
Esta página descreve as práticas recomendadas a usar quando desenvolve os seus pipelines do Dataflow. A utilização destas práticas recomendadas tem as seguintes vantagens:
- Melhore a observabilidade e o desempenho do pipeline
- Melhore a produtividade dos programadores
- Melhore a capacidade de teste do pipeline
Os exemplos de código do Apache Beam nesta página usam Java, mas o conteúdo aplica-se aos SDKs Java, Python e Go do Apache Beam.
Questões a considerar
Ao criar o seu pipeline, considere as seguintes perguntas:
- Onde são armazenados os dados de entrada do pipeline? Quantos conjuntos de dados de entrada tem?
- Qual é o aspeto dos seus dados?
- O que quer fazer com os seus dados?
- Para onde devem ir os dados de saída do seu pipeline?
- A sua tarefa do Dataflow usa o Assured Workloads?
Use modelos
Para acelerar o desenvolvimento de pipelines, em vez de criar um pipeline escrevendo código do Apache Beam, use um modelo do Dataflow sempre que possível. Os modelos têm as seguintes vantagens:
- Os modelos são reutilizáveis.
- Os modelos permitem-lhe personalizar cada tarefa alterando parâmetros específicos do pipeline.
- Qualquer pessoa a quem conceder autorizações pode usar o modelo para implementar o pipeline. Por exemplo, um programador pode criar uma tarefa a partir de um modelo e um cientista de dados na organização pode implementar esse modelo mais tarde.
Pode usar um modelo fornecido pela Google ou criar o seu próprio modelo. Alguns modelos fornecidos pela Google permitem adicionar lógica personalizada como um passo do pipeline. Por exemplo, o modelo do Pub/Sub para o BigQuery fornece um parâmetro para executar uma função definida pelo utilizador (UDF) em JavaScript que está armazenada no Cloud Storage.
Uma vez que os modelos fornecidos pela Google são de código aberto ao abrigo da licença Apache 2.0, pode usá-los como base para novos pipelines. Os modelos também são úteis como exemplos de código. Veja o código do modelo no repositório do GitHub.
Assured Workloads
O Assured Workloads ajuda a aplicar requisitos de segurança e conformidade para clientes da Google Cloud Platform. Por exemplo, as regiões e o apoio técnico da UE com controlos de soberania ajudam a aplicar as garantias de residência e soberania dos dados para clientes baseados na UE. Para oferecer estas funcionalidades, algumas funcionalidades do Dataflow são restritas ou limitadas. Se usar o Assured Workloads com o Dataflow, todos os recursos aos quais o seu pipeline acede têm de estar localizados na pasta ou no projeto do Assured Workloads da sua organização. Estes recursos incluem:
- Contentores do Cloud Storage
- Conjuntos de dados do BigQuery
- Tópicos e subscrições Pub/Sub
- Conjuntos de dados do Firestore
- Conetores de E/S
No Dataflow, para tarefas de streaming criadas após 7 de março de 2024, todos os dados do utilizador são encriptados com CMEK.
Para tarefas de streaming criadas antes de 7 de março de 2024, as chaves de dados usadas em operações baseadas em chaves, como visualização baseada na janela atual, agrupamento e junção, não estão protegidas pela encriptação CMEK. Para ativar esta encriptação para as suas tarefas, esvazie ou cancele a tarefa e, em seguida, reinicie-a. Para mais informações, consulte o artigo Encriptação de artefactos de estado do pipeline.
Partilhe dados entre pipelines
Não existe um mecanismo de comunicação entre pipelines específico do Dataflow para partilhar dados ou processar o contexto entre pipelines. Pode usar armazenamento duradouro, como o Cloud Storage, ou uma cache na memória, como o App Engine, para partilhar dados entre instâncias de pipelines.
Agende tarefas
Pode automatizar a execução do pipeline das seguintes formas:
- Use o Cloud Scheduler.
- Use o Dataflow Operator do Apache Airflow, um dos vários operadores da Google Cloud Platform num fluxo de trabalho do Cloud Composer.
- Executar processos de tarefas (cron) personalizados no Compute Engine.
Práticas recomendadas para escrever código de pipeline
As secções seguintes fornecem práticas recomendadas a usar quando cria pipelines escrevendo código Apache Beam.
Estruture o seu código do Apache Beam
Para criar pipelines, é comum usar a transformação de processamento paralelo genérica do Apache Beam
ParDo.
