
이 문서에서는 Managed Service for Apache Spark 일괄 워크로드의 자동 조정에 관한 정보를 제공합니다. Spark 구성 옵션의 수와 이러한 옵션이 워크로드에 미치는 영향을 평가하기가 어렵기 때문에 성능과 복원력을 위해 Spark 워크로드를 최적화하기 어려울 수 있습니다. Managed Service for Apache Spark 자동 조정은 Spark 최적화 권장사항 및 워크로드 실행 분석('동질 집단'이라고 함)을 기반으로 반복되는 Spark 워크로드에 Spark 구성 설정을 자동으로 적용하여 수동 워크로드 구성의 대안을 제공합니다.
Managed Service for Apache Spark 자동 튜닝 가입
이 페이지에 설명된 Managed Service for Apache Spark 자동 조정 프리뷰 출시 액세스 권한을 신청하려면 Managed Service for Apache Spark 프리뷰 액세스 요청 가입 양식을 작성하고 제출합니다. 양식이 승인되면 양식에 등록된 프로젝트에서 미리보기 기능을 사용할 수 있습니다.
이점
Managed Service for Apache Spark 자동 조정은 다음과 같은 이점을 제공할 수 있습니다.
- 자동 최적화: 비효율적인 Managed Service for Apache Spark 배치 및 Spark 구성을 자동으로 조정하여 작업 실행 시간을 단축할 수 있습니다.
- 이전 학습: 반복되는 실행에서 학습하여 워크로드에 맞게 맞춤설정된 권장사항을 적용합니다.
자동 조정 동질 집단
자동 조정은 배치 워크로드의 반복 실행 (동질 집단)에 적용됩니다.
배치 워크로드를 제출할 때 지정한 동질 집단 이름은 이를 반복 워크로드의 연속 실행 중 하나로 식별합니다.
일괄 워크로드 동질 집단에는 다음과 같이 자동 조정이 적용됩니다.
자동 조정은 워크로드의 두 번째 및 후속 동질 집단에 계산되어 적용됩니다. Managed Service for Apache Spark 자동 조정은 최적화를 위해 워크로드 기록을 사용하므로 반복 워크로드의 첫 번째 실행에는 자동 조정이 적용되지 않습니다.
자동 조정은 실행 중인 워크로드에 소급 적용되지 않으며 새로 제출된 워크로드에만 적용됩니다.
자동 조정은 코호트 통계를 분석하여 시간이 지남에 따라 학습하고 개선됩니다. 시스템에서 충분한 데이터를 수집할 수 있도록 자동 조정 기능을 최소 5회 실행 동안 사용 설정하는 것이 좋습니다.
동질 집단 이름: 반복 워크로드 유형을 식별하는 데 도움이 되는 동질 집단 이름을 사용하는 것이 좋습니다. 예를 들어 일일 판매 집계 작업을 실행하는 예약된 워크로드의 동질 집단 이름으로 daily_sales_aggregation을 사용할 수 있습니다.
자동 조정 시나리오
해당하는 경우 자동 튜닝은 배치 워크로드를 최적화하기 위해 다음 scenarios 또는 목표를 자동으로 선택하고 실행합니다.
- 확장: Spark 자동 확장 구성 설정입니다.
- 조인 최적화: SQL 브로드캐스트 조인 성능을 최적화하는 Spark 구성 설정입니다.
Managed Service for Apache Spark 자동 튜닝 사용
Google Cloud 콘솔, Google Cloud CLI, Dataproc API 또는 Cloud 클라이언트 라이브러리를 사용하여 일괄 워크로드에서 Apache Spark용 관리 서비스 자동 조정을 사용 설정할 수 있습니다.
콘솔
반복 일괄 워크로드를 제출할 때마다 Managed Service for Apache Spark 자동 조정을 사용 설정하려면 다음 단계를 따르세요.
Google Cloud 콘솔에서 Managed Service for Apache Spark 배치 페이지로 이동합니다.
일괄 워크로드를 만들려면 만들기를 클릭합니다.
자동 조정 섹션에서 다음을 수행합니다.
사용 설정 버튼을 전환하여 Spark 워크로드의 자동 조정을 사용 설정합니다.
