
O spark-bigquery-conector é usado com o Apache Spark para ler e gravar dados do e para o BigQuery. O conector usa a API BigQuery Storage ao ler dados do BigQuery.
Este tutorial fornece informações sobre a disponibilidade do conector pré-instalado e mostra como disponibilizar uma versão específica do conector para jobs do Spark. O exemplo de código mostra como usar o conector do BigQuery para Spark em um aplicativo Spark.
Usar o conector pré-instalado
O conector do Spark BigQuery é pré-instalado e está disponível para
jobs do Spark executados em clusters do Serviço Gerenciado para Apache Spark criados com versões de imagem
2.1 e mais recentes. A versão pré-instalada do conector está listada nas
páginas de lançamento da versão da imagem.
Disponibilizar uma versão específica do conector para jobs do Spark
Se você quiser usar uma versão de conector diferente de uma versão pré-instalada em um cluster de versão de imagem 2.1 ou mais recente, ou se quiser instalar o conector em um cluster de versão de imagem anterior a 2.1, siga as instruções desta seção.
Importante:a versão spark-bigquery-connector precisa ser compatível com a versão de imagem do cluster do Serviço Gerenciado para Apache Spark. Consulte a matriz de compatibilidade de imagens do conector com o Serviço Gerenciado para Apache Spark.
Clusters da versão de imagem 2.1 e posteriores
Ao criar um cluster do Serviço Gerenciado para Apache Spark
com uma versão de imagem 2.1 ou mais recente, especifique a
versão do conector como metadados do cluster.
Exemplo da CLI gcloud:
gcloud dataproc clusters create CLUSTER_NAME \ --region=REGION \ --image-version=2.2 \ --metadata=SPARK_BQ_CONNECTOR_VERSION or SPARK_BQ_CONNECTOR_URL\ other flags
Observações:
SPARK_BQ_CONNECTOR_VERSION: especifique uma versão do conector. As versões do conector do Spark para o BigQuery estão listadas na página spark-bigquery-connector/releases no GitHub.
Exemplo:
--metadata=SPARK_BQ_CONNECTOR_VERSION=0.42.1
SPARK_BQ_CONNECTOR_URL: especifique um URL que aponte para o jar no Cloud Storage. Você pode especificar o URL de um conector listado na coluna link em Como fazer o download e usar o conector no GitHub ou o caminho para um local do Cloud Storage em que você colocou um jar de conector personalizado.
Exemplos:
--metadata=SPARK_BQ_CONNECTOR_URL=gs://spark-lib/bigquery/spark-3.5-bigquery-0.42.1.jar --metadata=SPARK_BQ_CONNECTOR_URL=gs://PATH_TO_CUSTOM_JAR
Clusters da versão de imagem 2.0 e anteriores
Você pode disponibilizar o conector do Spark BigQuery para seu aplicativo de uma das seguintes maneiras:
Instale o spark-bigquery-connector no diretório jars do Spark de cada nó usando a ação de inicialização dos conectores do Serviço Gerenciado para Apache Spark ao criar o cluster.
Forneça o URL do jar do conector ao enviar o job para o cluster usando o console do Google Cloud , a CLI gcloud ou a API do Serviço Gerenciado para Apache Spark.
Console
Use o item Arquivos JAR do job do Spark na página Enviar um job do Serviço Gerenciado para Apache Spark.
