
概要
Dataflow データ パイプラインは、次のタスクに使用できます。
- 繰り返し実行するジョブのスケジュールを作成する。
- 複数のジョブ実行でリソースが消費される場所を把握する。
- データの更新頻度の目標を定義して管理する。
- パイプラインを修正して最適化するために、個々のパイプライン ステージまで掘り下げて調査する。
API ドキュメントについては、Data Pipelines リファレンスをご覧ください。
機能
- スケジュールに基づいてバッチジョブを実行する繰り返しバッチ パイプラインを作成する。
- 最新バージョンの入力データに対してバッチジョブを繰り返し実行する増分バッチ パイプラインを作成する。
- パイプラインの概要スコアカードを使用して、パイプラインの総使用量とリソース使用量を確認する。
- ストリーミング パイプラインのデータの更新頻度を表示する。この指標は、時間の経過とともに進化し、更新頻度が特定の目標を下回った場合に通知するアラートに関連付けられます。
- パイプライン指標グラフを使用して、バッチ パイプライン ジョブを比較して、異常を見つける。
制限事項
ご利用いただけるリージョン: Cloud Scheduler が利用可能なリージョンでデータ パイプラインを作成できます。
割り当て:
- プロジェクトあたりのデフォルトのパイプライン数: 500
組織あたりのデフォルトのパイプライン数: 2,500
組織レベルの割り当てはデフォルトで無効になっています。組織レベルの割り当てにオプトインすると、組織ごとにデフォルトで最大 2,500 のパイプラインを作成できます。
ラベル: ユーザー定義のラベルを使用して Dataflow データ パイプラインにラベルを付けることはできません。ただし、
additionalUserLabelsフィールドを使用すると、それらの値が Dataflow ジョブに渡されます。個々の Dataflow ジョブにラベルが適用される仕組みについては、パイプライン オプションをご覧ください。
データ パイプラインの種類
Dataflow には、ストリーミングとバッチの 2 種類のデータ パイプラインがあります。どちらのパイプラインも、Dataflow テンプレートで定義されているジョブを実行します。
- ストリーミング データ パイプライン
- ストリーミング データ パイプラインは、Dataflow ストリーミング ジョブが作成された直後にそれを実行します。
- バッチ データ パイプライン
バッチデータ パイプラインは、ユーザー定義のスケジュールで Dataflow バッチジョブを実行します。バッチ パイプラインの入力ファイル名をパラメータ化することで、増分バッチ パイプライン処理が可能になります。
増分バッチ パイプライン
日時プレースホルダを使用すると、バッチ パイプラインの増分入力ファイルの形式を指定できます。
- 年、月、日付、時、分、秒のプレースホルダを使用できます。
strftime()形式に従う必要があります。プレースホルダの前には、パーセント記号(%)が付きます。 - パイプラインの作成中は、パラメータの形式は検証されません。
- 例: パラメータ化された入力パスとして「gs://bucket/Y」を指定すると、「%」が前に付いていない「Y」は
strftime()形式に対応していないため、「gs://bucket/Y」として評価されます。
- 例: パラメータ化された入力パスとして「gs://bucket/Y」を指定すると、「%」が前に付いていない「Y」は
スケジュールされたバッチ パイプラインの実行時刻ごとに、入力パスのプレースホルダ部分が現在(またはシフト時間)の日時に評価されます。日付の値は、スケジュールされたジョブのタイムゾーンでの現在の日付を使用して評価されます。評価されたパスが入力ファイルのパスと一致する場合、ファイルは、スケジュールされた時間にバッチ パイプラインで処理するために取得されます。
- 例: バッチ パイプラインは、PST の各時間 00 分(1 時間毎)に繰り返すようにスケジュールされます。入力パスを
