
Les charges de travail par lot et les sessions interactives Managed Service pour Apache Spark s'exécutent avec les identifiants d'un utilisateur final ou d'un compte de service. Lorsque des identifiants de compte de service sont utilisés, le compte de service utilisé pour exécuter des charges de travail par lot ou des sessions interactives dépend de la version du runtime par lot ou de session.
Comptes de service d'exécution antérieurs à la version 3.0
Les versions du runtime Spark antérieures à 3.0 avec des identifiants de compte de service utilisent le compte de service Compute Engine par défaut ou un compte de service personnalisé spécifié par l'utilisateur pour envoyer une charge de travail par lot ou créer une session interactive.
Comptes de service d'exécution 3.0 et versions ultérieures
Les versions 3.0 et ultérieures du runtime Spark avec des identifiants de compte de service utilisent un compte de service personnalisé spécifié par l'utilisateur pour envoyer une charge de travail par lot ou créer une session interactive.
Les environnements d'exécution Managed Service pour Apache Spark 3.0 et versions ultérieures créent le compte de service Agent de service de nœud Resource Manager pour Dataproc, service-project-number@gcp-sa-dataprocrmnode.iam.gserviceaccount.com, avec le rôle Agent de service de nœud Resource Manager pour Dataproc dans un projet Google Cloud d'utilisateur Managed Service pour Apache Spark. Ce compte de service effectue les opérations système suivantes sur les ressources Managed Service pour Apache Spark situées dans le projet où une charge de travail est créée :
- Cloud Logging et Cloud Monitoring
- Opérations de base des nœuds Resource Manager Managed Service pour Apache Spark, telles que
get,heartbeatetmintOAuthToken
Afficher et gérer les rôles des comptes de service IAM
Pour afficher et gérer les rôles attribués au compte de service de charge de travail par lot ou de session, procédez comme suit :
Dans la console Google Cloud , accédez à la page IAM.
Cliquez sur Inclure les attributions de rôles fournies par Google.
Affichez les rôles listés pour la charge de travail par lot ou le compte de service par défaut ou personnalisé de la session.
L'image suivante montre le rôle Nœud de calcul Managed Service pour Apache Spark requis listé pour le compte de service Compute Engine par défaut,
project_number-compute@developer.gserviceaccount.com, que Managed Service pour Apache Spark utilise par défaut comme compte de service de charge de travail ou de session.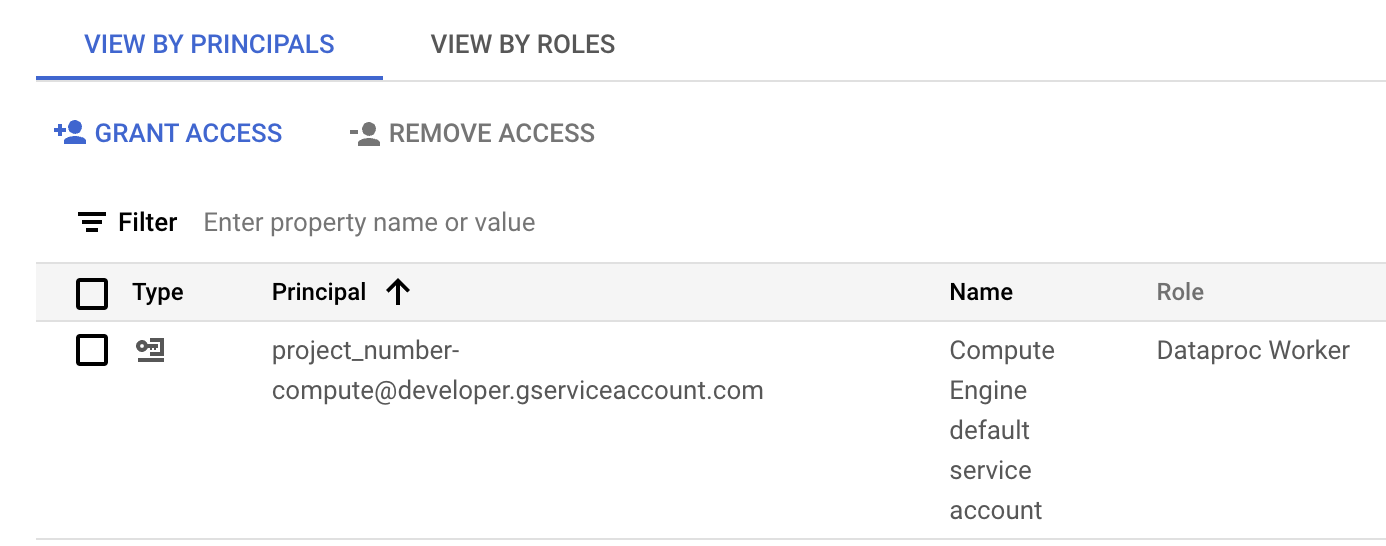
Rôle de nœud de calcul Managed Service pour Apache Spark attribué au compte de service Compute Engine par défaut dans la section IAM de la console Google Cloud . Vous pouvez cliquer sur l'icône en forme de crayon affichée sur la ligne du compte de service pour attribuer ou supprimer des rôles de compte de service.
