
最是資源配置功能會使用 Apache Beam 資源提示,為管道自訂工作站資源。將多種不同資源指定至特定管道步驟的功能,可提供額外的管道彈性和功能,並可能節省成本。您可以將成本較高的資源套用至需要這些資源的管道步驟,並將成本較低的資源套用至其他管道步驟。使用適當的 fitting,為整個管道或特定管道步驟指定資源需求。
支援與限制
- Apache Beam Java 和 Python SDK 2.31.0 以上版本均支援資源提示。
- 批次管道支援適當資源配置。
啟用水平自動調度資源的串流管道支援適當調整。
- 只要設定
--experiments=enable_streaming_rightfitting管道選項,即可啟用這項功能。
- 只要設定
適合的解決方案支援 Dataflow Prime。
合身試穿功能不支援 FlexRS。
使用合適的尺寸時,請勿使用
worker_accelerator服務選項。使用 Dataflow Prime 時,系統不支援自動選取 VM。
啟用最適資源配置
如要啟用右側調整功能,請在管道中使用一或多個可用資源提示。在管道中使用資源提示時,系統會自動啟用適當的調整。詳情請參閱本文的「使用資源提示」一節。
可用的資源提示
以下是可用的資源提示。
| 資源提示 | 說明 |
|---|---|
min_ram |
以 GB 為單位,分配給工作站的 RAM 最低數量。 Dataflow 會將這個值做為下限,為新工作站 (水平擴展) 或現有工作站 (垂直擴展) 分配記憶體。 例如: min_ram=NUMBERGB
|
cpu_count |
要為每個工作站分配的 vCPU 數量。使用這項資源提示時,Dataflow 會選取具有指定 vCPU 數量且符合記憶體需求的機器類型。 例如: cpu_count=NUMBER
|
accelerator |
使用者提供的 GPU 分配量,可讓您控管管道及其步驟中的 GPU 使用量和費用。將要附加至 Dataflow 工作站的 GPU 類型和數量指定為旗標的參數。 例如: accelerator="type:GPU_TYPE;count:GPU_COUNT;machine_type:MACHINE_TYPE;CONFIGURATION_OPTIONS"
如要進一步瞭解如何使用 GPU,請參閱「在 Dataflow 使用 GPU」。 |
自動選取工作站機器的 VM 類型
如果管道步驟不需要加速器,但您使用 min_ram 或 cpu_count 資源提示,系統會自動啟用執行個體彈性 (自動選取 VM)。使用自動 VM 選取功能時,系統會從符合 RAM 和 CPU 需求的機型中,為工作站佈建 VM。
自動 VM 選取功能主要會根據可靠性 (而非效能) 最佳化 VM 選取作業。也就是說,使用自動 VM 選取功能改善部分經過高度調整的作業可靠性時,您可能會遇到效能降低的情況。建議您先在現有作業的子集中測試自動 VM 選取功能,再逐步擴大部署範圍。
如果您使用 Compute Engine 預留項目搭配自動 VM 選取功能,請注意下列事項:
- 如果您有自動使用的預留項目,Compute Engine 佈建相符機型的 VM 時,可能會使用這些預留項目。
- 自動選取 VM 不支援從特定預留項目使用執行個體。
- Dataflow Prime 不支援自動 VM 選取功能。
詳情請參閱「執行個體彈性和預留項目」。
資源提示巢狀結構
資源提示會套用至管道轉換階層,如下所示:
min_ram:系統會將轉換中的值評估為轉換本身和轉換階層中所有父項設定的值中,最大的min_ram提示值。- 舉例來說,如果內部轉換提示將
min_ram設為 16 GB,而階層中的外部轉換提示將min_ram設為 32 GB,則整個轉換的所有步驟都會使用 32 GB 的提示。 - 舉例來說,如果內部轉換提示將
min_ram設為 16 GB,而階層中的外部轉換提示將min_ram設為 8 GB,則外部轉換中不在內部轉換的所有步驟都會使用 8 GB 的提示,而內部轉換的所有步驟都會使用 16 GB 的提示。
- 舉例來說,如果內部轉換提示將
accelerator:轉換階層中最內層的值優先。- 示例:如果階層中的內部轉換
accelerator提示與外部轉換accelerator提示不同,系統會將內部轉換accelerator提示用於內部轉換。
- 示例:如果階層中的內部轉換
為整個管道設定的提示,會視為在最外層的個別轉換中設定。
使用資源提示
您可以針對整個管道或管道步驟設定資源提示。
管道資源提示
從指令列執行管道時,您可以在整個管道中設定資源提示。
如要設定 Python 環境,請參閱 Python 教學課程。
範例:
python my_pipeline.py \
--runner=DataflowRunner \
--resource_hints=min_ram=numberGB \
--resource_hints=cpu_count=number \
--resource_hints=accelerator="type:type;count:number;install-nvidia-driver" \
...