gs://bucket-name/%Y-%m-%d/prefix-%H_%M.csvとしてパラメータ化した場合、2021 年 4 月 15 日午後 6 時(PST)の入力パスは、gs://bucket-name/2021-04-15/prefix-18_00.csvとなります。
タイムシフト パラメータを使用する
+/- 分または時間のタイムシフト パラメータを使用できます。パイプライン スケジュールの現在の日時の前後にシフトした評価日時と入力パスの照合をサポートするには、これらのパラメータを中かっこで囲みます。{[+|-][0-9]+[m|h]} という形式を使用します。バッチ パイプラインはスケジュールされた時刻に繰り返し実行されますが、入力パスは、指定した時間オフセットで求められます。
- 例: バッチ パイプラインは、PST の各時間 00 分(1 時間毎)に繰り返すようにスケジュールされます。入力パスを
gs://bucket-name/%Y-%m-%d/prefix-%H_%M.csv{-2h}としてパラメータ化した場合、2021 年 4 月 15 日午後 6 時(PST)の入力パスは、gs://bucket-name/2021-04-15/prefix-16_00.csvとなります。
データ パイプラインのロール
Dataflow データ パイプラインのオペレーションを正常に実行するには、次に挙げる必須の IAM ロールが必要です。
オペレーションを実行するには適切なロールが必要です。
Datapipelines.admin: すべてのデータ パイプライン操作を実行できます。Datapipelines.viewer: データ パイプラインとジョブを表示できます。Datapipelines.invoker: データ パイプライン ジョブを実行できます(このロールは API で有効にできます)。
サービス アカウントがユーザー指定か、デフォルトの Compute Engine サービス アカウントかに関係なく、Cloud Scheduler で使用するサービス アカウントには
roles/iam.serviceAccountUserロールが必要です。詳細については、データ パイプラインのロールをご覧ください。そのアカウントに
roles/iam.serviceAccountUserロールが付与されることで Cloud Scheduler と Dataflow が使用するサービス アカウントとして機能できる必要があります。Cloud Scheduler と Dataflow のサービス アカウントを選択しない場合は、デフォルトの Compute Engine サービス アカウントが使用されます。
データ パイプラインを作成する
Dataflow データ パイプラインは、次の 2 つの方法で作成できます。
データ パイプラインの設定ページ: Google Cloud コンソールで、Dataflow パイプライン機能に初めてアクセスすると設定ページが開きます。リストにある API を有効にして、データ パイプラインを作成します。
ジョブをインポートする
クラシックまたは Flex テンプレートに基づく Dataflow のバッチジョブやストリーミング ジョブをインポートして、データ パイプラインにできます。
Google Cloud コンソールで、Dataflow の [ジョブ] ページに移動します。
完了したジョブを選択し、[ジョブの詳細] ページで [+パイプラインとしてインポート] を選択します。
[テンプレートからのパイプラインの作成] ページのパラメータに、インポートされたジョブのオプションが入力されます。
バッチジョブの場合は、[パイプラインのスケジュール設定] セクションで、繰り返しのスケジュールを指定します。バッチ実行のスケジュール設定で使用される Cloud Scheduler のメール アカウント アドレスは指定しなくても構いません。指定しない場合は、デフォルトの Compute Engine サービス アカウントが使用されます。
データ パイプラインを作成する
Google Cloud コンソールで、Dataflow の [データ パイプライン] ページに移動します。
[+ データ パイプラインを作成] を選択します。
