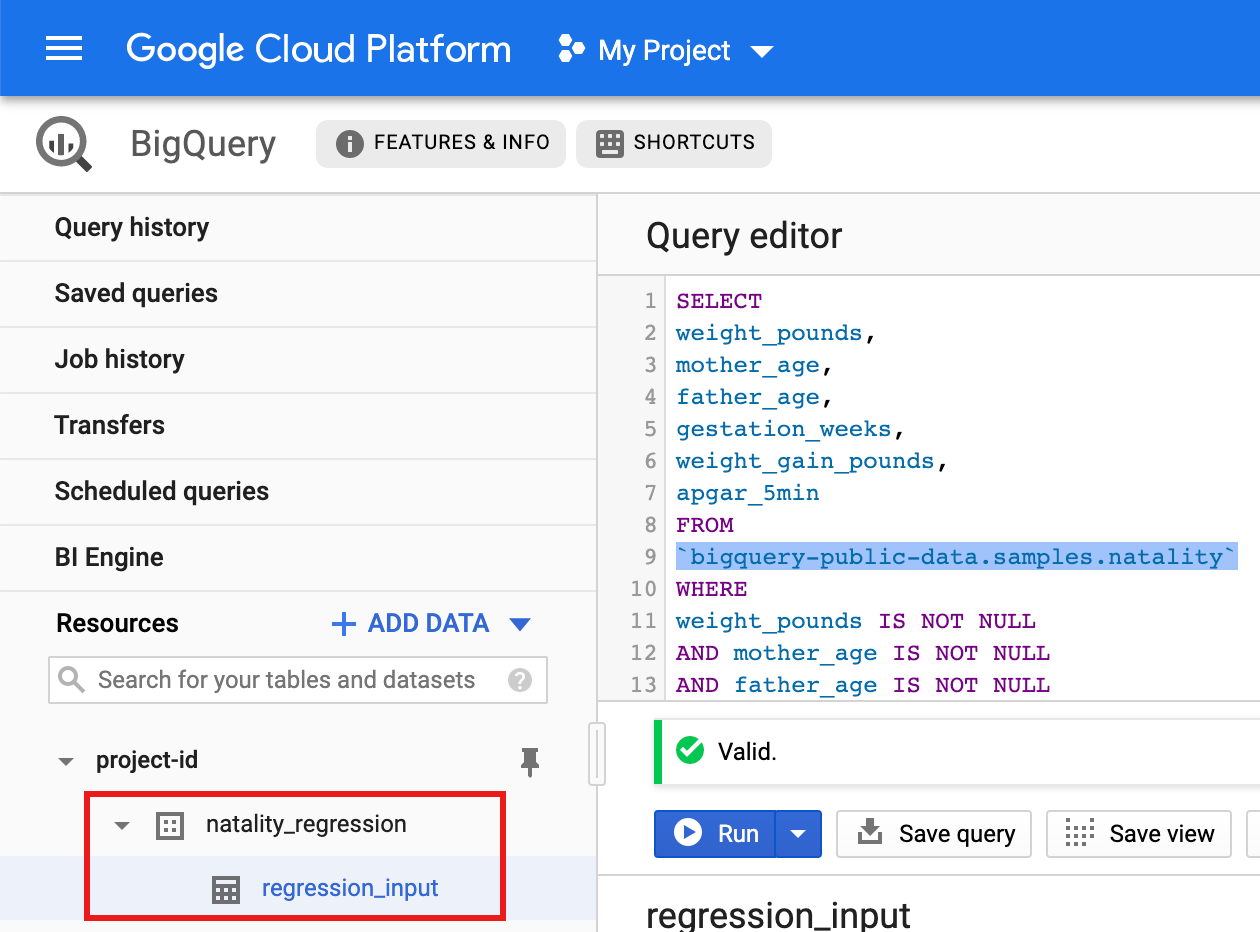
- Copie e cole a seguinte consulta no editor de consultas e, de seguida,
clique em Executar.
Consulte o artigo Configurar um ambiente de desenvolvimento Python para ver instruções sobre a instalação do Python e da biblioteca cliente Google Cloud para Python (necessária para executar o código). Recomendamos a instalação e a utilização de um Python
virtualenv.Copie e cole o código
natality_tutorial.pyabaixo numa shellpythonna sua máquina local. Prima a tecla<return>na shell para executar o código para criar um conjunto de dados do BigQuery "natality_regression" no seu projetoGoogle Cloud predefinido com uma tabela "regression_input" preenchida com um subconjunto dos dadosnatalitypúblicos.Confirme a criação do conjunto de dados
natality_regressione da tabelaregression_input.
