
概览
您可以使用 Dataflow 数据流水线执行以下任务:
- 创建周期性作业时间表。
- 了解资源在多个作业执行中的消耗位置。
- 定义和管理数据新鲜度目标。
- 深入了解各个流水线阶段,以修复和优化流水线。
如需了解 API 文档,请参阅 Data Pipelines 参考文档。
功能
- 创建周期性的批量流水线,以按时间表运行批量作业。
- 创建周期性的增量式批量流水线,以针对最新版本的输入数据运行批量作业。
- 使用流水线信息摘要图表来查看流水线的总体容量用量和资源消耗量。
- 查看流式流水线的数据新鲜度。此指标会随时间变化,可以与提醒相关联,当新鲜度低于指定目标时发出通知。
- 使用流水线指标图表比较批量流水线作业并查找异常值。
限制
区域可用性:您可以在可用的 Cloud Scheduler 区域中创建数据流水线。
配额:
- 每个项目的默认流水线数量:500
每个组织的默认流水线数量:2500
组织级层配额默认处于停用状态。您可以选择启用组织级层的配额,如果这样做,每个组织默认最多可以有 2500 个流水线。
标签:您不能使用用户定义的标签来为 Dataflow 数据流水线添加标签。但是,当您使用
additionalUserLabels字段时,这些值会传递到 Dataflow 作业。如需详细了解如何将标签应用于各个 Dataflow 作业,请参阅流水线选项。
数据流水线类型
Dataflow 有两种数据流水线类型:流式和批量。这两种流水线都运行在 Dataflow 模板中定义的作业。
- 流式数据流水线
- 流式数据流水线在创建后立即运行 Dataflow 流式作业。
- 批量数据流水线
批量数据流水线按照用户定义的时间表运行 Dataflow 批量作业。批量流水线输入文件名可以参数化,以允许进行增量式批量流水线处理。
增量式批量流水线
您可以使用日期时间占位符来指定批量流水线的增量输入文件格式。
- 可以使用年、月、日期、小时、分和秒的占位符,并且必须遵循
strftime()格式。占位符带有百分比符号 (%) 前缀。 - 创建流水线期间不会验证参数格式。
- 示例:如果指定“gs://bucket/Y”作为参数化输入文件路径,则计算结果为“gs://bucket/Y”,因为没有“%”前缀的“Y”不会映射为
strftime()格式。
- 示例:如果指定“gs://bucket/Y”作为参数化输入文件路径,则计算结果为“gs://bucket/Y”,因为没有“%”前缀的“Y”不会映射为
在每个计划的批处理流水线执行时,输入路径的占位符部分的计算结果为当前(或时间偏移)的日期时间。日期值使用预定作业所在时区的当前日期计算。如果计算出的路径与输入文件的路径匹配,则批处理流水线将在计划的时间提取该文件进行处理。