Utiliser un compte de service multiprojet
Vous pouvez envoyer une charge de travail par lot qui utilise un compte de service provenant d'un projet différent de celui de la charge de travail par lot (le projet dans lequel le lot est envoyé). Dans cette section, le projet dans lequel se trouve le compte de service est appelé service account project, et le projet dans lequel le lot est envoyé est appelé batch project.
Pourquoi utiliser un compte de service multiprojet pour exécuter une charge de travail par lot ? Cela peut se produire si le compte de service de l'autre projet s'est vu attribuer des rôles IAM qui offrent un accès précis aux ressources de ce projet.
Procédure de configuration
Les exemples de cette section s'appliquent à l'envoi d'une charge de travail par lot exécutée avec une version d'exécution antérieure à 3.0.
Dans le projet de compte de service :
Activer l'association des comptes de service à plusieurs projets
activer l'API Dataproc ;
Rôles requis pour activer les API
Pour activer les API, vous devez disposer de l'autorisation
serviceusage.services.enable. Si vous avez créé le projet, vous disposez probablement déjà de cette autorisation grâce au rôle Propriétaire (roles/owner). Sinon, vous pouvez obtenir cette autorisation grâce au rôle Administrateur Service Usage (roles/serviceusage.serviceUsageAdmin). Découvrez comment attribuer des rôles.Attribuez à votre compte de messagerie (l'utilisateur qui crée le cluster) le rôle Utilisateur du compte de service sur le projet de compte de service ou, pour un contrôle plus précis, sur le compte de service dans le projet de compte de service.
Pour en savoir plus, consultez Gérer l'accès aux projets, aux dossiers et aux organisations pour attribuer des rôles au niveau du projet et Gérer l'accès aux comptes de service pour attribuer des rôles au niveau du compte de service.
Exemples de gcloud CLI :
L'exemple de commande suivant attribue le rôle Utilisateur de compte de service à l'utilisateur au niveau du projet :
gcloud projects add-iam-policy-binding SERVICE_ACCOUNT_PROJECT_ID \ --member=USER_EMAIL \ --role="roles/iam.serviceAccountUser"
Remarques :
USER_EMAIL: indiquez l'adresse e-mail de votre compte utilisateur, au formatuser:user-name@example.com.
L'exemple de commande suivant attribue le rôle Utilisateur du compte de service à l'utilisateur au niveau du compte de service :
gcloud iam service-accounts add-iam-policy-binding VM_SERVICE_ACCOUNT_EMAIL \ --member=USER_EMAIL \ --role="roles/iam.serviceAccountUser"
Remarques :
USER_EMAIL: indiquez l'adresse e-mail de votre compte utilisateur, au formatuser:user-name@example.com.
