
Utilisez le connecteur spark-bigquery avec Apache Spark pour lire et écrire des données depuis et vers BigQuery.
Ce tutoriel présente une application PySpark qui utilise spark-bigquery-connector.
Utiliser le connecteur BigQuery avec votre charge de travail
Consultez les versions d'exécution Serverless pour Apache Spark pour déterminer la version du connecteur BigQuery installée dans la version d'exécution de votre charge de travail par lot. Si le connecteur n'est pas listé, consultez la section suivante pour savoir comment le rendre disponible pour les applications.
Utiliser le connecteur avec la version 2.0 du runtime Spark
Le connecteur BigQuery n'est pas installé dans la version 2.0 du runtime Spark. Lorsque vous utilisez la version 2.0 du runtime Spark, vous pouvez rendre le connecteur disponible pour votre application de l'une des manières suivantes :
- Utilisez le paramètre
jarspour pointer vers un fichier JAR de connecteur lorsque vous envoyez votre charge de travail par lot Google Cloud Serverless pour Apache Spark. L'exemple suivant spécifie un fichier JAR de connecteur (pour obtenir la liste des fichiers JAR de connecteur disponibles, consultez le dépôt GoogleCloudDataproc/spark-bigquery-connector sur GitHub).- Exemple de Google Cloud CLI :
gcloud dataproc batches submit pyspark \ --region=region \ --jars=gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.13-version.jar \ ... other args
- Exemple de Google Cloud CLI :
- Incluez le fichier JAR du connecteur dans votre application Spark en tant que dépendance (consultez la section Compiler sur le connecteur).
Calculer les coûts
Ce tutoriel fait appel à des composants payants de Google Cloud, y compris :
- Sans serveur pour Apache Spark
- BigQuery
- Cloud Storage
Utilisez le Simulateur de coût pour générer une estimation des coûts en fonction de votre utilisation prévue.
E/S BigQuery
Cet exemple lit les données de BigQuery dans un DataFrame Spark pour effectuer un décompte de mots à l'aide de l'API de source de données standard.
Le connecteur écrit le nombre de mots dans BigQuery comme suit :
Mise en mémoire tampon des données dans des fichiers temporaires de votre bucket Cloud Storage
Copier les données en une seule opération depuis votre bucket Cloud Storage vers BigQuery
Suppression des fichiers temporaires dans Cloud Storage une fois l'opération de chargement BigQuery terminée (les fichiers temporaires sont également supprimés une fois l'application Spark terminée). Si la suppression échoue, vous devrez supprimer tous les fichiers Cloud Storage temporaires indésirables, qui sont généralement placés dans
gs://YOUR_BUCKET/.spark-bigquery-JOB_ID-UUID.
Configurer la facturation
Par défaut, le projet qui est facturé pour l'utilisation de l'API est le projet associé aux identifiants ou au compte de service. Pour facturer un autre projet, définissez la configuration suivante : spark.conf.set("parentProject", "<BILLED-GCP-PROJECT>").
Vous pouvez également ajouter un projet à facturer à une opération de lecture ou d'écriture, comme ceci : .option("parentProject", "<BILLED-GCP-PROJECT>").
Envoyer une charge de travail par lot de décompte de mots PySpark
Exécutez une charge de travail par lot Spark qui compte le nombre de mots dans un ensemble de données public.
- Ouvrez un terminal local ou Cloud Shell.
- Créez le
wordcount_datasetavec l'outil de ligne de commande bq dans un terminal local ou dans Cloud Shell.bq mk wordcount_dataset
- Créez un bucket Cloud Storage avec la Google Cloud CLI.
gcloud storage buckets create gs://YOUR_BUCKET
YOUR_BUCKETpar le nom du bucket Cloud Storage que vous avez créé. - Créez le fichier
wordcount.pyen local dans un éditeur de texte en copiant le code PySpark suivant.#!/usr/bin/python """BigQuery I/O PySpark example.""" from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .appName('spark-bigquery-demo') \ .getOrCreate() # Use the Cloud Storage bucket for temporary BigQuery export data used # by the connector. bucket = "YOUR_BUCKET" spark.conf.set('temporaryGcsBucket', bucket) # Load data from BigQuery. words = spark.read.format('bigquery') \ .option('table', 'bigquery-public-data:samples.shakespeare') \ .load() words.createOrReplaceTempView('words') # Perform word count. word_count = spark.sql( 'SELECT word, SUM(word_count) AS word_count FROM words GROUP BY word') word_count.show() word_count.printSchema() # Saving the data to BigQuery word_count.write.format('bigquery') \ .option('table', 'wordcount_dataset.wordcount_output') \ .save()
- Envoyez la charge de travail par lot PySpark :
gcloud dataproc batches submit pyspark wordcount.py \ --region=REGION \ --deps-bucket=YOUR_BUCKET
... +---------+----------+ | word|word_count| +---------+----------+ | XVII| 2| | spoil| 28| | Drink| 7| |forgetful| 5| | Cannot| 46| | cures| 10| | harder| 13| | tresses| 3| | few| 62| | steel'd| 5| | tripping| 7| | travel| 35| | ransom| 55| | hope| 366| | By| 816| | some| 1169| | those| 508| | still| 567| | art| 893| | feign| 10| +---------+----------+ only showing top 20 rows root |-- word: string (nullable = false) |-- word_count: long (nullable = true)
Pour prévisualiser la table de sortie dans la console Google Cloud , ouvrez la page BigQuery de votre projet, sélectionnez la tablewordcount_output, puis cliquez sur Aperçu.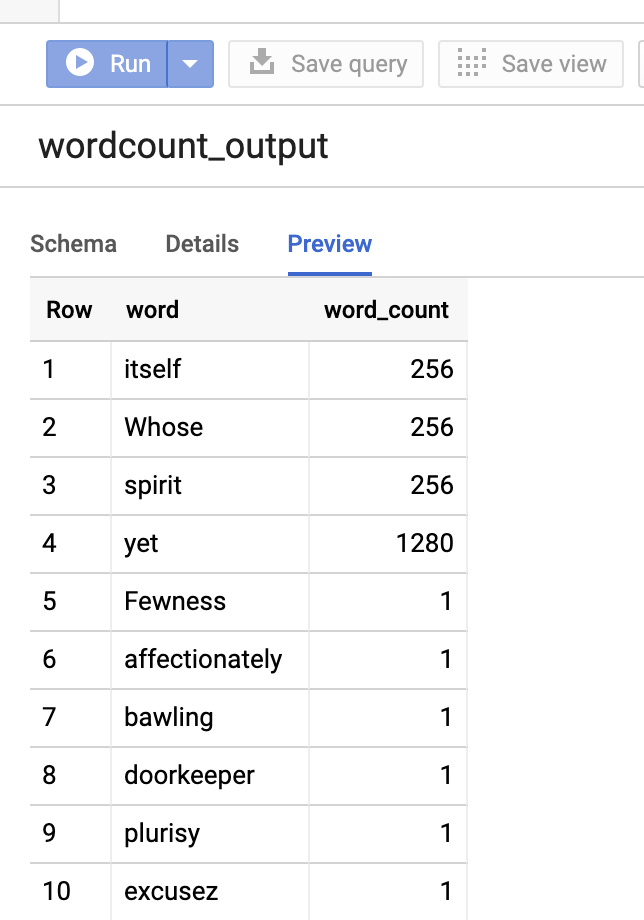
Pour en savoir plus
- Stockage BigQuery et Spark SQL - Python
- Créer un fichier de définition de table pour une source de données externe
- Utiliser des données partitionnées en externe