Quando aplica uma transformação ParDo, fornece código sob a forma de um objeto DoFn. DoFn é uma classe do SDK do Apache Beam que define uma função de processamento distribuída.
Pode considerar o seu código DoFn como entidades pequenas e independentes: podem existir potencialmente muitas instâncias em execução em máquinas diferentes, cada uma sem conhecimento das outras. Como tal, recomendamos que crie funções puras, que são ideais para a natureza paralela e distribuída dos elementos DoFn.
As funções puras têm as seguintes caraterísticas:
- As funções puras não dependem de estados ocultos ou externos.
- Não têm efeitos secundários observáveis.
- São determinísticas.
O modelo de função pura não é estritamente rígido. Quando o seu código não depende de elementos que não são garantidos pelo serviço Dataflow, as informações de estado ou os dados de inicialização externos podem ser válidos para DoFn e outros objetos de função.
Ao estruturar as ParDotransformaçõesDoFn e criar os elementos DoFn, considere as seguintes diretrizes:
- Quando usa o processamento exatamente uma vez, o serviço Dataflow garante que cada elemento na sua entrada
PCollectioné processado por uma instânciaDoFnexatamente uma vez. - O serviço Dataflow não garante quantas vezes um
DoFné invocado. - O serviço Dataflow não garante exatamente como os elementos distribuídos são agrupados. Não garante que elementos, se existirem, sejam processados em conjunto.
- O serviço Dataflow não garante o número exato de instâncias
DoFncriadas ao longo de um pipeline. - O serviço Dataflow é tolerante a falhas e pode tentar executar o seu código várias vezes se os trabalhadores encontrarem problemas.
- O serviço Dataflow pode criar cópias de segurança do seu código. Podem ocorrer problemas com efeitos secundários manuais, por exemplo, se o seu código depender ou criar ficheiros temporários com nomes não únicos.
- O serviço Dataflow serializa o processamento de elementos por
DoFninstância. O seu código não tem de ser estritamente seguro para threads, mas qualquer estado partilhado entre várias instânciasDoFntem de ser seguro para threads.
Crie bibliotecas de transformações reutilizáveis
O modelo de programação Apache Beam permite-lhe reutilizar transformações. Ao criar uma biblioteca partilhada de transformações comuns, pode melhorar a reutilização, a capacidade de teste e a propriedade do código por diferentes equipas.
Considere os dois exemplos de código Java seguintes, que leem eventos de pagamento. Partindo do princípio de que ambas as condutas realizam o mesmo processamento, podem usar as mesmas transformações através de uma biblioteca partilhada para os restantes passos de processamento.
O primeiro exemplo é de uma origem Pub/Sub não limitada:
PipelineOptions options = PipelineOptionsFactory.create();
Pipeline p = Pipeline.create(options)
// Initial read transform
PCollection<PaymentEvent> payments =
p.apply("Read from topic",
PubSubIO.readStrings().withTimestampAttribute(...).fromTopic(...))
.apply("Parse strings into payment events",
ParDo.of(new ParsePaymentEventFn()));
O segundo exemplo é de uma origem de base de dados relacional delimitada:
PipelineOptions options = PipelineOptionsFactory.create();
Pipeline p = Pipeline.create(options);
PCollection<PaymentEvent> payments =
p.apply(
"Read from database table",
JdbcIO.<PaymentEvent>read()
.withDataSourceConfiguration(...)
.withQuery(...)
.withRowMapper(new RowMapper<PaymentEvent>() {
...
}));
A forma como implementa as práticas recomendadas de reutilização de código varia consoante a linguagem de programação e a ferramenta de compilação. Por exemplo, se usar o Maven, pode separar o código de transformação no respetivo módulo. Em seguida, pode incluir o módulo como um submódulo em projetos com vários módulos maiores para diferentes pipelines, conforme mostrado no seguinte exemplo de código:
// Reuse transforms across both pipelines
payments
.apply("ValidatePayments", new PaymentTransforms.ValidatePayments(...))
.apply("ProcessPayments", new PaymentTransforms.ProcessPayments(...))
...
Para mais informações, consulte as seguintes páginas de documentação do Apache Beam:
- Requisitos para escrever código do utilizador para transformações do Apache Beam
- Guia de estilo
PTransform: um guia de estilo para escritores de novas coleçõesPTransformreutilizáveis
Use filas de mensagens rejeitadas para o processamento de erros
Por vezes, o pipeline não consegue processar elementos. Os problemas de dados são uma causa comum. Por exemplo, um elemento que contenha JSON com formato incorreto pode causar falhas de análise.
