
Puoi applicare etichette utente ai cluster e ai job Managed Service for Apache Spark per raggruppare queste risorse per la successiva applicazione di filtri ed elenchi. Associ le etichette alle risorse quando la risorsa viene creata, durante la creazione del cluster o l'invio del job. Una volta associata una risorsa a un'etichetta, questa viene propagata alle operazioni eseguite sulla risorsa: creazione, aggiornamento, applicazione di patch o eliminazione del cluster; invio, aggiornamento, annullamento o eliminazione del job, consentendoti di filtrare ed elencare cluster, job e operazioni in base all'etichetta.
Puoi anche aggiungere etichette alle risorse di Compute Engine associate alle risorse del cluster, come istanze di macchine virtuali e dischi.
Cosa sono le etichette?
Un'etichetta è una coppia chiave-valore che puoi assegnare ai cluster e ai job Managed Service for Apache Spark. Ti aiutano a organizzare queste risorse e a gestire i costi su larga scala, con la granularità di cui hai bisogno. Puoi collegare un'etichetta a ogni risorsa, quindi filtrare le risorse in base alle etichette. Le informazioni relative alle etichette vengono inoltrate al sistema di fatturazione, che ti consente di suddividere gli addebiti fatturati in base all'etichetta. Con i report sulla fatturazione integrati, puoi filtrare e raggruppare i costi in base alle etichette delle risorse. Puoi anche utilizzare le etichette per interrogare le esportazioni dei dati di fatturazione.
Requisiti per le etichette
Le etichette applicate a una risorsa devono soddisfare i seguenti requisiti:
- Ogni cluster o job può avere fino a 32 etichette.
- Ogni etichetta deve essere una coppia chiave/valore.
- Le chiavi hanno una lunghezza minima di 1 carattere e una lunghezza massima di 63 caratteri e non possono essere vuote. I valori possono essere vuoti e avere una lunghezza massima di 63 caratteri.
- Chiavi e valori possono contenere solo lettere minuscole, caratteri numerici, trattini bassi e trattini. Tutti i caratteri devono utilizzare la codifica UTF-8; sono consentiti i caratteri internazionali. Le chiavi devono iniziare con una lettera minuscola o un carattere internazionale.
- La parte della chiave di un'etichetta deve essere univoca all'interno di una singola risorsa. Tuttavia, puoi utilizzare la stessa chiave con più risorse.
Questi limiti si applicano alla chiave e al valore di ogni etichetta e al singolo cluster o job Managed Service per Apache Spark con etichette. Non esiste un limite al numero di etichette che puoi applicare a tutte le risorse all'interno di un progetto.
Utilizzi comuni delle etichette
Ecco alcuni casi d'uso comuni per le etichette:
Etichette di team o centro di costo: aggiungi etichette basate su team o centro di costo per distinguere i cluster e i job Managed Service for Apache Spark di proprietà di team diversi (ad esempio
team:researcheteam:analytics). Puoi utilizzare questo tipo di etichetta per la contabilità dei costi o la definizione del budget.Etichette dei componenti: ad esempio,
component:redis,component:frontend,component:ingestecomponent:dashboard.Etichette di ambiente o fase: ad esempio,
environment:productioneenvironment:test.Etichette di stato: ad esempio,
state:active,state:readytodeleteestate:archive.Etichette di proprietà: utilizzate per identificare i team responsabili delle operazioni, ad esempio:
team:shopping-cart.
Non è consigliabile creare un numero elevato di etichette uniche, ad esempio per timestamp o valori individuali per ogni chiamata API. Il problema di questo approccio è che quando i valori cambiano frequentemente o con chiavi che ingombrano il catalogo, è difficile filtrare e generare report in modo efficace sulle risorse.
Etichette e tag
Le etichette possono essere utilizzate come annotazioni interrogabili per le risorse, ma non possono essere utilizzate per impostare condizioni per i criteri. I tag forniscono un modo per consentire o negare in modo condizionale i criteri a seconda che una risorsa abbia un tag specifico, fornendo un controllo granulare sui criteri. Per saperne di più, consulta la Panoramica dei tag.
Creare e utilizzare le etichette di Managed Service per Apache Spark
Comando gcloud
Puoi specificare una o più etichette da applicare a un cluster o a un job Managed Service per Apache Spark al momento della creazione o dell'invio utilizzando Google Cloud CLI.
gcloud dataproc clusters create args --labels environment=production,customer=acmegcloud dataproc jobs submit args --labels environment=production,customer=acme
Una volta creato un cluster o un job Managed Service per Apache Spark, puoi aggiornare le etichette associate alla risorsa utilizzando Google Cloud CLI.
gcloud dataproc clusters update args --update-labels environment=production,customer=acmegcloud dataproc jobs update args --update-labels environment=production,customer=acme
Allo stesso modo, puoi utilizzare Google Cloud CLI per filtrare le risorse di Managed Service for Apache Spark per etichetta utilizzando
un'espressione di filtro nel seguente formato: labels.<key=value>.
gcloud dataproc clusters list \ --region=region \ --filter="status.state=ACTIVE AND labels.environment=production"gcloud dataproc jobs list \ --region=region \ --filter="status.state=ACTIVE AND labels.customer=acme"
Per ulteriori informazioni sulla scrittura di un'espressione di filtro, consulta la documentazione dell'API Dataproc relativa a clusters.list e jobs.list.