管道步驟資源提示
您可以透過程式輔助方式,在管道步驟 (轉換) 中設定資源提示。
Java
如要安裝 Java 適用的 Apache Beam SDK,請參閱「安裝 Apache Beam SDK」。
您可以使用 ResourceHints 類別,以程式輔助方式在管道轉換中設定資源提示。
以下範例說明如何以程式輔助方式,在管道轉換中設定資源提示。
pcoll.apply(MyCompositeTransform.of(...)
.setResourceHints(
ResourceHints.create()
.withMinRam("15GB")
.withCpuCount(8)
.withAccelerator(
"type:nvidia-l4;count:1;install-nvidia-driver")))
pcoll.apply(ParDo.of(new BigMemFn())
.setResourceHints(
ResourceHints.create()
.withMinRam("30GB")
.withCpuCount(16)))
如要以程式輔助方式在整個管道中設定資源提示,請使用 ResourceHintsOptions 介面。
Python
如要安裝 Apache Beam SDK for Python,請參閱「安裝 Apache Beam SDK」。
您可以使用 PTransforms.with_resource_hints 類別,以程式輔助方式在管道轉換中設定資源提示。詳情請參閱 ResourceHint 類別。
以下範例說明如何以程式輔助方式,在管道轉換中設定資源提示。
pcoll | MyPTransform().with_resource_hints(
min_ram="4GB",
cpu_count=8,
