
I log dei job e dei cluster di Managed Service per Apache Spark possono essere visualizzati, cercati, filtrati, e archiviati in Cloud Logging.
Consulta i prezzi di Google Cloud Observability per comprendere i costi.
Per informazioni sulla conservazione dei log, consulta Periodi di conservazione dei log.
Consulta Esclusioni dei log per disabilitare tutti i log o escludere i log da Logging.
Consulta la panoramica su routing e archiviazione per eseguire il routing dei log da Logging a Cloud Storage, BigQuery o Pub/Sub.
Livelli di logging dei componenti
Imposta i livelli di logging dei componenti di Spark, Hadoop, Flink e altri componenti di Managed Service per Apache Spark
con le proprietà log4j
del cluster, specifiche del componente, ad esempio hadoop-log4j, quando crei
un cluster. I livelli di logging dei componenti basati su cluster si applicano ai daemon di servizio, come YARN ResourceManager, e ai job eseguiti sul cluster.
Se le proprietà log4j non sono supportate per un componente, ad esempio il componente Presto,
scrivi un'azione di inizializzazione
che modifichi il file log4j.properties o log4j2.properties del componente.
Livelli di logging dei componenti specifici del job: puoi anche impostare i livelli di logging dei componenti quando invii un job. Questi livelli di logging vengono applicati al job e hanno la precedenza sui livelli di logging impostati quando hai creato il cluster. Per saperne di più, consulta Proprietà del cluster e del job .
Livelli di logging della versione dei componenti Spark e Hive:
I componenti Spark 3.3.X e Hive 3.X utilizzano le proprietà log4j2,
mentre le versioni precedenti di questi componenti utilizzano le proprietà log4j (vedi
Apache Log4j2).
Utilizza il prefisso spark-log4j: per impostare i livelli di logging di Spark su un cluster.
Esempio: versione dell'immagine di Managed Service per Apache Spark 2.0 con Spark 3.1 per impostare
log4j.logger.org.apache.spark:gcloud dataproc clusters create ... \ --properties spark-log4j:log4j.logger.org.apache.spark=DEBUG
Esempio: versione dell'immagine di Managed Service per Apache Spark 2.1 con Spark 3.3 per impostare
logger.sparkRoot.level:gcloud dataproc clusters create ...\ --properties spark-log4j:logger.sparkRoot.level=debug
Livelli di logging del driver del job
Managed Service per Apache Spark utilizza un livello di logging predefinito
di INFO per i programmi driver del job. Puoi modificare questa impostazione per uno o più pacchetti
con il gcloud dataproc jobs submit
--driver-log-levels flag.
Esempio:
Imposta il livello di logging DEBUG quando invii un job Spark che legge i file di Cloud Storage.
gcloud dataproc jobs submit spark ...\ --driver-log-levels org.apache.spark=DEBUG,com.google.cloud.hadoop.gcsio=DEBUG
Esempio:
Imposta il livello del logger root su WARN, il livello del logger com.example su INFO.
gcloud dataproc jobs submit hadoop ...\ --driver-log-levels root=WARN,com.example=INFO
Livelli di logging dell'esecutore Spark
Per configurare i livelli di logging dell'esecutore Spark:
Prepara un file di configurazione log4j e caricalo su Cloud Storage
.Fai riferimento al file di configurazione quando invii il job.
Esempio:
gcloud dataproc jobs submit spark ...\ --file gs://my-bucket/path/spark-log4j.properties \ --properties spark.executor.extraJavaOptions=-Dlog4j.configuration=file:spark-log4j.properties
Spark scarica il file delle proprietà di Cloud Storage nella directory di lavoro locale del job, a cui viene fatto riferimento come file:<name> in -Dlog4j.configuration.
Log dei job di Managed Service per Apache Spark in Logging
Per informazioni su come abilitare i log dei driver dei job di Managed Service per Apache Spark in Logging, consulta Output e log dei job di Managed Service per Apache Spark.
Accedere ai log dei job in Logging
Accedi ai log dei job di Managed Service per Apache Spark utilizzando Esplora log, il comando gcloud logging o l'API Logging.
Console
I log dei driver dei job e dei container YARN di Managed Service per Apache Spark sono elencati nella risorsa Job di Cloud Managed Service per Apache Spark.
