
Este documento mostra como ativar o Lightning Engine para acelerar as cargas de trabalho em lote e as sessões interativas do Serverless for Apache Spark.
Vista geral
O Lightning Engine é um acelerador de consultas de elevado desempenho com tecnologia de um motor de otimização de várias camadas que executa técnicas de otimização habituais, como otimizações de consultas e de execução, bem como otimizações organizadas na camada do sistema de ficheiros e nos conetores de acesso aos dados.
Conforme mostrado na ilustração seguinte, o Lightning Engine acelera o desempenho da execução de consultas do Spark numa carga de trabalho semelhante ao TPC-H (tamanho do conjunto de dados 10 TB).
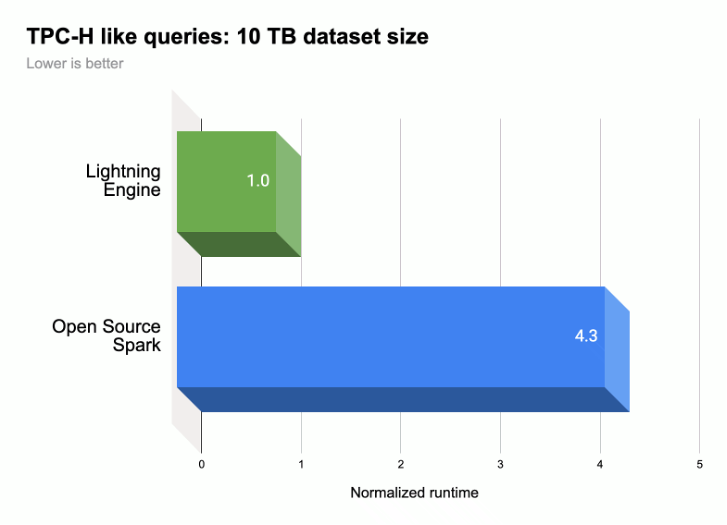
Para mais informações, consulte o artigo Apresentamos o Lightning Engine: a próxima geração do desempenho do Apache Spark.
Disponibilidade do Lightning Engine
- O Lightning Engine está disponível para utilização com o tempo de execução sem servidor para Apache Spark 2.3.
- O Lightning Engine só está disponível com o nível de preços premium do Serverless para Apache Spark.
- Cargas de trabalho em lote: o Lightning Engine é ativado automaticamente para cargas de trabalho em lote no nível premium. Não é necessária qualquer ação da sua parte.
- Sessões interativas: o motor Lightning não está ativado por predefinição para sessões interativas. Para a ativar, consulte o artigo Ative o Lightning Engine.
- Modelos de sessões: o motor Lightning não está ativado por predefinição para modelos de sessões. Para a ativar, consulte o artigo Ative o Lightning Engine.
Ative o Lightning Engine
As secções seguintes mostram como ativar o motor Lightning numa carga de trabalho em lote Serverless para Apache Spark, num modelo de sessão e numa sessão interativa.
Carga de trabalho em lote
Ative o Lightning Engine numa carga de trabalho em lote
Pode usar a Google Cloud consola, a CLI do Google Cloud ou a API Dataproc para ativar o Lightning Engine numa carga de trabalho em lote.
Consola
Use a Google Cloud consola para ativar o Lightning Engine numa carga de trabalho em lote.
Na Google Cloud consola:
- Aceda a Lotes do Dataproc.
- Clique em Criar para abrir a página Criar lote.
Selecione e preencha os seguintes campos:
- Contentor:
- Versão do tempo de execução: selecione
2.3.
- Versão do tempo de execução: selecione
Configuração do nível:
- Selecione
Premium. Isto ativa e seleciona automaticamente a opção "Ativar o MOTOR LIGHTNING para acelerar o desempenho do Spark".
Quando seleciona o nível premium, o Nível de computação do controlador e o Nível de computação do executor são definidos como
Premium. Não é possível substituir estas definições de computação de nível premium definidas automaticamente para lotes que usam tempos de execução anteriores a3.0.Pode configurar o nível do disco do controlador e o nível do disco do executor para
Premiumou deixá-los no respetivo valor de nívelStandardpredefinido. Se escolher um nível de disco premium, tem de selecionar o tamanho do disco. Para mais informações, consulte as propriedades de atribuição de recursos.- Selecione
Propriedades: opcional: introduza o seguinte par
Key(nome da propriedade) eValuese quiser selecionar o tempo de execução Native Query Execution:Chave Valor spark.dataproc.lightningEngine.runtimenativo/nativa
- Contentor:
Preencha, selecione ou confirme outras definições de cargas de trabalho em lote. Consulte Envie uma carga de trabalho em lote do Spark.