[テンプレートからのパイプラインの作成] ページでパイプライン名を入力し、他のテンプレートの選択フィールドとパラメータ フィールドに入力します。
バッチジョブの場合は、[パイプラインのスケジュール設定] セクションで、繰り返しのスケジュールを指定します。バッチ実行のスケジュール設定で使用される Cloud Scheduler のメール アカウント アドレスは指定しなくても構いません。値が指定されていない場合は、デフォルトの Compute Engine サービス アカウントが使用されます。
バッチデータ パイプラインを作成する
このサンプル バッチデータ パイプラインを作成するには、プロジェクト内の次のリソースにアクセスできる必要があります。
- 入出力ファイルを保存する Cloud Storage バケット
- テーブルを作成する BigQuery データセット。
このパイプラインの例では、Cloud Storage Text to BigQuery バッチ パイプライン テンプレートを使用しています。このテンプレートは、Cloud Storage から CSV 形式のファイルを読み取り、変換を実行して、値を 3 つの列を持つ BigQuery テーブルに挿入します。
ローカル ドライブに次のファイルを作成します。
宛先 BigQuery テーブルの次のスキーマを含む
bq_three_column_table.jsonファイル。{ "BigQuery Schema": [ { "name": "col1", "type": "STRING" }, { "name": "col2", "type": "STRING" }, { "name": "col3", "type": "INT64" } ] }BigQuery に挿入する前に入力データの単純な変換を行う
split_csv_3cols.jsJavaScript ファイル。function transform(line) { var values = line.split(','); var obj = new Object(); obj.col1 = values[0]; obj.col2 = values[1]; obj.col3 = values[2]; var jsonString = JSON.stringify(obj); return jsonString; }BigQuery テーブルに挿入される複数のレコードを含む
file01.csvCSV ファイル。b8e5087a,74,27531 7a52c051,4a,25846 672de80f,cd,76981 111b92bf,2e,104653 ff658424,f0,149364 e6c17c75,84,38840 833f5a69,8f,76892 d8c833ff,7d,201386 7d3da7fb,d5,81919 3836d29b,70,181524 ca66e6e5,d7,172076 c8475eb6,03,247282 558294df,f3,155392 737b82a8,c7,235523 82c8f5dc,35,468039 57ab17f9,5e,480350 cbcdaf84,bd,354127 52b55391,eb,423078 825b8863,62,88160 26f16d4f,fd,397783
次のように、
gcloud storage cpコマンドを使用して、プロジェクトの Cloud Storage バケット内のフォルダにファイルをコピーします。bq_three_column_table.jsonとsplit_csv_3cols.jsをgs://BUCKET_ID/text_to_bigquery/にコピーします。gcloud storage cp bq_three_column_table.json gs://BUCKET_ID/text_to_bigquery/gcloud storage cp split_csv_3cols.js gs://BUCKET_ID/text_to_bigquery/file01.csvをgs://BUCKET_ID/inputs/にコピーします。gcloud storage cp file01.csv gs://BUCKET_ID/inputs/