Copie e cole o seguinte código num novo
natality_sparkml.pyficheiro no seu computador local."""Run a linear regression using Apache Spark ML. In the following PySpark (Spark Python API) code, we take the following actions: * Load a previously created linear regression (BigQuery) input table into our Cloud Dataproc Spark cluster as an RDD (Resilient Distributed Dataset) * Transform the RDD into a Spark Dataframe * Vectorize the features on which the model will be trained * Compute a linear regression using Spark ML """ from pyspark.context import SparkContext from pyspark.ml.linalg import Vectors from pyspark.ml.regression import LinearRegression from pyspark.sql.session import SparkSession # The imports, above, allow us to access SparkML features specific to linear # regression as well as the Vectors types. # Define a function that collects the features of interest # (mother_age, father_age, and gestation_weeks) into a vector. # Package the vector in a tuple containing the label (`weight_pounds`) for that # row. def vector_from_inputs(r): return (r["weight_pounds"], Vectors.dense(float(r["mother_age"]), float(r["father_age"]), float(r["gestation_weeks"]), float(r["weight_gain_pounds"]), float(r["apgar_5min"]))) sc = SparkContext() spark = SparkSession(sc) # Read the data from BigQuery as a Spark Dataframe. natality_data = spark.read.format("bigquery").option( "table", "natality_regression.regression_input").load() # Create a view so that Spark SQL queries can be run against the data. natality_data.createOrReplaceTempView("natality") # As a precaution, run a query in Spark SQL to ensure no NULL values exist. sql_query = """ SELECT * from natality where weight_pounds is not null and mother_age is not null and father_age is not null and gestation_weeks is not null """ clean_data = spark.sql(sql_query) # Create an input DataFrame for Spark ML using the above function. training_data = clean_data.rdd.map(vector_from_inputs).toDF(["label", "features"]) training_data.cache() # Construct a new LinearRegression object and fit the training data. lr = LinearRegression(maxIter=5, regParam=0.2, solver="normal") model = lr.fit(training_data) # Print the model summary. print("Coefficients:" + str(model.coefficients)) print("Intercept:" + str(model.intercept)) print("R^2:" + str(model.summary.r2)) model.summary.residuals.show()
Copie o ficheiro
natality_sparkml.pylocal para um contentor do Cloud Storage no seu projeto.gcloud storage cp natality_sparkml.py gs://bucket-name
Execute a regressão a partir da página Enviar uma tarefa do Dataproc.
No campo Ficheiro Python principal, insira o URI do contentor do Cloud Storage onde se encontra a sua cópia do ficheiro
natality_sparkml.py.gs://Selecione
PySparkcomo o Tipo de serviço.Insira
gs://spark-lib/bigquery/spark-bigquery-latest_2.12.jarno campo Ficheiros JAR. Isto torna o spark-bigquery-connector disponível para a aplicação PySpark no momento da execução, o que lhe permite ler dados do BigQuery num DataFrame do Spark.Preencha os campos ID da tarefa, Região e Cluster.
Clique em Enviar para executar a tarefa no seu cluster.