Attribuez au compte de service le rôle Worker Managed Service pour Apache Spark sur le projet par lot.
Exemple de gcloud CLI :
gcloud projects add-iam-policy-binding BATCH_PROJECT_ID \ --member=serviceAccount:SERVICE_ACCOUNT_NAME@SERVICE_ACCOUNT_PROJECT_ID.iam.gserviceaccount.com \ --role="roles/dataproc.worker"
Dans le projet par lots :
Attribuez au compte de service de l'agent de service Managed Service for Apache Spark les rôles Utilisateur du compte de service et Créateur de jetons du compte de service sur le projet du compte de service ou, pour un contrôle plus précis, sur le compte de service dans le projet du compte de service. Vous autorisez ainsi le compte de service de l'agent de service Managed Service pour Apache Spark dans le projet par lot à créer des jetons pour le compte de service dans le projet de compte de service.
Pour en savoir plus, consultez Gérer l'accès aux projets, aux dossiers et aux organisations pour attribuer des rôles au niveau du projet et Gérer l'accès aux comptes de service pour attribuer des rôles au niveau du compte de service.
Exemples de gcloud CLI :
Les commandes suivantes attribuent les rôles d'utilisateur du compte de service et de créateur de jetons du compte de service au compte de service de l'agent de service Managed Service pour Apache Spark dans le projet par lot au niveau du projet :
gcloud projects add-iam-policy-binding SERVICE_ACCOUNT_PROJECT_ID \ --member=serviceAccount:service-BATCH_PROJECT_NUMBER@dataproc-accounts.iam.gserviceaccount.com \ --role="roles/iam.serviceAccountUser"
gcloud projects add-iam-policy-binding SERVICE_ACCOUNT_PROJECT_ID \ --member=serviceAccount:service-BATCH_PROJECT_NUMBER@dataproc-accounts.iam.gserviceaccount.com \ --role="roles/iam.serviceAccountTokenCreator"
Les exemples de commandes suivants attribuent les rôles d'utilisateur du compte de service et de créateur de jetons du compte de service au compte de service de l'agent de service Managed Service pour Apache Spark dans le projet par lot au niveau du compte de service :
gcloud iam service-accounts add-iam-policy-binding VM_SERVICE_ACCOUNT_EMAIL \ --member=serviceAccount:service-BATCH_PROJECT_NUMBER@dataproc-accounts.iam.gserviceaccount.com \ --role="roles/iam.serviceAccountUser"
gcloud iam service-accounts add-iam-policy-binding VM_SERVICE_ACCOUNT_EMAIL \ --member=serviceAccount:service-BATCH_PROJECT_NUMBER@dataproc-accounts.iam.gserviceaccount.com \ --role="roles/iam.serviceAccountTokenCreator"
Dans le projet par lot, attribuez le rôle Créateur de jetons du compte de service au compte de service de l'agent de service Compute Engine, soit au niveau du projet de compte de service, soit au niveau du compte de service dans le projet de compte de service pour un contrôle plus précis. Vous accordez ainsi au compte de service de l'agent de service Compute dans le projet par lot la possibilité de créer des jetons pour le compte de service dans le projet de compte de service.
Pour en savoir plus, consultez Gérer l'accès aux projets, aux dossiers et aux organisations pour attribuer des rôles au niveau du projet et Gérer l'accès aux comptes de service pour attribuer des rôles au niveau du compte de service.
