
本页面介绍了为什么以及如何使用 MLTransform 功能来准备数据以用于训练机器学习 (ML) 模型。具体而言,本页面介绍了如何通过使用 MLTransform 生成嵌入来处理数据。
通过将多个数据处理转换合并到一个类中,MLTransform 可简化将 Apache Beam ML 数据处理操作应用于工作流的过程。
MLTransform。嵌入概览
嵌入对于现代语义搜索和检索增强生成 (RAG) 应用至关重要。借助嵌入,系统可以更深入地理解信息,并在更概念层面与信息进行互动。在语义搜索中,嵌入会将查询和文档转换为向量表示法。这些表示法捕获了它们的底层含义和关系。因此,即使关键字不直接匹配,您也可以找到相关结果。这比标准的关键字搜索有了显著的飞跃。 您还可以将嵌入用于产品推荐。这包括使用图片和文本的多模式搜索、日志分析以及重复信息删除等任务。
在 RAG 中,嵌入在从知识库检索最相关的上下文以为大语言模型 (LLM) 的回答提供依据方面发挥着至关重要的作用。通过在知识库中嵌入用户查询和信息块,RAG 系统可以高效地识别和检索语义最相似的部分。这种语义匹配可确保 LLM 能够访问必要的信息,以生成准确且信息丰富的答案。
注入和处理嵌入数据
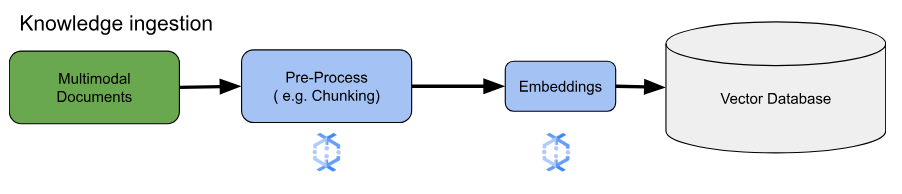
对于核心嵌入用例,关键考虑因素是如何注入和处理知识。这种注入可以采用批量注入或流式注入方式。这种知识的来源可能千差万别。例如,这些信息可以来自存储在 Cloud Storage 中的文件,也可以来自 Pub/Sub 或 Google Cloud Managed Service for Apache Kafka 等流数据源。
对于流式数据源,数据本身可能是原始内容(例如纯文本)或指向文档的 URI。无论信息来源如何,第一阶段通常涉及对信息进行预处理。对于原始文本,这可能很少,例如基本数据清理。不过,对于较大的文档或更复杂的内容,分块是一个关键步骤。分块涉及将源资料拆分为更小、更易于管理的单元。最优分块策略尚未标准化,并且取决于具体数据和应用。像 Dataflow 这样的平台提供内置功能来处理各种分块需求,从而简化这项必要的预处理阶段。
优势
MLTransform 类具有以下优势:
- 生成可用于将数据推送到向量数据库或运行推理的嵌入。
- 无需编写复杂代码或管理底层库即可转换数据。
- 通过一个接口有效地链接多种类型的处理操作。
支持和限制
MLTransform 类具有以下限制:
- 适用于使用 Apache Beam Python SDK 2.53.0 及更高版本的流水线。
- 流水线必须使用默认窗口。
文本嵌入转换:
- 支持 Python 3.8、3.9、3.10、3.11 和 3.12。
- 支持批处理和流式处理流水线。
- 支持 Vertex AI 文本嵌入 API 和 Hugging Face Sentence Transformers 模块。
使用场景
示例笔记本演示了如何将 MLTransform 用于特定应用场景。
- 我想使用 Vertex AI 为 LLM 生成文本嵌入
- 将 Apache Beam
MLTransform类与 Vertex AI 文本嵌入 API 搭配使用以生成文本嵌入。文本嵌入是将文本表示为数字向量的方法,这是许多自然语言处理 (NLP) 任务所必需的。 - 我想使用 Hugging Face 为 LLM 生成文本嵌入
- 使用 Apache Beam
MLTransform类和 Hugging Face Hub 模型来生成文本嵌入。Hugging FaceSentenceTransformers框架使用 Python 生成句子、文本和图片嵌入。 - 我想生成文本嵌入并将其注入到 AlloyDB for PostgreSQL
- 使用 Apache Beam(特别是其
MLTransform类)与 Hugging Face Hub 模型搭配使用来生成文本嵌入。然后,使用VectorDatabaseWriteTransform将这些嵌入和关联的元数据加载到 AlloyDB for PostgreSQL 中。此笔记本演示了如何构建可扩展的批量和流式 Beam 数据流水线,以填充 AlloyDB for PostgreSQL 向量数据库。这包括处理来自各种来源(例如 Pub/Sub 或现有数据库表)的数据、制作自定义架构以及更新数据。 - 我想生成文本嵌入数据,并将其注入到 BigQuery 中
- 将 Apache Beam
MLTransform类与 Hugging Face Hub 模型搭配使用,以便从应用数据(例如产品清单)生成文本嵌入。为此,我们使用了 Apache BeamHuggingfaceTextEmbeddings转换。此转换使用 Hugging Face SentenceTransformers 框架,该框架提供用于生成句子和文本嵌入的模型。然后,使用 Apache BeamVectorDatabaseWriteTransform将这些生成的嵌入和它们的元数据注入到 BigQuery 中。该笔记本还进一步演示了如何使用“Enrichment”转换在 BigQuery 中执行向量相似度搜索。
如需查看可用转换的完整列表,请参阅 Apache Beam 文档中的转换。
使用 MLTransform 生成嵌入
如需使用 MLTransform 类对信息进行分块处理并生成嵌入,请在流水线中添加以下代码:
def create_chunk(product: Dict[str, Any]) -> Chunk:
return Chunk(
content=Content(
text=f"{product['name']}: {product['description']}"
),
id=product['id'], # Use product ID as chunk ID
metadata=product, # Store all product info in metadata
)
[...]
with beam.Pipeline() as p:
_ = (
p
| 'Create Products' >> beam.Create(products)
| 'Convert to Chunks' >> beam.Map(create_chunk)
| 'Generate Embeddings' >> MLTransform(
write_artifact_location=tempfile.mkdtemp())
.with_transform(huggingface_embedder)
| 'Write to AlloyDB' >> VectorDatabaseWriteTransform(alloydb_config)
)
上一个示例会为每个元素创建一个数据块,但您也可以改用 LangChain 来创建数据块:
splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=20)
provider = beam.ml.rag.chunking.langchain.LangChainChunker(
document_field='content', metadata_fields=[], text_splitter=splitter)
with beam.Pipeline() as p:
_ = (
p
| 'Create Products' >> beam.io.textio.ReadFromText(products)
| 'Convert to Chunks' >> provider.get_ptransform_for_processing()
后续步骤
- 阅读博文“如何使用 Dataflow 机器学习实现实时语义搜索和 RAG 应用”。
- 如需详细了解
MLTransform,请参阅 Apache Beam 文档中的预处理数据。 - 如需查看更多示例,请参阅 Apache Beam 转换目录中的用于数据处理的
MLTransform。 - 在 Colab 中运行交互式笔记本。