Copie e cole o seguinte código num novo
natality_sparkml.pyficheiro no seu computador local."""Run a linear regression using Apache Spark ML. In the following PySpark (Spark Python API) code, we take the following actions: * Load a previously created linear regression (BigQuery) input table into our Cloud Dataproc Spark cluster as an RDD (Resilient Distributed Dataset) * Transform the RDD into a Spark Dataframe * Vectorize the features on which the model will be trained * Compute a linear regression using Spark ML """ from pyspark.context import SparkContext from pyspark.ml.linalg import Vectors from pyspark.ml.regression import LinearRegression from pyspark.sql.session import SparkSession # The imports, above, allow us to access SparkML features specific to linear # regression as well as the Vectors types. # Define a function that collects the features of interest # (mother_age, father_age, and gestation_weeks) into a vector. # Package the vector in a tuple containing the label (`weight_pounds`) for that # row. def vector_from_inputs(r): return (r["weight_pounds"], Vectors.dense(float(r["mother_age"]), float(r["father_age"]), float(r["gestation_weeks"]), float(r["weight_gain_pounds"]), float(r["apgar_5min"]))) sc = SparkContext() spark = SparkSession(sc) # Read the data from BigQuery as a Spark Dataframe. natality_data = spark.read.format("bigquery").option( "table", "natality_regression.regression_input").load() # Create a view so that Spark SQL queries can be run against the data. natality_data.createOrReplaceTempView("natality") # As a precaution, run a query in Spark SQL to ensure no NULL values exist. sql_query = """ SELECT * from natality where weight_pounds is not null and mother_age is not null and father_age is not null and gestation_weeks is not null """ clean_data = spark.sql(sql_query) # Create an input DataFrame for Spark ML using the above function. training_data = clean_data.rdd.map(vector_from_inputs).toDF(["label", "features"]) training_data.cache() # Construct a new LinearRegression object and fit the training data. lr = LinearRegression(maxIter=5, regParam=0.2, solver="normal") model = lr.fit(training_data) # Print the model summary. print("Coefficients:" + str(model.coefficients)) print("Intercept:" + str(model.intercept)) print("R^2:" + str(model.summary.r2)) model.summary.residuals.show()
Copie o ficheiro
natality_sparkml.pylocal para um contentor do Cloud Storage no seu projeto.gcloud storage cp natality_sparkml.py gs://bucket-name
Envie a tarefa do Pyspark para o serviço Dataproc executando o comando
gcloud, apresentado abaixo, a partir de uma janela de terminal na sua máquina local.- O valor da flag --jars torna o spark-bigquery-connector disponível
para a tarefa do PySpark em tempo de execução para lhe permitir ler
dados do BigQuery num DataFrame do Spark.
gcloud dataproc jobs submit pyspark \ gs://your-bucket/natality_sparkml.py \ --cluster=cluster-name \ --region=region \ --jars=gs://spark-lib/bigquery/spark-bigquery-with-dependencies_SCALA_VERSION-CONNECTOR_VERSION.jar
- O valor da flag --jars torna o spark-bigquery-connector disponível
para a tarefa do PySpark em tempo de execução para lhe permitir ler
dados do BigQuery num DataFrame do Spark.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Crie um subconjunto de dados de natalidade do BigQuery
Nesta secção, cria um conjunto de dados no seu projeto e, em seguida, cria uma tabela no conjunto de dados para o qual copia um subconjunto de dados da taxa de natalidade do conjunto de dados do BigQuery natality disponível publicamente. Mais adiante neste tutorial, vai usar os dados do subconjunto nesta tabela para prever o peso ao nascer como uma função da idade materna, da idade paterna e das semanas de gestação.
Pode criar o subconjunto de dados através da Google Cloud consola ou executando um script Python no seu computador local.
Consola
Python
Antes de experimentar este exemplo, siga as Pythoninstruções de configuração no início rápido do Dataproc com bibliotecas de cliente. Para mais informações, consulte a documentação de referência da API Python Dataproc.
Para se autenticar no Dataproc, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para um ambiente de desenvolvimento local.
Execute uma regressão linear
Nesta secção, vai executar uma regressão linear do PySpark enviando
a tarefa para o serviço Dataproc através da Google Cloud consola
ou executando o comando gcloud a partir de um terminal local.
Consola
Quando a tarefa estiver concluída, o resumo do modelo de saída de regressão linear é apresentado na janela de detalhes da tarefa do Dataproc.
