
Après avoir créé un cluster Managed Service pour Apache Spark, vous pouvez définir sur celui-ci un "scaling", c'est-à-dire l'ajuster en augmentant ou en diminuant le nombre de nœuds de calcul primaires ou secondaires qu'il contient. Vous pouvez procéder au scaling d'un cluster Managed Service pour Apache Spark à n'importe quel moment, même lorsqu'il contient des tâches en cours d'exécution. Vous ne pouvez pas modifier le type de machine d'un cluster existant (scaling vertical). Pour effectuer un scaling vertical, créez un cluster à l'aide d'un type de machine compatible, puis migrez les tâches vers le nouveau cluster.
Vous pouvez procéder au scaling d'un cluster Managed Service pour Apache Spark pour les raisons suivantes :
- Pour augmenter le nombre de nœuds de calcul afin d'accélérer l'exécution d'une tâche.
- Pour diminuer le nombre de nœuds de calcul et faire des économies (consultez notamment la section Mise hors service concertée , ce qui permet de ne pas perdre le travail en cours lors de la réduction de la taille d'un cluster).
- Pour augmenter le nombre de nœuds afin d'étendre l'espace de stockage Hadoop Distributed File System (HDFS) disponible.
Étant donné que les clusters peuvent être mis à l'échelle plusieurs fois, vous pouvez augmenter ou diminuer la taille du cluster une première fois, puis la diminuer ou l'augmenter ultérieurement.
Utiliser le scaling
Vous pouvez procéder au scaling de votre cluster Managed Service pour Apache Spark de trois manières :
- Utilisez l'
gcloudoutil de ligne de commande dans gcloud CLI. - Modifiez la configuration du cluster dans la Google Cloud console.
- Utilisez l'API REST.
Les nœuds de calcul récemment ajoutés à un cluster utiliseront le même type de machine que les nœuds de calcul existants. Par exemple, si un cluster est créé avec des nœuds de calcul utilisant le type de machine n1-standard-8, les nouveaux nœuds de calcul utiliseront également le type de machine n1-standard-8.
Vous pouvez ajuster le nombre de nœuds de calcul primaires, le nombre de nœuds de calcul secondaires (préemptifs), ou les deux. Ainsi, si vous ne modifiez que le nombre de nœuds de calcul préemptifs, le nombre de nœuds de calcul primaires reste inchangé.
gcloud
Pour mettre à l'échelle un cluster avecgcloud dataproc clusters update,
exécutez la commande suivante :
gcloud dataproc clusters update cluster-name \ --region=region \ [--num-workers and/or --num-secondary-workers]=new-number-of-workers
gcloud dataproc clusters update dataproc-1 \
--region=region \
--num-workers=5
...
Waiting on operation [operations/projects/project-id/operations/...].
Waiting for cluster update operation...done.
Updated [https://dataproc.googleapis.com/...].
clusterName: my-test-cluster
...
masterDiskConfiguration:
bootDiskSizeGb: 500
masterName: dataproc-1-m
numWorkers: 5
...
workers:
- my-test-cluster-w-0
- my-test-cluster-w-1
- my-test-cluster-w-2
- my-test-cluster-w-3
- my-test-cluster-w-4
...
API REST
Consultez la page concernant clusters.patch.
Exemple
PATCH /v1/projects/project-id/regions/us-central1/clusters/example-cluster?updateMask=config.worker_config.num_instances,config.secondary_worker_config.num_instances
{
"config": {
"workerConfig": {
"numInstances": 4
},
"secondaryWorkerConfig": {
"numInstances": 2
}
},
"labels": null
}
Console
Une fois le cluster créé, vous pouvez procéder à son scaling en ouvrant sa page Détails du cluster à partir de la Google Cloud console Clusters, puis en cliquant sur le bouton Modifier dans l'onglet Configuration. Renseignez une nouvelle valeur dans les champs Worker nodes (Nœuds de calcul) et/ou
Preemptible worker nodes (Nœuds de calcul préemptifs). Dans la capture d'écran suivante, ces valeurs ont respectivement été mises à jour sur "5" et "2".
Renseignez une nouvelle valeur dans les champs Worker nodes (Nœuds de calcul) et/ou
Preemptible worker nodes (Nœuds de calcul préemptifs). Dans la capture d'écran suivante, ces valeurs ont respectivement été mises à jour sur "5" et "2".
