
Este documento descreve como atualizar uma tarefa de streaming em curso. Pode querer atualizar a tarefa do Dataflow existente pelos seguintes motivos:
- Quiser melhorar o código do pipeline.
- Quer corrigir erros no código do pipeline.
- Quer atualizar o pipeline para processar alterações no formato de dados ou ter em conta a versão ou outras alterações na sua origem de dados.
- Quer aplicar uma correção a uma vulnerabilidade de segurança relacionada com o SO otimizado para contentores para todos os trabalhadores do Dataflow.
- Quer dimensionar um pipeline de streaming do Apache Beam para usar um número diferente de trabalhadores.
Pode atualizar as tarefas de duas formas:
- Atualização de tarefas em curso: para tarefas de streaming que usam o Streaming Engine, pode atualizar as opções de tarefas
min-num-workersemax-num-workerssem parar a tarefa nem alterar o ID da tarefa. - Trabalho de substituição: para executar código de pipeline atualizado ou para atualizar opções de trabalho que as atualizações de trabalho em curso não suportam, inicie um novo trabalho que substitua o trabalho existente. Para verificar se uma tarefa de substituição é válida, antes de iniciar a nova tarefa, valide o respetivo gráfico de tarefas.
Quando atualiza a sua tarefa, o serviço Dataflow realiza uma verificação de compatibilidade entre a tarefa em execução e a potencial tarefa de substituição. A verificação de compatibilidade garante que as informações de estado intermédio e os dados em buffer podem ser transferidos da tarefa anterior para a tarefa de substituição.
Também pode usar a infraestrutura de registo incorporada do SDK Apache Beam para registar informações quando atualiza a tarefa. Para mais informações, consulte o artigo
Trabalhe com registos de pipelines.
Para identificar problemas com o código do pipeline, use o
DEBUG nível de registo.
- Para obter instruções sobre como atualizar tarefas de streaming que usam modelos clássicos, consulte o artigo Atualize uma tarefa de streaming de modelo personalizado.
- Para ver instruções sobre como atualizar tarefas de streaming que usam modelos flexíveis, siga as instruções da CLI gcloud nesta página ou consulte o artigo Atualize uma tarefa de modelo flexível.
Atualização da opção de tarefa em voo
Para uma tarefa de streaming que usa o Streaming Engine, pode atualizar as seguintes opções de tarefas sem parar a tarefa nem alterar o ID da tarefa:
min-num-workers: o número mínimo de instâncias do Compute Engine.max-num-workers: o número máximo de instâncias do Compute Engine.worker-utilization-hint: a utilização da CPU alvo>, no intervalo [0,1, 0,9]
Para outras atualizações de trabalhos, tem de substituir o trabalho atual pelo trabalho atualizado. Para mais informações, consulte o artigo Inicie um trabalho de substituição.
Faça uma atualização em voo
Para fazer uma atualização da opção de tarefa em curso, siga estes passos.
gcloud
Use o comando gcloud dataflow jobs update-options:
gcloud dataflow jobs update-options \ --region=REGION \ --min-num-workers=MINIMUM_WORKERS \ --max-num-workers=MAXIMUM_WORKERS \ --worker-utilization-hint=TARGET_UTILIZATION \ JOB_ID
Substitua o seguinte:
- REGION: o ID da região da tarefa
- MINIMUM_WORKERS: o número mínimo de instâncias do Compute Engine
- MAXIMUM_WORKERS: o número máximo de instâncias do Compute Engine
- TARGET_UTILIZATION: um valor no intervalo [0,1, 0,9]
- JOB_ID: o ID da tarefa a atualizar
Também pode atualizar --min-num-workers, --max-num-workers e
worker-utilization-hint individualmente.
REST
Use o método
projects.locations.jobs.update:
PUT https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID?updateMask=MASK { "runtime_updatable_params": { "min_num_workers": MINIMUM_WORKERS, "max_num_workers": MAXIMUM_WORKERS, "worker_utilization_hint": TARGET_UTILIZATION } }
Substitua o seguinte:
- MASK: uma lista de parâmetros separados por vírgulas a atualizar, a partir do seguinte:
runtime_updatable_params.max_num_workersruntime_updatable_params.min_num_workersruntime_updatable_params.worker_utilization_hint
- PROJECT_ID: o Google Cloud ID do projeto da tarefa do Dataflow
- REGION: o ID da região da tarefa
- JOB_ID: o ID da tarefa a atualizar
- MINIMUM_WORKERS: o número mínimo de instâncias do Compute Engine
- MAXIMUM_WORKERS: o número máximo de instâncias do Compute Engine
- TARGET_UTILIZATION: um valor no intervalo [0,1, 0,9]
Também pode atualizar min_num_workers, max_num_workers e worker_utilization_hint individualmente.
