
En este documento, se muestra cómo habilitar Lightning Engine para acelerar las cargas de trabajo por lotes y las sesiones interactivas de Managed Service para Apache Spark.
Descripción general
Lightning Engine es un acelerador de consultas de alto rendimiento que cuenta con un motor de optimización multicapa que realiza técnicas de optimización habituales, como optimizaciones de consultas y de ejecución, además de optimizaciones seleccionadas en la capa del sistema de archivos y los conectores de acceso a los datos.
Como se muestra en la siguiente ilustración, Lightning Engine acelera el rendimiento de la ejecución de consultas de Spark en una carga de trabajo similar a TPC-H (tamaño del conjunto de datos de 10 TB).
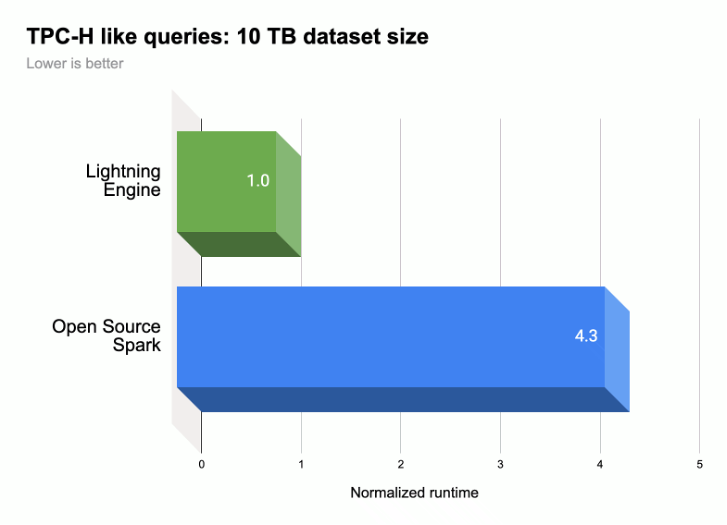
Para obtener más información, consulta Presentamos Lightning Engine, la nueva generación de rendimiento de Apache Spark.
Disponibilidad de Lightning Engine
- Lightning Engine está disponible para usarse con el entorno de ejecución 2.3 de Managed Service para Apache Spark.
- Lightning Engine solo está disponible con el nivel de precios premium de Managed Service para Apache Spark.
- Cargas de trabajo por lotes: Lightning Engine se habilita automáticamente para las cargas de trabajo por lotes en el nivel premium. No es necesario que realices ninguna acción.
- Sesiones interactivas: Lightning Engine no está habilitado de forma predeterminada para las sesiones interactivas. Para habilitarlo, consulta Habilitar Lightning Engine.
- Plantillas de sesión: Lightning Engine no está habilitado de forma predeterminada para las plantillas de sesión. Para habilitarlo, consulta Habilitar Lightning Engine.
Habilitar Lightning Engine
En las siguientes secciones, se muestra cómo habilitar el motor de Lightning en una carga de trabajo por lotes, una plantilla de sesión y una sesión interactiva de Managed Service para Apache Spark.
Carga de trabajo por lotes
Habilita Lightning Engine en una carga de trabajo por lotes
Puedes usar la Google Cloud consola, Google Cloud CLI o la API de Dataproc para habilitar Lightning Engine en una carga de trabajo por lotes.
Console
Usa la consola de Google Cloud para habilitar Lightning Engine en una carga de trabajo por lotes.
En la consola de Google Cloud , haz lo siguiente:
- Ve a Managed Service para Apache Spark Batches.
- Haz clic en Crear para abrir la página Crear lote.
Selecciona y completa los siguientes campos:
- Contenedor:
- Versión del entorno de ejecución: Selecciona
2.3.
- Versión del entorno de ejecución: Selecciona
Configuración del nivel:
- Selecciona
Premium. Esto habilita y verifica automáticamente la opción "Habilitar LIGHTNING ENGINE para acelerar el rendimiento de Spark".
