
In diesem Dokument wird beschrieben, wie Sie die Lightning Engine aktivieren, um Batcharbeitslasten und interaktive Sitzungen von Serverless for Apache Spark zu beschleunigen.
Übersicht
Die Lightning Engine ist ein leistungsstarker Abfragebeschleuniger, der auf einer mehrschichtigen Optimierungs-Engine basiert. Diese führt übliche Optimierungstechniken wie Abfrage- und Ausführungsoptimierungen sowie kuratierte Optimierungen in der Dateisystemebene und in Datenzugriffs-Connectors aus.
Wie in der folgenden Abbildung dargestellt, beschleunigt Lightning Engine die Ausführungsleistung von Spark-Abfragen für eine TPC-H-ähnliche Arbeitslast (10 TB-Datasetgröße).
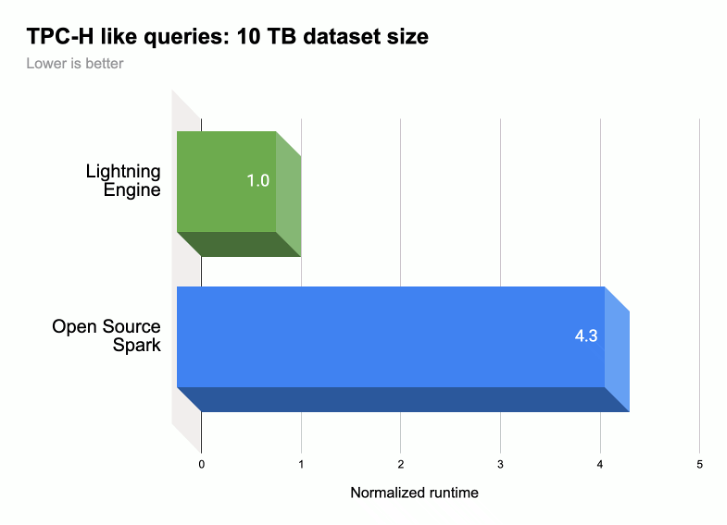
Weitere Informationen finden Sie unter Introducing Lightning Engine – the next generation of Apache Spark performance.
Verfügbarkeit der Lightning Engine
- Lightning Engine ist für die Verwendung mit der Serverless for Apache Spark-Laufzeit 2.3 verfügbar.
- Lightning Engine ist nur mit der Premium-Preisstufe für Serverless for Apache Spark verfügbar.
- Batcharbeitslasten:Lightning Engine ist für Batcharbeitslasten auf der Premium-Stufe automatisch aktiviert. Sie müssen nichts weiter tun.
- Interaktive Sitzungen:Die Lightning-Engine ist für interaktive Sitzungen nicht standardmäßig aktiviert. Informationen zum Aktivieren finden Sie unter Lightning Engine aktivieren.
- Sitzungsvorlagen:Lightning Engine ist für Sitzungsvorlagen nicht standardmäßig aktiviert. Informationen zum Aktivieren finden Sie unter Lightning Engine aktivieren.
Lightning Engine aktivieren
In den folgenden Abschnitten erfahren Sie, wie Sie die Lightning Engine für eine Serverless for Apache Spark-Batcharbeitslast, eine Sitzungsvorlage und eine interaktive Sitzung aktivieren.
Batcharbeitslast
Lightning Engine für eine Batch-Arbeitslast aktivieren
Sie können die Google Cloud Console, die Google Cloud CLI oder die Dataproc API verwenden, um Lightning Engine für einen Batch-Arbeitslast zu aktivieren.
Console
Verwenden Sie die Google Cloud Console, um Lightning Engine für eine Batcharbeitslast zu aktivieren.
In der Google Cloud Console:
- Zu Dataproc-Batches
- Klicken Sie auf Erstellen, um die Seite Batch erstellen zu öffnen.
Wählen Sie die folgenden Felder aus und füllen Sie sie aus:
- Container:
- Laufzeitversion:Wählen Sie
2.3aus.
- Laufzeitversion:Wählen Sie
Stufenkonfiguration:
- Wählen Sie
Premiumaus. Dadurch wird „LIGHTNING ENGINE aktivieren, um die Spark-Leistung zu beschleunigen“ automatisch aktiviert und geprüft.
