
Esta página explica por que e como usar o recurso MLTransform para preparar
seus dados para treinar modelos de machine learning (ML). Especificamente, esta página mostra como processar dados gerando embeddings usando MLTransform.
Ao combinar várias transformações de processamento de dados em uma classe, MLTransform simplifica o processo de aplicação de operações de processamento de dados de ML do Apache Beam ao fluxo de trabalho.
MLTransform na etapa de pré-processamento do fluxo de trabalho.
Visão geral dos embeddings
Os embeddings são essenciais para a pesquisa semântica moderna e para aplicativos de geração aumentada de recuperação (RAG). Os embeddings permitem que os sistemas entendam e interajam com informações em um nível mais profundo e conceitual. Na pesquisa semântica, os embeddings transformam consultas e documentos em representações vetoriais. Essas representações capturam o significado e as relações subjacentes. Consequentemente, isso permite encontrar resultados relevantes mesmo quando as palavras-chave não correspondem diretamente. Esse é um avanço significativo em relação à pesquisa padrão baseada em palavras-chave. Também é possível usar embeddings para recomendações de produtos. Isso inclui pesquisas multimodais que usam imagens e texto, análise de registros e tarefas como a remoção de duplicação.
No RAG, os embeddings desempenham um papel crucial na recuperação do contexto mais relevante de uma base de conhecimento para fundamentar as respostas de modelos de linguagem grandes (LLMs). Ao incorporar a consulta do usuário e os blocos de informações na base de conhecimento, os sistemas de RAG podem identificar e recuperar com eficiência as partes mais semelhantes semanticamente. Essa correspondência semântica garante que o LLM tenha acesso às informações necessárias para gerar respostas precisas e informativas.
Ingerir e processar dados para embeddings
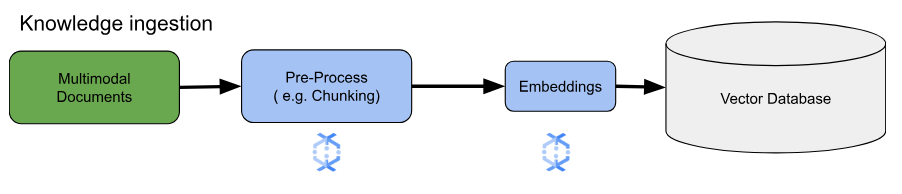
Para os principais casos de uso de embeddings, a principal consideração é como ingerir e processar o conhecimento. Essa ingestão pode ser em lote ou de streaming. A origem desse conhecimento pode variar muito. Por exemplo, essas informações podem vir de arquivos armazenados no Cloud Storage ou de fontes de streaming, como o Pub/Sub ou o Serviço Gerenciado do Google Cloud para Apache Kafka.
Para fontes de streaming, os dados podem ser o conteúdo bruto (por exemplo, texto simples) ou URIs que apontam para documentos. Independente da origem, a primeira etapa normalmente envolve o pré-processamento das informações. Para texto bruto, isso pode ser mínimo, como a limpeza básica de dados. No entanto, para documentos maiores ou conteúdo mais complexo, uma etapa crucial é a geração de blocos. A geração de blocos envolve a divisão do material de origem em unidades menores e gerenciáveis. A estratégia ideal de geração de blocos não é padronizada e depende dos dados e do aplicativo específicos. Plataformas como o Dataflow oferecem recursos integrados para lidar com diversas necessidades de geração de blocos, simplificando essa etapa essencial de pré-processamento.
Benefícios
A classe MLTransform oferece os seguintes benefícios:
- Gere embeddings que podem ser usados para enviar dados a bancos de dados de vetores ou executar inferência.
- Transforme seus dados sem escrever códigos complexos ou gerenciar bibliotecas.
- Encadeie vários tipos de operações de processamento de maneira eficiente com uma só interface.
Suporte e limitações
A classe MLTransform tem as seguintes limitações:
- Disponível para pipelines que usam as versões 2.53.0 e posteriores do SDK do Apache Beam para Python.
- Os pipelines precisam usar janelas padrão.
Transformações de embedding de texto:
- Compatíveis com Python 3.8, 3.9, 3.10, 3.11 e 3.12.
