
Fitur penyesuaian yang tepat menggunakan hint resource Apache Beam untuk menyesuaikan resource pekerja untuk pipeline. Kemampuan untuk menargetkan beberapa resource berbeda ke langkah-langkah pipeline tertentu memberikan fleksibilitas dan kemampuan pipeline tambahan, serta potensi penghematan biaya. Anda dapat menerapkan resource yang lebih mahal ke langkah-langkah pipeline yang memerlukannya, dan resource yang lebih murah ke langkah-langkah pipeline lainnya. Gunakan penyesuaian kanan untuk menentukan persyaratan resource bagi seluruh pipeline atau untuk langkah-langkah pipeline tertentu.
Dukungan dan batasan
- Petunjuk resource didukung dengan Apache Beam Java dan Python SDK, versi 2.31.0 dan yang lebih baru.
- Penyesuaian yang tepat didukung dengan pipeline batch.
Penyesuaian kanan didukung dengan pipeline streaming yang mengaktifkan penskalaan otomatis horizontal.
- Anda dapat mengaktifkannya dengan menyetel opsi pipeline
--experiments=enable_streaming_rightfitting.
- Anda dapat mengaktifkannya dengan menyetel opsi pipeline
Penyesuaian yang tepat mendukung Dataflow Prime.
Pengepasan kanan tidak mendukung FlexRS.
Saat Anda menggunakan kecocokan kanan, jangan gunakan
worker_acceleratoropsi layanan.Saat Anda menggunakan Dataflow Prime, Pemilihan VM Otomatis tidak didukung.
Aktifkan penyesuaian yang tepat
Untuk mengaktifkan penyesuaian yang tepat, gunakan satu atau beberapa petunjuk resource yang tersedia di pipeline Anda. Saat Anda menggunakan petunjuk resource di pipeline, penyesuaian yang tepat akan otomatis diaktifkan. Untuk mengetahui informasi selengkapnya, lihat bagian Menggunakan petunjuk resource dalam dokumen ini.
Petunjuk resource yang tersedia
Petunjuk resource berikut tersedia.
| Petunjuk resource | Deskripsi |
|---|---|
min_ram |
Jumlah minimum RAM dalam gigabyte yang akan dialokasikan ke pekerja. Dataflow menggunakan nilai ini sebagai batas bawah saat mengalokasikan memori ke worker baru (penskalaan horizontal) atau ke worker yang ada (penskalaan vertikal). Contoh: min_ram=NUMBERGB
|
cpu_count |
Jumlah vCPU yang akan dialokasikan per pekerja. Saat Anda menggunakan petunjuk resource ini, Dataflow akan memilih jenis mesin yang memiliki jumlah vCPU yang ditentukan dan memenuhi persyaratan memori. Contoh: cpu_count=NUMBER
|
accelerator |
Alokasi GPU yang disediakan pengguna yang memungkinkan Anda mengontrol penggunaan dan biaya GPU di pipeline dan langkah-langkahnya. Tentukan jenis dan jumlah GPU yang akan dipasang ke worker Dataflow sebagai parameter ke tanda. Contoh: accelerator="type:GPU_TYPE;count:GPU_COUNT;machine_type:MACHINE_TYPE;CONFIGURATION_OPTIONS"
Untuk mengetahui informasi selengkapnya tentang penggunaan GPU, lihat GPU dengan Dataflow. |
Pemilihan VM Otomatis untuk jenis mesin pekerja
Saat Anda menggunakan petunjuk resource min_ram atau cpu_count untuk langkah-langkah pipeline yang tidak memerlukan akselerator, Fleksibilitas Instance (Pemilihan VM Otomatis) akan diaktifkan secara otomatis. Dengan Pemilihan VM Otomatis, pekerja disediakan dari pilihan jenis mesin yang memenuhi persyaratan RAM dan CPU Anda.
Pemilihan VM Otomatis mengoptimalkan pemilihan VM terutama untuk keandalan, bukan performa. Artinya, Anda mungkin mengalami penurunan performa saat menggunakan Seleksi VM Otomatis untuk meningkatkan keandalan beberapa tugas yang sangat dioptimalkan. Sebaiknya uji Pemilihan VM Otomatis pada sebagian kecil tugas yang ada sebelum men-deploy-nya secara bertahap ke lebih banyak tugas.