- 示例:批量流水线计划在太平洋标准时间 (PST) 每小时开始时重复执行。如果您将输入路径参数化为
gs://bucket-name/%Y-%m-%d/prefix-%H_%M.csv,则在太平洋标准时间 2021 年 4 月 15 日下午 6 点,输入路径会计算为gs://bucket-name/2021-04-15/prefix-18_00.csv。
使用时移参数
您可以使用 + 或 - 分钟或小时时间调整参数。
如需支持将输入路径与流水线时间表的当前日期时间之前或之后的评估日期时间进行匹配,请将这些参数用大括号括起来。
请使用格式 {[+|-][0-9]+[m|h]}。批处理流水线将继续按计划的时间重复,但输入路径会采用指定的时间偏移值进行计算。
- 示例:批量流水线计划在太平洋标准时间 (PST) 每小时开始时重复执行。如果您将输入路径参数化为
gs://bucket-name/%Y-%m-%d/prefix-%H_%M.csv{-2h},则在太平洋标准时间 2021 年 4 月 15 日下午 6 点,输入路径会计算为gs://bucket-name/2021-04-15/prefix-16_00.csv。
数据流水线角色
为了使 Dataflow 数据流水线操作成功,您需要具有必要的 IAM 角色,如下所示:
您需要适当的角色才能执行操作:
Datapipelines.admin:可以执行所有数据流水线操作Datapipelines.viewer:可以查看数据流水线和作业Datapipelines.invoker:可以调用数据流水线作业运行(可以使用 API 启用此角色)
Cloud Scheduler 使用的服务账号需要具有
roles/iam.serviceAccountUser角色,无论该服务账号是用户指定的 Compute Engine 服务账号还是默认的 Compute Engine 服务账号。如需了解详情,请参阅数据流水线角色。您需要获得 Cloud Scheduler 和 Dataflow 使用的服务账号的
roles/iam.serviceAccountUser角色,以使用该服务账号作为其身份进行操作。如果您未为 Cloud Scheduler 和 Dataflow 选择服务账号,则使用默认 Compute Engine 服务账号。
创建数据流水线
您可以通过以下两种方式创建 Dataflow 数据流水线:
数据流水线设置页面:首次访问 Google Cloud 控制台中的 Dataflow 流水线功能时,系统会打开一个设置页面。启用列出的 API 以创建数据流水线。
导入作业