- Compatíveis com pipelines em lote e de streaming.
- Compatíveis com a API text-embeddings da plataforma de agentes do Gemini Enterprise e o módulo Sentence Transformers da Hugging Face.
Casos de uso
Os notebooks de exemplo demonstram como usar MLTransform para casos de uso específicos.
- Quero gerar embeddings de texto para meu LLM usando pipelines da plataforma de agentes
- Use a classe
MLTransformdo Apache Beam com a API text-embeddings dos pipelines da plataforma de agentes para gerar embeddings de texto. Os embeddings de texto são uma maneira de representar o texto como vetores numéricos, o que é necessário para muitas tarefas de processamento de linguagem natural (PLN). - Quero gerar embeddings de texto para meu LLM usando a Hugging Face
- Use a classe
MLTransformdo Apache Beam com modelos do Hugging Face Hub para gerar embeddings de texto. O frameworkSentenceTransformersda Hugging Face usa Python para gerar embeddings de sentenças, textos e imagens. - Quero gerar embeddings de texto e ingerir no AlloyDB para PostgreSQL
- Use o Apache Beam, especificamente a classe
MLTransformcom modelos do Hugging Face Hub para gerar embeddings de texto. Em seguida, useVectorDatabaseWriteTransformpara carregar esses embeddings e os metadados associados no AlloyDB para PostgreSQL. Este notebook demonstra a criação de pipelines de dados do Beam escalonáveis em lote e de streaming para preencher um banco de dados de vetores do AlloyDB para PostgreSQL. Isso inclui o processamento de dados de várias fontes, como tabelas de bancos de dados do Pub/Sub ou existentes, a criação de esquemas personalizados e a atualização de dados. - Quero gerar embeddings de texto e ingerir no BigQuery
- Use a classe
MLTransformdo Apache Beam com modelos Hugging Face Hub para gerar embeddings de texto de dados de aplicativos, como um catálogo de produtos. A transformaçãoHuggingfaceTextEmbeddingsdo Apache Beam é usada para isso. Essa transformação usa o framework SentenceTransformers da Hugging Face, que fornece modelos para gerar embeddings de sentenças e textos. Esses embeddings gerados e os metadados deles são ingeridos no BigQuery usando oVectorDatabaseWriteTransformdo Apache Beam. O notebook demonstra ainda mais pesquisas de similaridade de vetores no BigQuery usando a transformação de aprimoramento.
Para uma lista completa das transformações disponíveis, consulte Transformações na documentação do Apache Beam.
Usar MLTransform para geração de embeddings
Para usar a classe MLTransform para dividir informações e gerar embeddings, inclua o seguinte código no pipeline:
def create_chunk(product: Dict[str, Any]) -> Chunk:
return Chunk(
content=Content(
text=f"{product['name']}: {product['description']}"
),
id=product['id'], # Use product ID as chunk ID
metadata=product, # Store all product info in metadata
)
[...]
with beam.Pipeline() as p:
_ = (
p
| 'Create Products' >> beam.Create(products)
| 'Convert to Chunks' >> beam.Map(create_chunk)
| 'Generate Embeddings' >> MLTransform(
write_artifact_location=tempfile.mkdtemp())
.with_transform(huggingface_embedder)
| 'Write to AlloyDB' >> VectorDatabaseWriteTransform(alloydb_config)
)
O exemplo anterior cria um único bloco por elemento, mas também é possível usar o LangChain para criar blocos:
splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=20)
provider = beam.ml.rag.chunking.langchain.LangChainChunker(
document_field='content', metadata_fields=[], text_splitter=splitter)
with beam.Pipeline() as p:
_ = (
p
| 'Create Products' >> beam.io.textio.ReadFromText(products)
| 'Convert to Chunks' >> provider.get_ptransform_for_processing()
A seguir
- Leia a postagem do blog "Como ativar a pesquisa semântica em tempo real e aplicativos RAG com o Dataflow ML".
- Para mais detalhes sobre
MLTransform, consulte Pré-processar dados na documentação do Apache Beam. - Para mais exemplos, consulte
MLTransformpara processamento de dados no catálogo de transformações do Apache Beam. - Execute um notebook interativo no Colab.