API REST
Le etichette possono essere associate ai cluster o ai job Managed Service per Apache Spark tramite l'API REST Managed Service per Apache Spark. Le API clusters.create e
jobs.submit
possono essere utilizzate per collegare etichette a un cluster o a un job al momento della creazione o dell'invio.
Le API clusters.patch e jobs.patch possono essere utilizzate per modificare le etichette dopo la creazione di un cluster. Di seguito è riportato il corpo JSON di una richiesta cluster.create che include l'assegnazione di un'etichetta
key1:value al cluster.
{
"clusterName":"cluster-1",
"projectId":"my-project",
"config":{
"configBucket":"",
"gceClusterConfig":{
"networkUri":".../networks/default",
"zoneUri":".../zones/us-central1-f"
},
"masterConfig":{
"numInstances":1,
"machineTypeUri":"..../machineTypes/n1-standard-4",
"diskConfig":{
"bootDiskSizeGb":500,
"numLocalSsds":0
}
},
"workerConfig":{
"numInstances":2,
"machineTypeUri":"...machineTypes/n1-standard-4",
"diskConfig":{
"bootDiskSizeGb":500,
"numLocalSsds":0
}
}
},
"labels":{
"key1":"value1"
}
}
Le API clusters.list
e jobs.list
possono essere utilizzate per elencare i cluster o i job che corrispondono a un filtro specificato, utilizzando
il seguente formato: labels.<key=value>.
Ecco una richiesta HTTPS GET di esempio dell'API Dataproc
clusters.list
che specifica un filtro per etichetta key=value. Il chiamante inserisce
project, region, un filtro label-key e label-value e un api-key.
Tieni presente che questa richiesta di esempio è suddivisa in due righe per favorire la leggibilità.
GET https://dataproc.googleapis.com/v1/projects/project/regions/region/clusters? filter=labels.label-key=label-value&key=api-key
Per ulteriori informazioni sulla scrittura di un'espressione di filtro, consulta la documentazione dell'API Dataproc relativa a clusters.list e jobs.list.
Console
Puoi specificare un insieme di etichette da aggiungere a un cluster o a un job Managed Service for Apache Spark al momento della creazione o dell'invio utilizzando la console Google Cloud .
- Aggiungi etichette a un cluster dalla sezione Etichette del pannello Personalizza cluster di Managed Service per Apache Spark nella pagina Crea un cluster.
- Aggiungi etichette a un job dalla pagina Invia un job di Managed Service per Apache Spark.
Una volta creato o inviato un cluster o un job Managed Service per Apache Spark,
puoi aggiornare le etichette associate al cluster o al job. Per aggiornare le etichette,
fai clic sulla casella di selezione di un cluster o un job elencato, poi fai clic su SHOW INFO PANEL. Questo è un esempio della pagina Managed Service per Apache Spark→Elenco cluster.

Una volta visualizzato il riquadro delle informazioni, puoi aggiornare le etichette del cluster o del job Managed Service per Apache Spark. Di seguito è riportato un esempio di aggiornamento delle etichette per un cluster Managed Service per Apache Spark.

