
이 튜토리얼에서는 Apache Beam YAML 구문을 사용하여 Dataflow 데이터 처리 파이프라인을 만드는 방법을 보여줍니다. Google Cloud 콘솔의 작업 빌더 UI를 사용하여 파일에서 데이터를 읽고, 변환을 적용하고, 결과를 다른 파일에 쓰는 방법을 알아봅니다. 이 튜토리얼은 Apache Beam을 처음 접하거나 YAML API를 사용하여 파이프라인을 빌드하는 방법을 배우려는 개발자를 대상으로 합니다.
다음 표는 Google Cloud 콘솔의 파이프라인 그래프와 해당 YAML 사양을 보여줍니다.
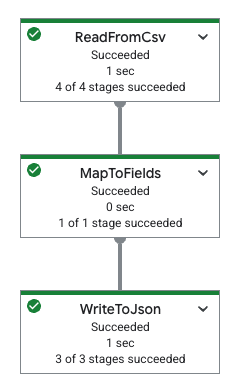
|
pipeline: transforms: - name: ReadFromCsv type: ReadFromCsv config: path: 'gs://[...]/restaurant-data.csv' - name: MapToFields type: MapToFields input: ReadFromCsv config: language: python fields: Lowercase_menu_item: Item.lower() Total_price: Price + Tax append: true - name: WriteToJson type: WriteToJson input: MapToFields config: path: 'gs://[...]/restaurant-data_map-fields.json' |
목표
이 튜토리얼에서는 다음 작업을 수행하는 방법을 알아봅니다.
- 데이터를 읽고 쓰고 변환하는 Beam YAML 파이프라인을 만듭니다.
- 콘텐츠를 기반으로 데이터를 필터링합니다.
- Python 표현식을 사용하여 필드를 매핑합니다.
- SQL을 사용하여 데이터를 쿼리하고 집계합니다.
- Google Cloud 콘솔의 작업 빌더 UI에서 빌더 양식을 사용하여 Beam YAML 파이프라인을 빌드하고 실행합니다.
비용
이 문서에서는 비용이 청구될 수 있는 Google Cloud구성요소를 사용합니다.
프로젝트 사용량을 기준으로 예상 비용을 산출하려면 가격 계산기를 사용하세요.
이 문서에 설명된 태스크를 완료했으면 만든 리소스를 삭제하여 청구가 계속되는 것을 방지할 수 있습니다. 자세한 내용은 삭제를 참조하세요.
시작하기 전에
파이프라인을 실행하기 전에 다음 단계를 완료하세요.
프로젝트 설정
- Google Cloud 계정에 로그인합니다. Google Cloud를 처음 사용하는 경우 계정을 만들고 Google 제품의 실제 성능을 평가해 보세요. 신규 고객에게는 워크로드를 실행, 테스트, 배포하는 데 사용할 수 있는 $300의 무료 크레딧이 제공됩니다.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataflow, Compute Engine, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the
serviceusage.services.enablepermission. If you created the project, then you likely already have this permission through the Owner role (roles/owner). Otherwise, you can get this permission through the Service Usage Admin role (roles/serviceusage.serviceUsageAdmin). Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataflow, Compute Engine, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the
serviceusage.services.enablepermission. If you created the project, then you likely already have this permission through the Owner role (roles/owner). Otherwise, you can get this permission through the Service Usage Admin role (roles/serviceusage.serviceUsageAdmin). Learn how to grant roles.
Cloud Storage 버킷 만들기
파이프라인을 실행하려면 먼저 Cloud Storage 버킷을 만들어야 합니다.
Cloud Storage 버킷을 만듭니다.
- Google Cloud 콘솔에서 Cloud Storage 버킷 페이지로 이동합니다.
- 만들기를 클릭합니다.
- 버킷 만들기 페이지에서 버킷 정보를 입력합니다. 다음 단계로 이동하려면 계속을 클릭합니다.
