
סקירה כללית
צינורות נתונים של Dataflow הם שירות מנוהל במלואו להמרת נתונים ולהוספת נתונים במצבי סטרימינג ואצווה. בעזרת צינורות עיבוד נתונים של Dataflow, אפשר:
- יצירת לוחות זמנים חוזרים למשימות בפייפליין.
- ניהול האופן שבו Dataflow משתמש במשאבים בכמה הפעלות של משימות.
- הגדרת יעדים לעדכניות הנתונים ומעקב אחריהם.
- כדי לייעל ולתקן שלבים בצינור, אפשר לעיין במדדים ובנתוני המעקב של כל שלב בנפרד.
מאמרי העזרה בנושא API זמינים בהפניה ל-Data Pipelines.
תכונות
- יוצרים צינור אצווה חוזר כדי להריץ משימת אצווה לפי לוח זמנים.
- יוצרים פייפליין באצווה מצטברת קבוע כדי להריץ משימה באצווה על הגרסה העדכנית של נתוני הקלט.
- אפשר להשתמש בכרטיס הניקוד של סיכום צינור עיבוד הנתונים כדי לראות את השימוש המצטבר בקיבולת ואת צריכת המשאבים של צינור עיבוד הנתונים.
- בודקים את עדכניות הנתונים בפייפליין של סטרימינג. אפשר לקשר את המדד הזה, שמשתנה עם הזמן, להתראה שתשלח לכם כשהרעננות תהיה נמוכה מהיעד שציינתם.
- אפשר להשתמש בתרשימים של מדדי צינור עיבוד נתונים כדי להשוות בין משימות של צינור עיבוד נתונים באצווה ולמצוא אנומליות.
מגבלות
זמינות אזורית: אפשר ליצור צינורות להעברת נתונים באזורים זמינים ב-Cloud Scheduler.
מכסה:
- מספר ברירת המחדל של צינורות לכל פרויקט: 500
מספר ברירת המחדל של צינורות עיבוד נתונים לכל ארגון: 2,500
המכסה ברמת הארגון מושבתת כברירת מחדל. אתם יכולים להצטרף למכסות ברמת הארגון, ואם תעשו זאת, כל ארגון יוכל להשתמש ב-2,500 צינורות לכל היותר כברירת מחדל.
תוויות: אי אפשר להשתמש בתוויות שהוגדרו על ידי המשתמש כדי לתייג צינורות עיבוד נתונים ב-Dataflow. עם זאת, כשמשתמשים בשדה
additionalUserLabels, הערכים האלה מועברים למשימת Dataflow. מידע נוסף על האופן שבו התוויות חלות על משימות Dataflow ספציפיות זמין במאמר בנושא אפשרויות של צינורות.
סוגים של צינורות נתונים
ב-Dataflow יש שני סוגים של צינורות נתונים: סטרימינג ואצווה. שני הסוגים של צינורות עיבוד נתונים מריצים משימות שמוגדרות בתבניות של Dataflow.
- צינור נתונים בסטרימינג
- צינור נתונים בסטרימינג מפעיל משימת סטרימינג של Dataflow מיד אחרי שהוא נוצר.
- פייפליין לעיבוד נתונים באצווה
צינור נתונים באצווה מריץ עבודת אצווה של Dataflow לפי לוח זמנים שהמשתמש מגדיר. אפשר להגדיר פרמטרים לשם הקובץ של קבוצת הקבצים בצינור עיבוד הנתונים כדי לאפשר עיבוד מצטבר של קבוצת הקבצים בצינור עיבוד הנתונים.
צינורות עיבוד נתונים מצטברים של קבוצות
אפשר להשתמש ב-placeholder של תאריך ושעה כדי לציין פורמט של קובץ קלט מצטבר לצינור להעברת נתונים באצווה.
- אפשר להשתמש במחזיקי מקום לשנה, לחודש, לתאריך, לשעה, לדקה ולשנייה, והם צריכים להיות בפורמט
strftime(). לפני מחזיקי המקום מופיע סמל האחוז (%). - הפורמט של הפרמטר לא מאומת במהלך יצירת צינור הנתונים.