Especifique os parâmetros a atualizar no parâmetro de consulta updateMask e inclua os valores atualizados no campo runtimeUpdatableParams do corpo do pedido. O exemplo seguinte atualiza min_num_workers:
PUT https://dataflow.googleapis.com/v1b3/projects/my_project/locations/us-central1/jobs/job1?updateMask=runtime_updatable_params.min_num_workers { "runtime_updatable_params": { "min_num_workers": 5 } }
Um trabalho tem de estar em execução para ser elegível para atualizações em curso. Ocorre um erro se a tarefa não tiver sido iniciada ou já tiver sido cancelada. Da mesma forma, se iniciar uma tarefa de substituição, aguarde que comece a ser executada antes de enviar atualizações em curso para a nova tarefa.
Depois de enviar um pedido de atualização, recomendamos que aguarde pela conclusão do pedido antes de enviar outra atualização. Veja os registos de tarefas para saber quando o pedido é concluído.
Valide uma tarefa de substituição
Para verificar se uma tarefa de substituição é válida, antes de iniciar a nova tarefa, valide o respetivo gráfico de tarefas. No Dataflow, um gráfico de tarefas é uma representação gráfica de um pipeline. Ao validar o gráfico de tarefas, reduz o risco de o pipeline encontrar erros ou falhas após a atualização. Além disso, pode validar as atualizações sem ter de parar a tarefa original, para que esta não sofra qualquer tempo de inatividade.
Para validar o seu gráfico de tarefas, siga os passos para iniciar uma tarefa de substituição. Inclua a graph_validate_only
opção de serviço Dataflow no comando de atualização.
Java
- Transmita a opção
--update. - Defina a opção
--jobNameemPipelineOptionscom o mesmo nome da tarefa que quer atualizar. - Defina a opção
--regionpara a mesma região que a região da tarefa que quer atualizar. - Inclua a opção de serviço
--dataflowServiceOptions=graph_validate_only. - Se algum nome de transformação no seu pipeline tiver sido alterado, tem de fornecer um
mapeamento de transformações e transmiti-lo através da opção
--transformNameMapping. - Se estiver a enviar um trabalho de substituição que usa uma versão posterior do SDK do Apache Beam, defina
--updateCompatibilityVersionpara a versão do SDK do Apache Beam usada no trabalho original.
Python
- Transmita a opção
--update. - Defina a opção
--job_nameemPipelineOptionscom o mesmo nome da tarefa que quer atualizar. - Defina a opção
--regionpara a mesma região que a região da tarefa que quer atualizar. - Inclua a opção de serviço
--dataflow_service_options=graph_validate_only. - Se algum nome de transformação no seu pipeline tiver sido alterado, tem de fornecer um
mapeamento de transformações e transmiti-lo através da opção
--transform_name_mapping. - Se estiver a enviar um trabalho de substituição que usa uma versão posterior do SDK do Apache Beam, defina
--updateCompatibilityVersionpara a versão do SDK do Apache Beam usada no trabalho original.
Go
- Transmita a opção
--update. - Defina a opção
--job_namecom o mesmo nome da tarefa que quer atualizar. - Defina a opção
--regionpara a mesma região que a região da tarefa que quer atualizar. - Inclua a opção de serviço
--dataflow_service_options=graph_validate_only. - Se algum nome de transformação no seu pipeline tiver sido alterado, tem de fornecer um
mapeamento de transformações e transmiti-lo através da opção
--transform_name_mapping.
gcloud
Para validar o gráfico de tarefas de uma tarefa de modelo flexível, use o comando
gcloud dataflow flex-template run
com a opção additional-experiments:
- Transmita a opção
--update. - Defina o JOB_NAME com o mesmo nome da tarefa que quer atualizar.
- Defina a opção
--regionpara a mesma região que a região da tarefa que quer atualizar. - Inclua a opção
--additional-experiments=graph_validate_only. - Se algum nome de transformação no seu pipeline tiver sido alterado, tem de fornecer um
mapeamento de transformações e transmiti-lo através da opção
--transform-name-mappings.
Por exemplo:
gcloud dataflow flex-template run JOB_NAME --additional-experiments=graph_validate_only
Substitua JOB_NAME pelo nome da tarefa que quer atualizar.
REST
Use o campo additionalExperiments no objeto
FlexTemplateRuntimeEnvironment
(modelos flexíveis) ou
RuntimeEnvironment.