Clique em Enviar para executar a carga de trabalho em lote do Spark.
gcloud
Defina as seguintes flags de comando da CLI gcloud
gcloud dataproc batches submit spark
para ativar um Lightning Engine numa carga de trabalho em lote.
gcloud dataproc batches submit spark \ --project=PROJECT_ID \ --region=REGION \ --version=2.3 \ --properties=dataproc.tier=premium \ OTHER_FLAGS_AS_NEEDED
Notas:
- PROJECT_ID: o ID do seu Google Cloud projeto. Os IDs dos projetos estão listados na secção Informações do projeto no Google Cloud painel de controlo da consola.
- REGION: Uma região do Compute Engine disponível para executar a carga de trabalho.
--properties=dataproc.tier=premium. A definição do nível premium define automaticamente as seguintes propriedades na carga de trabalho em lote:spark.dataproc.engine=lightningEngineseleciona o Lightning Engine para a carga de trabalho em lote.spark.dataproc.driver.compute.tierespark.dataproc.executor.compute.tierestão definidos comopremium(consulte as propriedades de atribuição de recursos). Não é possível substituir estas definições de computação de nível premium definidas automaticamente para lotes que usam tempos de execução anteriores a3.0.
Outras propriedades
Native Query Engine:
spark.dataproc.lightningEngine.runtime=nativeadicione esta propriedade se quiser selecionar o tempo de execução da execução de consultas nativas.Níveis e tamanhos de disco: por predefinição, os tamanhos dos discos do controlador e do executor são definidos para
standardníveis e tamanhos. Pode adicionar propriedades para selecionarpremiumníveis e tamanhos de discos (em múltiplos de375 GiB).
Para mais informações, consulte as propriedades de atribuição de recursos.
OTHER_FLAGS_AS_NEEDED: consulte o artigo Envie uma carga de trabalho em lote do Spark.
API
Para ativar o Lightning Engine numa carga de trabalho em lote, como parte do seu pedido batches.create:
- Defina RuntimeConfig.version
como
2.3. Adicione "dataproc.tier":"premium" a RuntimeConfig.properties A definição do nível premium define automaticamente as seguintes propriedades na carga de trabalho em lote:
spark.dataproc.engine=lightningEngineseleciona o Lightning Engine para a carga de trabalho em lote.spark.dataproc.driver.compute.tierespark.dataproc.executor.compute.tierestão definidos comopremium(consulte as propriedades de atribuição de recursos). Não é possível substituir estas definições de computação de nível premium definidas automaticamente para lotes que usam tempos de execução anteriores ao3.0.
Outro RuntimeConfig.properties:
Motor de consultas nativo:
spark.dataproc.lightningEngine.runtime:native. Adicione esta propriedade se quiser selecionar o tempo de execução de Execução de consultas nativas.Níveis e tamanhos de disco: por predefinição, os tamanhos dos discos do controlador e do executor são definidos para
standardníveis e tamanhos. Pode adicionar propriedades para selecionarpremiumníveis e tamanhos (em múltiplos de375 GiB).
Para mais informações, consulte as propriedades de atribuição de recursos.
Consulte o artigo Envie uma carga de trabalho em lote do Spark para definir outros campos da API de carga de trabalho em lote.
Modelo de sessão
Ative o motor Lightning num modelo de sessão
Pode usar a Google Cloud consola, a CLI do Google Cloud ou a API Dataproc para ativar o Lightning Engine num modelo de sessão para uma sessão do Jupyter ou do Spark Connect.
Consola
Use a Google Cloud consola para ativar o Lightning Engine numa carga de trabalho em lote.
Na Google Cloud consola:
- Aceda aos modelos de sessão do Dataproc.
- Clique em Criar para abrir a página Criar modelo de sessão.
Selecione e preencha os seguintes campos:
- Informações do modelo de sessão:
- Selecione "Ativar o motor Lightning para acelerar o desempenho do Spark".
- Configuração de execução:
- Versão do tempo de execução: selecione
2.3.
- Versão do tempo de execução: selecione
Propriedades: Introduza os seguintes pares
Key(nome da propriedade) eValuepara selecionar o nível Premium:Chave Valor dataproc.tierpremium spark.dataproc.enginelightningEngine Opcional: introduza o par
Key(nome da propriedade)Valueseguinte para selecionar o tempo de execução da execução de consultas nativas:Chave Valor spark.dataproc.lightningEngine.runtimenative
- Informações do modelo de sessão:
Preencha, selecione ou confirme outras definições do modelo de sessão. Consulte o artigo Crie um modelo de sessão.