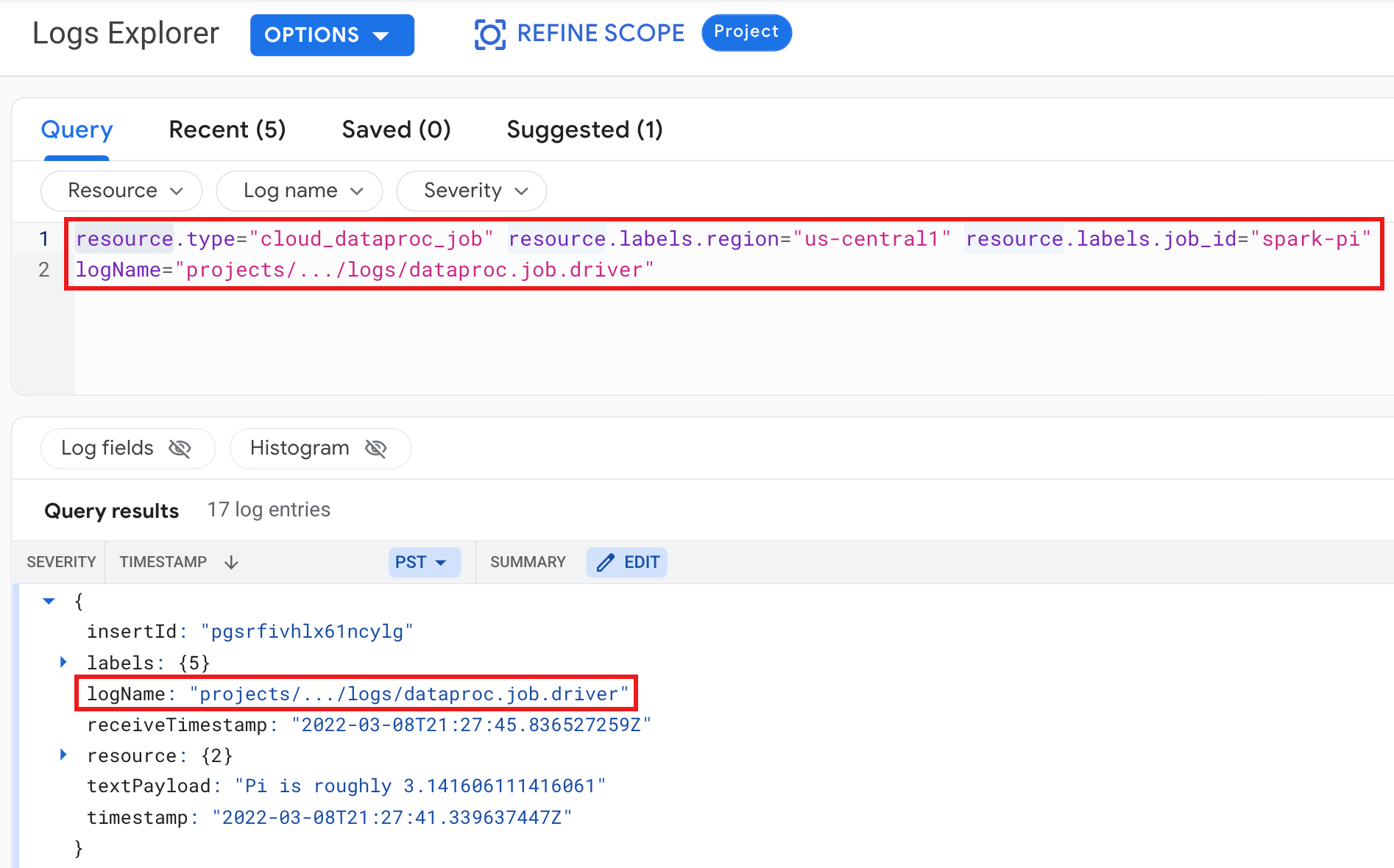
Esempio: log del driver del job dopo l'esecuzione di una query di Esplora log con le seguenti selezioni:
- Risorsa:
Cloud Dataproc Job - Nome log:
dataproc.job.driver
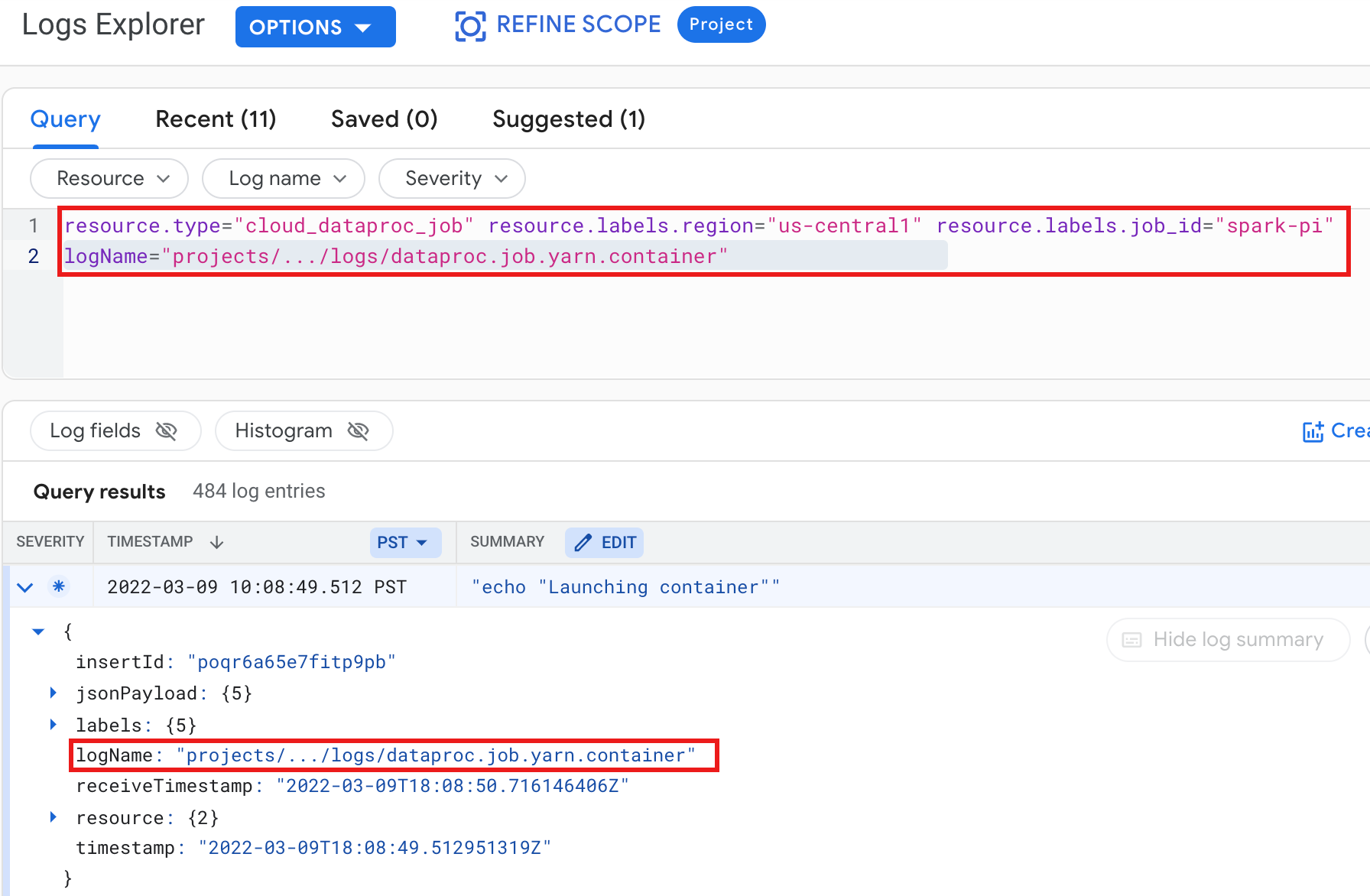
Esempio: log del container YARN dopo l'esecuzione di una query di Esplora log con le seguenti selezioni:
- Risorsa:
Cloud Dataproc Job - Nome log:
dataproc.job.yarn.container
gcloud
Puoi leggere le voci dei log dei job utilizzando il comando gcloud logging read. Gli argomenti delle risorse devono essere racchiusi tra virgolette ("..."). Il seguente comando utilizza le etichette dei cluster per filtrare le voci di log restituite.
gcloud logging read \ "resource.type=cloud_dataproc_job \ resource.labels.region=cluster-region \ resource.labels.job_id=my-job-id"
Esempio di output (parziale):
jsonPayload: class: org.apache.hadoop.hdfs.StateChange filename: hadoop-hdfs-namenode-test-dataproc-resize-cluster-20190410-38an-m-0.log ,,, logName: projects/project-id/logs/hadoop-hdfs-namenode --- jsonPayload: class: SecurityLogger.org.apache.hadoop.security.authorize.ServiceAuthorizationManager filename: cluster-name-dataproc-resize-cluster-20190410-38an-m-0.log ... logName: projects/google.com:hadoop-cloud-dev/logs/hadoop-hdfs-namenode
API REST
Puoi utilizzare l'API REST Logging per elencare le voci di log (vedi entries.list).
