
שימוש ב-Apache Beam interactive runner עם מחברות JupyterLab מאפשר לכם לפתח צינורות עיבוד נתונים באופן איטרטיבי, לבדוק את גרף צינור עיבוד הנתונים ולנתח PCollections ספציפיים בתהליך עבודה של read-eval-print-loop (REPL). מדריך שמדגים איך להשתמש ב-Apache Beam interactive runner עם מחברות JupyterLab זמין במאמר פיתוח באמצעות מחברות Apache Beam.
בדף הזה מפורטות תכונות מתקדמות שאפשר להשתמש בהן במחברת Apache Beam.
FlinkRunner אינטראקטיבי באשכולות שמנוהלים על ידי מחברת
כדי לעבוד עם נתונים בגודל של נתוני ייצור באופן אינטראקטיבי מתוך המחברת, אפשר להשתמש ב-FlinkRunner עם כמה אפשרויות כלליות של צינורות עיבוד נתונים כדי להגדיר ל сеанс המחברת לנהל אשכול של Managed Service for Apache Spark לטווח ארוך ולהריץ את צינורות עיבוד הנתונים של Apache Beam באופן מבוזר.
דרישות מוקדמות
כדי להשתמש בתכונה הזו:
- מפעילים את Managed Service for Apache Spark API.
- מקצים לחשבון השירות שמריץ את מופע המחברת של Managed Service for Apache Spark תפקיד אדמין או תפקיד עריכה.
- משתמשים בגרעין של מחברת עם Apache Beam SDK בגרסה 2.40.0 ואילך.
הגדרות אישיות
לפחות צריך להגדיר את הדברים הבאים:
# Set a Cloud Storage bucket to cache source recording and PCollections.
# By default, the cache is on the notebook instance itself, but that does not
# apply to the distributed execution scenario.
ib.options.cache_root = 'gs://<BUCKET_NAME>/flink'
# Define an InteractiveRunner that uses the FlinkRunner under the hood.
interactive_flink_runner = InteractiveRunner(underlying_runner=FlinkRunner())
options = PipelineOptions()
# Instruct the notebook that Google Cloud is used to run the FlinkRunner.
cloud_options = options.view_as(GoogleCloudOptions)
cloud_options.project = 'PROJECT_ID'
הקצאה מפורשת (אופציונלי)
אפשר להוסיף את האפשרויות הבאות.
# Change this if the pipeline needs to run in a different region
# than the default, 'us-central1'. For example, to set it to 'us-west1':
cloud_options.region = 'us-west1'
# Explicitly provision the notebook-managed cluster.
worker_options = options.view_as(WorkerOptions)
# Provision 40 workers to run the pipeline.
worker_options.num_workers=40
# Use the default subnetwork.
worker_options.subnetwork='default'
# Choose the machine type for the workers.
worker_options.machine_type='n1-highmem-8'
# When working with non-official Apache Beam releases, such as Apache Beam built from source
# code, configure the environment to use a compatible released SDK container.
# If needed, build a custom container and use it. For more information, see:
# https://beam.apache.org/documentation/runtime/environments/
options.view_as(PortableOptions).environment_config = 'apache/beam_python3.7_sdk:2.41.0 or LOCATION.pkg.dev/PROJECT_ID/REPOSITORY/your_custom_container'
Usage
# The parallelism is applied to each step, so if your pipeline has 10 steps, you
# end up having 10 * 10 = 100 tasks scheduled, which can be run in parallel.
options.view_as(FlinkRunnerOptions).parallelism = 10
p_word_count = beam.Pipeline(interactive_flink_runner, options=options)
word_counts = (
p_word_count
| 'read' >> ReadWordsFromText('gs://apache-beam-samples/shakespeare/kinglear.txt')
| 'count' >> beam.combiners.Count.PerElement())
# The notebook session automatically starts and manages a cluster to run
# your pipelines with the FlinkRunner.
ib.show(word_counts)
# Interactively adjust the parallelism.
options.view_as(FlinkRunnerOptions).parallelism = 150
# The BigQuery read needs a Cloud Storage bucket as a temporary location.
options.view_as(GoogleCloudOptions).temp_location = ib.options.cache_root
p_bq = beam.Pipeline(runner=interactive_flink_runner, options=options)
delays_by_airline = (
p_bq
| 'Read Dataset from BigQuery' >> beam.io.ReadFromBigQuery(
project=project, use_standard_sql=True,
query=('SELECT airline, arrival_delay '
'FROM `bigquery-samples.airline_ontime_data.flights` '
'WHERE date >= "2010-01-01"'))
| 'Rebalance Data to TM Slots' >> beam.Reshuffle(num_buckets=1000)
| 'Extract Delay Info' >> beam.Map(
lambda e: (e['airline'], e['arrival_delay'] > 0))
| 'Filter Delayed' >> beam.Filter(lambda e: e[1])
| 'Count Delayed Flights Per Airline' >> beam.combiners.Count.PerKey())
# This step reuses the existing cluster.
ib.collect(delays_by_airline)