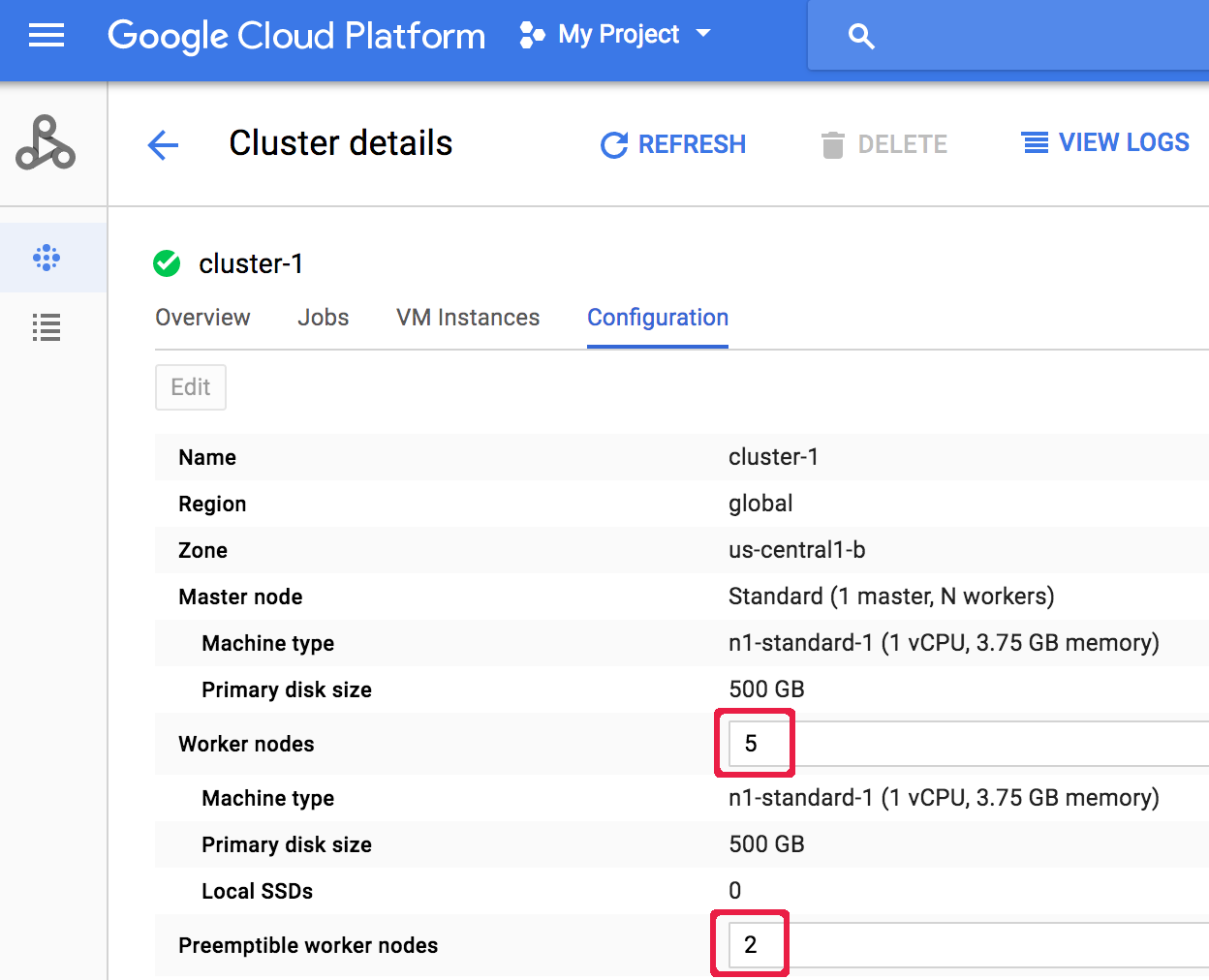 Cliquez sur Enregistrer pour mettre à jour le cluster.
Cliquez sur Enregistrer pour mettre à jour le cluster.
Comment Managed Service pour Apache Spark sélectionne les nœuds de cluster à supprimer
Sur les clusters créés avec les versions d'image 1.5.83+, 2.0.57+, et 2.1.5+, lorsque vous réduisez la taille d'un cluster, Managed Service pour Apache Spark tente de minimiser l'impact de la suppression de nœuds sur les applications YARN en cours d'exécution. Pour ce faire, il supprime d'abord les nœuds inactifs, défectueux et inactifs, puis les nœuds avec le moins de maîtres d'application YARN et de conteneurs en cours d'exécution.