您可以导入基于经典或灵活模板的 Dataflow 批量或流式作业,并将其设置为数据流水线。
在 Google Cloud 控制台中,前往 Dataflow 作业页面。
选择一个已完成的作业,然后在作业详情页面上选择 +作为流水线导入。
在基于模板创建流水线页面上,系统会使用已导入作业的选项填充参数。
对于批量作业,请在安排流水线部分中提供周期性时间安排。可以选择提供 Cloud Scheduler 电子邮件账号地址,用于安排批量运行。如果未指定,则使用默认 Compute Engine 服务账号。
创建数据流水线
在 Google Cloud 控制台中,前往 Dataflow 数据流水线页面。
选择 + 创建数据流水线。
在基于模板创建流水线页面上,提供流水线名称,然后填写其他模板选择和模板参数字段。
对于批量作业,请在安排流水线部分中提供周期性时间安排。可以选择提供 Cloud Scheduler 电子邮件账号地址,用于安排批量运行。如果未指定值,则系统会使用默认 Compute Engine 服务账号。
创建批量数据流水线
要创建此示例批量数据流水线,您必须拥有项目中以下资源的访问权限:
- 用于存储输入和输出文件的 Cloud Storage 存储桶
- 用于创建表的 BigQuery 数据集。
此示例流水线使用 Cloud Storage Text to BigQuery 批处理流水线模板。该模板会从 Cloud Storage 中读取 CSV 格式的文件,运行转换,然后将值插入到包含三列的 BigQuery 表中。
在本地驱动器上创建以下文件:
一个
bq_three_column_table.json文件,其中包含目标 BigQuery 表的以下架构。{ "BigQuery Schema": [ { "name": "col1", "type": "STRING" }, { "name": "col2", "type": "STRING" }, { "name": "col3", "type": "INT64" } ] }一个
split_csv_3cols.jsJavaScript 文件,用于在插入 BigQuery 之前对输入数据进行简单的转换。function transform(line) { var values = line.split(','); var obj = new Object(); obj.col1 = values[0]; obj.col2 = values[1]; obj.col3 = values[2]; var jsonString = JSON.stringify(obj); return jsonString; }一个