# Describe the cluster running the pipelines.
# You can access the Flink dashboard from the printed link.
ib.clusters.describe()
# Cleans up all long-lasting clusters managed by the notebook session.
ib.clusters.cleanup(force=True)
אשכולות בניהול Notebook
- כברירת מחדל, אם לא מספקים אפשרויות צינור, Interactive Apache Beam תמיד משתמש מחדש באשכול שהיה בשימוש לאחרונה כדי להריץ צינור עם
FlinkRunner.- כדי למנוע את ההתנהגות הזו, למשל כדי להריץ צינור אחר באותה הפעלה של מחברת עם FlinkRunner שלא מתארח במחברת, מריצים את
ib.clusters.set_default_cluster(None).
- כדי למנוע את ההתנהגות הזו, למשל כדי להריץ צינור אחר באותה הפעלה של מחברת עם FlinkRunner שלא מתארח במחברת, מריצים את
- כשיוצרים צינור חדש שמשתמש בפרויקט, באזור ובהגדרת הקצאת משאבים שממופים לאשכול קיים של Managed Service for Apache Spark, Dataflow גם משתמש מחדש באשכול, אבל יכול להיות שהוא לא ישתמש באשכול שהיה בשימוש לאחרונה.
- עם זאת, בכל פעם שמתבצע שינוי בהקצאת משאבים, למשל כשמשנים את הגודל של אשכול, נוצר אשכול חדש כדי להפעיל את השינוי הרצוי. אם אתם מתכוונים לשנות את הגודל של אשכול, כדי למנוע ניצול יתר של משאבי הענן, כדאי לנקות אשכולות מיותרים באמצעות
ib.clusters.cleanup(pipeline). - כשמציינים
master_urlשל Flink, אם הוא שייך לאשכול שמנוהל על ידי סשן המחברת, Dataflow משתמש מחדש באשכול המנוהל.- אם ה-
master_urlלא מוכר בסשן של ה-notebook, המשמעות היא שרוצים להשתמש ב-FlinkRunnerשמתארח על ידי המשתמש. המחברת לא עושה שום דבר באופן מרומז.
- אם ה-
פתרון בעיות
בקטע הזה מוסבר איך לפתור בעיות ולבצע ניפוי באגים ב-FlinkRunner האינטראקטיבי באשכולות שמנוהלים על ידי מחברת.
Flink IOException: אין מספיק מאגרי רשת
כדי לפשט את התהליך, הגדרת מאגר הרשת של Flink לא מוצגת להגדרה.
אם תרשים העבודה שלכם מסובך מדי או שהמקביליות מוגדרת גבוה מדי, יכול להיות שהקרדינליות של השלבים כפול המקביליות תהיה גדולה מדי, יתוזמנו יותר מדי משימות במקביל וההפעלה תיכשל.
הטיפים הבאים יעזרו לכם לשפר את המהירות של הפעלות אינטראקטיביות:
- מקצים למשתנה רק את
PCollectionשרוצים לבדוק. - בודקים
PCollectionsכל אחד מהם. - מומלץ להשתמש בפעולת הארגון מחדש אחרי טרנספורמציות עם פיצול גבוה.
- כדאי לשנות את רמת המקביליות בהתאם לגודל הנתונים. לפעמים קטן יותר זה מהיר יותר.
הבדיקה של הנתונים נמשכת יותר מדי זמן
בודקים את לוח הבקרה של Flink כדי לראות את העבודה שמתבצעת. יכול להיות שתראו שלב שבו מאות משימות הסתיימו ונשארה רק אחת, כי נתונים שנמצאים בתהליך ממוקמים במחשב אחד ולא עוברים ערבוב.
תמיד משתמשים בפעולת ערבוב מחדש אחרי טרנספורמציה עם פיצול גבוה, למשל במקרים הבאים:
- קריאת שורות מקובץ
- קריאת שורות מטבלה ב-BigQuery
בלי שינוי הסדר, נתוני הפיצול תמיד מופעלים באותו worker, ואי אפשר לנצל את היתרונות של מקביליות.