Embora possa detetar exceções no método
DoFn.ProcessElement
, registar o erro e ignorar o elemento, esta abordagem perde os dados e impede que os dados sejam inspecionados posteriormente para processamento manual ou resolução de problemas.
Em alternativa, use um padrão denominado fila de mensagens rejeitadas (fila de mensagens não processadas).
Detete exceções no método DoFn.ProcessElement e registe erros. Em vez de ignorar o elemento com falha, use saídas de ramificação para escrever elementos com falha num objeto PCollection separado. Em seguida, estes elementos são escritos num destino de dados para inspeção posterior
e processamento com uma transformação separada.
O exemplo de código Java seguinte mostra como implementar o padrão de fila de mensagens rejeitadas.
TupleTag<Output> successTag = new TupleTag<>() {};
TupleTag<Input> deadLetterTag = new TupleTag<>() {};
PCollection<Input> input = /* ... */;
PCollectionTuple outputTuple =
input.apply(ParDo.of(new DoFn<Input, Output>() {
@Override
void processElement(ProcessContext c) {
try {
c.output(process(c.element()));
} catch (Exception e) {
LOG.severe("Failed to process input {} -- adding to dead-letter file",
c.element(), e);
c.sideOutput(deadLetterTag, c.element());
}
}).withOutputTags(successTag, TupleTagList.of(deadLetterTag)));
// Write the dead-letter inputs to a BigQuery table for later analysis
outputTuple.get(deadLetterTag)
.apply(BigQueryIO.write(...));
// Retrieve the successful elements...
PCollection<Output> success = outputTuple.get(successTag);
// and continue processing ...
Use o Cloud Monitoring para aplicar diferentes políticas de monitorização e alerta à fila de mensagens rejeitadas do seu pipeline. Por exemplo, pode visualizar o número e o tamanho dos elementos processados pela transformação de mensagens não entregues e configurar alertas para serem acionados se forem cumpridas determinadas condições de limite.
Faça a gestão de mutações do esquema
Pode processar dados com esquemas inesperados, mas válidos, através de um padrão de mensagens não entregues, que escreve elementos com falhas num objeto PCollection separado.
Em alguns casos, quer processar automaticamente elementos que refletem um esquema alterado como elementos válidos. Por exemplo, se o esquema de um elemento refletir uma mutação, como a adição de novos campos, pode adaptar o esquema do destino de dados para acomodar as mutações.
A mutação automática do esquema baseia-se na abordagem de saída de ramificação usada pelo padrão de mensagens não entregues. No entanto, neste caso, aciona uma transformação que altera o esquema de destino sempre que são encontrados esquemas aditivos. Para ver um exemplo desta abordagem, consulte Como processar esquemas JSON mutantes num pipeline de streaming com a Square Enix no Google Cloud blogue.
Decida como juntar conjuntos de dados
A junção de conjuntos de dados é um exemplo de utilização comum para pipelines de dados. Pode usar entradas laterais ou a transformação CoGroupByKey para fazer junções no seu pipeline.
Cada um tem vantagens e desvantagens.
As entradas laterais
oferecem uma forma flexível de resolver problemas comuns de processamento de dados, como o enriquecimento de dados e as pesquisas com chaves. Ao contrário dos objetos PCollection, as entradas laterais são mutáveis e podem ser determinadas no tempo de execução. Por exemplo, os valores numa entrada lateral podem ser calculados por outro ramo no seu pipeline ou determinados através da chamada de um serviço remoto.
O Dataflow suporta entradas laterais persistindo dados no armazenamento persistente, semelhante a um disco partilhado. Esta configuração disponibiliza a entrada lateral completa a todos os trabalhadores.
No entanto, os tamanhos de entrada secundários podem ser muito grandes e podem não caber na memória do worker. A leitura de uma entrada lateral grande pode causar problemas de desempenho se os trabalhadores precisarem de ler constantemente a partir do armazenamento persistente.
A transformação CoGroupByKey
transform é uma
transformação Apache Beam principal
que une (achata) vários objetos PCollection e agrupa elementos que
têm uma chave comum. Ao contrário de uma entrada lateral, que disponibiliza todos os dados de entrada lateral a cada trabalhador, CoGroupByKey executa uma operação de aleatorização (agrupamento) para distribuir dados pelos trabalhadores. Por conseguinte, o CoGroupByKey é ideal quando os objetos PCollection que quer juntar são muito grandes e não cabem na memória do trabalhador.