{
additionalExperiments : ["graph_validate_only"]
...
}
A graph_validate_onlyopção de serviço
só valida atualizações de pipelines. Não use esta opção quando criar ou iniciar pipelines. Para atualizar o pipeline,
inicie uma tarefa de substituição sem a opção de serviço
graph_validate_only.
Quando a validação do gráfico de tarefas é bem-sucedida, o estado da tarefa e os registos da tarefa mostram os seguintes estados:
- O estado da tarefa é
JOB_STATE_DONE. - Na Google Cloud consola, o estado da tarefa
é
Succeeded. A seguinte mensagem é apresentada nos registos de tarefas:
Workflow job: JOB_ID succeeded validation. Marking graph_validate_only job as Done.
Quando a validação do gráfico de tarefas falha, o estado da tarefa e os registos da tarefa mostram os seguintes estados:
- O estado da tarefa é
JOB_STATE_FAILED. - Na Google Cloud consola, o estado da tarefa
é
Failed. - É apresentada uma mensagem nos registos de tarefas a descrever o erro de incompatibilidade. O conteúdo da mensagem depende do erro.
Inicie uma tarefa de substituição
Pode substituir uma tarefa existente pelos seguintes motivos:
- Para executar o código do pipeline atualizado.
- Para atualizar opções de tarefas que não suportam atualizações em tempo real.
Para verificar se uma tarefa de substituição é válida, antes de iniciar a nova tarefa, valide o respetivo gráfico de tarefas.
Quando inicia uma tarefa de substituição, defina as seguintes opções de pipeline para realizar o processo de atualização, além das opções normais da tarefa:
Java
- Transmita a opção
--update. - Defina a opção
--jobNameemPipelineOptionscom o mesmo nome da tarefa que quer atualizar. - Defina a opção
--regionpara a mesma região que a região da tarefa que quer atualizar. - Se algum nome de transformação no seu pipeline tiver sido alterado, tem de fornecer um
mapeamento de transformações e transmiti-lo através da opção
--transformNameMapping. - Se estiver a enviar um trabalho de substituição que usa uma versão posterior do SDK do Apache Beam, defina
--updateCompatibilityVersionpara a versão do SDK do Apache Beam usada no trabalho original.
Python
- Transmita a opção
--update. - Defina a opção
--job_nameemPipelineOptionscom o mesmo nome da tarefa que quer atualizar. - Defina a opção
--regionpara a mesma região que a região da tarefa que quer atualizar. - Se algum nome de transformação no seu pipeline tiver sido alterado, tem de fornecer um
mapeamento de transformações e transmiti-lo através da opção
--transform_name_mapping. - Se estiver a enviar um trabalho de substituição que usa uma versão posterior do SDK do Apache Beam, defina
--updateCompatibilityVersionpara a versão do SDK do Apache Beam usada no trabalho original.
Go
- Transmita a opção
--update. - Defina a opção
--job_namecom o mesmo nome da tarefa que quer atualizar. - Defina a opção
--regionpara a mesma região que a região da tarefa que quer atualizar. - Se algum nome de transformação no seu pipeline tiver sido alterado, tem de fornecer um
mapeamento de transformações e transmiti-lo através da opção
--transform_name_mapping.
gcloud
Para atualizar uma tarefa de modelo flexível através da CLI gcloud, use o comando
gcloud dataflow flex-template run. A atualização de outros trabalhos através da CLI gcloud não é suportada.
- Transmita a opção
--update. - Defina o JOB_NAME com o mesmo nome da tarefa que quer atualizar.
- Defina a opção
--regionpara a mesma região que a região da tarefa que quer atualizar. - Se algum nome de transformação no seu pipeline tiver sido alterado, tem de fornecer um
mapeamento de transformações e transmiti-lo através da opção
--transform-name-mappings.
REST
Estas instruções mostram como atualizar tarefas que não usam modelos através da API REST. Para usar a API REST para atualizar uma tarefa de modelo clássico, consulte o artigo Atualize uma tarefa de streaming de modelo personalizado. Para usar a API REST para atualizar uma tarefa de modelo flexível, consulte o artigo Atualize uma tarefa de modelo flexível.