כמה עובדים צריך?
ככלל, מספר המעבדים הווירטואליים (vCPU) באשכול Flink הוא בערך מספר משבצות העבודה כפול מספר המעבדים הווירטואליים. לדוגמה, אם יש לכם 40 עובדים מסוג n1-highmem-8, באשכול Flink יש לכל היותר 320 משבצות, כלומר 8 כפול 40.
באופן אידיאלי, תהליך העבודה יכול לנהל משימה שקוראת, ממפה ומשלבת עם מקביליות שמוגדרת במאות, שמתזמנת אלפי משימות במקביל.
האם אפשר להשתמש בו בסטרימינג?
צינורות להזרמת נתונים לא תואמים כרגע לתכונה האינטראקטיבית Flink באשכול שמנוהל על ידי מחברת.
Beam SQL ו-beam_sql magic
Beam SQL מאפשר לשלוח שאילתות לנתונים PCollections מוגבלים ולא מוגבלים באמצעות הצהרות SQL. אם אתם עובדים במחברת Apache Beam, אתם יכולים להשתמש בפקודת ה-magic המותאמת אישית של IPython beam_sql כדי לזרז את פיתוח צינור עיבוד הנתונים.
אתם יכולים לבדוק את השימוש בתכונות מבוססות-AI באמצעות האפשרות -h או --help:beam_sql
אפשר ליצור PCollection מערכים של ערכים קבועים:

אפשר להצטרף לכמה PCollections:

אפשר להפעיל משימת Dataflow באמצעות האפשרות -r DataflowRunner או --runner DataflowRunner:
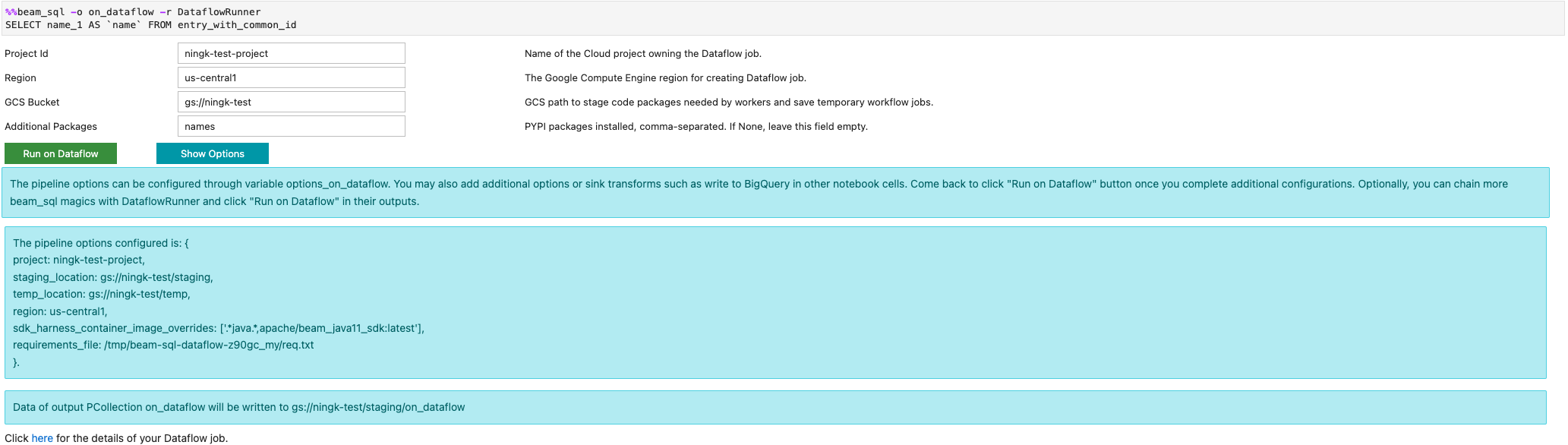
מידע נוסף זמין בקובץ ה-notebook לדוגמה Apache Beam SQL in notebooks.
שיפור המהירות באמצעות מהדר JIT ו-GPU
אפשר להשתמש בספריות כמו numba וGPUs כדי להאיץ את קוד Python ואת צינורות Apache Beam. במכונת ה-notebook של Apache Beam שנוצרה עם nvidia-tesla-t4 GPU, כדי להריץ את הקוד ב-GPU, צריך לקמפל את קוד ה-Python באמצעות numba.cuda.jit. אפשר גם להדר את קוד Python לשפת מכונה באמצעות numba.jit או numba.njit כדי לזרז את ההרצה במעבדי CPU.