Siga estas diretrizes para ajudar a decidir se deve usar entradas laterais ou
CoGroupByKey:
- Use entradas laterais quando um dos objetos
PCollectionaos quais está a juntar-se for desproporcionadamente menor do que os outros e o objetoPCollectionmais pequeno couber na memória do trabalhador. O armazenamento em cache da entrada lateral inteiramente na memória torna a obtenção de elementos rápida e eficiente. - Use entradas laterais quando tiver um objeto
PCollectionque tem de ser unido várias vezes no seu pipeline. Em vez de usar várias transformaçõesCoGroupByKey, crie uma única entrada lateral que possa ser reutilizada por várias transformaçõesParDo. - Use
CoGroupByKeyse precisar de obter uma grande proporção de um objetoPCollectionque exceda significativamente a memória do trabalhador.
Para mais informações, consulte o artigo Resolva problemas de erros de falta de memória do Dataflow.
Minimize as operações caras por elemento
Uma instância DoFn processa lotes de elementos denominados
pacotes,
que são unidades de trabalho atómicas compostas por zero ou mais
elementos. Os elementos individuais são, em seguida, processados pelo método
DoFn.ProcessElement, que é executado para cada elemento. Uma vez que o método DoFn.ProcessElement
é chamado para cada elemento, quaisquer operações demoradas ou computacionalmente
caras que sejam invocadas por esse método
são executadas para cada elemento processado pelo método.
Se precisar de realizar operações dispendiosas apenas uma vez para um lote de elementos, inclua essas operações no método DoFn.Setup ou no método DoFn.StartBundle, em vez de no elemento DoFn.ProcessElement. Os exemplos incluem as seguintes operações:
Analisar um ficheiro de configuração que controla algum aspeto do comportamento da instância.
DoFnSó invoque esta ação uma vez, quando a instânciaDoFnfor inicializada, através do métodoDoFn.Setup.Instanciar um cliente de curta duração que é reutilizado em todos os elementos num pacote, como quando todos os elementos no pacote são enviados através de uma única ligação de rede. Invoque esta ação uma vez por pacote através do método
DoFn.StartBundle.
Limite os tamanhos dos lotes e as chamadas simultâneas a serviços externos
Quando chama serviços externos, pode reduzir os custos gerais por chamada usando a transformação GroupIntoBatches. Esta transformação cria lotes de elementos de um tamanho especificado.
O processamento em lote envia elementos para um serviço externo como uma carga útil em vez de individualmente.
Em combinação com o processamento em lote, limite o número máximo de chamadas paralelas (simultâneas) para o serviço externo escolhendo as chaves adequadas para particionar os dados recebidos. O número de partições determina a paralelização máxima. Por exemplo, se cada elemento receber a mesma chave, uma transformação a jusante para chamar o serviço externo não é executada em paralelo.
Considere uma das seguintes abordagens para gerar chaves para elementos:
- Escolha um atributo do conjunto de dados para usar como chaves de dados, como IDs de utilizadores.
- Gere chaves de dados para dividir elementos aleatoriamente num número fixo de partições, em que o número de valores de chaves possíveis determina o número de partições. Tem de criar partições suficientes para o paralelismo.
Cada partição tem de ter elementos suficientes para que a transformação seja útil.
GroupIntoBatches
O seguinte exemplo de código Java mostra como dividir aleatoriamente elementos em dez partições:
// PII or classified data which needs redaction.
PCollection<String> sensitiveData = ...;
int numPartitions = 10; // Number of parallel batches to create.
PCollection<KV<Long, Iterable<String>>> batchedData =
sensitiveData
.apply("Assign data into partitions",
ParDo.of(new DoFn<String, KV<Long, String>>() {
Random random = new Random();
@ProcessElement
public void assignRandomPartition(ProcessContext context) {
context.output(
KV.of(randomPartitionNumber(), context.element()));
}
private static int randomPartitionNumber() {
return random.nextInt(numPartitions);
}
}))
.apply("Create batches of sensitive data",
GroupIntoBatches.<Long, String>ofSize(100L));
// Use batched sensitive data to fully utilize Redaction API,
// which has a rate limit but allows large payloads.
batchedData
.apply("Call Redaction API in batches", callRedactionApiOnBatch());
Identifique problemas de desempenho causados por passos fundidos
O Dataflow cria um gráfico de passos que representa o seu pipeline com base nas transformações e nos dados que usou para o construir. Este gráfico é denominado o gráfico de execução do pipeline.