Mise hors service concertée
Lorsque vous réduisez la taille d'un cluster, le travail en cours peut s'arrêter avant la fin. Si vous utilisez Managed Service pour Apache Spark v 1.2 ou une version ultérieure, vous pouvez utiliser la mise hors service concertée, qui intègre la mise hors service concertée des nœuds YARN pour terminer le travail en cours sur un nœud de calcul avant qu'il soit retiré du cluster Cloud Managed Service pour Apache Spark.
Mise hors service concertée et nœuds de calcul secondaires
Le groupe de nœuds de calcul préemptifs (secondaires) continue de provisionner ou de supprimer des nœuds de calcul pour atteindre la taille souhaitée, même après qu'une opération de scaling de cluster a été marquée comme étant terminée. Si vous tentez une mise hors service concertée sur un nœud de calcul secondaire
et que vous recevez un message d'erreur semblable au suivant :
"Le groupe de nœuds de calcul secondaires
ne peut pas être modifié en dehors de Managed Service pour Apache Spark. Si vous avez récemment créé ou mis à jour ce cluster, attendez quelques minutes avant de procéder à une mise hors service concertée, afin de permettre à toutes les instances secondaires de rejoindre ou de quitter le cluster.
Taille attendue du groupe de nœuds de calcul secondaires : x, taille réelle : y",
attendez quelques minutes, puis répétez la demande de mise hors service concertée.
Utiliser la mise hors service concertée
La mise hors service concertée Managed Service pour Apache Spark intègre la mise hors service concertée des nœuds YARN pour terminer le travail en cours sur un nœud de calcul avant qu'il ne soit supprimé du cluster Cloud Managed Service pour Apache Spark. Par défaut, la mise hors service concertée est désactivée. Vous pouvez l'activer en définissant un délai avant expiration lorsque vous mettez à jour votre cluster dans le but de le délester d'un ou plusieurs nœuds de calcul.
gcloud
Lorsque vous mettez à jour un cluster dans le but de supprimer un ou plusieurs nœuds de calcul, exécutez la commande gcloud dataproc clusters update avec l'option--graceful-decommission-timeout. Les valeurs du délai (chaîne) peuvent être définies sur "0s" (la valeur par défaut ; mise hors service forcée, et non concertée) ou sur une durée positive exprimée par rapport à l'heure actuelle (par exemple, "3s").
La durée maximale est d'1 jour.
gcloud dataproc clusters update cluster-name \ --region=region \ --graceful-decommission-timeout="timeout-value" \ [--num-workers and/or --num-secondary-workers]=decreased-number-of-workers \ ... other args ...
API REST
Consultez la section concernant clusters.patch.gracefulDecommissionTimeout. Les valeurs du délai (chaîne) peuvent être définies sur "0" (la valeur par défaut ; mise hors service forcée, et non concertée) ou sur une durée en secondes (par exemple, "3s"). La durée maximale est d'1 jour.Console
Une fois le cluster créé, vous pouvez sélectionner la mise hors service concertée d'un cluster en ouvrant la page Cluster details (Détails du cluster) des Clusters dans la Google Cloud console, puis cliquez sur le bouton Edit (Modifier) dans l'onglet Configuration.
Dans la section Graceful Decommissioning (Mise hors service concertée), sélectionnez
Use graceful decommissioning (Utiliser la mise hors service concertée), puis sélectionnez une valeur pour le délai.