Jika Anda menggunakan reservasi Compute Engine dengan Pemilihan VM Otomatis, perhatikan hal-hal berikut:
- Jika Anda memiliki reservasi yang dikonsumsi secara otomatis, reservasi tersebut dapat digunakan jika Compute Engine menyediakan VM dengan jenis mesin yang cocok.
- Pemilihan VM Otomatis tidak mendukung penggunaan instance dari reservasi tertentu.
- Pemilihan VM Otomatis tidak didukung dengan Dataflow Prime.
Untuk mengetahui informasi selengkapnya, lihat Fleksibilitas dan reservasi instance.
Penyusunan petunjuk resource
Petunjuk resource diterapkan ke hierarki transformasi pipeline sebagai berikut:
min_ram: Nilai pada transformasi dievaluasi sebagai nilai petunjukmin_ramterbesar di antara nilai yang ditetapkan pada transformasi itu sendiri dan semua induknya dalam hierarki transformasi.- Contoh: Jika petunjuk transformasi dalam menetapkan
min_ramke 16 GB, dan petunjuk transformasi luar dalam hierarki menetapkanmin_ramke 32 GB, petunjuk 32 GB akan digunakan untuk semua langkah dalam seluruh transformasi. - Contoh: Jika petunjuk transformasi dalam menetapkan
min_ramke 16 GB, dan petunjuk transformasi luar dalam hierarki menetapkanmin_ramke 8 GB, petunjuk 8 GB digunakan untuk semua langkah dalam transformasi luar yang tidak ada dalam transformasi dalam, dan petunjuk 16 GB digunakan untuk semua langkah dalam transformasi dalam.
- Contoh: Jika petunjuk transformasi dalam menetapkan
accelerator: Nilai paling dalam dalam hierarki transformasi akan diprioritaskan.- Contoh: Jika petunjuk transformasi dalam
acceleratorberbeda dari petunjuk transformasi luaracceleratordalam hierarki, petunjuk transformasi dalamacceleratordigunakan untuk transformasi dalam.
- Contoh: Jika petunjuk transformasi dalam
Petunjuk yang ditetapkan untuk seluruh pipeline diperlakukan seolah-olah ditetapkan pada transformasi terluar yang terpisah.
Menggunakan petunjuk resource
Anda dapat menetapkan petunjuk resource di seluruh pipeline atau di langkah-langkah pipeline.
Petunjuk resource pipeline
Anda dapat menetapkan petunjuk resource di seluruh pipeline saat menjalankan pipeline dari command line.
Untuk menyiapkan lingkungan Python, lihat tutorial Python.
Contoh:
python my_pipeline.py \
--runner=DataflowRunner \
--resource_hints=min_ram=numberGB \
--resource_hints=cpu_count=number \
--resource_hints=accelerator="type:type;count:number;install-nvidia-driver" \
...
Petunjuk resource langkah pipeline
Anda dapat menyetel petunjuk resource pada langkah-langkah pipeline (transformasi) secara terprogram.
Java
Untuk menginstal Apache Beam SDK untuk Java, lihat Menginstal Apache Beam SDK.
Anda dapat menyetel petunjuk resource secara terprogram pada transformasi pipeline menggunakan
class ResourceHints.
Contoh berikut menunjukkan cara menyetel petunjuk resource secara terprogram pada transformasi pipeline.
pcoll.apply(MyCompositeTransform.of(...)
.setResourceHints(
ResourceHints.create()
.withMinRam("15GB")
.withCpuCount(8)
.withAccelerator(
"type:nvidia-l4;count:1;install-nvidia-driver")))
pcoll.apply(ParDo.of(new BigMemFn())
.setResourceHints(
ResourceHints.create()
.withMinRam("30GB")
.withCpuCount(16)))
Untuk menyetel petunjuk resource secara terprogram di seluruh pipeline, gunakan
antarmuka ResourceHintsOptions.