Obtenha o recurso
jobpara a tarefa que quer substituir através do métodoprojects.locations.jobs.get. Inclua o parâmetro de consultaviewcom o valorJOB_VIEW_DESCRIPTION. A inclusão deJOB_VIEW_DESCRIPTIONlimita a quantidade de dados na resposta para que o pedido subsequente não exceda os limites de tamanho. Se precisar de informações mais detalhadas sobre a tarefa, use o valorJOB_VIEW_ALL.GET https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID?view=JOB_VIEW_DESCRIPTIONSubstitua os seguintes valores:
- PROJECT_ID: o Google Cloud ID do projeto da tarefa do Dataflow
- REGION: a região da tarefa que quer atualizar
- JOB_ID: o ID da tarefa que quer atualizar
Para atualizar a tarefa, use o método
projects.locations.jobs.create. No corpo do pedido, use o recursojobque obteve.POST https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs { "id": JOB_ID, "replaceJobId": JOB_ID, "name": JOB_NAME, "type": "JOB_TYPE_STREAMING", "transformNameMapping": { string: string, ... }, }Substitua o seguinte:
- JOB_ID: o mesmo ID da tarefa que o ID da tarefa que quer atualizar.
- JOB_NAME: o mesmo nome da tarefa que o nome da tarefa que quer atualizar.
Se os nomes de alguma transformação no seu pipeline tiverem sido alterados, tem de fornecer um mapeamento de transformações e transmiti-lo através do campo
transformNameMapping.Opcional: para enviar o seu pedido através do curl (Linux, macOS ou Cloud Shell), guarde o pedido num ficheiro JSON e, em seguida, execute o seguinte comando:
curl -X POST -d "@FILE_PATH" -H "Content-Type: application/json" -H "Authorization: Bearer $(gcloud auth print-access-token)" https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobsSubstitua FILE_PATH pelo caminho para o ficheiro JSON que contém o corpo do pedido.
Especifique o nome do trabalho de substituição
Java
Quando iniciar a tarefa de substituição, o valor que transmite para a opção --jobName
tem de corresponder exatamente ao nome da tarefa que quer substituir.
Python
Quando iniciar a tarefa de substituição, o valor que transmite para a opção --job_name
tem de corresponder exatamente ao nome da tarefa que quer substituir.
Go
Quando iniciar a tarefa de substituição, o valor que transmite para a opção --job_name
tem de corresponder exatamente ao nome da tarefa que quer substituir.
gcloud
Quando inicia o trabalho de substituição, o JOB_NAME tem de corresponder exatamente ao nome do trabalho que quer substituir.
REST
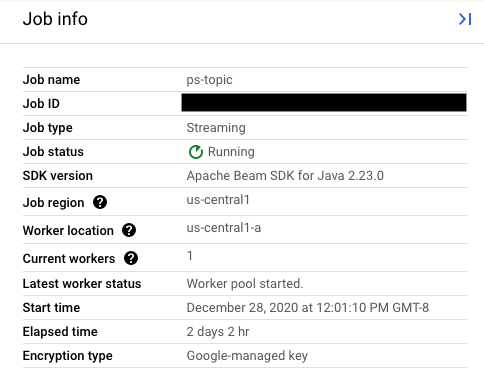
Defina o valor do campo replaceJobId para o mesmo ID da tarefa que quer atualizar. Para encontrar o valor do nome da tarefa correto, selecione a tarefa anterior na interface de monitorização do Dataflow.
Em seguida, no painel lateral Informações da tarefa, encontre o campo ID da tarefa.
Para encontrar o valor do nome da tarefa correto, selecione a tarefa anterior na interface de monitorização do Dataflow. Em seguida, no painel lateral Informações do trabalho, encontre o campo Nome do trabalho:
Em alternativa, consulte uma lista de tarefas existentes através da interface de linhas de comando do Dataflow.
Introduza o comando gcloud dataflow jobs list na janela da shell ou do terminal para obter uma lista de tarefas do Dataflow no seu projeto do Google Cloud Platform e encontre o campo NAME para a tarefa que quer substituir:
JOB_ID NAME TYPE CREATION_TIME STATE REGION 2020-12-28_12_01_09-yourdataflowjobid ps-topic Streaming 2020-12-28 20:01:10 Running us-central1
Crie um mapeamento de transformações
Se a pipeline de substituição alterar os nomes de transformações dos nomes na pipeline anterior, o serviço Dataflow requer um mapeamento de transformações. O mapeamento de transformações mapeia as transformações com nome no código do pipeline anterior para nomes no código do pipeline de substituição.
Java
Transmita o mapeamento através da opção de linha de comandos --transformNameMapping, usando o seguinte formato geral:
--transformNameMapping= .
{"oldTransform1":"newTransform1","oldTransform2":"newTransform2",...}
Só tem de fornecer entradas de mapeamento em --transformNameMapping para nomes de transformações que tenham sido alterados entre o pipeline anterior e o pipeline de substituição.