Clique em Enviar para criar o modelo de sessão.
gcloud
Não pode criar diretamente um modelo de sessão do Serverless para Apache Spark através da CLI gcloud. Em alternativa, pode usar o comando gcloud beta dataproc session-templates import para importar um modelo de sessão existente, editar o modelo importado para ativar o Lightning Engine e, opcionalmente, o tempo de execução de consultas nativas e, em seguida, exportar o modelo editado através do comando gcloud beta dataproc session-templates export.
API
Para ativar o Lightning Engine num modelo de sessão, como parte do seu pedido sessionTemplates.create:
- Defina RuntimeConfig.version
como
2.3. - Adicione "dataproc.tier":"premium" e "spark.dataproc.engine":"lightningEngine" a RuntimeConfig.properties.
Outro RuntimeConfig.properties:
- Motor de consultas nativo:
spark.dataproc.lightningEngine.runtime:native: adicione esta propriedade a RuntimeConfig.properties para selecionar o tempo de execução de execução de consultas nativas.
Consulte o artigo Crie um modelo de sessão para definir outros campos da API do modelo de sessão.
Sessão interativa
Ative o Lightning Engine numa sessão interativa
Pode usar a CLI do Google Cloud ou a API Dataproc para ativar o Lightning Engine numa sessão interativa do Serverless para Apache Spark. Também pode ativar o Lightning Engine numa sessão interativa num bloco de notas do BigQuery Studio.
gcloud
Defina as seguintes flags de comando da CLI gcloud
gcloud beta dataproc sessions create spark
para ativar o Lightning Engine numa sessão interativa.
gcloud beta dataproc sessions create spark \ --project=PROJECT_ID \ --location=REGION \ --version=2.3 \ --properties=dataproc.tier=premium,spark.dataproc.engine=lightningEngine \ OTHER_FLAGS_AS_NEEDED
Notas:
- PROJECT_ID: o ID do seu Google Cloud projeto. Os IDs dos projetos estão listados na secção Informações do projeto no Google Cloud painel de controlo da consola.
- REGION: Uma região do Compute Engine disponível para executar a carga de trabalho.
--properties=dataproc.tier=premium,spark.dataproc.engine=lightningEngine. Estas propriedades ativam o Lightning Engine na sessão.Outras propriedades:
- Native Query Engine:
spark.dataproc.lightningEngine.runtime=native: adicione esta propriedade para selecionar o tempo de execução da execução de consultas nativas.
- Native Query Engine:
OTHER_FLAGS_AS_NEEDED: consulte o artigo Crie uma sessão interativa.
API
Para ativar o Lightning Engine numa sessão, como parte do seu pedido sessions.create:
- Defina RuntimeConfig.version
como
2.3. - Adicione "dataproc.tier":"premium" e "spark.dataproc.engine":"lightningEngine" a RuntimeConfig.properties.
Outro RuntimeConfig.properties:
- Native Query Engine:
spark.dataproc.lightningEngine.runtime:native: adicione esta propriedade a RuntimeConfig.properties se quiser selecionar o tempo de execução Native Query Execution.
Consulte o artigo Crie uma sessão interativa para definir outros campos da API de modelos de sessões.
Bloco de notas do BigQuery
Pode ativar o Lightning Engine quando cria uma sessão num notebook PySpark do BigQuery Studio.
from google.cloud.dataproc_spark_connect import DataprocSparkSession
from google.cloud.dataproc_v1 import Session
session = Session()
# Enable Lightning Engine.
session.runtime_config.properties["version"] = "2.3"
session.runtime_config.properties["dataproc.tier"] = "premium"
session.runtime_config.properties["spark.dataproc.engine"] = "lightningEngine"
# Enable THE Native Query Execution runtime.
session.runtime_config.properties["spark.dataproc.lightningEngine.runtime"] = "native"
# Create the Spark session.
spark = (
DataprocSparkSession.builder
.appName("APP_NAME")
.dataprocSessionConfig(session)
.getOrCreate())
# Add Spark application code here:
Verifique as definições do Lightning Engine
Pode usar a Google Cloud consola, a CLI do Google Cloud ou a API Dataproc para validar as definições do Lightning Engine numa carga de trabalho em lote, num modelo de sessão ou numa sessão interativa.
Carga de trabalho em lote
Para verificar se o nível do lote está definido como
premiume o motor está definido comoLightning Engine:- Google Cloud console: na página Lotes, consulte as colunas Nível e Motor para o lote. Pode clicar no ID do lote para ver também estas definições na página de detalhes do lote.
