
En esta página, se explica por qué y cómo usar la función MLTransform para preparar
los datos para entrenar modelos de aprendizaje automático (AA). En particular, en esta página, se muestra cómo procesar datos mediante la generación de embeddings con MLTransform.
A través de la combinación de varias transformaciones de procesamiento de datos en una clase, MLTransform optimiza el proceso de aplicación de operaciones de procesamiento de datos de AA de Apache Beam en tu flujo de trabajo.
MLTransform en el paso de procesamiento previo del flujo de trabajo.
Descripción general de los embeddings
Los embeddings son esenciales para la búsqueda semántica moderna y las aplicaciones de Generación mejorada por recuperación (RAG). Los embeddings permiten que los sistemas comprendan e interactúen con la información en un nivel más profundo y conceptual. En la búsqueda semántica, los embeddings transforman las consultas y los documentos en representaciones vectoriales. Estas representaciones capturan su significado y relaciones subyacentes. En consecuencia, esto te permite encontrar resultados relevantes incluso cuando las palabras clave no coinciden directamente. Este es un avance significativo más allá de la búsqueda estándar basada en palabras clave. También puedes usar embeddings para recomendaciones de productos. Esto incluye búsquedas multimodales que usan imágenes y texto, análisis de registros y tareas como la deduplicación.
Dentro de RAG, los embeddings desempeñan un papel fundamental en la recuperación del contexto más relevante de una base de conocimiento para fundamentar las respuestas de los modelos de lenguaje grandes (LLM). Mediante la incorporación de la consulta del usuario y los fragmentos de información en la base de conocimiento, los sistemas de RAG pueden identificar y recuperar de manera eficiente las partes más similares semánticamente. Esta coincidencia semántica garantiza que el LLM tenga acceso a la información necesaria para generar respuestas informativas y precisas.
Transfiere y procesa datos para embeddings
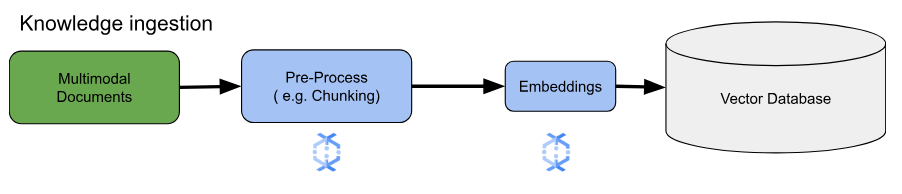
Para los casos de uso de embeddings principales, la consideración clave es cómo transferir y procesar el conocimiento. Esta transferencia puede ser por lotes o de transmisión. La fuente de este conocimiento puede variar mucho. Por ejemplo, esta información puede provenir de archivos almacenados en Cloud Storage o de fuentes de transmisión como Pub/Sub o Google Cloud Managed Service para Apache Kafka.
Para las fuentes de transmisión, los datos en sí pueden ser el contenido sin procesar (por ejemplo, texto sin formato) o los URIs que dirigen a los documentos. Independientemente de la fuente, la primera etapa suele implicar el procesamiento previo de la información. Para el texto sin procesar, esto puede ser mínimo, como la limpieza básica de datos. Sin embargo, para documentos más grandes o contenido más complejo, un paso fundamental es la fragmentación. La fragmentación implica dividir el material de referencia en unidades más pequeñas y manejables. La estrategia de fragmentación óptima no está estandarizada y depende de los datos y la aplicación específicos. Las plataformas como Dataflow ofrecen capacidades integradas para controlar diversas necesidades de fragmentación, lo que simplifica esta etapa esencial de procesamiento previo.
Beneficios
La clase MLTransform proporciona los siguientes beneficios:
- Generar embeddings que puedas usar para enviar datos a bases de datos vectoriales o ejecutar inferencias.
- Transforma tus datos sin tener que escribir código complejo ni administrar bibliotecas subyacentes.
- Encadenar de manera eficiente varios tipos de operaciones de procesamiento con una interfaz.
Asistencia y limitaciones
La clase MLTransform tiene las siguientes limitaciones:
- Disponible para las canalizaciones que usan la versión 2.53.0 y posterior del SDK de Apache Beam para Python.
- Las canalizaciones deben usar ventanas predeterminadas.
Transformaciones de embedding de texto:
- Admite Python 3.8, 3.9, 3.10, 3.11 y 3.12.