Quando executa com --transformNameMapping, pode ter de escapar às aspas conforme adequado para o seu shell. Por exemplo, no Bash:
--transformNameMapping='{"oldTransform1":"newTransform1",...}'
Python
Transmita o mapeamento através da opção de linha de comandos --transform_name_mapping, usando o seguinte formato geral:
--transform_name_mapping= .
{"oldTransform1":"newTransform1","oldTransform2":"newTransform2",...}
Só tem de fornecer entradas de mapeamento em --transform_name_mapping para nomes de transformações que tenham sido alterados entre o pipeline anterior e o pipeline de substituição.
Quando executa com --transform_name_mapping, pode ter de escapar às aspas conforme adequado para o seu shell. Por exemplo, no Bash:
--transform_name_mapping='{"oldTransform1":"newTransform1",...}'
Go
Transmita o mapeamento através da opção de linha de comandos --transform_name_mapping, usando o seguinte formato geral:
--transform_name_mapping= .
{"oldTransform1":"newTransform1","oldTransform2":"newTransform2",...}
Só tem de fornecer entradas de mapeamento em --transform_name_mapping para nomes de transformações que tenham sido alterados entre o pipeline anterior e o pipeline de substituição.
Quando executa com --transform_name_mapping, pode ter de escapar às aspas conforme adequado para o seu shell. Por exemplo, no Bash:
--transform_name_mapping='{"oldTransform1":"newTransform1",...}'
gcloud
Transmita o mapeamento através da opção --transform-name-mappings
com o seguinte formato geral:
--transform-name-mappings= .
{"oldTransform1":"newTransform1","oldTransform2":"newTransform2",...}
Só tem de fornecer entradas de mapeamento em --transform-name-mappings para nomes de transformações que tenham sido alterados entre o pipeline anterior e o pipeline de substituição.
Quando executa o comando com --transform-name-mappings,
pode ter de escapar às aspas conforme adequado para o seu shell. Por
exemplo, no Bash:
--transform-name-mappings='{"oldTransform1":"newTransform1",...}'
REST
Transmita o mapeamento através do campo transformNameMapping
com o seguinte formato geral:
"transformNameMapping": {
oldTransform1: newTransform1,
oldTransform2: newTransform2,
...
}
Só tem de fornecer entradas de mapeamento em transformNameMapping para nomes de transformações que tenham sido alterados entre o pipeline anterior e o pipeline de substituição.
Determine os nomes das transformações
O nome da transformação em cada instância no mapa é o nome que forneceu quando aplicou a transformação no seu pipeline. Por exemplo:
Java
.apply("FormatResults", ParDo
.of(new DoFn<KV<String, Long>>, String>() {
...
}
}))
Python
| 'FormatResults' >> beam.ParDo(MyDoFn())
Go
// In Go, this is always the package-qualified name of the DoFn itself.
// For example, if the FormatResults DoFn is in the main package, its name
// is "main.FormatResults".
beam.ParDo(s, FormatResults, results)
Também pode obter os nomes das transformações da tarefa anterior examinando o gráfico de execução da tarefa na interface de monitorização do Dataflow:
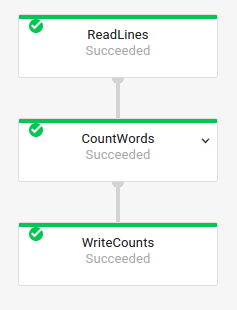
Nomenclatura da transformação composta
Os nomes das transformações são hierárquicos, com base na hierarquia de transformações no seu pipeline. Se o seu pipeline tiver uma transformação composta, as transformações aninhadas são denominadas em função da transformação que as contém. Por exemplo, suponhamos que o seu pipeline contém uma transformação composta denominada CountWidgets, que contém uma transformação interna denominada Parse. O nome completo da transformação é CountWidgets/Parse e tem de especificar esse nome completo no mapeamento da transformação.
Se o novo pipeline mapear uma transformação composta para um nome diferente, todas as transformações aninhadas também são automaticamente renomeadas. Tem de especificar os nomes alterados das transformações internas no mapeamento de transformações.
Refatore a hierarquia de transformações
Se a pipeline de substituição usar uma hierarquia de transformações diferente da pipeline anterior, tem de declarar explicitamente o mapeamento. Pode ter uma hierarquia de transformações diferente porque refatorou as transformações compostas ou o seu pipeline depende de uma transformação composta de uma biblioteca que foi alterada.