Quando implementa o pipeline, o Dataflow pode modificar o gráfico de execução do pipeline para melhorar o desempenho. Por exemplo, o Dataflow pode fundir algumas operações, um processo conhecido como otimização de fusão, para evitar o impacto no desempenho e no custo da escrita de todos os objetos PCollection intermédios no seu pipeline.
Em alguns casos, o Dataflow pode determinar incorretamente a melhor forma de fundir operações no pipeline, o que pode limitar a capacidade do seu trabalho de usar todos os trabalhadores disponíveis. Nesses casos, pode impedir a união de operações.
Considere o seguinte exemplo de código do Apache Beam. Uma transformação
GenerateSequence
cria um pequeno objeto PCollection delimitado, que é posteriormente
processado por duas transformações ParDo a jusante.
A transformação Find Primes Less-than-N pode ser computacionalmente dispendiosa e é provável que seja executada lentamente para grandes números. Por outro lado, a transformação Increment Number provavelmente é concluída rapidamente.
import com.google.common.math.LongMath;
...
public class FusedStepsPipeline {
final class FindLowerPrimesFn extends DoFn<Long, String> {
@ProcessElement
public void processElement(ProcessContext c) {
Long n = c.element();
if (n > 1) {
for (long i = 2; i < n; i++) {
if (LongMath.isPrime(i)) {
c.output(Long.toString(i));
}
}
}
}
}
public static void main(String[] args) {
Pipeline p = Pipeline.create(options);
PCollection<Long> sequence = p.apply("Generate Sequence",
GenerateSequence
.from(0)
.to(1000000));
// Pipeline branch 1
sequence.apply("Find Primes Less-than-N",
ParDo.of(new FindLowerPrimesFn()));
// Pipeline branch 2
sequence.apply("Increment Number",
MapElements.via(new SimpleFunction<Long, Long>() {
public Long apply(Long n) {
return ++n;
}
}));
p.run().waitUntilFinish();
}
}
O diagrama seguinte mostra uma representação gráfica do pipeline na interface de monitorização do Dataflow.
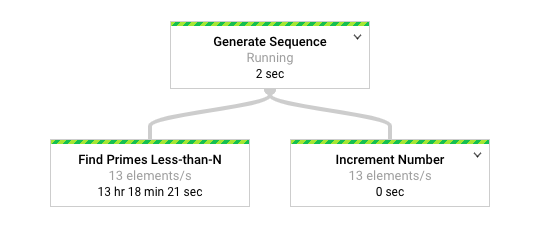
A
interface de monitorização do Dataflow
mostra que a mesma taxa de processamento lenta ocorre para ambas as transformações, especificamente 13
elementos por segundo. Pode esperar que a transformação Increment Number processe os elementos rapidamente, mas, em vez disso, parece estar associada à mesma taxa de processamento que Find Primes Less-than-N.
O motivo é que o Dataflow uniu os passos numa única fase, o que impede a respetiva execução independente. Pode usar o comando
gcloud dataflow jobs describe
para encontrar mais informações:
gcloud dataflow jobs describe --full job-id --format json
No resultado, os passos fundidos são descritos no objeto
ExecutionStageSummary
na matriz
ComponentTransform:
...
"executionPipelineStage": [
{
"componentSource": [
...
],
"componentTransform": [
{
"name": "s1",
"originalTransform": "Generate Sequence/Read(BoundedCountingSource)",
"userName": "Generate Sequence/Read(BoundedCountingSource)"
},
{
"name": "s2",
"originalTransform": "Find Primes Less-than-N",
"userName": "Find Primes Less-than-N"
},
{
"name": "s3",
"originalTransform": "Increment Number/Map",
"userName": "Increment Number/Map"
}
],
"id": "S01",
"kind": "PAR_DO_KIND",
"name": "F0"
}
...