Google Cloud コンソールで Cloud Storage の [バケット] ページに移動します。
Cloud Storage バケットに
tmpフォルダを作成するには、フォルダ名を選択してバケットの詳細ページを開き、[フォルダを作成] をクリックします。![[バケットの詳細] ページの [フォルダを作成] ボタン。](https://docs.cloud.google.com/static/dataflow/images/create-folder.png?authuser=3&hl=ja)
Google Cloud コンソールで、Dataflow の [データ パイプライン] ページに移動します。
[データ パイプラインを作成] を選択します。[テンプレートからのパイプラインの作成] ページで、次の項目を入力または選択します。
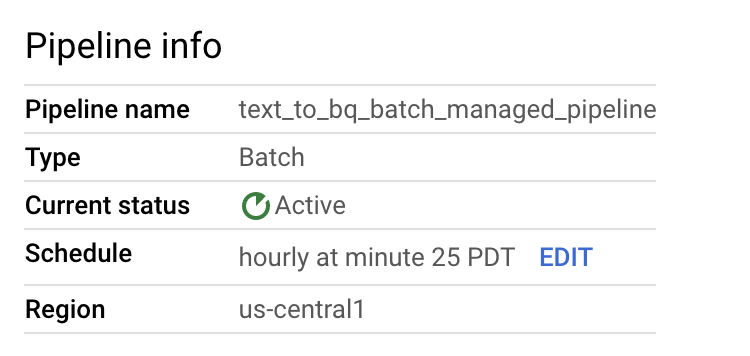
- [パイプライン名] に「
text_to_bq_batch_data_pipeline」と入力します。 - リージョン エンドポイント: Compute Engine リージョンを選択します。移行元と移行先のリージョンは一致している必要があります。このため、Cloud Storage バケットと BigQuery テーブルは同じリージョン内に存在している必要があります。
[Dataflow テンプレート] で、[Process Data in Bulk (batch)] の [Text Files on Cloud Storage to BigQuery] を選択します。
パイプラインをスケジュールする: 使用しているタイムゾーンで [Hourly at Minute 25] などのスケジュールを選択します。スケジュールはパイプラインを送信した後に編集できます。バッチ実行のスケジュール設定で使用される Cloud Scheduler のメール アカウント アドレスは指定しなくても構いません。指定しない場合は、デフォルトの Compute Engine サービス アカウントが使用されます。
[必須パラメータ] に次のように入力します。
- Cloud Storage の JavaScript UDF パス:
gs://BUCKET_ID/text_to_bigquery/split_csv_3cols.js
- JSON パス:
BUCKET_ID/text_to_bigquery/bq_three_column_table.json
- JavaScript UDF 名:
transform - BigQuery 出力テーブル:
PROJECT_ID:DATASET_ID.three_column_table
- Cloud Storage 入力パス:
BUCKET_ID/inputs/file01.csv
- 一時的な BigQuery ディレクトリ:
BUCKET_ID/tmp
- 一時的な場所:
BUCKET_ID/tmp
- Cloud Storage の JavaScript UDF パス:
[パイプラインを作成] をクリックします。
- [パイプライン名] に「
パイプラインとテンプレートの情報を確認し、[パイプラインの詳細] ページで現在の値と履歴を確認します。
![[パイプラインの詳細] ページ。](https://docs.cloud.google.com/static/dataflow/images/pipeline-details.png?authuser=3&hl=ja)
データ パイプライン スケジュールは、[パイプラインの詳細] ページの [パイプラインの情報] パネルで編集できます。
Dataflow Pipelines コンソールの [実行] ボタンを使用して、バッチ パイプラインをオンデマンドで実行することもできます。
サンプル ストリーミング データ パイプラインを作成する
サンプル ストリーミング データ パイプラインは、サンプルのバッチ パイプラインの手順に沿って作成できます。ただし、次の違いがあります。