- Admite canalizaciones por lotes y de transmisión.
- Admite la API de incorporaciones de texto de Agent Platform de Gemini Enterprise y el módulo de Hugging Face Sentence Transformers.
Casos de uso
En los notebooks de ejemplo, se muestra cómo usar MLTransform para casos de uso específicos.
- Quiero generar embeddings de texto para mi LLM con canalizaciones de Agent Platform
- Usa la clase
MLTransformde Apache Beam con la API de incorporaciones de texto de canalizaciones de Agent Platform para generar embeddings de texto. Las incorporaciones de texto son una forma de representar texto como vectores numéricos, lo que es necesario para muchas tareas de procesamiento de lenguaje natural (PLN). - Quiero generar incorporaciones de texto para mi LLM con Hugging Face
- Usa la clase
MLTransformde Apache Beam con los modelos de Hugging Face Hub para generar incorporaciones de texto. El frameworkSentenceTransformersde Hugging Face usa Python para generar embeddings de imágenes, texto y oraciones. - Quiero generar embeddings de texto y transferirlos a AlloyDB para PostgreSQL
- Usa Apache Beam, específicamente su clase
MLTransformcon los modelos de Hugging Face Hub para generar embeddings de texto. Luego, usaVectorDatabaseWriteTransformpara cargar estos embeddings y los metadatos asociados en AlloyDB para PostgreSQL. En este notebook, se muestra cómo compilar canalizaciones de datos de Beam escalables por lotes y de transmisión para propagar una base de datos de vectores de AlloyDB para PostgreSQL. Esto incluye el manejo de datos de varias fuentes, como Pub/Sub o tablas de bases de datos existentes, la creación de esquemas personalizados y la actualización de datos. - Quiero generar embeddings de texto y transferirlos a BigQuery
- Usa la clase
MLTransformde Apache Beam con los modelos de Hugging Face Hub para generar embeddings de texto a partir de datos de aplicaciones, como un catálogo de productos. Para ello, se usa la transformaciónHuggingfaceTextEmbeddingsde Apache Beam. Esta transformación usa el framework de Hugging Face SentenceTransformers, que proporciona modelos para generar embeddings de oraciones y texto. Luego, estos embeddings generados y sus metadatos se transfieren a BigQuery conVectorDatabaseWriteTransformde Apache Beam. En el notebook, también se muestran búsquedas de similitud de vectores en BigQuery con la transformación de enriquecimiento.
Para obtener una lista completa de las transformaciones disponibles, consulta Transformaciones en la documentación de Apache Beam.
Usa MLTransform para la generación de embeddings
Para usar la clase MLTransform para fragmentar información y generar embeddings, incluye el siguiente código en tu canalización:
def create_chunk(product: Dict[str, Any]) -> Chunk:
return Chunk(
content=Content(
text=f"{product['name']}: {product['description']}"
),
id=product['id'], # Use product ID as chunk ID
metadata=product, # Store all product info in metadata
)
[...]
with beam.Pipeline() as p:
_ = (
p
| 'Create Products' >> beam.Create(products)
| 'Convert to Chunks' >> beam.Map(create_chunk)
| 'Generate Embeddings' >> MLTransform(
write_artifact_location=tempfile.mkdtemp())
.with_transform(huggingface_embedder)
| 'Write to AlloyDB' >> VectorDatabaseWriteTransform(alloydb_config)
)
En el ejemplo anterior, se crea un solo fragmento por elemento, pero también puedes usar LangChain para crear fragmentos:
splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=20)
provider = beam.ml.rag.chunking.langchain.LangChainChunker(
document_field='content', metadata_fields=[], text_splitter=splitter)
with beam.Pipeline() as p:
_ = (
p
| 'Create Products' >> beam.io.textio.ReadFromText(products)
| 'Convert to Chunks' >> provider.get_ptransform_for_processing()
¿Qué sigue?
- Lee la entrada de blog "Cómo habilitar la búsqueda semántica en tiempo real y las aplicaciones de RAG con Dataflow ML".
- Para obtener más detalles sobre
MLTransform, consulta Preprocesa datos en la documentación de Apache Beam. - Con el fin de obtener más ejemplos, consulta
MLTransformpara el procesamiento de datos en el catálogo de transformaciones de Apache Beam. - Ejecuta un notebook interactivo en Colab.