Wenn Sie die Premium-Stufe auswählen, werden die Driver Compute Tier (Computing-Stufe für Treiber) und die Executor Compute Tier (Computing-Stufe für Executor) auf
Premiumfestgelegt. Diese automatisch festgelegten Compute-Einstellungen für die Premium-Stufe können für Batches mit Runtimes vor3.0nicht überschrieben werden.Sie können die Driver Disk Tier (Treiber-Festplattenstufe) und die Executor Disk Tier (Executor-Festplattenstufe) auf
Premiumkonfigurieren oder den StandardwertStandardbeibehalten. Wenn Sie eine Premium-Laufwerkstufe auswählen, müssen Sie die Laufwerksgröße angeben. Weitere Informationen finden Sie unter Eigenschaften für die Ressourcenverteilung.- Wählen Sie
Properties (Attribute): Optional: Geben Sie das folgende
Key(Attributname) undValue-Paar ein, wenn Sie die Laufzeit Native Query Execution (Ausführung nativer Abfragen) auswählen möchten:Schlüssel Wert spark.dataproc.lightningEngine.runtimeEinheimischer / Einheimische / Ureinwohner / Ureinwohnerin / gebürtig / einheimisch
- Container:
Geben Sie andere Einstellungen für Batch-Arbeitslasten ein, wählen Sie sie aus oder bestätigen Sie sie. Weitere Informationen finden Sie unter Spark-Batcharbeitslast senden.
Klicken Sie auf Senden, um die Spark-Batcharbeitslast auszuführen.
gcloud
Legen Sie die folgenden gcloud CLI-Befehlsflags gcloud dataproc batches submit spark fest, um eine Lightning-Engine für einen Batch-Arbeitslast zu aktivieren.
gcloud dataproc batches submit spark \ --project=PROJECT_ID \ --region=REGION \ --version=2.3 \ --properties=dataproc.tier=premium \ OTHER_FLAGS_AS_NEEDED
Hinweise:
- PROJECT_ID: Ihre Google Cloud Projekt-ID Projekt-IDs werden im Bereich Projektinformationen im Dashboard der Google Cloud Console aufgeführt.
- REGION: Eine verfügbare Compute Engine-Region zum Ausführen der Arbeitslast.
--properties=dataproc.tier=premium. Wenn Sie die Premium-Stufe festlegen, werden für die Batcharbeitslast automatisch die folgenden Attribute festgelegt:spark.dataproc.engine=lightningEnginewählt Lightning Engine für die Batch-Arbeitslast aus.spark.dataproc.driver.compute.tierundspark.dataproc.executor.compute.tiersind aufpremiumgesetzt (siehe Attribute für die Ressourcenzuweisung). Diese automatisch festgelegten Compute-Einstellungen für die Premium-Stufe können für Batches mit Runtimes vor3.0nicht überschrieben werden.
Weitere Eigenschaften
Native Query Engine:
spark.dataproc.lightningEngine.runtime=nativeFügen Sie diese Eigenschaft hinzu, wenn Sie die Laufzeit Native Query Execution auswählen möchten.Laufwerkstufen und ‑größen: Standardmäßig sind die Laufwerkgrößen für Treiber und Executors auf
standard-Stufen und ‑größen festgelegt. Sie können Eigenschaften hinzufügen, umpremium-Laufwerkstufen und ‑Größen (in Vielfachen von375 GiB) auszuwählen.
Weitere Informationen finden Sie unter Eigenschaften für die Ressourcenzuweisung.
OTHER_FLAGS_AS_NEEDED: Weitere Informationen finden Sie unter Spark-Batcharbeitslast senden.
API
So aktivieren Sie Lightning Engine für eine Batcharbeitslast im Rahmen Ihrer batches.create-Anfrage:
- Legen Sie RuntimeConfig.version auf
2.3fest. Fügen Sie RuntimeConfig.properties „dataproc.tier“:“premium“ hinzu. Wenn Sie die Premium-Stufe festlegen, werden automatisch die folgenden Attribute für die Batcharbeitslast festgelegt:
spark.dataproc.engine=lightningEnginewählt Lightning Engine für die Batch-Arbeitslast aus.spark.dataproc.driver.compute.tierundspark.dataproc.executor.compute.tiersind aufpremiumgesetzt (siehe Attribute für die Ressourcenzuweisung). Diese automatisch festgelegten Einstellungen für die Berechnung auf Premium-Ebene können für Batches mit Runtimes vor3.0nicht überschrieben werden.
Sonstiges RuntimeConfig.properties:
Native Query Engine:
spark.dataproc.lightningEngine.runtime:native. Fügen Sie dieses Attribut hinzu, wenn Sie die Laufzeit Native Query Execution auswählen möchten.Laufwerkstufen und ‑größen: Standardmäßig sind die Laufwerkgrößen für Treiber und Executors auf
standard-Stufen und ‑größen festgelegt. Sie können Eigenschaften hinzufügen, umpremium-Stufen und ‑Größen (in Vielfachen von375 GiB) auszuwählen.