동질 집단: 배치를 일련의 반복되는 워크로드 중 하나로 식별하는 동질 집단 이름을 입력합니다. 이 동질 집단 이름으로 제출된 두 번째 및 후속 워크로드에 자동 조정이 적용됩니다. 예를 들어 일일 판매 집계 작업을 실행하는 예약된 배치 워크로드의 동질 집단 이름으로
daily_sales_aggregation을 지정합니다.
필요에 따라 일괄 만들기 페이지의 다른 섹션을 작성한 다음 제출을 클릭합니다. 이러한 필드에 대한 자세한 내용은 일괄 워크로드 제출을 참고하세요.
gcloud
반복 일괄 워크로드를 제출할 때마다 Managed Service for Apache Spark 자동 조정을 사용 설정하려면 다음 gcloud CLI gcloud dataproc batches submit 명령어를 터미널 창에서 로컬로 실행하거나 Cloud Shell에서 실행합니다.
gcloud dataproc batches submit COMMAND \ --region=REGION \ --cohort=COHORT \ --autotuning-scenarios=auto \ other arguments ...
다음을 바꿉니다.
- COMMAND: Spark 워크로드 유형(예:
Spark,PySpark,Spark-Sql또는Spark-R). - REGION: 배치 워크로드가 실행되는 리전입니다.
- COHORT: 배치를 일련의 반복되는 워크로드 중 하나로 식별하는 동질 집단 이름.
이 동질 집단 이름으로 제출된 두 번째 및 후속 워크로드에 자동 조정이 적용됩니다. 예를 들어 일일 판매 집계 작업을 실행하는 예약된 배치 워크로드의 동질 집단 이름으로
daily_sales_aggregation을 지정합니다. --autotuning-scenarios=auto: 자동 튜닝을 사용 설정합니다.
API
반복 일괄 워크로드를 제출할 때마다 Managed Service for Apache Spark 자동 조정을 사용 설정하려면 다음 필드가 포함된 batches.create 요청을 제출합니다.
RuntimeConfig.cohort: 배치를 일련의 반복되는 워크로드 중 하나로 식별하는 동질 집단 이름. 이 동질 집단 이름으로 제출된 두 번째 및 후속 워크로드에 자동 조정이 적용됩니다. 예를 들어 일일 판매 집계 태스크를 실행하는 예약된 배치 워크로드의 동질 집단 이름으로daily_sales_aggregation을 지정합니다.AutotuningConfig.scenarios: Spark 배치 워크로드에서 자동 조정을 사용 설정하려면AUTO를 지정합니다.
예:
...
runtimeConfig:
cohort: COHORT_NAME
autotuningConfig:
scenarios:
- AUTO
...
Java
이 샘플을 사용해 보기 전에 Managed Service for Apache Spark 빠른 시작: 클라이언트 라이브러리 사용의 Java 설정 안내를 따르세요. 자세한 내용은 Managed Service for Apache Spark Java API 참조 문서를 참고하세요.
Managed Service for Apache Spark에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
반복 일괄 워크로드를 제출할 때마다 Managed Service for Apache Spark 자동 조정을 사용 설정하려면 다음 필드가 포함된 CreateBatchRequest를 사용하여 BatchControllerClient.createBatch를 호출합니다.
Batch.RuntimeConfig.cohort: 배치를 일련의 반복되는 워크로드 중 하나로 식별하는 동질 집단 이름. 이 동질 집단 이름으로 제출된 두 번째 및 후속 워크로드에 자동 조정이 적용됩니다. 예를 들어 일일 판매 집계 작업을 실행하는 예약된 일괄 워크로드의 동질 집단 이름으로daily_sales_aggregation을 지정할 수 있습니다.Batch.RuntimeConfig.AutotuningConfig.scenarios: Spark 배치 워크로드에서 자동 조정을 사용 설정하려면AUTO을 지정합니다.
예:
...
Batch batch =
Batch.newBuilder()
.setRuntimeConfig(
RuntimeConfig.newBuilder()
.setCohort("daily_sales_aggregation")
.setAutotuningConfig(
AutotuningConfig.newBuilder()
.addScenarios(Scenario.AUTO))
...
.build();
batchControllerClient.createBatch(
CreateBatchRequest.newBuilder()
.setParent(parent)
.setBatchId(batchId)
.setBatch(batch)
.build());
...
API를 사용하려면 google-cloud-dataproc 클라이언트 라이브러리 버전 4.43.0 이상을 사용해야 합니다. 다음 구성 중 하나를 사용하여 프로젝트에 라이브러리를 추가할 수 있습니다.