- דוגמה: אם מציינים את הנתיב המפורמט gs://bucket/Y כנתיב קלט עם פרמטרים, המערכת תעריך אותו כ-gs://bucket/Y, כי Y ללא סימן % לפניו לא ממופה לפורמט
strftime().
- דוגמה: אם מציינים את הנתיב המפורמט gs://bucket/Y כנתיב קלט עם פרמטרים, המערכת תעריך אותו כ-gs://bucket/Y, כי Y ללא סימן % לפניו לא ממופה לפורמט
בכל פעם שמתוזמן ביצוע של צינורות להעברת נתונים של קבוצות, החלק של נתיב הקלט שמכיל את ה-placeholder נמדד לפי התאריך והשעה הנוכחיים (או המוזזים בזמן). ערכי התאריכים מוערכים לפי התאריך הנוכחי באזור הזמן של המשימה המתוזמנת. אם הנתיב המוערך תואם לנתיב של קובץ קלט, הקובץ נבחר לעיבוד על ידי צינור העיבוד באצווה בזמן המתוזמן.
- דוגמה: צינור להעברת נתונים באצווה מתוזמן לחזור בתחילת כל שעה לפי שעון החוף הפסיפי (PST). אם מגדירים את נתיב הקלט כפרמטר
gs://bucket-name/%Y-%m-%d/prefix-%H_%M.csv, ב-15 באפריל 2021 בשעה 18:00 לפי שעון החוף המערבי, נתיב הקלט יהיהgs://bucket-name/2021-04-15/prefix-18_00.csv.
שימוש בפרמטרים של הזזת זמן
אפשר להשתמש בפרמטרים של הזזת זמן של דקות או שעות עם סימן + או -.
כדי לתמוך בהתאמה של נתיב קלט עם תאריך ושעה מוערכים שעברו שינוי לפני או אחרי התאריך והשעה הנוכחיים של לוח הזמנים של צינור הנתונים, צריך להוסיף סוגריים מסולסלים לפרמטרים האלה.
בפורמט {[+|-][0-9]+[m|h]}. צינור העיבוד של אצווה ימשיך לחזור בזמן המתוזמן שלו, אבל נתיב הקלט יוערך עם היסט הזמן שצוין.
- דוגמה: צינור להעברת נתונים באצווה מתוזמן לחזור בתחילת כל שעה לפי שעון החוף הפסיפי (PST). אם מגדירים את נתיב הקלט כפרמטר
gs://bucket-name/%Y-%m-%d/prefix-%H_%M.csv{-2h}, ב-15 באפריל 2021 בשעה 18:00 לפי שעון החוף המערבי, נתיב הקלט יהיהgs://bucket-name/2021-04-15/prefix-16_00.csv.
תפקידים בצינורות נתונים
כדי שהפעולות של צינור הנתונים של Dataflow יתבצעו בהצלחה, אתם צריכים את תפקידי ה-IAM הנדרשים, כמו שמתואר בהמשך:
כדי לבצע פעולות, צריך את התפקיד המתאים:
-
Datapipelines.admin: יכול לבצע את כל הפעולות בפייפליין של הנתונים -
Datapipelines.viewer: אפשר לצפות בצינורות עיבוד נתונים ובמשימות -
Datapipelines.invoker: יכול להפעיל הרצה של משימת צינור נתונים (אפשר להפעיל את התפקיד הזה באמצעות ה-API)
-
לחשבון השירות שבו משתמש Cloud Scheduler צריך להיות תפקיד
roles/iam.serviceAccountUser, בין אם חשבון השירות מוגדר על ידי המשתמש או שהוא חשבון השירות שמוגדר כברירת מחדל ב-Compute Engine. מידע נוסף זמין במאמר בנושא תפקידים בצינור נתונים.צריך לקבל את התפקיד
roles/iam.serviceAccountUserבחשבון השירות שבו משתמשים ב-Cloud Scheduler וב-Dataflow, כדי שתוכלו לפעול בשם חשבון השירות הזה. אם לא בוחרים חשבון שירות ל-Cloud Scheduler ול-Dataflow, נעשה שימוש בחשבון השירות שמוגדר כברירת מחדל ב-Compute Engine.