- CLI gcloud: execute o comando
gcloud dataproc batches describe. - API: emita um pedido
batches.get.
Modelo de sessão
Para verificar se o motor está definido como
Lightning Enginepara um modelo de sessão:- Google Cloud Consola: na página Modelos de sessões, consulte a coluna Motor do seu modelo. Pode clicar no Nome do modelo de sessão para ver também esta definição na página de detalhes do modelo de sessão.
- CLI gcloud: execute o comando
gcloud beta dataproc session-templates describe. - API: emita um pedido
sessionTemplates.get.
Sessão interativa
O motor está definido como
Lightning Enginepara uma sessão interativa:- Google Cloud Consola: na página Sessões interativas, veja a coluna Motor para o modelo. Pode clicar no ID da sessão interativa para ver também esta definição na página de detalhes do modelo de sessão.
- CLI gcloud: execute o comando
gcloud beta dataproc sessions describe. - API: emita um pedido
sessions.get.
Execução de consultas nativas
A execução de consultas nativas (NQE) é uma funcionalidade opcional do Lightning Engine que melhora o desempenho através de uma implementação nativa baseada no Apache Gluten e no Velox, que foi concebida para o hardware da Google.
O tempo de execução da execução de consultas nativas inclui a gestão unificada da memória para a comutação dinâmica entre a memória fora do heap e no heap sem exigir alterações às configurações existentes do Spark. O NQE inclui suporte expandido para operadores, funções e tipos de dados do Spark, bem como inteligência para identificar automaticamente oportunidades de usar o motor nativo para operações de pushdown ideais.
Identifique cargas de trabalho de execução de consultas nativas
Use a execução de consultas nativas nos seguintes cenários:
APIs Spark DataFrame, APIs Spark Dataset e consultas Spark SQL que leem dados de ficheiros Parquet e ORC. O formato do ficheiro de saída não afeta o desempenho da execução de consultas nativas.
Cargas de trabalho recomendadas pela ferramenta de qualificação de execução de consultas nativas.
A execução de consultas nativas não é recomendada para cargas de trabalho com entradas dos seguintes tipos de dados:
- Byte: ORC e Parquet
- Indicação de tempo: ORC
- Struct, Array, Map: Parquet
Limitações de execução de consultas nativas
A ativação da execução de consultas nativas nos seguintes cenários pode causar exceções, incompatibilidades com o Spark ou o recurso de carga de trabalho para o motor do Spark predefinido.
Alternativos
A execução de consultas nativas na execução seguinte pode resultar na reversão da carga de trabalho para o motor de execução do Spark, o que resulta em regressão ou falha.
ANSI: se o modo ANSI estiver ativado, a execução recorre ao Spark.
Modo sensível a maiúsculas e minúsculas: a execução de consultas nativas suporta apenas o modo predefinido do Spark que não é sensível a maiúsculas e minúsculas. Se o modo sensível a maiúsculas e minúsculas estiver ativado, podem ocorrer resultados incorretos.
Análise de tabelas particionadas: a execução de consultas nativas suporta a análise de tabelas particionadas apenas quando o caminho contém as informações de partição. Caso contrário, a carga de trabalho recorre ao motor de execução do Spark.
Comportamento incompatível
O comportamento incompatível ou os resultados incorretos podem ocorrer quando usa a execução de consultas nativas nos seguintes casos:
Funções JSON: a execução de consultas nativas suporta strings entre aspas duplas e não aspas simples. Os resultados incorretos ocorrem com as aspas simples. A utilização de "*" no caminho com a função
get_json_objectdevolveNULL.Configuração de leitura de Parquet:
- A execução de consultas nativas trata
spark.files.ignoreCorruptFilescomo definido para o valorfalsepredefinido, mesmo quando definido paratrue. - A execução de consultas nativas ignora
spark.sql.parquet.datetimeRebaseModeInRead, e devolve apenas o conteúdo do ficheiro Parquet. As diferenças entre o calendário híbrido antigo (juliano gregoriano) e o calendário gregoriano proléptico não são consideradas. Os resultados do Spark podem ser diferentes.
- A execução de consultas nativas trata
NaN: não suportado. Podem ocorrer resultados inesperados, por exemplo, quando usaNaNnuma comparação numérica.Leitura de colunas do Spark: pode ocorrer um erro fatal, uma vez que o vetor de colunas do Spark é incompatível com a execução de consultas nativas.
Transbordo: quando as partições de aleatorização estão definidas para um número elevado, a funcionalidade de transbordo para o disco pode acionar um
OutOfMemoryException. Se isto acontecer, reduzir o número de partições pode eliminar esta exceção.