- パイプライン スケジュールでは、ストリーミング データ パイプラインのスケジュールは指定しません。Dataflow ストリーミング ジョブはすぐに開始されます。
- [Dataflow テンプレート] で、[Process Data Continuously (stream)] の [Text Files on Cloud Storage to BigQuery] を選択します。
- ワーカー マシンタイプの場合、パイプラインは
gs://BUCKET_ID/inputs/file01.csvパターンに一致する最初のファイルセットを処理します。また、inputs/フォルダにアップロードしたファイルで、このパターンに一致する追加ファイルも処理します。CSV ファイルのサイズが数 GB を超える場合は、メモリ不足エラーが発生しないように、デフォルトのn1-standard-4マシンタイプよりも大容量のメモリを備えたマシンタイプ(n1-highmem-8など)を選択します。
トラブルシューティング
このセクションでは、Dataflow データ パイプラインの問題を解決する方法について説明します。
データ パイプライン ジョブを起動できない
データ パイプラインを使用して定期的なジョブ スケジュールを作成すると、Dataflow ジョブが起動せず、Cloud Scheduler のログファイルに 503 ステータス エラーが示されることがあります。
この問題は、Dataflow が一時的にジョブを実行できない場合に発生します。
この問題を回避するには、ジョブを再試行するように Cloud Scheduler を構成します。この問題は一時的なものであるため、ジョブを再試行すると成功する可能性があります。Cloud Scheduler での再試行値の設定の詳細については、ジョブを作成するをご覧ください。
パイプラインの目標に対する違反を調査する
以降のセクションでは、パフォーマンス目標を達成していないパイプラインを調査する方法について説明します。
繰り返し実行するバッチ パイプライン
パイプラインの健全性の初期分析には、 Google Cloud コンソールの [パイプラインの情報] ページで、[個々のジョブのステータス] と [ステップあたりのスレッド時間] グラフを使用します。これらのグラフはパイプライン ステータス パネルにあります。
調査例:
1 時間に 1 回(毎 x 時 3 分)に実行される繰り返しバッチ パイプラインがあり、通常、各ジョブは約 9 分実行され、すべてのジョブは 10 分未満で完了するという目標が設定しているとします。
ジョブ ステータス グラフは、ジョブが 10 分以上実行されていたことを表しています。
更新 / 実行履歴のテーブルで、対象の時間に実行されていたジョブを見つけます。クリックして Dataflow ジョブの詳細ページに移動します。そのページで実行ステージが長いジョブを探し、ログでエラーを確認して遅延の原因を特定します。
ストリーミング パイプライン
パイプラインの状態の初期分析には、[パイプラインの詳細] ページの [パイプラインの情報] タブで、データの更新頻度グラフを使用します。このグラフはパイプライン ステータス パネルにあります。
調査例:
通常、ストリーミング パイプラインは、20 秒のデータの更新頻度で 1 回出力を生成します。
データ更新頻度の保証目標を 30 秒に設定します。データの更新頻度グラフを確認すると、午前 9 時から 10 時の間のデータの更新頻度が、ほぼ 40 秒に上昇していることがわかります。
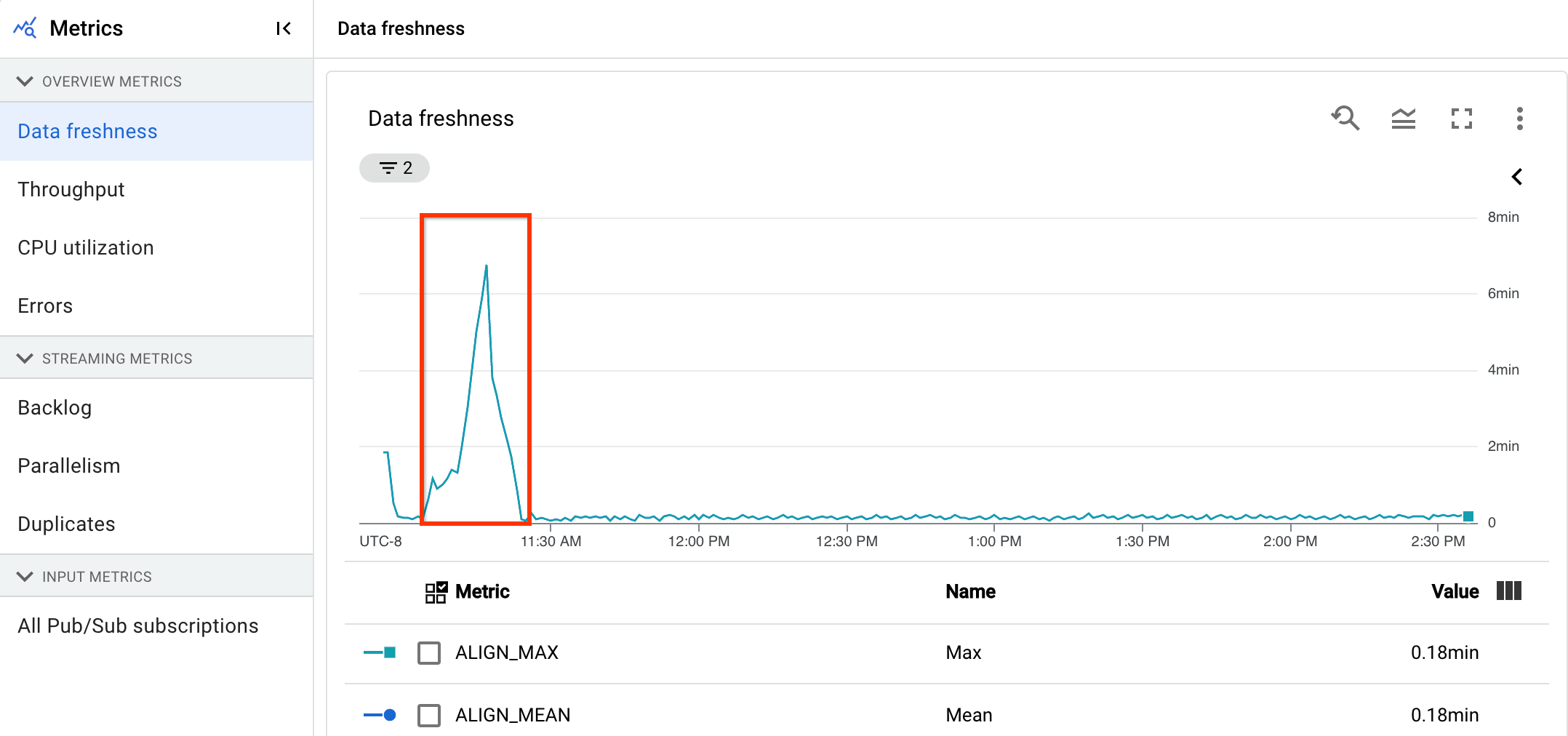
[パイプラインの指標] タブに切り替え、さらに分析するためにスループット、CPU 使用率、メモリ使用率のグラフを表示します。
エラー: プロジェクト内にパイプライン ID がすでに存在する
プロジェクト内にすでに存在する名前で新しいパイプラインを作成しようとすると、Pipeline Id already exist within the
project というエラー メッセージが表示されます。この問題を回避するために、パイプラインには常に一意の名前を選択してください。