file01.csvCSV 文件,其中包含插入到 BigQuery 表中的多条记录。b8e5087a,74,27531 7a52c051,4a,25846 672de80f,cd,76981 111b92bf,2e,104653 ff658424,f0,149364 e6c17c75,84,38840 833f5a69,8f,76892 d8c833ff,7d,201386 7d3da7fb,d5,81919 3836d29b,70,181524 ca66e6e5,d7,172076 c8475eb6,03,247282 558294df,f3,155392 737b82a8,c7,235523 82c8f5dc,35,468039 57ab17f9,5e,480350 cbcdaf84,bd,354127 52b55391,eb,423078 825b8863,62,88160 26f16d4f,fd,397783
使用
gcloud storage cp命令将文件复制到项目的 Cloud Storage 存储桶中的文件夹,如下所示:将
bq_three_column_table.json和split_csv_3cols.js复制到gs://BUCKET_ID/text_to_bigquery/gcloud storage cp bq_three_column_table.json gs://BUCKET_ID/text_to_bigquery/gcloud storage cp split_csv_3cols.js gs://BUCKET_ID/text_to_bigquery/将
file01.csv复制到gs://BUCKET_ID/inputs/gcloud storage cp file01.csv gs://BUCKET_ID/inputs/
在 Google Cloud 控制台中,前往 Cloud Storage 存储桶页面。
如需在 Cloud Storage 存储桶中创建
tmp文件夹,请选择文件夹名称以打开“存储桶详情”页面,然后点击创建文件夹。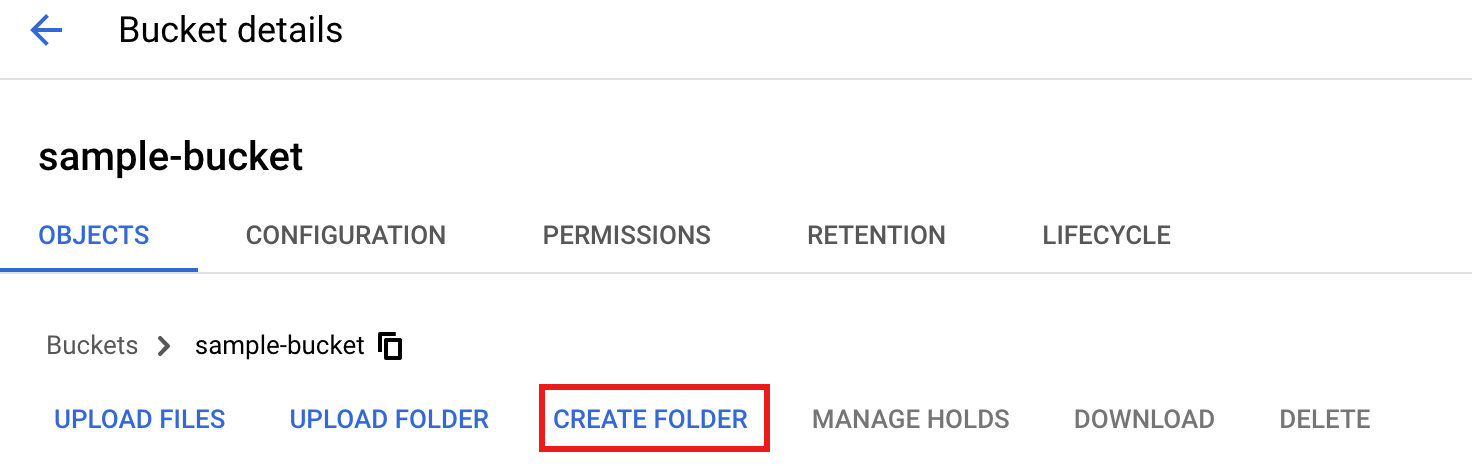
在 Google Cloud 控制台中,前往 Dataflow 数据流水线页面。
选择创建数据流水线。在基于模板创建流水线页面上,输入或选择以下各项:
- 对于流水线名称,输入
text_to_bq_batch_data_pipeline。 - 对于区域端点,选择一个 Compute Engine 区域。源区域和目标区域必须匹配。因此,您的 Cloud Storage 存储桶和 BigQuery 表必须位于同一区域。