- 버킷 이름 지정에 고유한 버킷 이름을 입력합니다. 버킷 네임스페이스는 전역적이며 공개로 표시되므로 버킷 이름에 민감한 정보를 포함해서는 안 됩니다.
-
데이터 저장 위치 선택 섹션에서 다음을 수행합니다.
- 위치 유형을 선택합니다.
- 위치 유형 드롭다운 메뉴에서 버킷의 데이터가 영구적으로 저장될 위치를 선택합니다.
- 버킷 간 복제를 설정하려면 Storage Transfer Service를 통해 버킷 간 복제 추가를 선택하고 다음 단계를 따르세요.
버킷 간 복제 설정
- 버킷 메뉴에서 버킷을 선택합니다.
복제 설정 섹션에서 구성을 클릭하여 복제 작업의 설정을 구성합니다.
버킷 간 복제 구성 창이 표시됩니다.
- 객체 이름 프리픽스를 기준으로 복제할 객체를 필터링하려면 객체를 포함하거나 제외할 프리픽스를 입력한 다음 프리픽스 추가를 클릭합니다.
- 복제된 객체의 스토리지 클래스를 설정하려면 스토리지 클래스 메뉴에서 스토리지 클래스를 선택합니다. 이 단계를 건너뛰면 복제된 객체가 기본적으로 대상 버킷의 스토리지 클래스를 사용합니다.
- 완료를 클릭합니다.
-
데이터 저장 방법 선택 섹션에서 다음을 수행합니다.
- 기본 클래스 설정 섹션에서 다음을 선택합니다. 표준
- 계층적 네임스페이스를 사용 설정하려면 데이터 집약적인 워크로드에 맞게 스토리지 최적화 섹션에서 이 버킷에서 계층적 네임스페이스 사용 설정을 선택합니다.
- 객체 액세스를 제어하는 방식 선택 섹션에서 버킷이 공개 액세스 방지를 적용할지 여부를 선택하고 버킷의 객체에 대한 액세스 제어 방법을 선택합니다.
-
객체 데이터 보호 방법 선택 섹션에서 다음을 수행합니다.
- 버킷에 설정할 데이터 보호 아래의 옵션을 선택합니다.
- 객체 데이터가 암호화되는 방식을 선택하려면 데이터 암호화 섹션 ()을 펼치고 데이터 암호화 방법을 선택합니다.
- 만들기를 클릭합니다.
뒤에 나오는 섹션에서 필요하므로 다음을 복사합니다.
- Cloud Storage 버킷 이름
- Google Cloud 프로젝트 ID입니다.
이 ID를 찾으려면 프로젝트 식별을 참고하세요.
VPC 네트워크
기본적으로 각각의 새 프로젝트는 기본 네트워크로 시작합니다. 프로젝트에 대한 기본 네트워크가 사용 중지되었거나 삭제된 경우 프로젝트에 사용자 계정에 Compute 네트워크 사용자 역할(roles/compute.networkUser)이 있는 네트워크가 있어야 합니다.
데이터 읽기, 쓰기, 변환
이 섹션에서는 Dataflow와 함께 Beam YAML 구문을 사용하여 다음을 통해 데이터를 읽고 쓰고 필터링하는 방법을 보여줍니다.
- 사용자 인터페이스 기반 개발을 통해 Google Cloud 콘솔의 작업 빌더 UI에서 작업을 빌드하고 실행합니다. 특히 작업 빌더 UI의 빌더 양식을 사용하므로 YAML 파일을 수동으로 만들 필요가 없습니다.