gcloud
API
Use o campo
SparkJob.jarFileUris.Como especificar o jar do conector ao executar jobs do Spark em clusters com versão de imagem anterior à 2.0
- Especifique o jar do conector substituindo as informações de versão do Scala e do conector na seguinte string de URI:
gs://spark-lib/bigquery/spark-bigquery-with-dependencies_SCALA_VERSION-CONNECTOR_VERSION.jar
- Usar o Scala
2.12com as versões de imagem do Serviço Gerenciado para Apache Spark1.5+gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.12-CONNECTOR_VERSION.jar
gcloud dataproc jobs submit spark \ --jars=gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.12-0.23.2.jar \ -- job args
- Use o Scala
2.11com as versões de imagem do Serviço Gerenciado para Apache Spark1.4e anteriores:gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.11-CONNECTOR_VERSION.jar
gcloud dataproc jobs submit spark \ --jars=gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.11-0.23.2.jar \ -- job-args
- Especifique o jar do conector substituindo as informações de versão do Scala e do conector na seguinte string de URI:
Inclua o jar do conector no aplicativo Scala ou Java Spark como uma dependência. Consulte Como compilar com o conector.
Calcular custos
Neste documento, você vai usar os seguintes componentes faturáveis do Google Cloud:
- Managed Service for Apache Spark
- BigQuery
- Cloud Storage
Para gerar uma estimativa de custo baseada na projeção de uso deste tutorial, use a calculadora de preços.
Ler e gravar dados do BigQuery
Este exemplo lê dados do BigQuery em um DataFrame do Spark para executar uma contagem de palavras usando a API de origem de dados padrão.
O conector grava os dados no BigQuery primeiro armazenando-os em buffer em uma tabela temporária do Cloud Storage. Em seguida, ele copia todos os dados para o BigQuery em uma operação. O conector tenta excluir os arquivos temporários depois que a operação de carregamento do BigQuery for bem-sucedida e mais uma vez quando o aplicativo Spark é encerrado.
Se o job falhar, remova os arquivos temporários restantes do Cloud Storage. Normalmente, os arquivos temporários do BigQuery estão localizados em gs://[bucket]/.spark-bigquery-[jobid]-[UUID].
Configurar o faturamento
Por padrão, o projeto associado às credenciais ou à conta de serviço é cobrado pelo uso da API. Para faturar um projeto diferente, defina a seguinte configuração: spark.conf.set("parentProject", "<BILLED-GCP-PROJECT>").
Ele também pode ser adicionado a uma operação de leitura ou gravação, da seguinte maneira: .option("parentProject", "<BILLED-GCP-PROJECT>").
Executar o código
Antes de executar este exemplo, crie um conjunto de dados chamado "wordcount_dataset" ou altere o conjunto de dados de saída no código para um conjunto de dados existente do BigQuery no projetoGoogle Cloud .
Use o comando bq para criar o wordcount_dataset:
bq mk wordcount_dataset
Use o comando da Google Cloud CLI para criar um bucket do Cloud Storage, que será usado para exportar para o BigQuery:
gcloud storage buckets create gs://[bucket]
Scala
- Examine o código e substitua o marcador [bucket] pelo bucket do Cloud Storage criado anteriormente.
/* * Remove comment if you are not running in spark-shell. * import org.apache.spark.sql.SparkSession val spark = SparkSession.builder() .appName("spark-bigquery-demo") .getOrCreate() */ // Use the Cloud Storage bucket for temporary BigQuery export data used // by the connector. val bucket = "[bucket]" spark.conf.set("temporaryGcsBucket", bucket) // Load data in from BigQuery. See // https://github.com/GoogleCloudDataproc/spark-bigquery-connector/tree/0.17.3#properties // for option information. val wordsDF = spark.read.bigquery("bigquery-public-data:samples.shakespeare") .cache() wordsDF.createOrReplaceTempView("words") // Perform word count. val wordCountDF = spark.sql( "SELECT word, SUM(word_count) AS word_count FROM words GROUP BY word") wordCountDF.show() wordCountDF.printSchema() // Saving the data to BigQuery. (wordCountDF.write.format("bigquery") .save("wordcount_dataset.wordcount_output"))
- Executar o código no seu cluster
- Use SSH para se conectar ao nó mestre do cluster do Serviço Gerenciado para Apache Spark.
