
本頁說明為何要使用 MLTransform 功能準備資料,以及如何使用這項功能訓練機器學習 (ML) 模型。具體來說,本頁面會說明如何使用 MLTransform 生成嵌入,藉此處理資料。
只要在一個類別中合併多個資料處理轉換,MLTransform 就能簡化將 Apache Beam ML 資料處理作業套用至工作流程的程序。
MLTransform。嵌入總覽
嵌入是現代語意搜尋和檢索增強生成 (RAG) 應用程式的必要功能。系統可透過嵌入內容,以更深入、更概念性的層次理解資訊並與之互動。在語意搜尋中,嵌入會將查詢和文件轉換為向量表示法。這些表示法會擷取基礎意義和關係。因此,即使關鍵字不直接相符,您也能找到相關結果。這項技術比以關鍵字為基礎的標準搜尋功能更先進。您也可以使用嵌入內容來提供產品建議。包括使用圖片和文字的多模態搜尋、記錄分析,以及重複資料刪除等工作。
在 RAG 中,嵌入扮演重要角色,可從知識庫檢索最相關的脈絡,為大型語言模型 (LLM) 的回覆提供依據。RAG 系統會將使用者查詢和知識庫中的資訊區塊嵌入,藉此有效找出並擷取語意最相似的內容。這項語意比對功能可確保 LLM 取得必要資訊,生成準確且實用的答案。
擷取及處理嵌入的資料
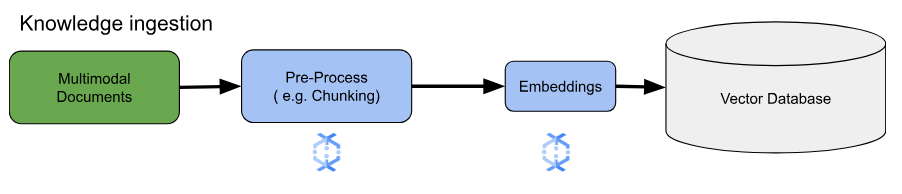
對於核心嵌入用途,主要考量是知識的擷取和處理方式。擷取方式可以是批次或串流。這類知識的來源可能大不相同。舉例來說,這類資訊可能來自 Cloud Storage 中儲存的檔案,也可能來自 Pub/Sub 或 Google Cloud Managed Service for Apache Kafka 等串流來源。
如果是串流來源,資料本身可能是原始內容 (例如純文字),也可能是指向文件的 URI。無論來源為何,第一階段通常會預先處理資訊。如果是原始文字,這類作業可能很簡單,例如基本資料清理。不過,如果是較大的文件或較複雜的內容,分塊是相當重要的步驟。分塊是指將來源資料拆解成易於管理的小單元。最佳分塊策略並無標準做法,取決於特定資料和應用程式。Dataflow 等平台提供內建功能,可處理各種分塊需求,簡化這個重要的預先處理階段。
優點
MLTransform 類別具備下列優點:
- 生成嵌入項目,可用於將資料推送至向量資料庫,或執行推論作業。
- 轉換資料時,不必編寫複雜的程式碼或管理基礎程式庫。
- 透過單一介面,有效串連多種處理作業。
支援與限制
MLTransform 類別具有下列限制:
- 適用於使用 Apache Beam Python SDK 2.53.0 以上版本的管道。
- 管道必須使用預設視窗。
文字嵌入轉換:
- 支援 Python 3.8、3.9、3.10、3.11 和 3.12。
- 支援批次和串流管道。
- 支援 Gemini Enterprise Agent Platform text-embeddings API 和 Hugging Face Sentence Transformers 模組。
用途
範例筆記本會說明如何針對特定用途使用 MLTransform。
- 我想使用 Agent Platform Pipelines 為 LLM 生成文字嵌入
- 搭配使用 Apache Beam
MLTransform類別和 Agent Platform Pipelines 文字嵌入 API,生成文字嵌入。文字嵌入是將文字表示為數值向量的方法,許多自然語言處理 (NLP) 任務都需要用到這項技術。 - 我想使用 Hugging Face 為 LLM 生成文字嵌入
- 搭配使用 Apache Beam 的
MLTransform類別和 Hugging Face Hub 模型,生成文字嵌入。Hugging FaceSentenceTransformers框架使用 Python 生成句子、文字和圖片嵌入。 - 我想生成文字嵌入,並將其擷取至 AlloyDB for PostgreSQL
- 使用 Apache Beam,特別是
MLTransform類別和 Hugging Face Hub 模型,生成文字嵌入。然後使用VectorDatabaseWriteTransform將這些嵌入內容和相關聯的中繼資料載入 AlloyDB for PostgreSQL。這個筆記本示範如何建構可擴充的批次和串流 Beam 資料管道,以填入 AlloyDB for PostgreSQL 向量資料庫。包括處理來自各種來源 (例如 Pub/Sub 或現有資料庫表格) 的資料、建立自訂結構定義,以及更新資料。 - 我想生成文字嵌入項目,並擷取至 BigQuery
- 搭配使用 Apache Beam
MLTransform類別和 Hugging Face Hub 模型,從應用程式資料 (例如產品目錄) 生成文字嵌入。這項作業會使用 Apache BeamHuggingfaceTextEmbeddings轉換。這項轉換會使用 Hugging Face SentenceTransformers 框架,提供生成句子和文字嵌入的模型。然後,系統會使用 Apache BeamVectorDatabaseWriteTransform,將這些生成的嵌入和中繼資料擷取到 BigQuery 中。筆記本會進一步示範如何使用 Enrichment 轉換,在 BigQuery 中執行向量相似度搜尋。
如需可用轉換指令的完整清單,請參閱 Apache Beam 說明文件中的「轉換」。
使用 MLTransform 生成嵌入
如要使用 MLTransform 類別將資訊分塊並產生嵌入,請在管道中加入下列程式碼:
def create_chunk(product: Dict[str, Any]) -> Chunk:
return Chunk(
content=Content(
text=f"{product['name']}: {product['description']}"
),
id=product['id'], # Use product ID as chunk ID
metadata=product, # Store all product info in metadata
)
[...]
with beam.Pipeline() as p:
_ = (
p
| 'Create Products' >> beam.Create(products)
| 'Convert to Chunks' >> beam.Map(create_chunk)
| 'Generate Embeddings' >> MLTransform(
write_artifact_location=tempfile.mkdtemp())
.with_transform(huggingface_embedder)
| 'Write to AlloyDB' >> VectorDatabaseWriteTransform(alloydb_config)
)
上一個範例會為每個元素建立一個區塊,但您也可以使用 LangChain 建立區塊:
splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=20)
provider = beam.ml.rag.chunking.langchain.LangChainChunker(
document_field='content', metadata_fields=[], text_splitter=splitter)
with beam.Pipeline() as p:
_ = (
p
| 'Create Products' >> beam.io.textio.ReadFromText(products)
| 'Convert to Chunks' >> provider.get_ptransform_for_processing()
後續步驟
- 請參閱「如何使用 Dataflow ML 啟用即時語意搜尋和 RAG 應用程式」網誌文章。
- 如要進一步瞭解
MLTransform,請參閱 Apache Beam 說明文件中的「預先處理資料」。 - 如需更多範例,請參閱 Apache Beam 轉換目錄中的「
MLTransformfor data processing」。 - 在 Colab 中執行互動式筆記本。