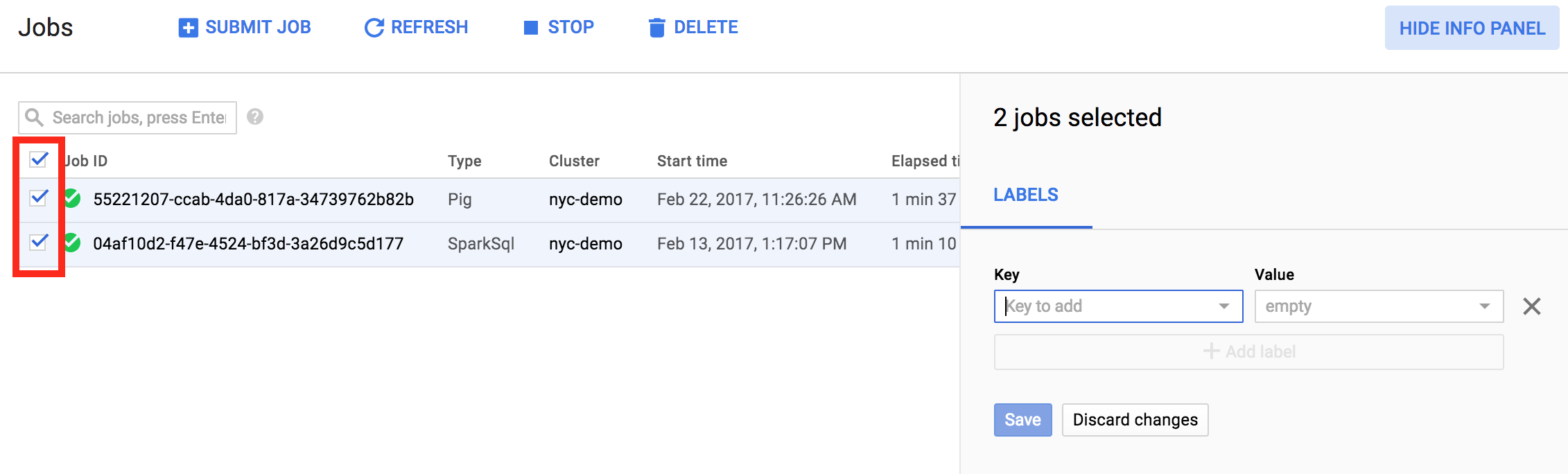
È anche possibile aggiornare le etichette per più elementi in un'unica operazione. In questo esempio, le etichette vengono aggiornate per più job Managed Service per Apache Spark contemporaneamente.
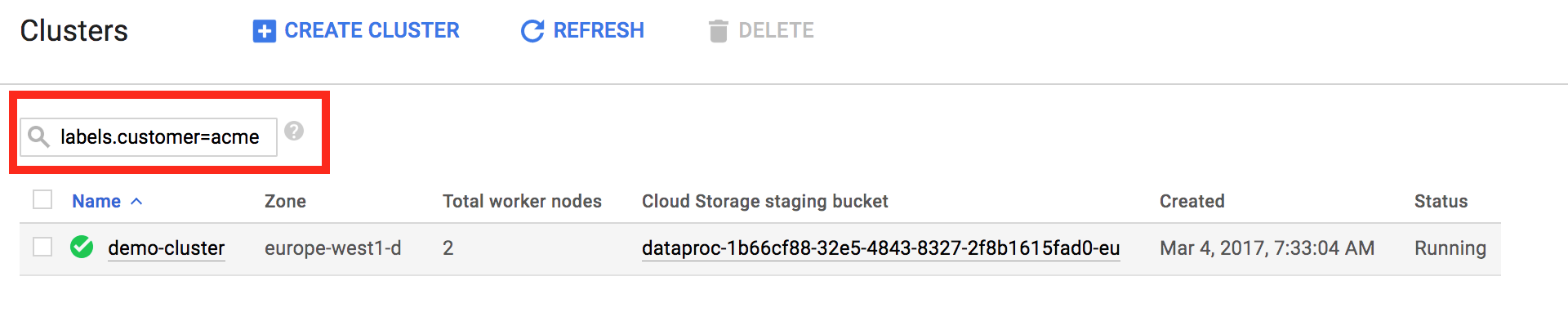
Le etichette ti consentono di filtrare le risorse del servizio gestito per Apache Spark mostrate nelle pagine [Servizio gestito per Apache Spark→Elenca cluster](https://console.cloud.google.com/dataproc/clusters) e [Servizio gestito per Apache Spark→Elenca job](https://console.cloud.google.com/dataproc/jobs). Nella parte superiore della pagina, puoi utilizzare il pattern di ricerca `labels.
Etichette applicate automaticamente
Quando crei o aggiorni un cluster, Managed Service for Apache Spark applica automaticamente diverse etichette al cluster e alle risorse del cluster. Ad esempio,
Managed Service per Apache Spark applica etichette a macchine virtuali, dischi permanenti
e acceleratori quando viene creato un cluster. Le etichette applicate automaticamente hanno un
prefisso speciale goog-dataproc.
Le seguenti etichette goog-dataproc vengono applicate automaticamente alle risorse di Managed Service per Apache Spark. I valori forniti per le etichette riservate
goog-dataproc durante la creazione del cluster sostituiranno
automaticamente i valori forniti. Per questo motivo, non è consigliabile fornire valori personalizzati per queste etichette.
| Etichetta | Descrizione |
|---|---|
goog-dataproc-cluster-name |
Nome del cluster specificato dall'utente |
goog-dataproc-cluster-uuid |
ID cluster univoco |
goog-dataproc-location |
Managed Service per Apache Spark endpoint del cluster regionale |
Puoi utilizzare queste etichette applicate automaticamente in molti modi, tra cui:
- Ricerca e filtro per le risorse di Managed Service per Apache Spark
- Filtrare i dati di fatturazione per calcolare i costi di Managed Service per Apache Spark
Passaggi successivi
Scopri come creare e aggiornare le etichette per i progetti utilizzando Resource Manager.
Scopri come organizzare le risorse utilizzando le etichette.