- Acesse a página
Clusters do Serviço Gerenciado para Apache Spark
no console Google Cloud e clique no nome do cluster
- Na página >Detalhes do cluster, selecione a guia "Instâncias de VM". Em seguida, clique em
SSHà direita do nome do nó mestre do cluster>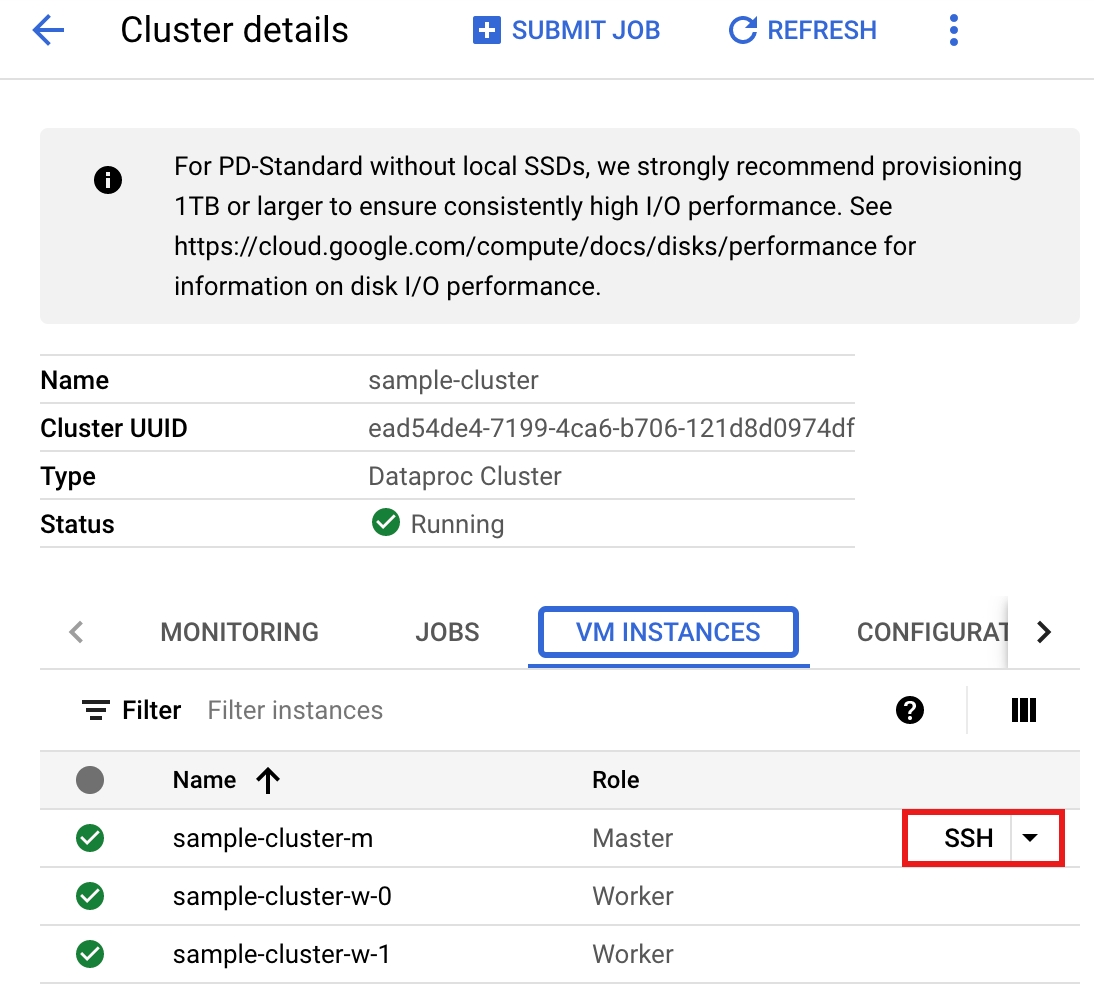
Uma janela do navegador é aberta no diretório principal no nó mestre.Connected, host fingerprint: ssh-rsa 2048 ... ... user@clusterName-m:~$
- Acesse a página
Clusters do Serviço Gerenciado para Apache Spark
no console Google Cloud e clique no nome do cluster
- Crie
wordcount.scalacom o editor de textovi,vimounanopré-instalado e cole o código da lista de códigos Scalanano wordcount.scala
- Inicie o REPL
spark-shell.$ spark-shell --jars=gs://spark-lib/bigquery/spark-bigquery-latest.jar ... Using Scala version ... Type in expressions to have them evaluated. Type :help for more information. ... Spark context available as sc. ... SQL context available as sqlContext. scala>