accelerator="type:nvidia-tesla-l4;count:1;install-nvidia-driver")
pcoll | beam.ParDo(BigMemFn()).with_resource_hints(
min_ram="30GB",
cpu_count=16)
如要在整個管道中設定資源提示,請在執行管道時使用 --resource_hints 管道選項。如需範例,請參閱「管道資源提示」。
Go
Go 不支援資源提示。
支援多個加速器
在管道中,不同的轉換可以有不同的加速器設定。包括需要不同機器類型的設定。如果提供轉換層級的加速器設定,系統會優先採用這項設定,而非管道層級的設定。
最適資源配置和融合
在某些情況下,使用不同資源提示設定的轉換,可能會在相同工作站集區的工作站上執行,這是融合最佳化程序的一部分。融合轉換時,Dataflow 會在滿足轉換資源提示聯集的環境中執行轉換。在某些情況下,這包括整個管道。
如果無法合併資源提示,就不會發生融合。舉例來說,不同 GPU 的資源提示無法合併,因此這些轉換不會融合。
您也可以在管道中加入一個作業,利用它來強制 Dataflow 具體化中繼 PCollection,防止融合。如果想將 GPU 或高記憶體機器等昂貴資源,與不需要這些特殊資源的緩慢或運算密集型步驟隔離,這項功能就特別實用。在這種情況下,強制在耗用 CPU 的緩慢步驟與需要昂貴 GPU 或高記憶體機器的步驟之間中斷融合,並支付與中斷融合相關的具體化成本,或許會有幫助。詳情請參閱「防止融合」。
串流最適資源配置
如要為串流工作啟用右側調整功能,請設定 --experiments=enable_streaming_rightfitting 管道選項。
如果管道涉及資源需求不同的階段,適當的調整可能可以提升管道效能。