יצירת צינור נתונים
אפשר ליצור צינור נתונים של Dataflow בשתי דרכים:
דף ההגדרה של צינורות להעברת נתונים: כשניגשים בפעם הראשונה לתכונה של צינורות Dataflow ב Google Cloud מסוף, נפתח דף הגדרה. מפעילים את ממשקי ה-API שמופיעים ברשימה כדי ליצור צינורות עיבוד נתונים.
ייבוא משרה
אתם יכולים לייבא משימת אצווה או סטרימינג של Dataflow שמבוססת על תבנית קלאסית או תבנית גמישה ולהפוך אותה לצינור נתונים.
נכנסים לדף Jobs של Dataflow במסוף Google Cloud .
בוחרים משימה שהושלמה, ואז בדף פרטי המשימה לוחצים על +ייבוא כצינור.
בדף יצירת צינור מתוך תבנית, הפרמטרים מאוכלסים באפשרויות של המשימה שיובאה.
עבור משימה באצווה, בקטע Schedule your pipeline (תזמון צינור עיבוד הנתונים), מציינים לוח זמנים של חזרה. אפשר לספק כתובת אימייל לחשבון בשביל Cloud Scheduler, שמשמש לתזמון של הפעלות אצווה. אם לא מציינים חשבון שירות, המערכת משתמשת בחשבון השירות שמוגדר כברירת מחדל ב-Compute Engine.
יצירת צינור נתונים
נכנסים לדף Data pipelines של Dataflow במסוף Google Cloud .
לוחצים על +יצירת צינור נתונים.
בדף Create pipeline from template (יצירת צינור עיבוד נתונים מתבנית), מציינים שם לצינור העיבוד וממלאים את שאר השדות של בחירת התבנית והפרמטרים.
עבור משימה באצווה, בקטע Schedule your pipeline (תזמון צינור עיבוד הנתונים), מציינים לוח זמנים של חזרה. אפשר לספק כתובת אימייל לחשבון בשביל Cloud Scheduler, שמשמש לתזמון של הפעלות אצווה. אם לא מציינים ערך, המערכת משתמשת בחשבון השירות המוגדר כברירת מחדל ב-Compute Engine.
יצירת צינור נתונים לעיבוד באצווה
כדי ליצור את צינור הנתונים לדוגמה הזה, צריך שתהיה לכם גישה למשאבים הבאים בפרויקט:
- קטגוריה של Cloud Storage לאחסון קובצי קלט ופלט
- מערך נתונים ב-BigQuery שבו תיצור טבלה.
בצינור הזה לדוגמה נעשה שימוש בתבנית של צינור אצווה Cloud Storage Text to BigQuery. התבנית הזו קוראת קבצים בפורמט CSV מ-Cloud Storage, מריצה טרנספורמציה ואז מוסיפה ערכים לטבלה ב-BigQuery עם שלוש עמודות.
יוצרים את הקבצים הבאים בכונן המקומי:
קובץ
bq_three_column_table.jsonשמכיל את הסכימה הבאה של טבלת היעד ב-BigQuery.{ "BigQuery Schema": [ { "name": "col1", "type": "STRING" }, { "name": "col2", "type": "STRING" }, { "name": "col3", "type": "INT64" } ] }קובץ JavaScript, שמטמיע טרנספורמציה בסיסית בנתוני הקלט לפני ההוספה ל-BigQuery.
split_csv_3cols.jsfunction transform(line) { var values = line.split(','); var obj = new Object(); obj.col1 = values[0]; obj.col2 = values[1]; obj.col3 = values[2]; var jsonString = JSON.stringify(obj); return jsonString; }קובץ CSV עם כמה רשומות שמוכנסות לטבלת BigQuery.