Maven
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-dataproc</artifactId>
<version>4.43.0</version>
</dependency>
</dependencies>
Gradle
implementation 'com.google.cloud:google-cloud-dataproc:4.43.0'
SBT
libraryDependencies += "com.google.cloud" % "google-cloud-dataproc" % "4.43.0"
Python
이 샘플을 사용해 보기 전에 Managed Service for Apache Spark 빠른 시작: 클라이언트 라이브러리 사용의 Python 설정 안내를 따르세요. 자세한 내용은 Managed Service for Apache Spark Python API 참조 문서를 참고하세요.
Managed Service for Apache Spark에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
반복 일괄 워크로드를 제출할 때마다 Managed Service for Apache Spark 자동 조정을 사용 설정하려면 다음 필드가 포함된 Batch를 사용하여 BatchControllerClient.create_batch를 호출합니다.
batch.runtime_config.cohort: 배치를 일련의 반복되는 워크로드 중 하나로 식별하는 동질 집단 이름. 이 동질 집단 이름으로 제출된 두 번째 및 후속 워크로드에 자동 조정이 적용됩니다. 예를 들어 일일 판매 집계 태스크를 실행하는 예약된 일괄 워크로드의 동질 집단 이름으로daily_sales_aggregation을 지정할 수 있습니다.batch.runtime_config.autotuning_config.scenarios: Spark 배치 워크로드에서 자동 조정을 사용 설정하려면AUTO을 지정합니다.
예:
# Create a client
client = dataproc_v1.BatchControllerClient()
# Initialize request argument(s)
batch = dataproc_v1.Batch()
batch.pyspark_batch.main_python_file_uri = "gs://bucket/run_tpcds.py"
batch.runtime_config.cohort = "daily_sales_aggregation"
batch.runtime_config.autotuning_config.scenarios = [
Scenario.AUTO
]
request = dataproc_v1.CreateBatchRequest(
parent="parent_value",
batch=batch,
)
# Make the request
operation = client.create_batch(request=request)
API를 사용하려면 google-cloud-dataproc 클라이언트 라이브러리 버전 5.10.1 이상을 사용해야 합니다. 프로젝트에 추가하려면 다음 요구사항을 사용하면 됩니다.
google-cloud-dataproc>=5.10.1
Airflow
자동 조정된 각 배치 동질 집단을 수동으로 제출하는 대신 Airflow를 사용하여 반복 일괄 워크로드의 제출을 예약할 수 있습니다. 이렇게 하려면 다음 필드가 포함된 Batch를 사용하여 BatchControllerClient.create_batch를 호출합니다.
batch.runtime_config.cohort: 배치를 일련의 반복되는 워크로드 중 하나로 식별하는 동질 집단 이름. 이 동질 집단 이름으로 제출된 두 번째 및 후속 워크로드에 자동 조정이 적용됩니다. 예를 들어 일일 판매 집계 작업을 실행하는 예약된 일괄 워크로드의 동질 집단 이름으로daily_sales_aggregation을 지정할 수 있습니다.batch.runtime_config.autotuning_config.scenarios: Spark 배치 워크로드에서 자동 조정을 사용 설정하려면AUTO을 지정합니다.
예:
create_batch = DataprocCreateBatchOperator(
task_id="batch_create",
batch={
"pyspark_batch": {
"main_python_file_uri": PYTHON_FILE_LOCATION,
},
"environment_config": {
"peripherals_config": {
"spark_history_server_config": {
"dataproc_cluster": PHS_CLUSTER_PATH,
},
},
},
"runtime_config": {
"cohort": "daily_sales_aggregation",
"autotuning_config": {
"scenarios": [
Scenario.AUTO,
]
}
},
},
batch_id="BATCH_ID",
)
API를 사용하려면 google-cloud-dataproc 클라이언트 라이브러리 버전 5.10.1 이상을 사용해야 합니다. 다음 Airflow 환경 요구사항을 사용할 수 있습니다.
google-cloud-dataproc>=5.10.1
Managed Service for Apache Airflow에서 패키지를 업데이트하려면 Managed Airflow용 Python 종속 항목 설치 를 참고하세요.