Por exemplo, o pipeline anterior aplicou uma transformação composta, CountWidgets, que continha uma transformação interna denominada Parse. O pipeline de substituição
refatora CountWidgets e aninha Parse noutra transformação denominada
Scan. Para que a atualização seja bem-sucedida, tem de mapear explicitamente o nome da transformação completo no pipeline anterior (CountWidgets/Parse) para o nome da transformação no novo pipeline (CountWidgets/Scan/Parse):
Java
--transformNameMapping={"CountWidgets/Parse":"CountWidgets/Scan/Parse"}
Se eliminar completamente uma transformação no pipeline de substituição, tem de
fornecer um mapeamento nulo. Suponhamos que a pipeline de substituição remove completamente a transformação CountWidgets/Parse:
--transformNameMapping={"CountWidgets/Parse":""}
Python
--transform_name_mapping={"CountWidgets/Parse":"CountWidgets/Scan/Parse"}
Se eliminar completamente uma transformação no pipeline de substituição, tem de
fornecer um mapeamento nulo. Suponhamos que a pipeline de substituição remove completamente a transformação CountWidgets/Parse:
--transform_name_mapping={"CountWidgets/Parse":""}
Go
--transform_name_mapping={"CountWidgets/main.Parse":"CountWidgets/Scan/main.Parse"}
Se eliminar completamente uma transformação no pipeline de substituição, tem de
fornecer um mapeamento nulo. Suponhamos que a pipeline de substituição remove completamente a transformação CountWidgets/Parse:
--transform_name_mapping={"CountWidgets/main.Parse":""}
gcloud
--transform-name-mappings={"CountWidgets/Parse":"CountWidgets/Scan/Parse"}
Se eliminar completamente uma transformação no pipeline de substituição, tem de
fornecer um mapeamento nulo. Suponhamos que a pipeline de substituição remove completamente a transformação CountWidgets/Parse:
--transform-name-mappings={"CountWidgets/main.Parse":""}
REST
"transformNameMapping": {
CountWidgets/Parse: CountWidgets/Scan/Parse
}
Se eliminar completamente uma transformação no pipeline de substituição, tem de
fornecer um mapeamento nulo. Suponhamos que a pipeline de substituição remove completamente a transformação CountWidgets/Parse:
"transformNameMapping": {
CountWidgets/main.Parse: null
}
Os efeitos da substituição de um trabalho
Quando substitui uma tarefa existente, uma nova tarefa executa o código do pipeline atualizado. O serviço Dataflow retém o nome da tarefa, mas executa a tarefa de substituição com um ID da tarefa atualizado. Este processo pode causar tempo de inatividade enquanto a tarefa existente é interrompida, a verificação de compatibilidade é executada e a nova tarefa é iniciada.
A substituição preserva os seguintes itens:
- Dados do estado intermédio do trabalho anterior. As caches na memória não são guardadas.
- Registos de dados em buffer ou metadados atualmente "em voo" da tarefa anterior. Por exemplo, alguns registos no seu pipeline podem ser armazenados em buffer enquanto aguardam que uma janela seja resolvida.
- Atualizações de opções de tarefas em curso que aplicou à tarefa anterior.
Dados de estado intermédio
Os dados do estado intermédio da tarefa anterior são preservados. Os dados de estado não incluem caches na memória. Se quiser preservar os dados da cache na memória quando atualizar a sua pipeline, como solução alternativa, refatore a pipeline para converter as caches em dados de estado ou em entradas laterais. Para mais informações sobre a utilização de entradas laterais, consulte os Padrões de entrada lateral na documentação do Apache Beam.
Os pipelines de streaming têm limites de tamanho para ValueState e para entradas laterais.
Como resultado, se tiver grandes caches que queira preservar, pode ter de usar armazenamento externo, como o Memorystore ou o Bigtable.
Dados em voo
Os dados "em voo" continuam a ser processados pelas transformações no novo pipeline. No entanto, as transformações adicionais que adicionar no código do pipeline de substituição podem ou não entrar em vigor, consoante o local onde os registos são colocados em buffer. Neste exemplo, o pipeline existente tem as seguintes transformações:
Java
p.apply("Read", ReadStrings())
.apply("Format", FormatStrings());
Python
p | 'Read' >> beam.io.ReadFromPubSub(subscription=known_args.input_subscription)
| 'Format' >> FormatStrings()
Go
beam.ParDo(s, ReadStrings) beam.ParDo(s, FormatStrings)
Pode substituir a tarefa por um novo código de pipeline da seguinte forma:
Java
p.apply("Read", ReadStrings())
.apply("Remove", RemoveStringsStartingWithA())
.apply("Format", FormatStrings());
Python
p | 'Read' >> beam.io.ReadFromPubSub(subscription=known_args.input_subscription)
| 'Remove' >> RemoveStringsStartingWithA()
| 'Format' >> FormatStrings()
Go
beam.ParDo(s, ReadStrings) beam.ParDo(s, RemoveStringsStartingWithA) beam.ParDo(s, FormatStrings)
Mesmo que adicione uma transformação para filtrar as strings que começam pela letra "A", a transformação seguinte (FormatStrings) pode continuar a ver strings em buffer ou em curso que começam por "A" e que foram transferidas do trabalho anterior.