Python
Untuk menginstal Apache Beam SDK untuk Python, lihat Menginstal Apache Beam SDK.
Anda dapat menyetel petunjuk resource secara terprogram pada transformasi pipeline menggunakan
class PTransforms.with_resource_hints.
Untuk mengetahui informasi selengkapnya, lihat
class ResourceHint.
Contoh berikut menunjukkan cara menyetel petunjuk resource secara terprogram pada transformasi pipeline.
pcoll | MyPTransform().with_resource_hints(
min_ram="4GB",
cpu_count=8,
accelerator="type:nvidia-tesla-l4;count:1;install-nvidia-driver")
pcoll | beam.ParDo(BigMemFn()).with_resource_hints(
min_ram="30GB",
cpu_count=16)
Untuk menetapkan petunjuk resource di seluruh pipeline, gunakan opsi pipeline --resource_hints saat Anda menjalankan pipeline. Sebagai contoh, lihat
Petunjuk resource pipeline.
Go
Petunjuk resource tidak didukung di Go.
Dukungan beberapa akselerator
Dalam pipeline, berbagai transformasi dapat memiliki konfigurasi akselerator yang berbeda. Hal ini mencakup konfigurasi yang memerlukan jenis mesin yang berbeda. Konfigurasi akselerator tingkat transformasi ini lebih diprioritaskan daripada konfigurasi tingkat pipeline jika ada.
Penyesuaian dan penggabungan yang tepat
Dalam beberapa kasus, transformasi yang ditetapkan dengan petunjuk resource yang berbeda dapat dieksekusi di pekerja dalam pool pekerja yang sama, sebagai bagian dari proses pengoptimalan penggabungan. Saat transformasi digabungkan, Dataflow akan mengeksekusinya di lingkungan yang memenuhi gabungan petunjuk resource yang ditetapkan pada transformasi. Dalam beberapa kasus, hal ini mencakup seluruh pipeline.
Jika petunjuk resource tidak dapat digabungkan, penggabungan tidak akan terjadi. Misalnya, petunjuk resource untuk GPU yang berbeda tidak dapat digabungkan, sehingga transformasi tersebut tidak digabungkan.
Anda juga dapat mencegah penggabungan dengan menambahkan operasi ke pipeline yang memaksa
Dataflow untuk mewujudkan PCollection perantara. Hal ini sangat berguna saat mencoba mengisolasi resource mahal seperti GPU atau mesin dengan memori tinggi dari langkah-langkah yang lambat atau mahal secara komputasi yang tidak memerlukan resource khusus tersebut. Dalam kasus tersebut, mungkin berguna untuk memaksakan jeda penggabungan
antara langkah-langkah yang terikat CPU lambat dan langkah-langkah yang memerlukan GPU
mahal atau mesin dengan memori tinggi, serta membayar biaya materialisasi yang terkait dengan
penghentian penggabungan. Untuk mempelajari lebih lanjut, lihat
Mencegah penggabungan.
Streaming penyesuaian yang tepat
Untuk tugas streaming, Anda dapat mengaktifkan pengepasan yang tepat dengan menetapkan opsi pipeline --experiments=enable_streaming_rightfitting.
Penyesuaian yang tepat dapat meningkatkan performa pipeline Anda jika melibatkan tahap dengan persyaratan resource yang berbeda.
Contoh: Pipeline dengan tahap yang intensif CPU dan tahap yang memerlukan GPU
Contoh pipeline yang mungkin diuntungkan dari penyesuaian yang tepat adalah pipeline yang menjalankan tahap intensif CPU, diikuti dengan tahap yang memerlukan GPU. Tanpa penyesuaian yang tepat, satu kumpulan pekerja GPU perlu dikonfigurasi untuk mengeksekusi semua tahap pipeline, termasuk tahap yang intensif CPU. Hal ini dapat menyebabkan kurangnya pemanfaatan resource GPU saat kumpulan pekerja menjalankan tahap yang intensif CPU.