Log dei cluster di Managed Service per Apache Spark in Logging
Managed Service per Apache Spark esporta i seguenti log dei cluster Apache Hadoop, Spark, Hive, Zookeeper e altri log dei cluster di Managed Service per Apache Spark in Cloud Logging.
| Tipo di log | Nome log | Descrizione | Note |
|---|---|---|---|
| Log dei daemon master | hadoop-hdfs hadoop-hdfs-namenode hadoop-hdfs-secondarynamenode hadoop-hdfs-zkfc hadoop-yarn-resourcemanager hadoop-yarn-timelineserver hive-metastore hive-server2 hadoop-mapred-historyserver zookeeper |
Nodo journal Namenode HDFS Namenode secondario HDFS Controller di failover di Zookeeper Gestore risorse YARN Server della sequenza temporale YARN Metastore Hive Server Hive2 Server della cronologia dei job MapReduce Server Zookeeper |
|
| Log dei daemon worker |
hadoop-hdfs-datanode hadoop-yarn-nodemanager |
Datanode HDFS Nodemanager YARN |
|
| Log di sistema |
autoscaler google.dataproc.agent google.dataproc.startup |
Log dello strumento di scalabilità automatica di Managed Service per Apache Spark Log dell'agente di Managed Service per Apache Spark Log dello script di avvio di Managed Service per Apache Spark + log dell'azione di inizializzazione |
|
| Log estesi (aggiuntivi) |
knox gateway-audit zeppelin ranger-usersync jupyter_notebook jupyter_kernel_gateway spark-history-server |
Tutti i log nelle sottodirectory /var/log/ che corrispondono a:knox (include gateway-audit.log) zeppelin ranger-usersync jupyter_notebook jupyter_kernel_gateway spark-history-server |
L'impostazione della proprietà
dataproc:dataproc.logging.extended.enabled=false disabilita la raccolta dei log estesi sul cluster
|
| Log di sistema delle VM |
syslog |
Log di sistema dei nodi master e worker del cluster |
L'impostazione della proprietà
dataproc:dataproc.logging.syslog.enabled=false disabilita la raccolta dei log di sistema delle VM sul cluster
|
Accedere ai log dei cluster in Cloud Logging
Puoi accedere ai log dei cluster di Managed Service per Apache Spark utilizzando lo strumento Esplora log, il comando gcloud logging o l'API Logging.
Console
Seleziona le seguenti query per visualizzare i log dei cluster in Esplora log:
- Risorsa:
Cloud Dataproc Cluster - Nome log: log name
gcloud
Puoi leggere le voci dei log dei cluster utilizzando il comando gcloud logging read. Gli argomenti delle risorse devono essere racchiusi tra virgolette ("..."). Il seguente comando utilizza le etichette dei cluster per filtrare le voci di log restituite.
gcloud logging read <<'EOF' "resource.type=cloud_dataproc_cluster resource.labels.region=cluster-region resource.labels.cluster_name=cluster-name resource.labels.cluster_uuid=cluster-uuid" EOF
Esempio di output (parziale):
jsonPayload: class: org.apache.hadoop.yarn.server.resourcemanager.ResourceTrackerService filename: hadoop-yarn-resourcemanager-cluster-name-m.log ... logName: projects/project-id/logs/hadoop-yarn-resourcemanager --- jsonPayload: class: org.apache.hadoop.yarn.server.resourcemanager.ResourceTrackerService filename: hadoop-yarn-resourcemanager-component-gateway-cluster-m.log ... logName: projects/project-id/logs/hadoop-yarn-resourcemanager
API REST
Puoi utilizzare l'API REST Logging per elencare le voci di log (vedi entries.list).
Autorizzazioni
Per scrivere i log in Logging, il service
account della VM di Managed Service per Apache Spark deve avere il logging.logWriter
ruolo IAM. Il account di servizio predefinito di Managed Service per Apache Spark ha questo ruolo. Se utilizzi
un service account personalizzato,
devi assegnare questo ruolo al account di servizio.
Proteggere i log
Per impostazione predefinita, i log in Logging vengono criptati at-rest. Puoi abilitare le chiavi di crittografia gestite dal cliente (CMEK) per criptare i log. Per saperne di più sul supporto CMEK, consulta Gestire le chiavi che proteggono i dati del router dei log e Gestire le chiavi che proteggono i dati di archiviazione di Logging.
Passaggi successivi
- Esplora Google Cloud Observability.