对于 Dataflow 模板,请在批量处理数据(批处理)中,选择 Text Files on Cloud Storage to BigQuery。
对于安排流水线,请在您的时区中选择时间安排,例如每小时的第 25 分钟。您可以在提交流水线后修改时间安排。可以选择提供用于安排批量运行的 Cloud Scheduler 账号电子邮件地址。如果未指定,则使用默认 Compute Engine 服务账号。
在必需参数中,输入以下内容:
- 对于 Cloud Storage 中的 JavaScript UDF 路径 (JavaScript UDF path in Cloud Storage),输入:
gs://BUCKET_ID/text_to_bigquery/split_csv_3cols.js
- 对于 JSON 路径,输入:
BUCKET_ID/text_to_bigquery/bq_three_column_table.json
- 对于 JavaScript UDF 名称 (JavaScript UDF name),输入
transform - 对于 BigQuery 输出表,输入:
PROJECT_ID:DATASET_ID.three_column_table
- 对于 Cloud Storage 输入路径 (Cloud Storage input path),输入:
BUCKET_ID/inputs/file01.csv
- 对于临时 BigQuery 目录 (Temporary BigQuery directory),输入:
BUCKET_ID/tmp
- 对于临时位置,输入:
BUCKET_ID/tmp
- 对于 Cloud Storage 中的 JavaScript UDF 路径 (JavaScript UDF path in Cloud Storage),输入:
点击创建流水线。
- 对于流水线名称,输入
确认流水线和模板信息,并在流水线详情页面中查看当前和过去的历史记录。
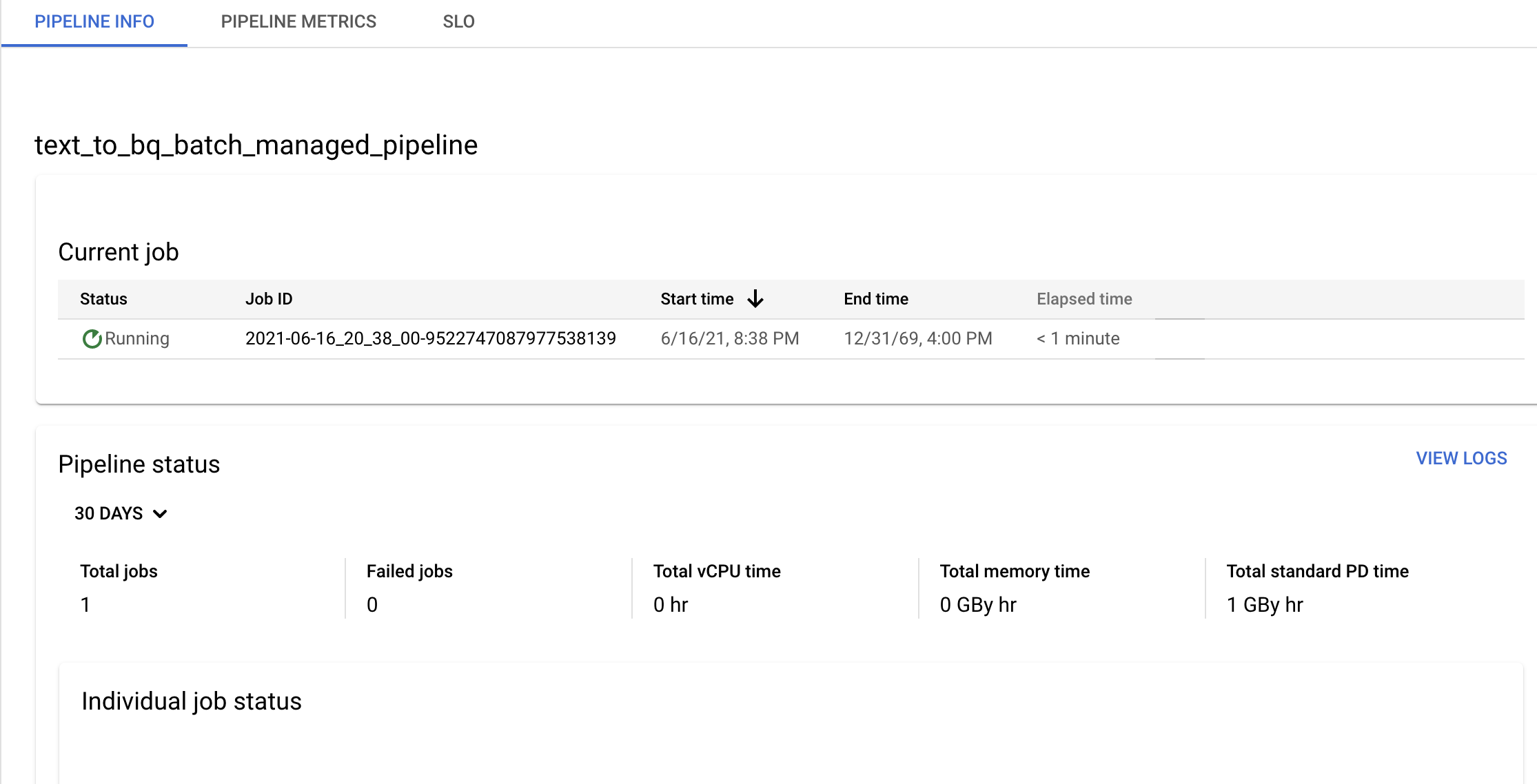
您可以在流水线详情页面的流水线信息面板中修改数据流水线时间表。
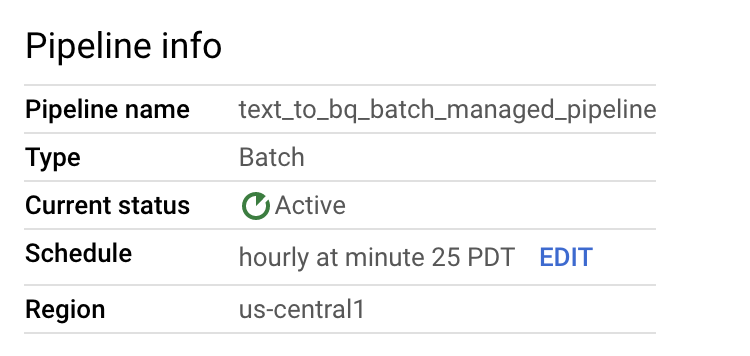
您还可以使用 Dataflow Pipelines 控制台中的运行按钮按需运行批处理流水线。
创建示例流式数据流水线
您可以按照示例批量流水线说明来创建示例流式数据流水线,但有以下不同之处:
- 对于 Pipeline schedule,请勿为流处理数据流水线指定时间表。Dataflow 流式作业会立即启动。
- 对于 Dataflow 模板,请在连续处理数据(流处理)中,选择 Text Files on Cloud Storage to BigQuery。