공개적으로 볼 수 있는 Cloud Storage 버킷에 저장된 CSV 파일 데이터입니다. 이 데이터에는 모의 레스토랑 메뉴 데이터가 포함되어 있으며 다음과 같습니다.
restaurant-data.csvMenu item,Category,Price,Tax Classic Cheeseburger,Entree,9.99,0.7 Margherita Pizza,Entree,14.50,1.02 Grilled Salmon with Asparagus,Entree,21.99,1.54 Chicken Caesar Salad,Salad,12.75,0.89 Spaghetti Carbonara,Entree,16.25,1.14 Beef Tacos (3),Entree,10.50,0.74 Vegetable Stir-Fry,Entree,13.00,0.91 Shrimp Scampi,Entree,19.75,1.38 Chicken Pot Pie,Entree,15.50,1.09 Steak Frites,Entree,28.00,1.96 Lobster Mac and Cheese,Entree,25.50,1.79 Pork Belly Bao Buns (2),Appetizer/Side,11.25,0.79 Mushroom Risotto,Entree,17.50,1.23 Fish and Chips,Entree,14.00,0.98 Buffalo Wings (6),Appetizer/Side,9.50,0.67 French Onion Soup,Appetizer/Side,7.00,0.49 Tomato Soup with Grilled Cheese,Appetizer/Side,10.00,0.7 Avocado Toast,Appetizer/Side,8.50,0.6 Quesadilla with Chicken,Appetizer/Side,11.75,0.82 Pad Thai,Entree,15.00,1.05 Chicken Tikka Masala,Entree,18.50,1.3 Burrito Bowl,Entree,13.50,0.95 Sushi Combo (8 pieces),Entree,22.00,1.54 Greek Salad,Salad,11.00,0.77 Clam Chowder,Appetizer/Side,8.00,0.56 New York Cheesecake,Dessert,6.50,0.46 Chocolate Lava Cake,Dessert,7.50,0.53 Apple Pie,Dessert,5.00,0.35 Tiramisu,Dessert,8.00,0.56 Crème brûlée,Dessert,7.00,0.49 Iced Coffee,Beverage,3.50,0.25 Lemonade,Beverage,3.00,0.21 Orange Juice,Beverage,4.00,0.28 Soda,Beverage,2.50,0.18 Craft Beer,Beverage,6.00,0.42 Glass of Wine,Beverage,9.00,0.63 Margarita,Beverage,12.00,0.84 Moscow Mule,Beverage,11.50,0.81 Old Fashioned,Beverage,13.00,0.91 Espresso,Beverage,3.00,0.21 Cappuccino,Beverage,4.50,0.32 Latte,Beverage,5.00,0.35 Mocha,Beverage,5.50,0.39 Hot Chocolate,Beverage,4.00,0.28 Breakfast Burrito,Breakfast,10.50,0.74 Pancakes (3),Breakfast,8.00,0.56 Waffles,Breakfast,9.00,0.63 Eggs Benedict,Breakfast,14.00,0.98 Omelette,Breakfast,11.00,0.77 Fruit Salad,Salad,7.50,0.53 Yogurt Parfait,Breakfast,6.00,0.42
데이터 읽기 및 필터링
다음 예에서는 CSV 파일에서 데이터를 읽고, 특정 정보를 필터링하고, 필터링된 데이터를 JSON 파일에 쓰는 방법을 보여줍니다.
이 샘플에서는 특정 기준을 충족하는 데이터를 선택적으로 유지할 수 있는 Filter 변환을 사용합니다. 다음 예에서는 Price이 20.00보다 크거나 같은 레코드만 유지하도록 데이터 세트를 필터링합니다.
CSV 데이터를 읽고 필터링된 JSON 콘텐츠를 출력하려면 다음 단계를 완료하세요.
Google Cloud 콘솔에서 Dataflow 작업 페이지로 이동합니다.
빌더에서 작업 만들기를 클릭합니다.
작업 빌더 탭에서 빌더 양식을 선택된 상태로 둡니다.
작업 이름 필드에
filter-python-job를 입력합니다.작업 유형의 경우 일괄을 선택된 상태로 둡니다.
소스 섹션에서 다음을 수행합니다.
새 소스 패널의 소스 이름 필드에서 이름을
ReadCsv로 변경합니다.소스 유형 목록에서 Cloud Storage의 CSV를 선택합니다.
CSV 위치 필드에 다음을 입력합니다.
cloud-samples-data/dataflow/tutorials/restaurant-data.csv완료를 클릭합니다.
변환 섹션에서 다음을 수행합니다.