Weitere Informationen finden Sie unter Eigenschaften für die Ressourcenverteilung.
Informationen zum Festlegen anderer API-Felder für Batcharbeitslasten finden Sie unter Spark-Batcharbeitslast senden.
Sitzungsvorlage
Lightning Engine für eine Sitzungsvorlage aktivieren
Sie können die Google Cloud Console, die Google Cloud CLI oder die Dataproc API verwenden, um Lightning Engine für eine Sitzungsvorlage für eine Jupyter- oder Spark Connect-Sitzung zu aktivieren.
Console
Verwenden Sie die Google Cloud Console, um Lightning Engine für eine Batcharbeitslast zu aktivieren.
In der Google Cloud Console:
- Zu Dataproc-Sitzungsvorlagen
- Klicken Sie auf Erstellen, um die Seite Sitzungsvorlage erstellen zu öffnen.
Wählen Sie die folgenden Felder aus und füllen Sie sie aus:
- Informationen zur Sitzungsvorlage:
- Wählen Sie „Lightning Engine aktivieren, um die Spark-Leistung zu beschleunigen“ aus.
- Ausführungskonfiguration:
- Laufzeitversion:Wählen Sie
2.3aus.
- Laufzeitversion:Wählen Sie
Attribute:Geben Sie die folgenden
Key- undValue-Paare (Attributname und Attributwert) ein, um den Premium-Tarif auszuwählen:Schlüssel Wert dataproc.tierPremium spark.dataproc.enginelightningEngine Optional: Geben Sie das folgende
Key-Value-Paar (Attributname) ein, um die Laufzeit Ausführung nativer Abfragen auszuwählen:Schlüssel Wert spark.dataproc.lightningEngine.runtimenative
- Informationen zur Sitzungsvorlage:
Füllen Sie andere Einstellungen für die Sitzungsvorlage aus, wählen Sie sie aus oder bestätigen Sie sie. Weitere Informationen finden Sie unter Sitzungsvorlage erstellen.
Klicken Sie auf Senden, um die Sitzungsvorlage zu erstellen.
gcloud
Sie können keine Serverless for Apache Spark-Sitzungsvorlage direkt mit der gcloud CLI erstellen. Stattdessen können Sie mit dem Befehl gcloud beta dataproc session-templates import eine vorhandene Sitzungsvorlage importieren, die importierte Vorlage bearbeiten, um die Lightning Engine und optional die Native Query-Laufzeit zu aktivieren, und die bearbeitete Vorlage dann mit dem Befehl gcloud beta dataproc session-templates export exportieren.
API
So aktivieren Sie Lightning Engine für eine Sitzungsvorlage im Rahmen Ihrer sessionTemplates.create-Anfrage:
- Legen Sie RuntimeConfig.version auf
2.3fest. - Fügen Sie RuntimeConfig.properties die Attribute „dataproc.tier“:“premium“ und „spark.dataproc.engine“:“lightningEngine“ hinzu.
Sonstiges RuntimeConfig.properties:
- Native Query Engine:
spark.dataproc.lightningEngine.runtime:native: Fügen Sie diese Property zu RuntimeConfig.properties hinzu, um die Laufzeit Native Query Execution auszuwählen.
Informationen zum Festlegen anderer API-Felder für Sitzungsvorlagen finden Sie unter Sitzungsvorlage erstellen.
Interaktive Sitzung
Lightning Engine in einer interaktiven Sitzung aktivieren
Sie können die Google Cloud CLI oder die Dataproc API verwenden, um Lightning Engine für eine interaktive Serverless for Apache Spark-Sitzung zu aktivieren. Sie können Lightning Engine auch in einer interaktiven Sitzung in einem BigQuery Studio-Notebook aktivieren.
gcloud
Legen Sie die folgenden gcloud CLI-Befehlsflags gcloud beta dataproc sessions create spark fest, um Lightning Engine in einer interaktiven Sitzung zu aktivieren.
gcloud beta dataproc sessions create spark \ --project=PROJECT_ID \ --location=REGION \ --version=2.3 \ --properties=dataproc.tier=premium,spark.dataproc.engine=lightningEngine \ OTHER_FLAGS_AS_NEEDED
Hinweise:
- PROJECT_ID: Ihre Google Cloud Projekt-ID Projekt-IDs werden im Bereich Projektinformationen im Dashboard der Google Cloud Console aufgeführt.
- REGION: Eine verfügbare Compute Engine-Region zum Ausführen der Arbeitslast.