- 对于工作器机器类型 (Worker machine type),流水线会处理与
gs://BUCKET_ID/inputs/file01.csv模式匹配的初始文件集,以及您上传到inputs/文件夹且与此模式匹配的任何其他文件。如果 CSV 文件的大小超过数 GB,为避免可能出现内存不足错误,请选择一种内存高于默认n1-standard-4机器类型的机器类型,例如n1-highmem-8。
问题排查
本部分介绍了如何解决 Dataflow 数据流水线的问题。
数据流水线作业无法启动
使用数据流水线创建周期性作业时间表时,Dataflow 作业可能无法启动,并且 Cloud Scheduler 日志文件中会显示 503 状态错误。
当 Dataflow 暂时无法运行作业时,就会出现此问题。
如需解决此问题,请配置 Cloud Scheduler 以重试作业。由于问题是暂时性的,因此在重试作业时,作业可能会成功。如需详细了解如何在 Cloud Scheduler 中设置重试值,请参阅创建作业。
调查流水线目标违规
以下部分介绍了如何调查不符合性能目标的流水线。
周期性的批量流水线
如需对流水线的健康状况进行初始分析,请在 Google Cloud 控制台的流水线信息页面上,使用个别作业状态和每个步骤的线程时间图表。 这些图表位于流水线状态面板中。
调查示例:
您有一个在每小时的第 3 分钟运行的周期性批量流水线。每个作业通常运行大约 9 分钟。您的目标是所有作业在 10 分钟内完成。
作业状态图表显示作业运行时间超过 10 分钟。
在更新/执行历史记录表中,找到在相关时段内运行的作业。点击进入 Dataflow 作业详情页面。在该页面上,找到运行时间较长的阶段,然后在日志中查找可能的错误,以确定延迟的原因。
流处理流水线
如需对流水线的健康状况进行初始分析,请在流水线详情页面的流水线信息标签页中,使用数据新鲜度图表。此图位于流水线状态面板中。
调查示例:
您有一个流式流水线,该流水线通常生成数据新鲜度为 20 秒的输出。
您设定的目标是保证 30 秒的数据新鲜度。查看数据新鲜度图表时,您注意到,在上午 9 点到 10 点之间,数据新鲜度提高到约 40 秒。
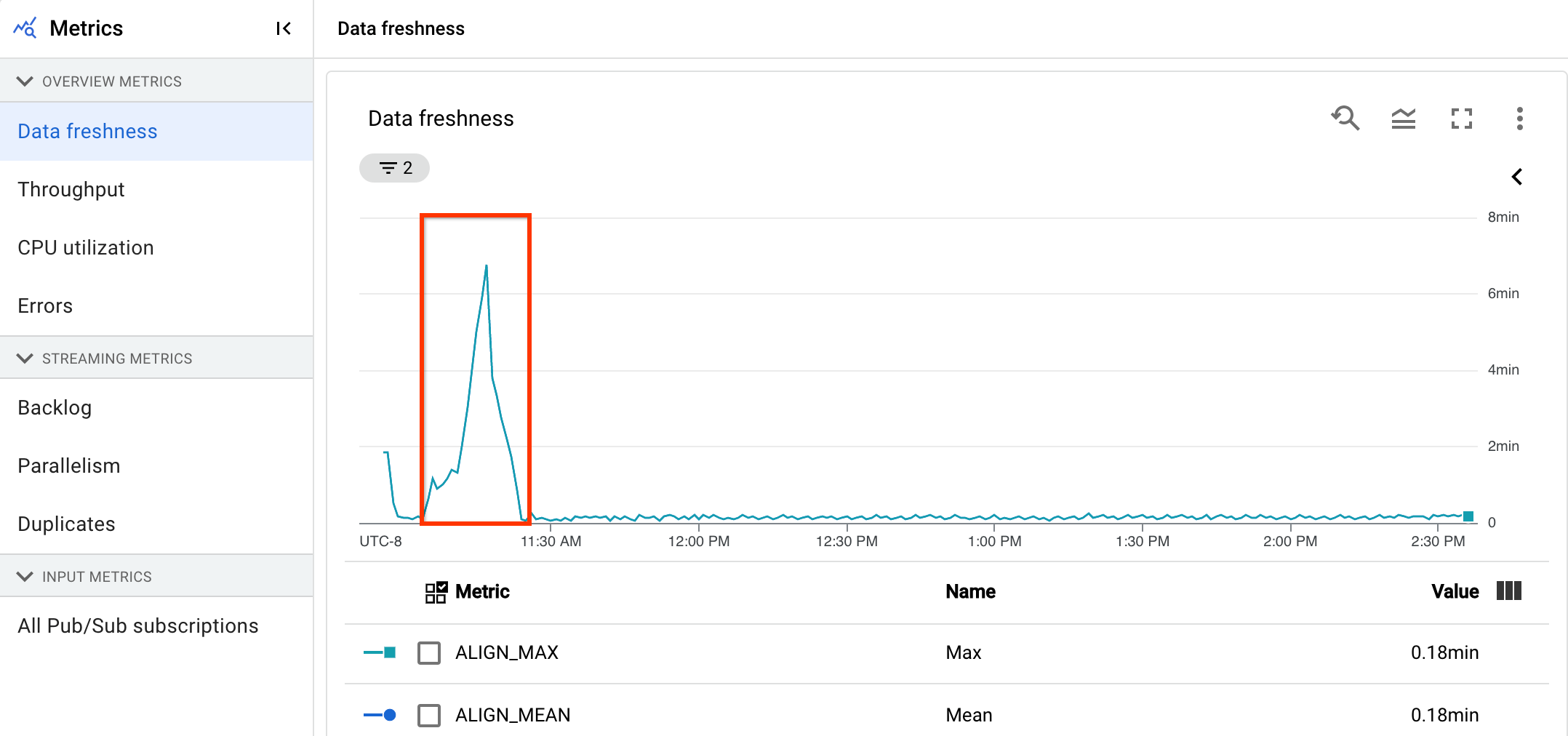
切换到流水线指标标签页,然后查看 CPU 利用率和内存利用率图表,以进行进一步分析。
错误:项目中已存在流水线 ID
如果您尝试创建名称在项目中已存在的新流水线,则会收到以下错误消息:Pipeline Id already exist within the
project。为避免此问题,请始终为流水线选择唯一的名称。