Cuando seleccionas el nivel Premium, el Nivel de procesamiento del controlador y el Nivel de procesamiento del ejecutor se establecen en
Premium. Estos parámetros de configuración de procesamiento de nivel premium establecidos automáticamente no se pueden anular para los lotes que usan tiempos de ejecución anteriores a3.0.Puedes configurar el nivel de disco del controlador y el nivel de disco del ejecutor en
Premiumo dejarlos en su valor predeterminado de nivelStandard. Si eliges un nivel de disco Premium, debes seleccionar el tamaño del disco. Para obtener más información, consulta las propiedades de asignación de recursos.- Selecciona
Propiedades: Opcional: Ingresa el siguiente par
Key(nombre de la propiedad) yValuesi deseas seleccionar el tiempo de ejecución de Native Query Execution:Clave Valor spark.dataproc.lightningEngine.runtimenativo/nativa/indígena/aborigen
- Contenedor:
Completa, selecciona o confirma otros parámetros de configuración de las cargas de trabajo por lotes. Consulta Envía una carga de trabajo por lotes de Spark.
Haz clic en Enviar para ejecutar la carga de trabajo por lotes de Spark.
gcloud
Configura las siguientes marcas del comando gcloud dataproc batches submit spark de gcloud CLI para habilitar un Lightning Engine en una carga de trabajo por lotes.
gcloud dataproc batches submit spark \ --project=PROJECT_ID \ --region=REGION \ --version=2.3 \ --properties=dataproc.tier=premium \ OTHER_FLAGS_AS_NEEDED
Notas:
- PROJECT_ID: Es el ID del proyecto de Google Cloud . Los IDs de los proyectos se enumeran en la sección Información del proyecto del panel de la consola de Google Cloud .
- REGION: Es una región de Compute Engine disponible para ejecutar la carga de trabajo.
--properties=dataproc.tier=premium. Si estableces el nivel premium, se configuran automáticamente las siguientes propiedades en la carga de trabajo por lotes:spark.dataproc.engine=lightningEngineselecciona Lightning Engine para la carga de trabajo por lotes.spark.dataproc.driver.compute.tieryspark.dataproc.executor.compute.tierse configuran comopremium(consulta las propiedades de asignación de recursos). Estos parámetros de configuración de procesamiento de nivel premium establecidos automáticamente no se pueden anular para los lotes que usan tiempos de ejecución anteriores a3.0.
Otras propiedades
Native Query Engine:
spark.dataproc.lightningEngine.runtime=nativeAgrega esta propiedad si deseas seleccionar el tiempo de ejecución de Native Query Execution.Niveles y tamaños de disco: De forma predeterminada, los tamaños de disco del controlador y del ejecutor se establecen en niveles y tamaños de
standard. Puedes agregar propiedades para seleccionar niveles y tamaños de discopremium(en múltiplos de375 GiB).
Para obtener más información, consulta propiedades de asignación de recursos.
OTHER_FLAGS_AS_NEEDED: Consulta Envía una carga de trabajo por lotes de Spark.
API
Para habilitar Lightning Engine en una carga de trabajo por lotes, como parte de tu solicitud batches.create, haz lo siguiente:
- Establece RuntimeConfig.version en
2.3. Agrega "dataproc.tier":"premium" a RuntimeConfig.properties. Establecer el nivel premium configura automáticamente las siguientes propiedades en la carga de trabajo por lotes:
spark.dataproc.engine=lightningEngineselecciona Lightning Engine para la carga de trabajo por lotes.spark.dataproc.driver.compute.tieryspark.dataproc.executor.compute.tierse configuran comopremium(consulta las propiedades de asignación de recursos). Estos parámetros de configuración de procesamiento de nivel premium establecidos automáticamente no se pueden anular para los lotes que usan tiempos de ejecución anteriores a3.0.