--properties=dataproc.tier=premium,spark.dataproc.engine=lightningEngine. Mit diesen Eigenschaften wird Lightning Engine für die Sitzung aktiviert.Weitere Eigenschaften:
- Native Query Engine:
spark.dataproc.lightningEngine.runtime=native: Fügen Sie diese Eigenschaft hinzu, um die Laufzeit Native Query Execution auszuwählen.
- Native Query Engine:
OTHER_FLAGS_AS_NEEDED: Weitere Informationen finden Sie unter Interaktive Sitzung erstellen.
API
So aktivieren Sie Lightning Engine für eine Sitzung im Rahmen Ihrer sessions.create-Anfrage:
- Legen Sie RuntimeConfig.version auf
2.3fest. - Fügen Sie RuntimeConfig.properties die Attribute „dataproc.tier“:“premium“ und „spark.dataproc.engine“:“lightningEngine“ hinzu.
Sonstiges RuntimeConfig.properties:
- Native Query Engine:
spark.dataproc.lightningEngine.runtime:native: Fügen Sie diese Property zu RuntimeConfig.properties hinzu, wenn Sie die Laufzeit Native Query Execution auswählen möchten.
Informationen zum Festlegen anderer API-Felder für Sitzungsvorlagen finden Sie unter Interaktive Sitzung erstellen.
BigQuery-Notebook
Sie können Lightning Engine aktivieren, wenn Sie eine Sitzung in einem BigQuery Studio-PySpark-Notebook erstellen.
from google.cloud.dataproc_spark_connect import DataprocSparkSession
from google.cloud.dataproc_v1 import Session
session = Session()
# Enable Lightning Engine.
session.runtime_config.properties["version"] = "2.3"
session.runtime_config.properties["dataproc.tier"] = "premium"
session.runtime_config.properties["spark.dataproc.engine"] = "lightningEngine"
# Enable THE Native Query Execution runtime.
session.runtime_config.properties["spark.dataproc.lightningEngine.runtime"] = "native"
# Create the Spark session.
spark = (
DataprocSparkSession.builder
.appName("APP_NAME")
.dataprocSessionConfig(session)
.getOrCreate())
# Add Spark application code here:
Lightning Engine-Einstellungen prüfen
Sie können die Google Cloud -Konsole, die Google Cloud CLI oder die Dataproc API verwenden, um die Lightning Engine-Einstellungen für einen Batcharbeitslast, eine Sitzungsvorlage oder eine interaktive Sitzung zu prüfen.
Batcharbeitslast
So prüfen Sie, ob die Stufe des Batches auf
premiumund die Engine aufLightning Enginefestgelegt ist:- Google Cloud Console: Auf der Seite Batches finden Sie die Spalten Tier und Engine für den Batch. Sie können auch auf die Batch-ID klicken, um diese Einstellungen auf der Seite mit den Batchdetails aufzurufen.
- gcloud CLI: Führen Sie den Befehl
gcloud dataproc batches describeaus. - API: Senden Sie eine
batches.get-Anfrage.
Sitzungsvorlage
So prüfen Sie, ob engine für eine Sitzungsvorlage auf
Lightning Enginefestgelegt ist:- Google Cloud -Konsole: Auf der Seite Sitzungsvorlagen finden Sie in der Spalte Engine die Engine für Ihre Vorlage. Sie können auch auf den Namen der Sitzungsvorlage klicken, um diese Einstellung auf der Detailseite der Sitzungsvorlage aufzurufen.
- gcloud CLI: Führen Sie den Befehl
gcloud beta dataproc session-templates describeaus. - API: Senden Sie eine
sessionTemplates.get-Anfrage.
Interaktive Sitzung
Die Engine ist für eine interaktive Sitzung auf
Lightning Enginefestgelegt:- Google Cloud -Konsole: Auf der Seite Interaktive Sitzungen finden Sie die Vorlage in der Spalte Engine. Sie können auch auf die ID der interaktiven Sitzung klicken, um diese Einstellung auf der Detailseite der Sitzungsvorlage aufzurufen.
- gcloud CLI: Führen Sie den Befehl
gcloud beta dataproc sessions describeaus. - API: Senden Sie eine
sessions.get-Anfrage.
Ausführung nativer Abfragen
Die native Ausführung von Abfragen (Native Query Execution, NQE) ist ein optionales Lightning Engine-Feature, das die Leistung durch eine native Implementierung auf Basis von Apache Gluten und Velox verbessert. Es wurde für Google-Hardware entwickelt.