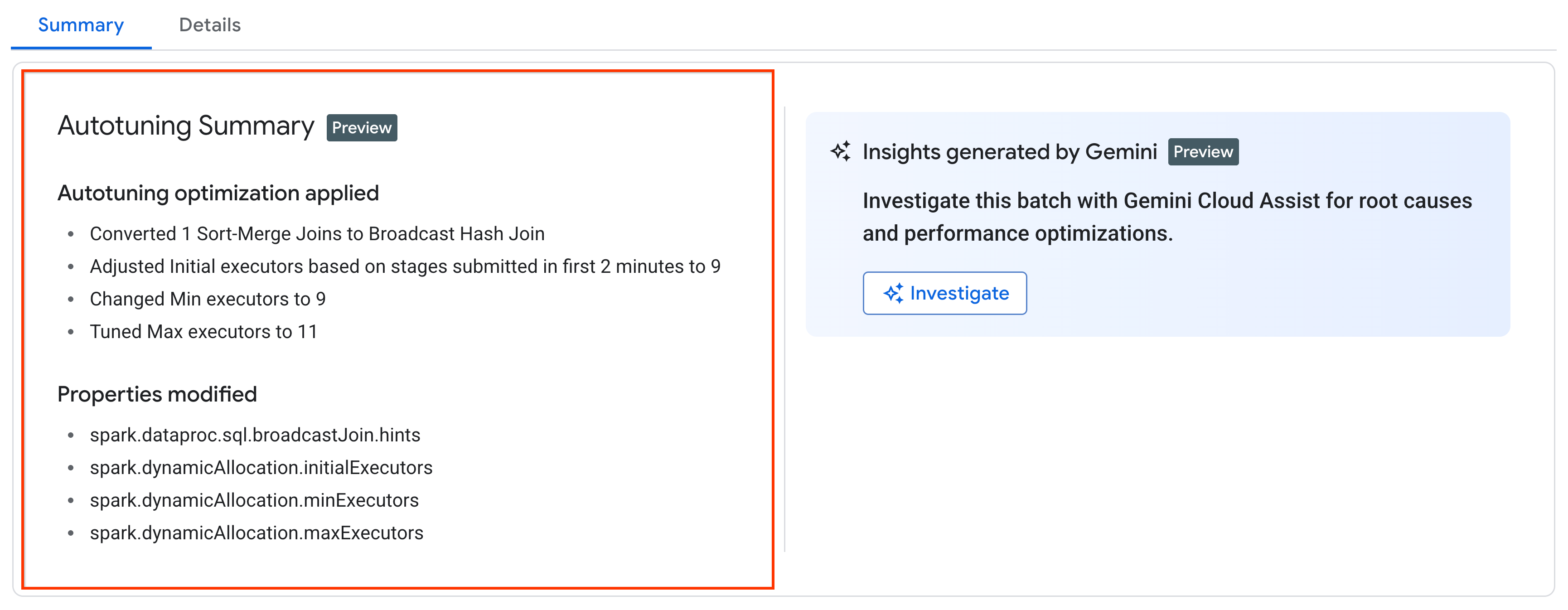
자동 조정 변경사항 보기
일괄 워크로드에 대한 Managed Service for Apache Spark 자동 조정 변경사항을 보려면 gcloud dataproc batches describe 명령어를 실행하세요.
예시: gcloud dataproc batches describe 출력은 다음과 비슷합니다.
...
runtimeInfo:
propertiesInfo:
# Properties set by autotuning.
autotuningProperties:
spark.dataproc.sql.broadcastJoin.hints:
annotation: Converted 1 Sort-Merge Joins to Broadcast Hash Join
value: v2;Inner,<hint>
spark.dynamicAllocation.initialExecutors:
annotation: Adjusted Initial executors based on stages submitted in first
2 minutes to 9
overriddenValue: '2'
value: '9'
spark.dynamicAllocation.maxExecutors:
annotation: Tuned Max executors to 11
overriddenValue: '5'
value: '11'
spark.dynamicAllocation.minExecutors:
annotation: Changed Min executors to 9
overriddenValue: '2'
value: '9'
...
Google Cloud 콘솔의 일괄 세부정보 페이지의 요약 탭에서 실행, 완료 또는 실패한 워크로드에 적용된 최근 자동 조정 변경사항을 확인할 수 있습니다.
가격 책정
Managed Service for Apache Spark 자동 조정은 비공개 미리보기 중에 추가 비용 없이 제공됩니다. 표준 Managed Service for Apache Spark 가격 책정이 적용됩니다.