Otros RuntimeConfig.properties:
Native Query Engine:
spark.dataproc.lightningEngine.runtime:native. Agrega esta propiedad si deseas seleccionar el entorno de ejecución de Native Query Execution.Niveles y tamaños de disco: De forma predeterminada, los tamaños de disco del controlador y del ejecutor se establecen en niveles y tamaños de
standard. Puedes agregar propiedades para seleccionar niveles y tamaños depremium(en múltiplos depremium).
Para obtener más información, consulta propiedades de asignación de recursos.375 GiB
Consulta Envía una carga de trabajo por lotes de Spark para configurar otros campos de la API de carga de trabajo por lotes.
Plantilla de sesión
Habilita Lightning Engine en una plantilla de sesión
Puedes usar la consola de Google Cloud , Google Cloud CLI o la API de Dataproc para habilitar Lightning Engine en una plantilla de sesión para una sesión de Jupyter o Spark Connect.
Console
Usa la consola de Google Cloud para habilitar Lightning Engine en una carga de trabajo por lotes.
En la consola de Google Cloud , haz lo siguiente:
- Ve a Plantillas de sesiones de Managed Service para Apache Spark.
- Haz clic en Crear para abrir la página Crear plantilla de sesión.
Selecciona y completa los siguientes campos:
- Información de la plantilla de sesión:
- Selecciona “Habilitar Lightning Engine para acelerar el rendimiento de Spark”.
- Configuración de ejecución:
- Versión del entorno de ejecución: Selecciona
2.3.
- Versión del entorno de ejecución: Selecciona
Propiedades: Ingresa los siguientes pares de
Key(nombre de la propiedad) yValuepara seleccionar el nivel Premium:Clave Valor dataproc.tierpremium spark.dataproc.enginelightningEngine Opcional: Ingresa el siguiente par de
Key(nombre de la propiedad) yValuepara seleccionar el tiempo de ejecución de Native Query Execution:Clave Valor spark.dataproc.lightningEngine.runtimenative
- Información de la plantilla de sesión:
Completa, selecciona o confirma otros parámetros de configuración de la plantilla de sesión. Consulta Crea una plantilla de sesión.
Haz clic en Enviar para crear la plantilla de sesión.
gcloud
No puedes crear directamente una plantilla de sesión de Managed Service para Apache Spark con gcloud CLI. En cambio, puedes usar el comando gcloud beta dataproc session-templates import para importar una plantilla de sesión existente, editar la plantilla importada para habilitar Lightning Engine y, de manera opcional, el entorno de ejecución de Native Query, y, luego, exportar la plantilla editada con el comando gcloud beta dataproc session-templates export.
API
Para habilitar Lightning Engine en una plantilla de sesión, como parte de tu solicitud sessionTemplates.create, haz lo siguiente:
- Establece RuntimeConfig.version en
2.3. - Agrega "dataproc.tier":"premium" y "spark.dataproc.engine":"lightningEngine" a RuntimeConfig.properties.
Otros RuntimeConfig.properties:
- Native Query Engine:
spark.dataproc.lightningEngine.runtime:native: Agrega esta propiedad a RuntimeConfig.properties para seleccionar el entorno de ejecución de Native Query Execution.
Consulta Crea una plantilla de sesión para configurar otros campos de la API de plantilla de sesión.
Sesión interactiva
Habilita Lightning Engine en una sesión interactiva
Puedes usar Google Cloud CLI o la API de Dataproc para habilitar Lightning Engine en una sesión interactiva de Managed Service para Apache Spark. También puedes habilitar Lightning Engine en una sesión interactiva en un notebook de BigQuery Studio.
gcloud
Configura las siguientes marcas del comando gcloud beta dataproc sessions create spark de gcloud CLI para habilitar Lightning Engine en una sesión interactiva.
gcloud beta dataproc sessions create spark \ --project=PROJECT_ID \ --location=REGION \ --version=2.3 \ --properties=dataproc.tier=premium,spark.dataproc.engine=lightningEngine \ OTHER_FLAGS_AS_NEEDED
Notas:
- PROJECT_ID: Es el ID del proyecto de Google Cloud . Los IDs de los proyectos se enumeran en la sección Información del proyecto del panel de la consola de Google Cloud .