Alterar a segmentação por tempo
Pode alterar as estratégias de janelas e de acionamento para os elementos PCollection na sua pipeline de substituição, mas tenha cuidado.
A alteração das estratégias de acionamento ou de janelas não afeta os dados que já estão em buffer ou em trânsito.
Recomendamos que tente apenas alterações mais pequenas à segmentação por tempo da sua pipeline, como alterar a duração das janelas de tempo fixas ou deslizantes. Fazer alterações significativas à análise de janelas ou aos acionadores, como alterar o algoritmo de análise de janelas, pode ter resultados imprevisíveis na saída do pipeline.
Verificação da compatibilidade do trabalho
Quando inicia a tarefa de substituição, o serviço Dataflow efetua uma verificação de compatibilidade entre a tarefa de substituição e a tarefa anterior. Se a verificação de compatibilidade for aprovada, a tarefa anterior é interrompida. Em seguida, a tarefa de substituição é iniciada no serviço Dataflow, mantendo o mesmo nome da tarefa. Se a verificação de compatibilidade falhar, a tarefa anterior continua a ser executada no serviço Dataflow e a tarefa de substituição devolve um erro.
Java
Devido a uma limitação, tem de usar o bloqueio da execução para ver erros de tentativas de atualização falhadas na consola ou no terminal. A solução alternativa atual consiste nos seguintes passos:
- Use pipeline.run().waitUntilFinish() no código do pipeline.
- Execute o seu programa de pipeline de substituição com a opção
--update. - Aguarde até que a tarefa de substituição passe com êxito na verificação de compatibilidade.
- Saia do processo de execução do bloqueio escrevendo
Ctrl+C.
Em alternativa, pode monitorizar o estado da tarefa de substituição na interface de monitorização do Dataflow. Se a tarefa tiver sido iniciada com êxito, também passou na verificação de compatibilidade.
Python
Devido a uma limitação, tem de usar o bloqueio da execução para ver erros de tentativas de atualização falhadas na consola ou no terminal. A solução alternativa atual consiste nos seguintes passos:
- Use pipeline.run().wait_until_finish() no código do pipeline.
- Execute o seu programa de pipeline de substituição com a opção
--update. - Aguarde até que a tarefa de substituição passe com êxito na verificação de compatibilidade.
- Saia do processo de execução do bloqueio escrevendo
Ctrl+C.
Em alternativa, pode monitorizar o estado da tarefa de substituição na interface de monitorização do Dataflow. Se a tarefa tiver sido iniciada com êxito, também passou na verificação de compatibilidade.
Go
Devido a uma limitação, tem de usar o bloqueio da execução para ver erros de tentativas de atualização falhadas na consola ou no terminal.
Em concreto, tem de especificar a execução sem bloqueio através das flags --execute_async ou --async. A solução alternativa atual consiste nos seguintes passos:
- Execute o programa da pipeline de substituição com a opção
--updatee sem os flags--execute_asyncou--async. - Aguarde até que a tarefa de substituição passe com êxito na verificação de compatibilidade.
- Saia do processo de execução do bloqueio escrevendo
Ctrl+C.
gcloud
Devido a uma limitação, tem de usar o bloqueio da execução para ver erros de tentativas de atualização falhadas na consola ou no terminal. A solução alternativa atual consiste nos seguintes passos:
- Para pipelines Java, use pipeline.run().waitUntilFinish() no código do pipeline. Para pipelines Python, use pipeline.run().wait_until_finish() no código do pipeline. Para pipelines Go, siga os passos no separador Go.
- Execute o seu programa de pipeline de substituição com a opção
--update. - Aguarde até que a tarefa de substituição passe com êxito na verificação de compatibilidade.
- Saia do processo de execução do bloqueio escrevendo
Ctrl+C.
REST
Devido a uma limitação, tem de usar o bloqueio da execução para ver erros de tentativas de atualização falhadas na consola ou no terminal. A solução alternativa atual consiste nos seguintes passos:
- Para pipelines Java, use pipeline.run().waitUntilFinish() no código do pipeline. Para pipelines Python, use pipeline.run().wait_until_finish() no código do pipeline. Para pipelines Go, siga os passos no separador Go.