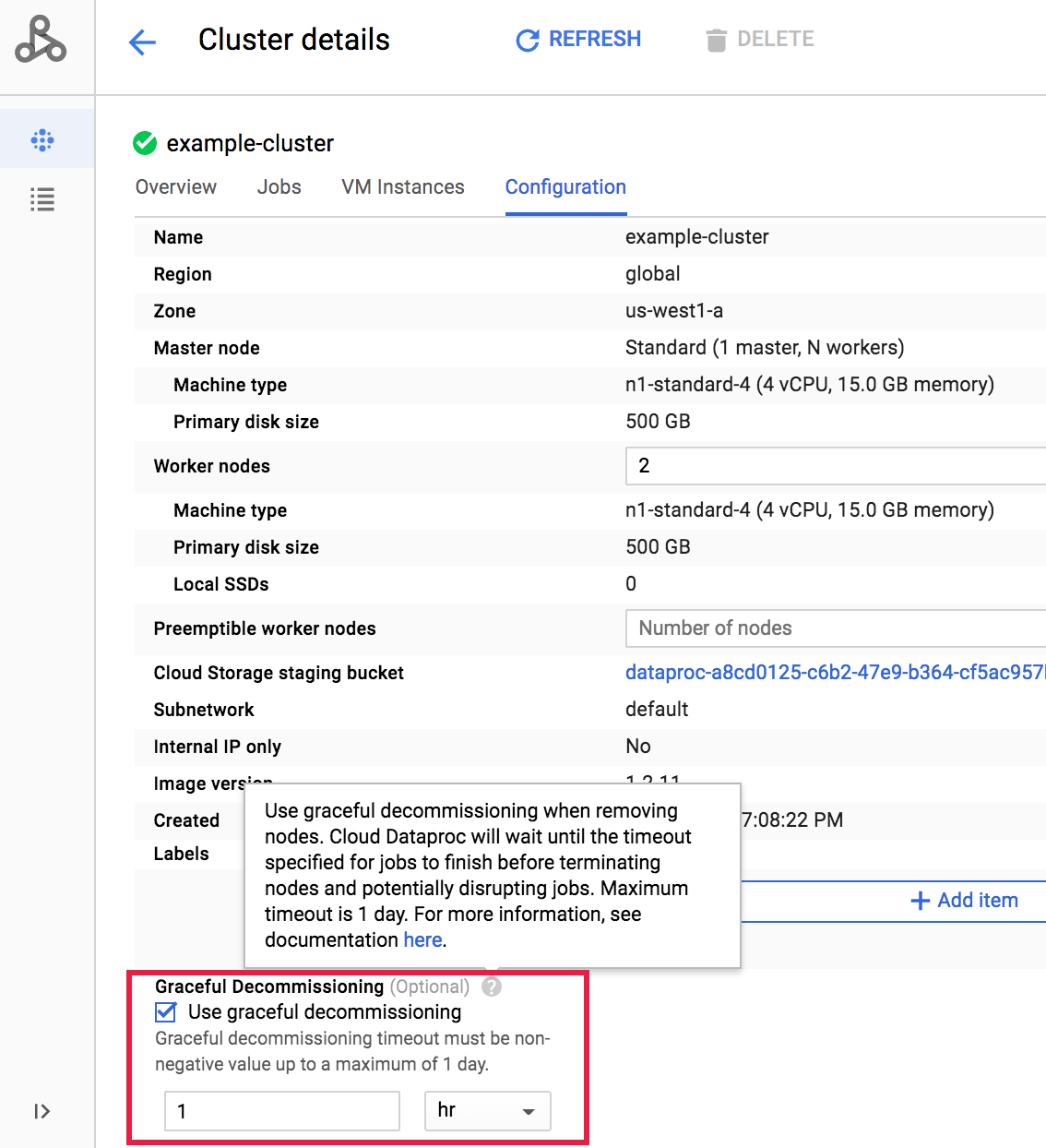 Cliquez sur Enregistrer pour mettre à jour le cluster.
Cliquez sur Enregistrer pour mettre à jour le cluster.
Annuler une opération de réduction de taille avec mise hors service concertée
Sur les clusters Managed Service pour Apache Spark créés avec les versions d'image
2.0.57+
ou 2.1.5+,
vous pouvez exécuter la gcloud dataproc operations cancel
commande ou envoyer une requête operations.cancel
à l'API Managed Service pour Apache Spark pour annuler une opération de réduction de taille avec mise hors service concertée.
Lorsque vous annulez une opération de réduction de taille avec mise hors service concertée :
Les nœuds de calcul à l'état
DECOMMISSIONINGsont remis en service et passent à l'étatACTIVEune fois l'annulation de l'opération terminée.Si l'opération de réduction de taille inclut des mises à jour de libellés, il est possible que ces mises à jour ne soient pas appliquées.
Pour vérifier l'état de la requête d'annulation, vous pouvez
exécuter la gcloud dataproc operations describe
commande ou envoyer une requête à l'API Managed Service pour Apache Spark
operations.get. Si l'opération d'annulation aboutit, l'état de l'opération interne est marqué comme CANCELLED.