- Execute o wordcount.scala com o comando
:load wordcount.scalapara criar a tabelawordcount_outputdo BigQuery. A listagem de saída exibe 20 linhas a partir da saída de wordcount.:load wordcount.scala ... +---------+----------+ | word|word_count| +---------+----------+ | XVII| 2| | spoil| 28| | Drink| 7| |forgetful| 5| | Cannot| 46| | cures| 10| | harder| 13| | tresses| 3| | few| 62| | steel'd| 5| | tripping| 7| | travel| 35| | ransom| 55| | hope| 366| | By| 816| | some| 1169| | those| 508| | still| 567| | art| 893| | feign| 10| +---------+----------+ only showing top 20 rows root |-- word: string (nullable = false) |-- word_count: long (nullable = true)
Para visualizar a tabela de saída, abra a páginaBigQueryselecione a tabelawordcount_outpute clique em Visualizar.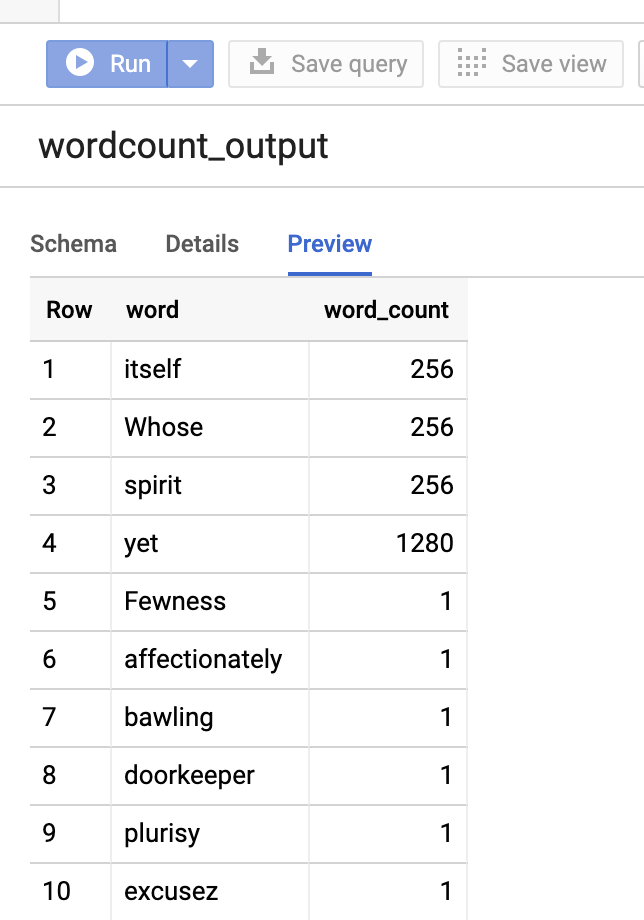
- Use SSH para se conectar ao nó mestre do cluster do Serviço Gerenciado para Apache Spark.
PySpark
- Examine o código e substitua o marcador [bucket] pelo bucket do Cloud Storage criado anteriormente.