- Execute o seu programa de pipeline de substituição com o campo
replaceJobId. - Aguarde até que a tarefa de substituição passe com êxito na verificação de compatibilidade.
- Saia do processo de execução do bloqueio escrevendo
Ctrl+C.
A verificação de compatibilidade usa o mapeamento de transformações fornecido para garantir que o Dataflow pode transferir dados de estado intermédio dos passos na sua tarefa anterior para a tarefa de substituição. A verificação de compatibilidade também garante que os PCollections no seu pipeline estão a usar os mesmos codificadores.
A alteração de um Coder pode fazer com que a verificação de compatibilidade falhe, porque os dados em curso ou os registos em buffer podem não ser serializados corretamente no pipeline de substituição.
Evite falhas de compatibilidade
Determinadas diferenças entre o pipeline anterior e o pipeline de substituição podem fazer com que a verificação de compatibilidade falhe. Estas diferenças incluem:
- Alterar o gráfico do pipeline sem fornecer um mapeamento. Quando atualiza uma tarefa, o Dataflow tenta fazer corresponder as transformações na tarefa anterior às transformações na tarefa de substituição. Este processo de correspondência ajuda o Dataflow a transferir dados de estado intermédios para cada passo. Se mudar o nome ou remover quaisquer passos, tem de fornecer um mapeamento de transformações para que o Dataflow possa fazer corresponder os dados de estado em conformidade.
- Alterar as entradas laterais de um passo. Adicionar entradas laterais ou removê-las de uma transformação no pipeline de substituição faz com que a verificação de compatibilidade falhe.
- Alterar o programador de um passo. Quando atualiza uma tarefa, o Dataflow preserva todos os registos de dados atualmente em buffer e processa-os na tarefa de substituição. Por exemplo, podem ocorrer dados em buffer enquanto a aplicação de janelas está a ser resolvida. Se a tarefa de substituição usar uma codificação de dados diferente ou incompatível, o Dataflow não consegue serializar nem desserializar estes registos.
Remover uma operação "com estado" do seu pipeline. Se remover as operações com estado da sua pipeline, a tarefa de substituição pode falhar na verificação de compatibilidade. O fluxo de dados pode fundir vários passos para aumentar a eficiência. Se remover uma operação dependente do estado de um passo fundido, a verificação falha. As operações com estado incluem:
- Transformações que produzem ou consomem entradas laterais.
- Leituras de I/O.
- Transformações que usam o estado com chave.
- Transformações que têm união de janelas.
Alterar variáveis
DoFncom estado. Para tarefas de streaming contínuas, se o seu pipeline incluirDoFns com estado, a alteração das variáveisDoFncom estado pode fazer com que o pipeline falhe.Tentar executar a tarefa de substituição numa zona geográfica diferente. Execute a tarefa de substituição na mesma zona em que executou a tarefa anterior.
Atualizar esquemas
O Apache Beam permite que os PCollections tenham esquemas com campos com nomes, caso em que não são necessários codificadores explícitos. Se os nomes e os tipos dos campos de um determinado esquema
permanecerem inalterados (incluindo os campos aninhados), esse esquema não faz com que a
verificação de atualização falhe. No entanto, a atualização pode continuar bloqueada se outros segmentos do novo pipeline forem incompatíveis.
Evolua esquemas
Muitas vezes, é necessário desenvolver o esquema de um PCollection devido à evolução dos requisitos empresariais. O serviço Dataflow permite fazer as seguintes alterações a um esquema quando atualiza o pipeline:
- Adicionar um ou mais campos novos a um esquema, incluindo campos aninhados.
- Tornar um tipo de campo obrigatório (não anulável) opcional (anulável).
Não é permitido remover campos, alterar os nomes dos campos nem alterar os tipos de campos durante a atualização.
Transmita dados adicionais para uma operação ParDo existente
Pode transmitir dados adicionais (fora da banda) para uma operação ParDo existente através de um dos seguintes métodos, consoante o seu exemplo de utilização:
- Serializar informações como campos na sua subclasse
DoFn. - Todas as variáveis referenciadas pelos métodos num
DoFnanónimo são automaticamente serializadas. - Calcule os dados no
DoFn.startBundle(). - Transmita dados através da
ParDo.withSideInputs.
Para mais informações, consulte as seguintes páginas:
- Guia de programação do Apache Beam: ParDo, especificamente as secções sobre a criação de um DoFn e entradas laterais.
- Referência do SDK do Apache Beam para Java: ParDo