Exemples de gcloud CLI :
L'exemple de commande suivant attribue le rôle de créateur de jetons de compte de service au compte de service de l'agent de service Compute Engine dans le projet par lot, au niveau du projet :
gcloud projects add-iam-policy-binding SERVICE_ACCOUNT_PROJECT_ID \ --member=serviceAccount:service-BATCH_PROJECT_NUMBER@compute-system.iam.gserviceaccount.com \ --role="roles/iam.serviceAccountTokenCreator"
L'exemple de commande suivant attribue le rôle de créateur de jetons du compte de service au compte de service de l'agent de service Compute Engine dans le projet de cluster, au niveau du compte de service :
gcloud iam service-accounts add-iam-policy-binding VM_SERVICE_ACCOUNT_EMAIL \ --member=serviceAccount:service-BATCH_PROJECT_NUMBER@compute-system.iam.gserviceaccount.com \ --role="roles/iam.serviceAccountTokenCreator"
Envoyer la charge de travail par lot
Une fois les étapes de configuration effectuées, vous pouvez envoyer une charge de travail par lot. Veillez à spécifier le compte de service dans le projet de compte de service comme compte de service à utiliser pour la charge de travail par lot.
Résoudre les échecs basés sur les autorisations
Des autorisations incorrectes ou insuffisantes pour le compte de service utilisé par votre charge de travail ou session par lot peuvent entraîner des échecs de création de lot ou de session qui affichent le message d'erreur "Le nœud de calcul du pilote n'a pas pu être initialisé pour le lot en 600 secondes". Cette erreur indique que le pilote Spark n'a pas pu démarrer dans le délai imparti, souvent en raison d'un manque d'accès aux ressources Google Cloud nécessaires.
Pour résoudre ce problème, vérifiez que votre compte de service dispose des rôles ou autorisations minimales suivants :
- Rôle Worker Managed Service pour Apache Spark (
roles/dataproc.worker) : ce rôle accorde les autorisations nécessaires à Managed Service pour Apache Spark afin de gérer et d'exécuter les charges de travail et les sessions Spark. - Lecteur des objets Storage (
roles/storage.objectViewer), Créateur des objets Storage (roles/storage.objectCreator) ou Administrateur des objets Storage (roles/storage.admin) : si votre application Spark lit ou écrit des données dans des buckets Cloud Storage, le compte de service doit disposer des autorisations appropriées pour accéder aux buckets. Par exemple, si vos données d'entrée se trouvent dans un bucket Cloud Storage,Storage Object Viewerest obligatoire. Si votre application écrit des résultats dans un bucket Cloud Storage,Storage Object CreatorouStorage Object Adminest nécessaire. - Éditeur de données BigQuery (
roles/bigquery.dataEditor) ou Lecteur de données BigQuery (roles/bigquery.dataViewer) : si votre application Spark interagit avec BigQuery, vérifiez que le compte de service dispose des rôles BigQuery appropriés. - Autorisations Cloud Logging : le compte de service a besoin d'autorisations pour écrire des journaux dans Cloud Logging afin de déboguer efficacement. En règle générale, le rôle
Logging Writer(roles/logging.logWriter) est suffisant.
Échecs courants liés aux autorisations ou à l'accès
Rôle
dataproc.workermanquant : sans ce rôle principal, l'infrastructure Managed Service pour Apache Spark ne peut pas provisionner ni gérer correctement le nœud du pilote.Autorisations Cloud Storage insuffisantes : si votre application Spark tente de lire des données d'entrée ou d'écrire des données de sortie dans un bucket Cloud Storage sans les autorisations de compte de service nécessaires, le pilote peut ne pas s'initialiser, car il n'a pas accès aux ressources critiques.
Problèmes de réseau ou de pare-feu : les règles VPC Service Controls ou de pare-feu peuvent bloquer par inadvertance l'accès des comptes de service aux API ou ressources Google Cloud .
Pour vérifier et modifier les autorisations du compte de service :
- Accédez à la page IAM et administration > IAM de la console Google Cloud .
- Recherchez le compte de service utilisé pour vos charges de travail ou sessions par lot.
- Vérifiez que les rôles nécessaires sont attribués. Si ce n'est pas le cas, ajoutez-les.
Pour obtenir la liste des rôles et autorisations Managed Service pour Apache Spark, consultez Autorisations Managed Service pour Apache Spark et rôles IAM.