변환 추가를 클릭합니다.
변환 이름 필드에
FilterPrice를 입력합니다.변환 유형 목록에서 필터 (Python)를 선택합니다.
Python 필터 표현식 필드에
Price >= 20.00를 입력합니다.변환 입력 단계 목록에서
ReadCsv을 선택한 상태로 둡니다.완료를 클릭합니다.
싱크 섹션에서 다음을 수행합니다.
싱크 이름 필드에서 이름을
WriteJson로 변경합니다.싱크 유형 목록에서 Cloud Storage의 JSON 파일을 선택합니다.
JSON 위치 필드에 다음을 입력합니다.
BUCKET_NAME/output/restaurant-data_filtered.jsonBUCKET_NAME을 Cloud Storage 버킷 이름으로 바꿉니다.싱크 입력 단계 목록에서
FilterPrice를 선택된 상태로 둡니다.완료를 클릭합니다.
Dataflow 옵션 섹션에서 작업 실행을 클릭합니다.
작업 출력 검사
작업이 완료되면 다음 단계를 완료하여 파이프라인의 출력을 확인합니다.
Google Cloud 콘솔에서 Cloud Storage 버킷 페이지로 이동합니다.
버킷 목록에서 Cloud Storage 버킷 만들기에서 만든 버킷의 이름을 클릭합니다.
restaurant-data_filtered.json-00000-of-00001파일을 클릭합니다.객체 세부정보 페이지에서 인증된 URL을 클릭하여 파이프라인 출력을 봅니다.
출력은 다음과 비슷하게 표시됩니다.
{"Item":"Grilled Salmon with Asparagus","Category":"Entree","Price":21.99,"Tax":1.54}
{"Item":"Steak Frites","Category":"Entree","Price":28.0,"Tax":1.96}
{"Item":"Lobster Mac and Cheese","Category":"Entree","Price":25.5,"Tax":1.79}
{"Item":"Sushi Combo (8 pieces)","Category":"Entree","Price":22.0,"Tax":1.54}
Python을 사용하여 필드 매핑
MapToFields 변환을 사용하면 기존 필드를 기반으로 새 필드를 만들 수 있습니다. 다음 예시에서는 메뉴 항목의 소문자 버전을 만들고, 총 가격을 계산하고, 기존 값 뒤에 값을 추가합니다.
Google Cloud 콘솔에서 Dataflow 작업 페이지로 이동합니다.
빌더에서 작업 만들기를 클릭합니다.
작업 빌더 탭에서 빌더 양식을 선택된 상태로 둡니다.
작업 이름 필드에
map-python-job를 입력합니다.작업 유형의 경우 일괄을 선택된 상태로 둡니다.
소스 섹션에서 다음을 수행합니다.
새 소스 패널의 소스 이름 필드에서 이름을
ReadFromCsvPy로 변경합니다.소스 유형 목록에서 Cloud Storage의 CSV를 선택합니다.
CSV 위치 필드에 다음을 입력합니다.
cloud-samples-data/dataflow/tutorials/restaurant-data.csv완료를 클릭합니다.
변환 섹션에서 다음을 수행합니다.
변환 추가를 클릭합니다.
변환 이름 필드에
MapToFieldsPy를 입력합니다.변환 유형 목록에서 필드 매핑 (Python)을 선택합니다.
기존 필드 유지를 선택된 상태로 둡니다.
매핑된 필드 섹션에서 필드 추가를 클릭합니다.
열리는 새 필드 패널에서
Lowercase_menu_item을 필드 이름으로 지정합니다.Python 표현식 필드에
Item.lower()를 입력합니다.완료를 클릭합니다.
동일한 매핑된 필드 섹션에서 필드 추가를 다시 클릭합니다.
열리는 새 필드 패널에서
Total_price을 필드 이름으로 지정합니다.Python 표현식 필드에
Price + Tax를 입력합니다.이 새 필드 패널에서 완료를 클릭합니다.
이 새 변환 패널에서 완료를 클릭합니다.
싱크 섹션에서 다음을 수행합니다.