Die Laufzeit für die Ausführung nativer Abfragen umfasst einheitliches Arbeitsspeicher-Management für das dynamische Umschalten zwischen Off-Heap- und On-Heap-Arbeitsspeicher, ohne dass Änderungen an vorhandenen Spark-Konfigurationen erforderlich sind. NQE bietet erweiterte Unterstützung für Operatoren, Funktionen und Spark-Datentypen sowie Intelligenz, um automatisch Möglichkeiten zur Verwendung der nativen Engine für optimale Pushdown-Vorgänge zu erkennen.
Arbeitslasten für die Ausführung nativer Abfragen identifizieren
Verwenden Sie die Ausführung nativer Abfragen in den folgenden Szenarien:
Spark-DataFrame-APIs, Spark-Dataset-APIs und Spark SQL-Abfragen, mit denen Daten aus Parquet- und ORC-Dateien gelesen werden. Das Ausgabedateiformat hat keine Auswirkungen auf die Leistung der Ausführung nativer Abfragen.
Arbeitslasten, die vom Qualifizierungstool für die Ausführung nativer Abfragen empfohlen werden.
Die Ausführung nativer Abfragen wird für Arbeitslasten mit Eingaben der folgenden Datentypen nicht empfohlen:
- Byte: ORC und Parquet
- Zeitstempel: ORC
- Struct, Array, Map: Parquet
Einschränkungen bei der Ausführung nativer Abfragen
Wenn Sie die Ausführung nativer Abfragen in den folgenden Szenarien aktivieren, kann dies zu Ausnahmen, Spark-Inkompatibilitäten oder einem Fallback der Arbeitslast auf die standardmäßige Spark-Engine führen.
Fallbacks
Die Ausführung nativer Abfragen kann dazu führen, dass die Arbeitslast auf die Spark-Ausführungs-Engine zurückfällt, was zu Regressionen oder Fehlern führt.
ANSI:Wenn der ANSI-Modus aktiviert ist, wird die Ausführung auf Spark zurückgesetzt.
Modus mit Berücksichtigung der Groß-/Kleinschreibung:Die Ausführung nativer Abfragen unterstützt nur den standardmäßigen Spark-Modus ohne Berücksichtigung der Groß-/Kleinschreibung. Wenn der Modus „Groß-/Kleinschreibung beachten“ aktiviert ist, können falsche Ergebnisse auftreten.
Scan partitionierter Tabellen:Die native Abfrageausführung unterstützt den Scan partitionierter Tabellen nur, wenn der Pfad die Partitionsinformationen enthält. Andernfalls wird die Arbeitslast auf die Spark-Ausführungs-Engine zurückgesetzt.
Inkompatibles Verhalten
In den folgenden Fällen kann es bei der Ausführung nativer Abfragen zu inkompatiblem Verhalten oder falschen Ergebnissen kommen:
JSON-Funktionen:Bei der Ausführung nativer Abfragen werden Strings unterstützt, die von doppelten Anführungszeichen umschlossen sind, nicht von einfachen Anführungszeichen. Bei einfachen Anführungszeichen werden falsche Ergebnisse zurückgegeben. Wenn Sie „*“ im Pfad mit der Funktion
get_json_objectverwenden, wirdNULLzurückgegeben.Parquet-Lesekonfiguration:
- Bei der Ausführung nativer Abfragen wird
spark.files.ignoreCorruptFilesals auf den Standardwertfalsefestgelegt behandelt, auch wenn der Wert auftruefestgelegt ist. - Bei der Ausführung nativer Abfragen wird
spark.sql.parquet.datetimeRebaseModeInReadignoriert und es werden nur die Inhalte der Parquet-Datei zurückgegeben. Unterschiede zwischen dem Legacy-Hybridkalender (julianisch-gregorianisch) und dem proleptischen gregorianischen Kalender werden nicht berücksichtigt. Die Ergebnisse von Spark können abweichen.
- Bei der Ausführung nativer Abfragen wird
NaN:Nicht unterstützt. Unerwartete Ergebnisse können beispielsweise auftreten, wenn SieNaNin einem numerischen Vergleich verwenden.Spaltenweises Lesen in Spark:Ein schwerwiegender Fehler kann auftreten, da der spaltenweise Spark-Vektor nicht mit der nativen Abfrageausführung kompatibel ist.
Spill:Wenn die Anzahl der Shuffle-Partitionen auf einen hohen Wert festgelegt ist, kann die Funktion „Spill-to-Disk“ einen
OutOfMemoryExceptionauslösen. Wenn dies der Fall ist, kann diese Ausnahme durch Reduzieren der Anzahl der Partitionen behoben werden.