- REGION: Es una región de Compute Engine disponible para ejecutar la carga de trabajo.
--properties=dataproc.tier=premium,spark.dataproc.engine=lightningEngine. Estas propiedades habilitan Lightning Engine en la sesión.Otras propiedades:
- Native Query Engine:
spark.dataproc.lightningEngine.runtime=native: Agrega esta propiedad para seleccionar el tiempo de ejecución de Native Query Execution.
- Native Query Engine:
OTHER_FLAGS_AS_NEEDED: Consulta Cómo crear una sesión interactiva.
API
Para habilitar Lightning Engine en una sesión, como parte de tu solicitud sessions.create, haz lo siguiente:
- Establece RuntimeConfig.version en
2.3. - Agrega "dataproc.tier":"premium" y "spark.dataproc.engine":"lightningEngine" a RuntimeConfig.properties.
Otro RuntimeConfig.properties:
- Native Query Engine:
spark.dataproc.lightningEngine.runtime:native: Agrega esta propiedad a RuntimeConfig.properties si deseas seleccionar el tiempo de ejecución de Native Query Execution.
Consulta Cómo crear una sesión interactiva para configurar otros campos de la API de plantillas de sesión.
Notebook de BigQuery
Puedes habilitar Lightning Engine cuando creas una sesión en un notebook de PySpark de BigQuery Studio.
from google.cloud.dataproc_spark_connect import DataprocSparkSession
from google.cloud.dataproc_v1 import Session
session = Session()
# Enable Lightning Engine.
session.runtime_config.properties["version"] = "2.3"
session.runtime_config.properties["dataproc.tier"] = "premium"
session.runtime_config.properties["spark.dataproc.engine"] = "lightningEngine"
# Enable THE Native Query Execution runtime.
session.runtime_config.properties["spark.dataproc.lightningEngine.runtime"] = "native"
# Create the Spark session.
spark = (
DataprocSparkSession.builder
.appName("APP_NAME")
.dataprocSessionConfig(session)
.getOrCreate())
# Add Spark application code here:
Verifica la configuración de Lightning Engine
Puedes usar la Google Cloud consola, Google Cloud CLI o la API de Dataproc para verificar la configuración de Lightning Engine en una carga de trabajo por lotes, una plantilla de sesión o una sesión interactiva.
Carga de trabajo por lotes
Para verificar que el nivel de procesamiento por lotes esté configurado como
premiumy que el motor esté configurado comoLightning Engine, haz lo siguiente:- Consola deGoogle Cloud : En la página Lotes, consulta las columnas Nivel y Motor del lote. También puedes hacer clic en el ID de lote para ver estos parámetros de configuración en la página de detalles del lote.
- Gcloud CLI: Ejecuta el comando
gcloud dataproc batches describe. - API: Envía una solicitud
batches.get.
Plantilla de sesión
Para verificar que engine esté configurado como
Lightning Enginepara una plantilla de sesión, haz lo siguiente:- Consola deGoogle Cloud : En la página Plantillas de sesión, consulta la columna Motor de tu plantilla. También puedes hacer clic en el Nombre de la plantilla de sesión para ver este parámetro de configuración en la página de detalles de la plantilla de sesión.
- Gcloud CLI: Ejecuta el comando
gcloud beta dataproc session-templates describe. - API: Envía una solicitud
sessionTemplates.get.
Sesión interactiva
El motor se establece en
Lightning Enginepara una sesión interactiva:- Consola deGoogle Cloud : En la página Sesiones interactivas, consulta la columna Motor de la plantilla. También puedes hacer clic en el ID de sesión interactiva para ver este parámetro de configuración en la página de detalles de la plantilla de sesión.