Jika penyesuaian yang tepat diaktifkan dan Petunjuk Resource diterapkan ke langkah yang memerlukan GPU, pipeline akan membuat dua pool terpisah, sehingga tahap yang intensif CPU dieksekusi oleh pool pekerja CPU, dan tahap yang memerlukan GPU dieksekusi oleh pool pekerja GPU.
Untuk pipeline contoh ini, tabel penskalaan otomatis menunjukkan bahwa pool worker yang menjalankan tahap intensif CPU, Pool 0, awalnya di-upscale menjadi 99 worker, dan kemudian di-downscale menjadi 87 worker. Kumpulan pekerja yang menjalankan tahap yang memerlukan GPU, Pool 1, di-upscale menjadi 13 pekerja:
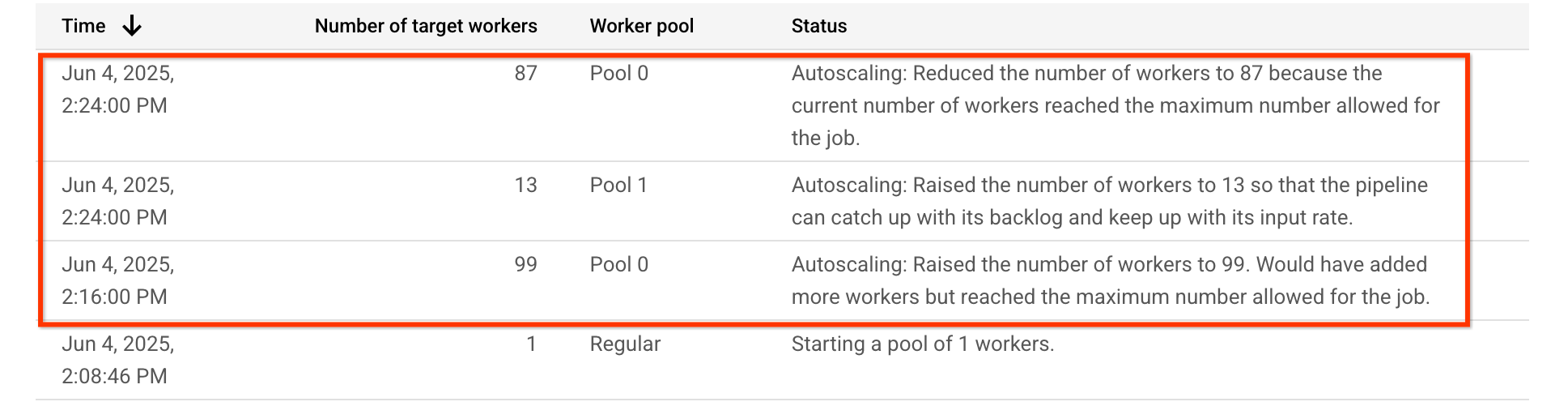
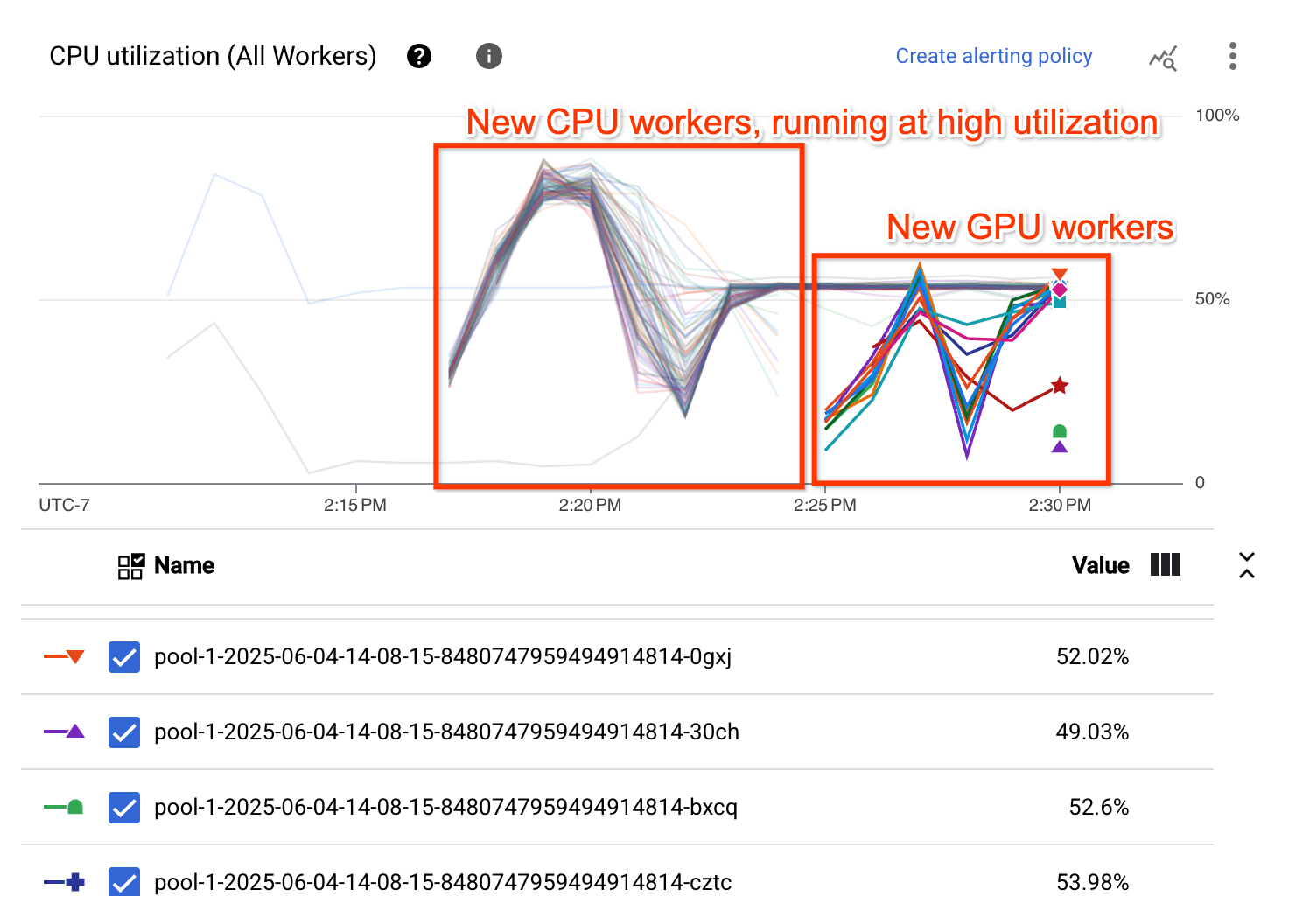
Grafik Penggunaan CPU menunjukkan bahwa pekerja di kedua kumpulan pekerja menunjukkan penggunaan CPU tinggi secara keseluruhan:
Memecahkan masalah penyesuaian yang tepat
Bagian ini memberikan petunjuk untuk memecahkan masalah umum terkait kecocokan yang tepat.
Konfigurasi tidak valid
Saat Anda mencoba menggunakan pencocokan kanan, error berikut akan terjadi:
Workflow failed. Causes: One or more operations had an error: 'operation-OPERATION_ID':
[UNSUPPORTED_OPERATION] 'NUMBER vCpus with NUMBER MiB memory is
an invalid configuration for NUMBER count of 'GPU_TYPE' in family 'MACHINE_TYPE'.'.
Error ini terjadi saat jenis GPU yang dipilih tidak kompatibel dengan jenis mesin yang dipilih. Untuk mengatasi error ini, pilih jenis GPU dan jenis mesin yang kompatibel. Untuk mengetahui detail kompatibilitas, lihat platform GPU.