範例:管道包含 CPU 密集型階段和需要 GPU 的階段
如果管道執行需要大量 CPU 資源的階段,接著執行需要 GPU 的階段,就可能適合適當調整。如果沒有適當調整,就必須設定單一 GPU 工作站集區,才能執行所有管道階段,包括需要大量 CPU 資源的階段。當工作站集區執行 CPU 密集型階段時,可能會導致 GPU 資源使用率偏低。
如果啟用適當調整功能,並將資源提示套用至需要 GPU 的步驟,管道會建立兩個獨立集區,以便 CPU 工作站集區執行需要大量 CPU 資源的階段,GPU 工作站集區則執行需要 GPU 的階段。
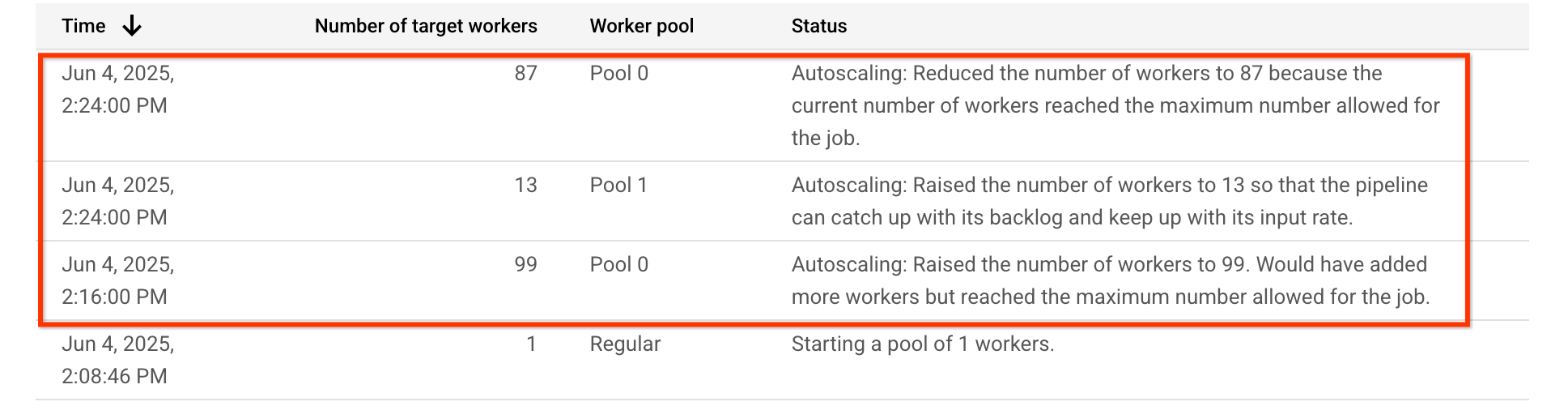
以這個範例管道來說,自動調度資源表顯示,執行 CPU 密集型階段 (Pool 0) 的工作站集區最初會擴充至 99 個工作站,之後縮減至 87 個工作站。執行需要 GPU 的階段 (Pool 1) 時,工作站集區會擴大為 13 個工作站:
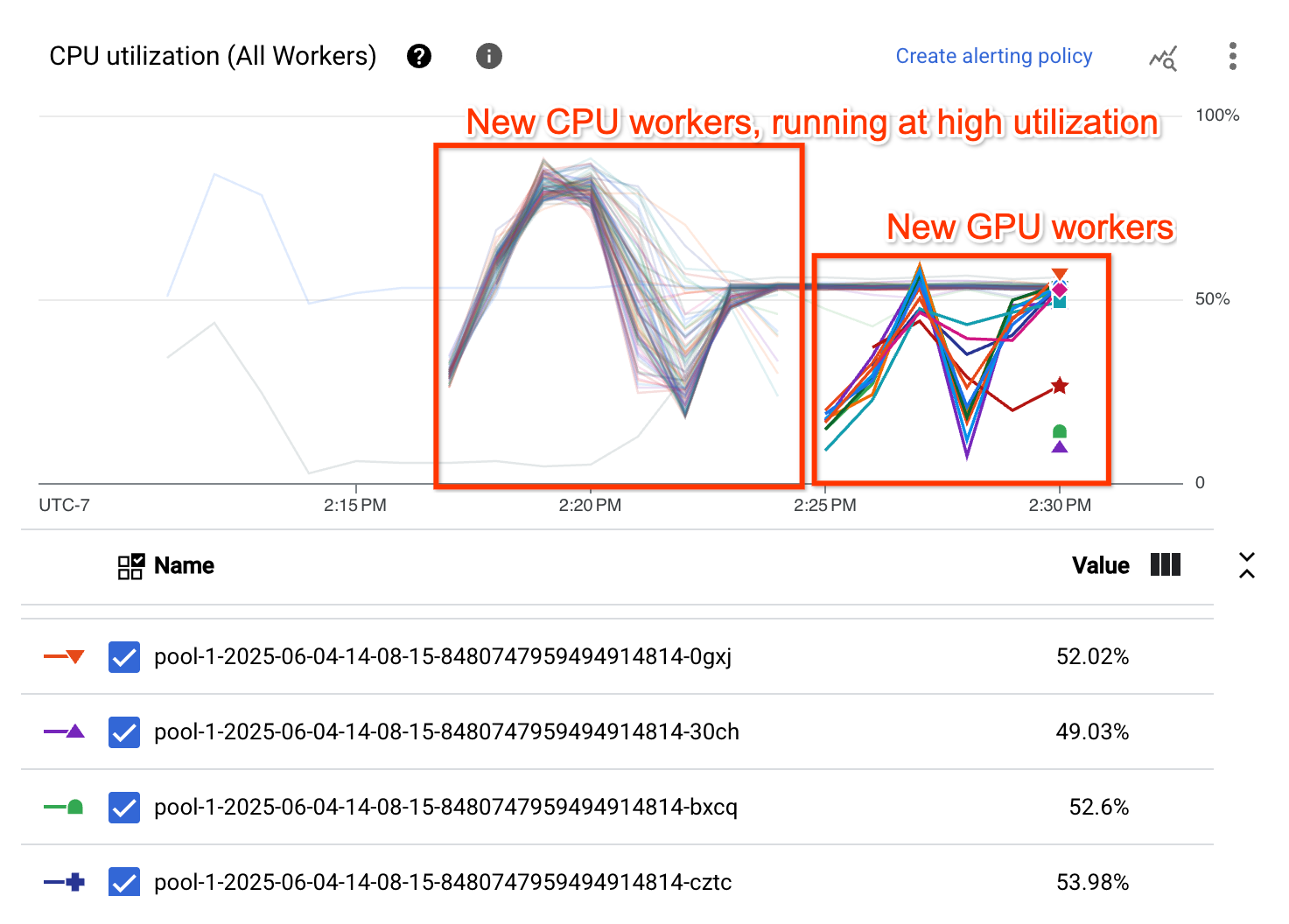
CPU 使用率圖表顯示,兩個工作站集區的工作站整體 CPU 使用率偏高:
排解最適資源配置問題
本節提供常見問題的疑難排解說明,協助你正確調整耳機。
設定無效
嘗試使用右側合適度時,會發生下列錯誤:
Workflow failed. Causes: One or more operations had an error: 'operation-OPERATION_ID':
[UNSUPPORTED_OPERATION] 'NUMBER vCpus with NUMBER MiB memory is
an invalid configuration for NUMBER count of 'GPU_TYPE' in family 'MACHINE_TYPE'.'.