בדוגמה הבאה נוצר DoFn שמעובד במעבדים גרפיים:
class Sampler(beam.DoFn):
def __init__(self, blocks=80, threads_per_block=64):
# Uses only 1 cuda grid with below config.
self.blocks = blocks
self.threads_per_block = threads_per_block
def setup(self):
import numpy as np
# An array on host as the prototype of arrays on GPU to
# hold accumulated sub count of points in the circle.
self.h_acc = np.zeros(
self.threads_per_block * self.blocks, dtype=np.float32)
def process(self, element: Tuple[int, int]):
from numba import cuda
from numba.cuda.random import create_xoroshiro128p_states
from numba.cuda.random import xoroshiro128p_uniform_float32
@cuda.jit
def gpu_monte_carlo_pi_sampler(rng_states, sub_sample_size, acc):
"""Uses GPU to sample random values and accumulates the sub count
of values within a circle of radius 1.
"""
pos = cuda.grid(1)
if pos < acc.shape[0]:
sub_acc = 0
for i in range(sub_sample_size):
x = xoroshiro128p_uniform_float32(rng_states, pos)
y = xoroshiro128p_uniform_float32(rng_states, pos)
if (x * x + y * y) <= 1.0:
sub_acc += 1
acc[pos] = sub_acc
rng_seed, sample_size = element
d_acc = cuda.to_device(self.h_acc)
sample_size_per_thread = sample_size // self.h_acc.shape[0]
rng_states = create_xoroshiro128p_states(self.h_acc.shape[0], seed=rng_seed)
gpu_monte_carlo_pi_sampler[self.blocks, self.threads_per_block](
rng_states, sample_size_per_thread, d_acc)
yield d_acc.copy_to_host()
בתמונה הבאה אפשר לראות מחברת שפועלת ב-GPU:
פרטים נוספים זמינים במחברת לדוגמה Use GPUs with Apache Beam.
יצירת מאגר תגים בהתאמה אישית
ברוב המקרים, אם צינור עיבוד הנתונים לא דורש תלות נוספת ב-Python או קובצי הפעלה, Apache Beam יכול להשתמש אוטומטית בתמונות הקונטיינר הרשמיות שלו כדי להריץ את הקוד שהוגדר על ידי המשתמש. התמונות האלה כוללות הרבה מודולים נפוצים של Python, ולא צריך ליצור או לציין אותם באופן מפורש.
במקרים מסוימים, יכול להיות שיש לכם תלויות נוספות ב-Python או אפילו תלויות שאינן ב-Python. בתרחישים האלה, אפשר ליצור קונטיינר בהתאמה אישית ולהפוך אותו לזמין להרצה באוסף Flink. ברשימה הבאה מפורטים היתרונות של שימוש במאגר תגים בהתאמה אישית:
- זמן הגדרה מהיר יותר להפעלות רצופות ואינטראקטיביות
- הגדרות ויחסי תלות יציבים
- יותר גמישות: אפשר להגדיר יותר יחסי תלות של Python
תהליך build של קונטיינר יכול להיות מייגע, אבל אפשר לעשות הכול בנוטבוק באמצעות דפוס השימוש הבא.
יצירת סביבת עבודה מקומית
קודם יוצרים ספריית עבודה מקומית בספריית הבית של Jupyter.
!mkdir -p /home/jupyter/.flink
הכנת יחסי תלות של Python
לאחר מכן, מתקינים את כל התלויות הנוספות של Python שאולי תשתמשו בהן, ומייצאים אותן לקובץ דרישות.
%pip install dep_a
%pip install dep_b
...
אפשר ליצור קובץ דרישות באופן מפורש באמצעות %%writefileהפונקציה הקסומה של המחברת.
%%writefile /home/jupyter/.flink/requirements.txt
dep_a
dep_b
...
לחלופין, אפשר להקפיא את כל התלויות המקומיות בקובץ דרישות. האפשרות הזו עלולה ליצור תלות לא מכוונת.
%pip freeze > /home/jupyter/.flink/requirements.txt
הכנת יחסי התלות שאינם Python
מעתיקים את כל התלויות שאינן Python אל סביבת העבודה. אם אין לכם תלות שאינה Python, דלגו על השלב הזה.
!cp /path/to/your-dep /home/jupyter/.flink/your-dep
...