- Gcloud CLI: Ejecuta el comando
gcloud beta dataproc sessions describe. - API: Envía una solicitud
sessions.get.
Ejecución de consultas nativas
La ejecución de consultas nativas (NQE) es una función opcional de Lightning Engine que mejora el rendimiento a través de una implementación nativa basada en Apache Gluten y Velox, diseñada para el hardware de Google.
El tiempo de ejecución de Native Query Execution incluye una administración de memoria unificada para el cambio dinámico entre la memoria fuera del heap y la memoria en el heap sin necesidad de cambiar la configuración existente de Spark. El NQE incluye compatibilidad expandida para operadores, funciones y tipos de datos de Spark, así como inteligencia para identificar automáticamente oportunidades para usar el motor nativo en operaciones de envío óptimas.
Identifica las cargas de trabajo de ejecución de consultas nativas
Usa la ejecución de consultas nativas en los siguientes casos:
APIs de DataFrame de Spark, APIs de Dataset de Spark y consultas de Spark SQL que leen datos de archivos Parquet y ORC El formato del archivo de salida no afecta el rendimiento de la ejecución de consultas nativas.
Son las cargas de trabajo recomendadas por la herramienta de calificación de ejecución de consultas nativas.
No se recomienda la ejecución de consultas nativas para cargas de trabajo con entradas de los siguientes tipos de datos:
- Byte: ORC y Parquet
- Marca de tiempo: ORC
- Struct, Array, Map: Parquet
Limitaciones de la ejecución de consultas nativas
Habilitar la ejecución de consultas nativas en las siguientes situaciones puede provocar excepciones, incompatibilidades con Spark o que la carga de trabajo recurra al motor de Spark predeterminado.
Resguardos
La ejecución de consultas nativas en la siguiente ejecución puede provocar una reversión de la carga de trabajo al motor de ejecución de Spark, lo que genera una regresión o una falla.
ANSI: Si el modo ANSI está habilitado, la ejecución se revierte a Spark.
Modo que distingue mayúsculas de minúsculas: La ejecución de consultas nativas solo admite el modo predeterminado de Spark que no distingue mayúsculas de minúsculas. Si el modo sensible a mayúsculas está habilitado, se pueden producir resultados incorrectos.
Análisis de tabla particionada: La ejecución de consultas nativas admite el análisis de tablas particionadas solo cuando la ruta contiene la información de partición. De lo contrario, la carga de trabajo recurre al motor de ejecución de Spark.
Comportamiento incompatible
El uso de la ejecución de consultas nativas puede generar un comportamiento incompatible o resultados incorrectos en los siguientes casos:
Funciones JSON: La ejecución de consultas nativas admite cadenas entre comillas dobles, no comillas simples. Los resultados incorrectos se producen con comillas simples. Usar "*" en la ruta de acceso con la función
get_json_objectdevuelveNULL.Configuración de lectura de Parquet:
- La ejecución de consultas nativas trata
spark.files.ignoreCorruptFilescomo si estuviera configurado en el valor predeterminadofalse, incluso cuando se establece entrue. - La ejecución de consultas nativas ignora
spark.sql.parquet.datetimeRebaseModeInReady solo devuelve el contenido del archivo Parquet. No se consideran las diferencias entre el calendario híbrido heredado (juliano gregoriano) y el calendario gregoriano proléptico. Los resultados de Spark pueden variar.
- La ejecución de consultas nativas trata
NaN: No compatible. Por ejemplo, pueden producirse resultados inesperados cuando se usaNaNen una comparación numérica.Lectura columnar de Spark: Se puede producir un error fatal, ya que el vector columnar de Spark no es compatible con la ejecución de consultas nativas.
Volcado: Cuando las particiones de la mezcla se establecen en una cantidad grande, la función de volcado en disco puede activar un
OutOfMemoryException. Si esto ocurre, reducir la cantidad de particiones puede eliminar esta excepción.