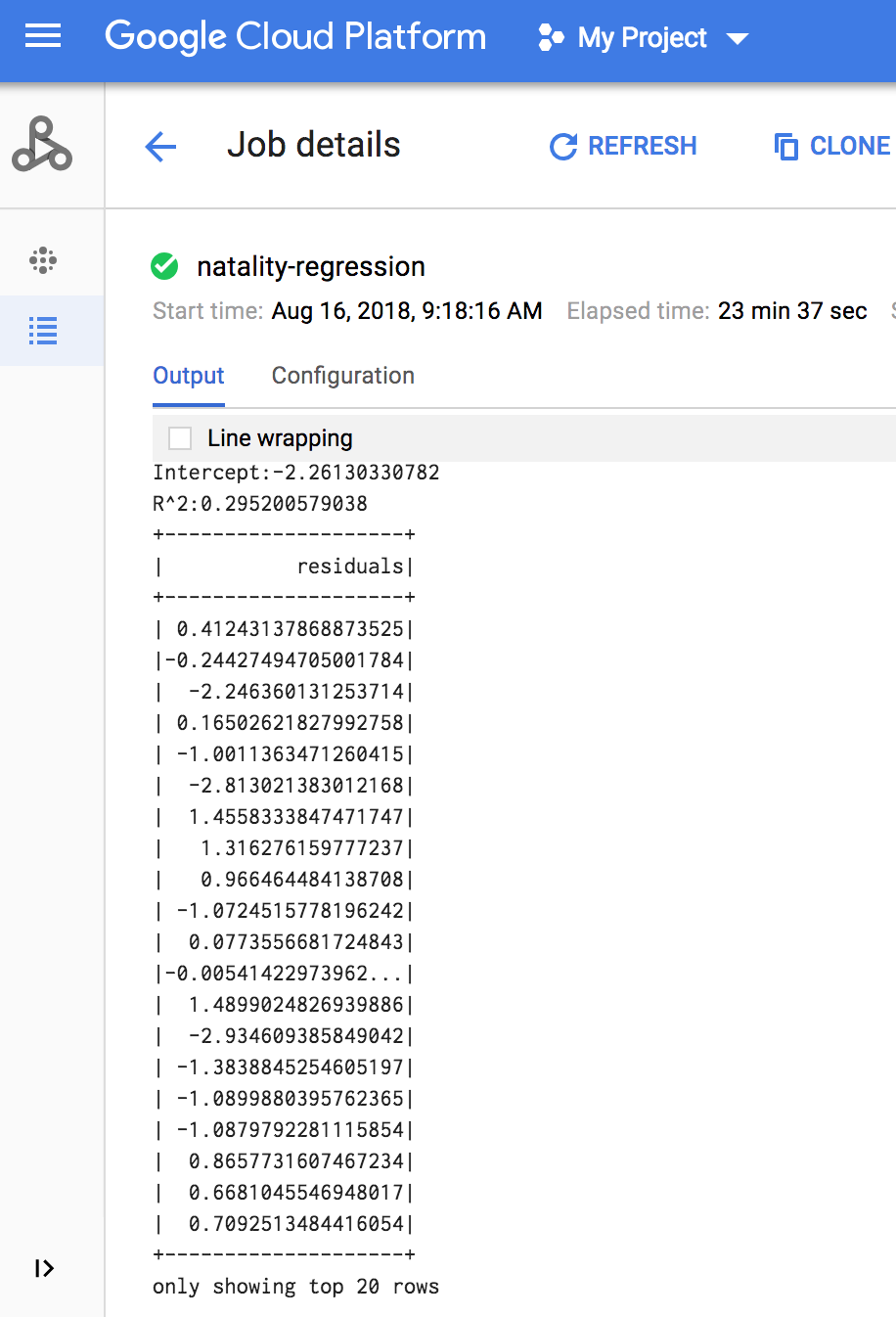
gcloud
O resultado da regressão linear (resumo do modelo) é apresentado na janela de terminal quando a tarefa é concluída.
<<< # Print the model summary. ... print "Coefficients:" + str(model.coefficients) Coefficients:[0.0166657454602,-0.00296751984046,0.235714392936,0.00213002070133,-0.00048577251587] <<< print "Intercept:" + str(model.intercept) Intercept:-2.26130330748 <<< print "R^2:" + str(model.summary.r2) R^2:0.295200579035 <<< model.summary.residuals.show() +--------------------+ | residuals| +--------------------+ | -0.7234737533344147| | -0.985466980630501| | -0.6669710598385468| | 1.4162434829714794| |-0.09373154375186754| |-0.15461747949235072| | 0.32659061654192545| | 1.5053877697929803| | -0.640142797263989| | 1.229530260294963| |-0.03776160295256...| | -0.5160734239126814| | -1.5165972740062887| | 1.3269085258245008| | 1.7604670124710626| | 1.2348130901905972| | 2.318660276655887| | 1.0936947030883175| | 1.0169768511417363| | -1.7744915698181583| +--------------------+ only showing top 20 rows.
Clean up
After you finish the tutorial, you can clean up the resources that you created so that they stop using quota and incurring charges. The following sections describe how to delete or turn off these resources.
Delete the project
The easiest way to eliminate billing is to delete the project that you created for the tutorial.
To delete the project:
Elimine o cluster do Dataproc
Consulte o artigo Elimine um grupo.