싱크 이름 필드에서 이름을
WriteToJsonPy로 변경합니다.싱크 유형 목록에서 Cloud Storage의 JSON 파일을 선택합니다.
JSON 위치 필드에 다음을 입력합니다.
BUCKET_NAME/output/restaurant-data_map-fields.jsonBUCKET_NAME을 Cloud Storage 버킷 이름으로 바꿉니다.싱크 입력 단계 목록에서
MapToFieldsPy를 선택된 상태로 둡니다.완료를 클릭합니다.
Dataflow 옵션 섹션에서 작업 실행을 클릭합니다.
작업 출력 검사
작업이 완료되면 다음 단계를 완료하여 파이프라인의 출력을 확인합니다.
Google Cloud 콘솔에서 Cloud Storage 버킷 페이지로 이동합니다.
버킷 목록에서 Cloud Storage 버킷 만들기에서 만든 버킷의 이름을 클릭합니다.
restaurant-data_map-fields.json-00000-of-00001파일을 클릭합니다.객체 세부정보 페이지에서 인증된 URL을 클릭하여 파이프라인 출력을 봅니다.
출력은 다음과 비슷하게 표시됩니다.
{"Item":"Classic Cheeseburger","Category":"Entree","Price":9.99,"Tax":0.7,"Lowercase_menu_item":"classic cheeseburger","Total_price":10.69}
{"Item":"Margherita Pizza","Category":"Entree","Price":14.5,"Tax":1.02,"Lowercase_menu_item":"margherita pizza","Total_price":15.52}
{"Item":"Grilled Salmon with Asparagus","Category":"Entree","Price":21.99,"Tax":1.54,"Lowercase_menu_item":"grilled salmon with asparagus","Total_price":23.53}
{"Item":"Chicken Caesar Salad","Category":"Salad","Price":12.75,"Tax":0.89,"Lowercase_menu_item":"chicken caesar salad","Total_price":13.64}
{"Item":"Spaghetti Carbonara","Category":"Entree","Price":16.25,"Tax":1.14,"Lowercase_menu_item":"spaghetti carbonara","Total_price":17.39}
{"Item":"Beef Tacos (3)","Category":"Entree","Price":10.5,"Tax":0.74,"Lowercase_menu_item":"beef tacos (3)","Total_price":11.24}
[...]
SQL을 사용하여 데이터 변환
Sql 변환을 사용하면 데이터에서 SQL 쿼리를 실행할 수 있습니다. 다음 예에서는 메뉴 항목을 카테고리 (예: Entree, Beverage, Dessert)별로 그룹화하고 각 카테고리의 항목 수를 나타내는 열을 추가합니다.
작업 빌더 UI를 사용하여 파이프라인을 만들려면 다음 단계를 따르세요.
Google Cloud 콘솔에서 Dataflow 작업 페이지로 이동합니다.
빌더에서 작업 만들기를 클릭합니다.
작업 빌더 탭의 작업 이름 필드에
sql-transform-job를 입력합니다.작업 유형의 경우 일괄을 선택된 상태로 둡니다.
소스 섹션에서 다음을 수행합니다.
소스 이름 필드에서 이름을
SqlTransformSource로 변경합니다.새 소스 탭의 소스 유형에서 Cloud Storage의 CSV를 선택합니다. CSV 위치 필드가 열립니다.
CSV 위치에 다음을 입력합니다.
cloud-samples-data/dataflow/tutorials/restaurant-data.csv완료를 클릭합니다.
변환 섹션에서 다음을 수행합니다.
변환 추가를 클릭합니다.
변환 이름 필드에서 이름을
SqlTransform로 업데이트합니다.변환 유형으로 SQL 변환을 선택합니다. SQL 변환 옵션이 열립니다.
SQL 표현식 필드에 다음을 입력합니다.
select Category, count(*) as category_count from PCOLLECTION group by Category완료를 클릭합니다.
싱크 섹션에서 다음을 수행합니다.