#!/usr/bin/env python """BigQuery I/O PySpark example.""" from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .master('yarn') \ .appName('spark-bigquery-demo') \ .getOrCreate() # Use the Cloud Storage bucket for temporary BigQuery export data used # by the connector. bucket = "[bucket]" spark.conf.set('temporaryGcsBucket', bucket) # Load data from BigQuery. words = spark.read.format('bigquery') \ .load('bigquery-public-data:samples.shakespeare') \ words.createOrReplaceTempView('words') # Perform word count. word_count = spark.sql( 'SELECT word, SUM(word_count) AS word_count FROM words GROUP BY word') word_count.show() word_count.printSchema() # Save the data to BigQuery word_count.write.format('bigquery') \ .save('wordcount_dataset.wordcount_output')
- Executar o código no cluster
- Use SSH para se conectar ao nó mestre do cluster do Serviço Gerenciado para Apache Spark.
- Acesse a página
Clusters do Serviço Gerenciado para Apache Spark
no console Google Cloud e clique no nome do cluster
- Na página Detalhes do cluster, selecione a guia "Instâncias de VM". Em seguida, clique em
SSHà direita do nome do nó mestre do cluster
Uma janela do navegador é aberta no diretório principal no nó mestre.Connected, host fingerprint: ssh-rsa 2048 ... ... user@clusterName-m:~$
- Acesse a página
Clusters do Serviço Gerenciado para Apache Spark
no console Google Cloud e clique no nome do cluster
- Crie
wordcount.pycom o editor de textovi,vimounanopré-instalado e cole o código PySpark da lista de códigos PySparknano wordcount.py
- Execute a contagem de palavras com
spark-submitpara criar a tabelawordcount_outputdo BigQuery. A listagem de saída exibe 20 linhas a partir da saída de wordcount.spark-submit --jars gs://spark-lib/bigquery/spark-bigquery-latest.jar wordcount.py ... +---------+----------+ | word|word_count| +---------+----------+ | XVII| 2| | spoil| 28| | Drink| 7| |forgetful| 5| | Cannot| 46| | cures| 10| | harder| 13| | tresses| 3| | few| 62| | steel'd| 5| | tripping| 7| | travel| 35| | ransom| 55| | hope| 366| | By| 816| | some| 1169| | those| 508| | still| 567| | art| 893| | feign| 10| +---------+----------+ only showing top 20 rows root |-- word: string (nullable = false) |-- word_count: long (nullable = true)
Para visualizar a tabela de saída, abra a páginaBigQueryselecione a tabelawordcount_outpute clique em Visualizar.
- Use SSH para se conectar ao nó mestre do cluster do Serviço Gerenciado para Apache Spark.
Dicas de solução de problemas
É possível examinar os registros de jobs no Cloud Logging e no Explorador de jobs do BigQuery para resolver problemas com jobs do Spark que usam o conector do BigQuery.
Os registros do driver do Serviço Gerenciado para Apache Spark contêm uma entrada
BigQueryClientcom metadados do BigQuery que incluem ojobId:ClassNotFoundException
INFO BigQueryClient:.. jobId: JobId{project=PROJECT_ID, job=JOB_ID, location=LOCATION} Os jobs do BigQuery contêm rótulos
Managed Service for Apache Spark_job_ideManaged Service for Apache Spark_job_uuid:- Geração de registros:
protoPayload.serviceData.jobCompletedEvent.job.jobConfiguration.labels.dataproc_job_id="JOB_ID" protoPayload.serviceData.jobCompletedEvent.job.jobConfiguration.labels.dataproc_job_uuid="JOB_UUID" protoPayload.serviceData.jobCompletedEvent.job.jobName.jobId="JOB_NAME"
- Explorador de jobs do BigQuery: clique em um ID de job para ver os detalhes em Rótulos em Informações do job.
- Geração de registros:
A seguir
- Consulte Armazenamento do BigQuery e Spark SQL, Python.
- Saiba como criar um arquivo de definição de tabela para uma fonte de dados externa.
- Saiba como consultar dados particionados externamente.
- Consulte dicas de ajuste de jobs do Spark.