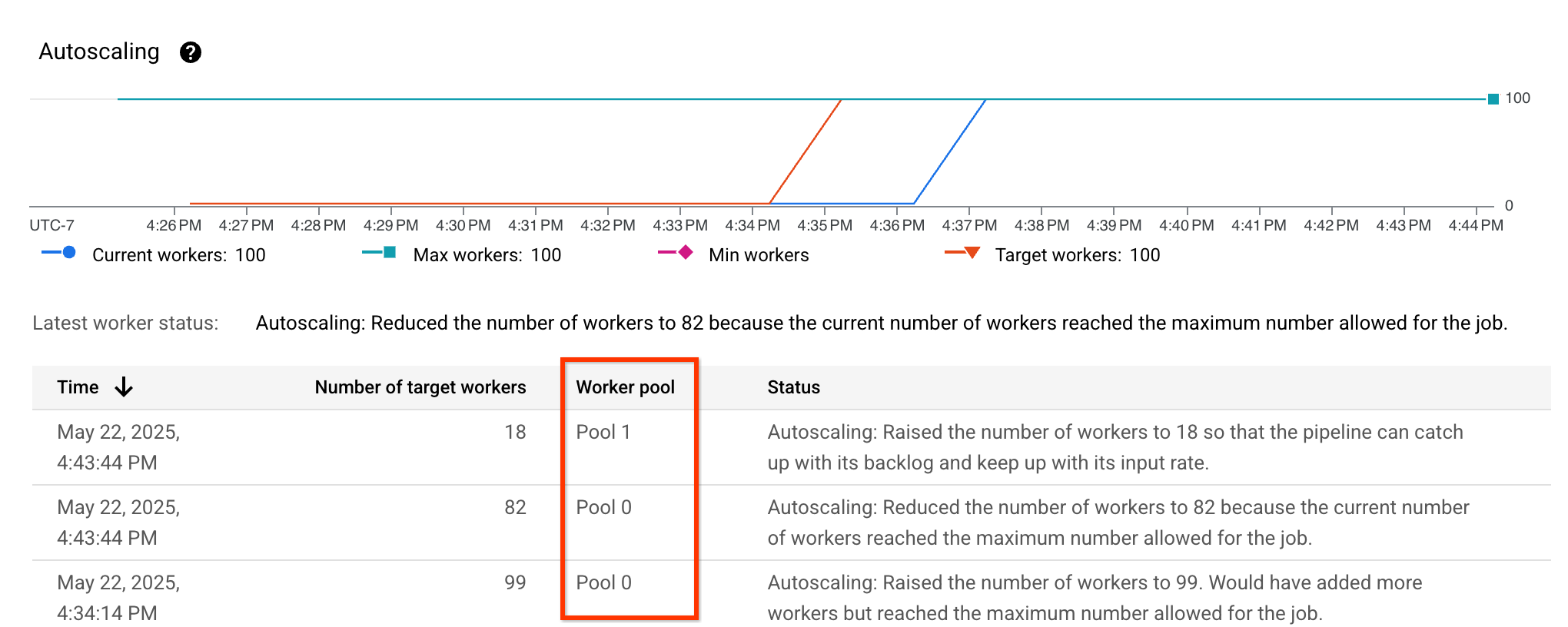
Memverifikasi penyesuaian yang tepat
Anda dapat memverifikasi bahwa penyesuaian yang tepat diaktifkan dengan melihat metrik penskalaan otomatis dan memverifikasi bahwa kolom Worker pool terlihat dan mencantumkan berbagai pool:
Performa penyesuaian yang tepat untuk streaming
Pipeline streaming dengan penyesuaian yang tepat diaktifkan mungkin tidak selalu berperforma lebih baik daripada pipeline tanpa penyesuaian yang tepat diaktifkan. Contoh:
- Pipeline menggunakan lebih banyak pekerja
- Latensi sistem lebih tinggi, atau throughput lebih rendah
- Ukuran kumpulan worker berubah lebih sering, atau tidak stabil
Jika Anda mengamati hal ini untuk pipeline, Anda dapat menonaktifkan penyesuaian kanan dengan menghapus opsi pipeline --experiments=enable_streaming_rightfitting. Selain itu, pipeline streaming dengan penyesuaian yang tepat diaktifkan menggunakan Petunjuk Resource akselerator mungkin menggunakan lebih banyak akselerator daripada yang diinginkan. Jika mengamati hal ini untuk pipeline Anda, Anda dapat mengonfigurasi jumlah maksimum akselerator yang digunakan oleh pipeline dengan menetapkan opsi pipeline --experiments=max_num_accelerators=NUM.