싱크 이름에
SqlTransformSink을 입력합니다.싱크 유형에서 Cloud Storage의 JSON 파일을 선택합니다. Cloud Storage의 JSON 파일에 쓰기 옵션이 열립니다.
JSON 위치에 다음을 입력합니다.
BUCKET_NAME/output/restaurant-data_transform-sql.jsonBUCKET_NAME을 Cloud Storage 버킷 이름으로 바꿉니다.완료를 클릭합니다.
선택사항: 이 파이프라인에 대해 생성된 YAML 정의를 확인합니다.
작업 빌더 탭의 상단으로 이동합니다.
YAML 편집기를 선택합니다. YAML 정의가 표시됩니다. 다음과 같이 표시됩니다.
생성된 YAML 사양
pipeline: transforms: - name: SqlTransformSource type: ReadFromCsv config: path: 'gs://cloud-samples-data/dataflow/tutorials/restaurant-data.csv' - name: SqlTransform type: Sql config: query: >- select Category, count(*) as category_count from PCOLLECTION group by Category input: input0: SqlTransformSource - name: SqlTransformSink type: WriteToJson input: SqlTransform config: path: 'gs://BUCKET_NAME/output/restaurant-data_transform-sql.json'
Dataflow 옵션 섹션에서 작업 실행을 클릭합니다.
작업 출력 검사
작업이 완료되면 다음 단계를 완료하여 파이프라인의 출력을 확인합니다.
Google Cloud 콘솔에서 Cloud Storage 버킷 페이지로 이동합니다.
버킷 목록에서 Cloud Storage 버킷 만들기에서 만든 버킷의 이름을 클릭합니다.
restaurant-data_transform-sql.json-00000-of-00001파일을 클릭합니다.객체 세부정보 페이지에서 인증된 URL을 클릭하여 파이프라인 출력을 봅니다.
출력은 다음과 비슷하게 표시됩니다.
{"Category":"Entree","category_count":16}
{"Category":"Beverage","category_count":14}
{"Category":"Appetizer\/Side","category_count":7}
{"Category":"Dessert","category_count":5}
{"Category":"Breakfast","category_count":6}
{"Category":"Salad","category_count":3}
삭제
이 튜토리얼에서 사용된 리소스 비용이 Google Cloud 계정에 청구되지 않도록 하려면 리소스가 포함된 프로젝트를 삭제하거나 프로젝트를 유지하고 개별 리소스를 삭제하세요.
프로젝트 삭제
- Google Cloud 콘솔에서 리소스 관리 페이지로 이동합니다.
- 프로젝트 목록에서 삭제할 프로젝트를 선택하고 삭제를 클릭합니다.
- 대화상자에서 프로젝트 ID를 입력한 후 종료를 클릭하여 프로젝트를 삭제합니다.
개별 리소스 삭제
나중에 프로젝트를 재사용하려면 프로젝트를 유지하고 튜토리얼 중에 만든 리소스를 삭제하면 됩니다.
Dataflow 파이프라인 중지
Google Cloud 콘솔에서 Dataflow 작업 페이지로 이동합니다.
중지할 작업을 클릭합니다.
작업을 중지하려면 작업 상태가 실행 중이어야 합니다.
작업 세부정보 페이지에서 중지를 클릭합니다.
취소를 클릭합니다.
선택을 확인하려면 작업 중지를 클릭합니다.
Cloud Storage 버킷 삭제
- Google Cloud 콘솔에서 Cloud Storage 버킷 페이지로 이동합니다.
- 삭제할 버킷의 체크박스를 클릭합니다.
- 버킷을 삭제하려면 삭제를 클릭한 후 안내를 따르세요.
다음 단계
- Google Cloud 콘솔의 작업 빌더 UI 개요를 사용하여 작업을 만드는 방법을 자세히 알아보세요.
- 작업 빌더로 커스텀 작업 만들기에서 작업 빌더 커스텀 작업에 대해 알아봅니다.
- Beam YAML API 개요를 읽어보세요.
- Beam YAML 예시를 자세히 확인하세요.