如果選取的 GPU 類型與所選機型不相容,就會發生這項錯誤。如要解決這個錯誤,請選取相容的 GPU 類型和機器類型。如需相容性詳細資料,請參閱「GPU 平台」。
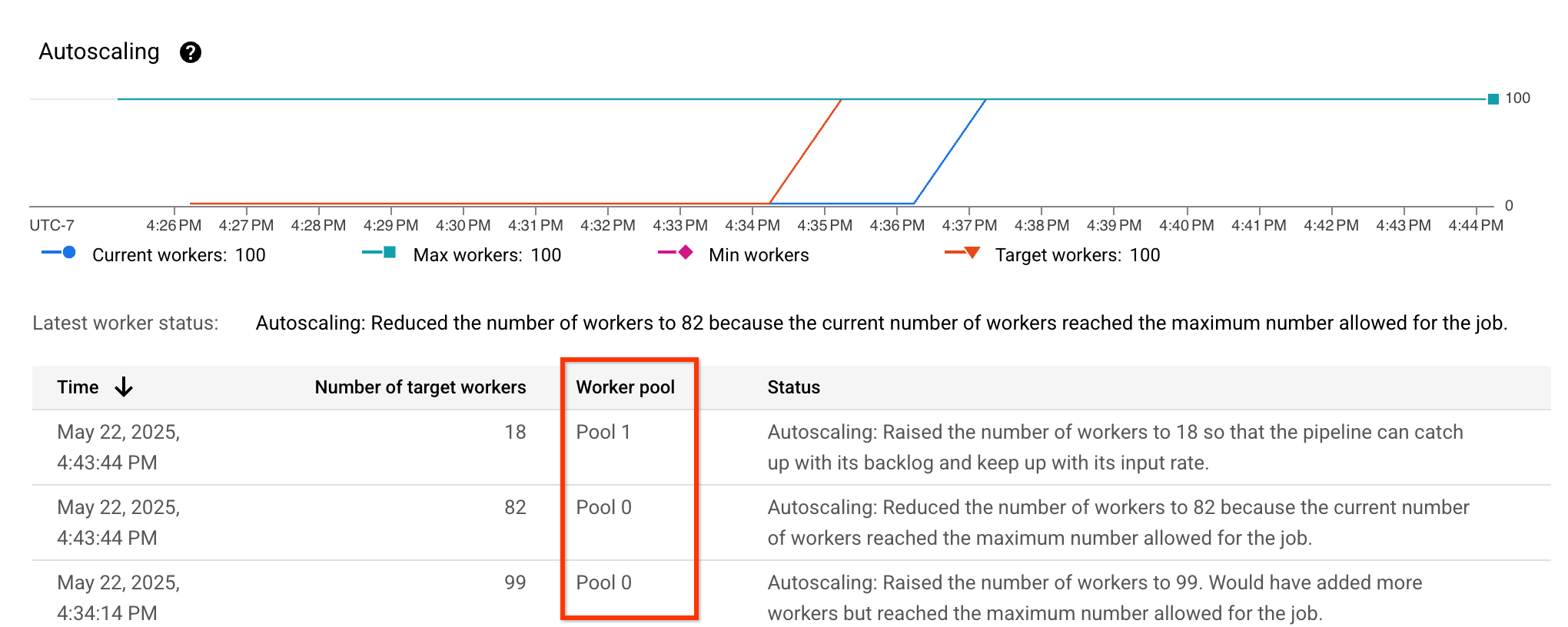
驗證最適資源配置
如要確認是否已啟用適當大小調整功能,請查看自動調度資源指標,並確認 Worker pool 欄是否顯示不同集區:
串流最適資源配置效能
啟用適當調整功能的串流管道,成效不一定會比未啟用適當調整功能的管道更好。例如:
- 管道使用的 worker 數量較多
- 系統延遲時間較長,或總處理量較低
- 工作站集區大小變更頻率較高,或是不穩定
如果發現管道出現這種情況,可以移除--experiments=enable_streaming_rightfitting管道選項,停用右側調整功能。此外,如果串流管道啟用適當的加速器資源提示,可能會使用超出預期的加速器數量。如果管道出現這種情況,您可以設定 --experiments=max_num_accelerators=NUM 管道選項,為管道設定使用的加速器數量上限。