יצירת קובץ Dockerfile
יוצרים קובץ Dockerfile באמצעות הפונקציה הקסומה של מחברת %%writefile. לדוגמה:
%%writefile /home/jupyter/.flink/Dockerfile
FROM apache/beam_python3.7_sdk:2.40.0
COPY requirements.txt /tmp/requirements.txt
COPY your_dep /tmp/your_dep
...
RUN python -m pip install -r /tmp/requirements.txt
קונטיינר לדוגמה משתמש בתמונה של Apache Beam SDK בגרסה 2.40.0 עם Python 3.7 כבסיס, מוסיף קובץ your_dep ומתקין את יחסי התלות הנוספים של Python.
אפשר להשתמש בקובץ Docker הזה כתבנית ולערוך אותו בהתאם לתרחיש השימוש שלכם.
בצינורות עיבוד הנתונים של Apache Beam, כשמפנים ליחסי תלות שאינם Python, צריך להשתמש בCOPYיעדים שלהם. לדוגמה, /tmp/your_dep הוא נתיב הקובץ של קובץ your_dep.
יצירת קובץ אימג' של קונטיינר ב-Artifact Registry באמצעות Cloud Build
מפעילים את השירותים Cloud Build ו-Artifact Registry, אם הם עדיין לא מופעלים.
!gcloud services enable cloudbuild.googleapis.com !gcloud services enable artifactregistry.googleapis.comיוצרים מאגר Artifact Registry כדי להעלות פריטי מידע שנוצרו בתהליך פיתוח (Artifact). כל מאגר יכול להכיל פריטי מידע שנוצרו בתהליך פיתוח (Artifact) בפורמט נתמך אחד בלבד.
כל התוכן במאגר מוצפן באמצעות Google-owned and Google-managed encryption keys או מפתחות הצפנה שמנוהלים על ידי הלקוח. Artifact Registry משתמש ב-Google-owned and Google-managed encryption keys כברירת מחדל, ולא נדרש שינוי הגדרות כדי להשתמש באפשרות הזו.
צריכה להיות לכם לפחות הרשאת כתיבה ב-Artifact Registry למאגר.
מריצים את הפקודה הבאה כדי ליצור מאגר חדש. הפקודה משתמשת בדגל
--asyncוחוזרת מיידית, בלי להמתין לסיום הפעולה.gcloud artifacts repositories create REPOSITORY \ --repository-format=docker \ --location=LOCATION \ --asyncמחליפים את הערכים הבאים:
- REPOSITORY: שם למאגר. שמות המאגרים צריכים להיות ייחודיים לכל מיקום מאגר בפרויקט.
- LOCATION: המיקום של המאגר.
לפני שמעבירים בדחיפה או מושכים תמונות, צריך להגדיר את Docker לאימות בקשות ל-Artifact Registry. כדי להגדיר אימות למאגרי Docker, מריצים את הפקודה הבאה:
gcloud auth configure-docker LOCATION-docker.pkg.devהפקודה מעדכנת את ההגדרה של Docker. מעכשיו אפשר להתחבר אל Artifact Registry בפרויקט Google Cloud כדי להעלות תמונות.
משתמשים ב-Cloud Build כדי ליצור את קובץ האימג' של הקונטיינר ושומרים אותו ב-Artifact Registry.
!cd /home/jupyter/.flink \ && gcloud builds submit \ --tag LOCATION.pkg.dev/PROJECT_ID/REPOSITORY/flink:latest \ --timeout=20mמחליפים את
PROJECT_IDבמזהה הפרויקט.
שימוש במאגרי תגים מותאמים אישית
בהתאם ל-Runner, אפשר להשתמש במאגרי תגים מותאמים אישית למטרות שונות.
למידע על שימוש כללי במאגרי Apache Beam:
למידע על השימוש במאגר Dataflow, אפשר לעיין במאמרים הבאים:
השבתה של כתובות IP חיצוניות
כשיוצרים מכונת מחברת של Apache Beam, כדי לשפר את האבטחה, צריך להשבית כתובות IP חיצוניות. מכיוון שמופעי מחברת צריכים להוריד משאבים מסוימים מהאינטרנט הציבורי, כמו Artifact Registry, קודם צריך ליצור רשת VPC חדשה ללא כתובת IP חיצונית. לאחר מכן, יוצרים שער Cloud NAT לרשת ה-VPC הזו. מידע נוסף על Cloud NAT זמין במסמכי התיעוד של Cloud NAT. משתמשים ברשת VPC ובשער Cloud NAT כדי לגשת למשאבים הדרושים באינטרנט הציבורי בלי להפעיל כתובות IP חיצוניות.