Neste cenário, uma vez que a transformação Find Primes Less-than-N é o passo lento, é uma estratégia adequada interromper a união antes desse passo. Um método para desagrupar passos é inserir uma transformação GroupByKey e desagrupar antes do passo, conforme mostrado no exemplo de código Java seguinte.
sequence
.apply("Map Elements", MapElements.via(new SimpleFunction<Long, KV<Long, Void>>() {
public KV<Long, Void> apply(Long n) {
return KV.of(n, null);
}
}))
.apply("Group By Key", GroupByKey.<Long, Void>create())
.apply("Emit Keys", Keys.<Long>create())
.apply("Find Primes Less-than-N", ParDo.of(new FindLowerPrimesFn()));
Também pode combinar estes passos de desagregação numa transformação composta reutilizável.
Depois de desfundir os passos, quando executa o pipeline, Increment Number
é concluído em segundos e a transformação Find Primes Less-than-N, que demora muito mais tempo, é executada numa fase separada.
Este exemplo aplica uma operação de agrupar e desagrupar para separar passos.
Pode usar outras abordagens para outras circunstâncias. Neste caso, o processamento da saída duplicada não é um problema, dada a saída consecutiva da transformação GenerateSequence.
KV
Os objetos com chaves duplicadas são desduplicados para uma única chave no grupo
(GroupByKey) transform
e na transformação ungroup
(Keys). Para reter duplicados após as operações de agrupamento e desagrupamento,
crie pares de chave-valor através dos seguintes passos:
- Use uma chave aleatória e a entrada original como valor.
- Agrupe através da chave aleatória.
- Emitir os valores de cada chave como saída.
Também pode usar uma transformação
Reshuffle
para impedir a união de transformações circundantes. No entanto, os efeitos secundários da transformação Reshuffle não são portáteis em diferentes executores do Apache Beam.
Para mais informações sobre o paralelismo e a otimização da fusão, consulte o artigo Ciclo de vida do pipeline.
Use métricas do Apache Beam para recolher estatísticas da pipeline
As métricas do Apache Beam são uma classe de utilidade que produz métricas para comunicar as propriedades de um pipeline em execução. Quando usa o Cloud Monitoring, as métricas do Apache Beam estão disponíveis como métricas personalizadas do Cloud Monitoring.
O exemplo seguinte mostra as métricas do Apache Beam
Counter usadas numa subclasse
DoFn.
O código de exemplo usa dois contadores. Um contador monitoriza as falhas de análise JSON (malformedCounter) e o outro contador monitoriza se a mensagem JSON é válida, mas contém um payload vazio (emptyCounter). No Cloud Monitoring, os nomes das métricas personalizadas são custom.googleapis.com/dataflow/malformedJson e custom.googleapis.com/dataflow/emptyPayload. Pode usar as métricas personalizadas para criar visualizações e políticas de alerta no Cloud Monitoring.
final TupleTag<String> errorTag = new TupleTag<String>(){};
final TupleTag<MockObject> successTag = new TupleTag<MockObject>(){};
final class ParseEventFn extends DoFn<String, MyObject> {
private final Counter malformedCounter = Metrics.counter(ParseEventFn.class, "malformedJson");
private final Counter emptyCounter = Metrics.counter(ParseEventFn.class, "emptyPayload");
private Gson gsonParser;
@Setup
public setup() {
gsonParser = new Gson();
}
@ProcessElement
public void processElement(ProcessContext c) {
try {
MyObject myObj = gsonParser.fromJson(c.element(), MyObject.class);
if (myObj.getPayload() != null) {
// Output the element if non-empty payload
c.output(successTag, myObj);
}
else {
// Increment empty payload counter
emptyCounter.inc();
}
}
catch (JsonParseException e) {
// Increment malformed JSON counter
malformedCounter.inc();
// Output the element to dead-letter queue
c.output(errorTag, c.element());
}
}
}
Migre um pipeline entre Google Cloud projetos
As tarefas do Dataflow estão associadas ao Google Cloud projeto onde as criou. Não pode mover um trabalho diretamente para um projeto diferente. Para mover um pipeline para outro projeto, pare a tarefa existente e recrie-a no novo projeto. Para um guia detalhado sobre este processo, consulte o artigo Migre tarefas de pipeline para outro projeto da Google Cloud Platform.
Saiba mais
As páginas seguintes fornecem mais informações sobre como estruturar o seu pipeline, como escolher as transformações a aplicar aos seus dados e o que ter em consideração ao escolher os métodos de entrada e saída do pipeline.
Para mais informações sobre a criação do código do utilizador, consulte os requisitos para funções fornecidas pelos utilizadores.