file01.csvb8e5087a,74,27531 7a52c051,4a,25846 672de80f,cd,76981 111b92bf,2e,104653 ff658424,f0,149364 e6c17c75,84,38840 833f5a69,8f,76892 d8c833ff,7d,201386 7d3da7fb,d5,81919 3836d29b,70,181524 ca66e6e5,d7,172076 c8475eb6,03,247282 558294df,f3,155392 737b82a8,c7,235523 82c8f5dc,35,468039 57ab17f9,5e,480350 cbcdaf84,bd,354127 52b55391,eb,423078 825b8863,62,88160 26f16d4f,fd,397783
כדי להעתיק את הקבצים לתיקיות בקטגוריה של Cloud Storage בפרויקט, משתמשים בפקודה
gcloud storage cpבאופן הבא:העתקת
bq_three_column_table.jsonו-split_csv_3cols.jsאלgs://BUCKET_ID/text_to_bigquery/gcloud storage cp bq_three_column_table.json gs://BUCKET_ID/text_to_bigquery/gcloud storage cp split_csv_3cols.js gs://BUCKET_ID/text_to_bigquery/העתקה של
file01.csvאלgs://BUCKET_ID/inputs/gcloud storage cp file01.csv gs://BUCKET_ID/inputs/
במסוף Google Cloud , נכנסים לדף Buckets של Cloud Storage.
כדי ליצור תיקייה
tmpבקטגוריה של Cloud Storage, בוחרים את שם התיקייה כדי לפתוח את דף פרטי הקטגוריה, ואז לוחצים על יצירת תיקייה.
נכנסים לדף Data pipelines של Dataflow במסוף Google Cloud .
לוחצים על יצירת צינור עיבוד נתונים. בדף יצירת צינור מתוך תבנית, מזינים או בוחרים את הפריטים הבאים:
- בשדה Pipeline name (שם צינור עיבוד הנתונים), מזינים
text_to_bq_batch_data_pipeline. - בקטע Regional endpoint (נקודת קצה אזורית), בוחרים אזור ב-Compute Engine. אזורי המקור והיעד חייבים להיות זהים. לכן, הקטגוריה של Cloud Storage והטבלה ב-BigQuery צריכים להיות באותו אזור.
בקטע תבנית Dataflow, בעיבוד נתונים בכמות גדולה (batch), בוחרים באפשרות קבצי טקסט ב-Cloud Storage ל-BigQuery.
בקטע Schedule your pipeline (תזמון צינור הנתונים), בוחרים תזמון, למשל Hourly (שעתי) בדקה 25, באזור הזמן שלכם. אפשר לערוך את לוח הזמנים אחרי ששולחים את צינור הנתונים. אפשר לציין כתובת אימייל של חשבון בשביל Cloud Scheduler, שמשמש לתזמון של הפעלות אצווה. אם לא מציינים חשבון שירות, המערכת משתמשת בחשבון השירות שמוגדר כברירת מחדל ב-Compute Engine.
בקטע פרמטרים נדרשים, מזינים את הפרטים הבאים:
- נתיב של פונקציית UDF ב-JavaScript ב-Cloud Storage:
gs://BUCKET_ID/text_to_bigquery/split_csv_3cols.js
- בקטע נתיב JSON:
BUCKET_ID/text_to_bigquery/bq_three_column_table.json
- בשדה שם של פונקציית UDF ב-JavaScript:
transform - בטבלת הפלט של BigQuery:
PROJECT_ID:DATASET_ID.three_column_table
- בקטע Cloud Storage input path (נתיב קלט של Cloud Storage):
BUCKET_ID/inputs/file01.csv
- בקטע ספריית BigQuery זמנית:
BUCKET_ID/tmp
- בקטע מיקום זמני:
BUCKET_ID/tmp
- נתיב של פונקציית UDF ב-JavaScript ב-Cloud Storage:
לוחצים על יצירת צינור.
- בשדה Pipeline name (שם צינור עיבוד הנתונים), מזינים
בדף פרטי צינור אפשר לאשר את המידע על צינורות ומאגרי תבניות ולראות את ההיסטוריה הנוכחית והקודמת.
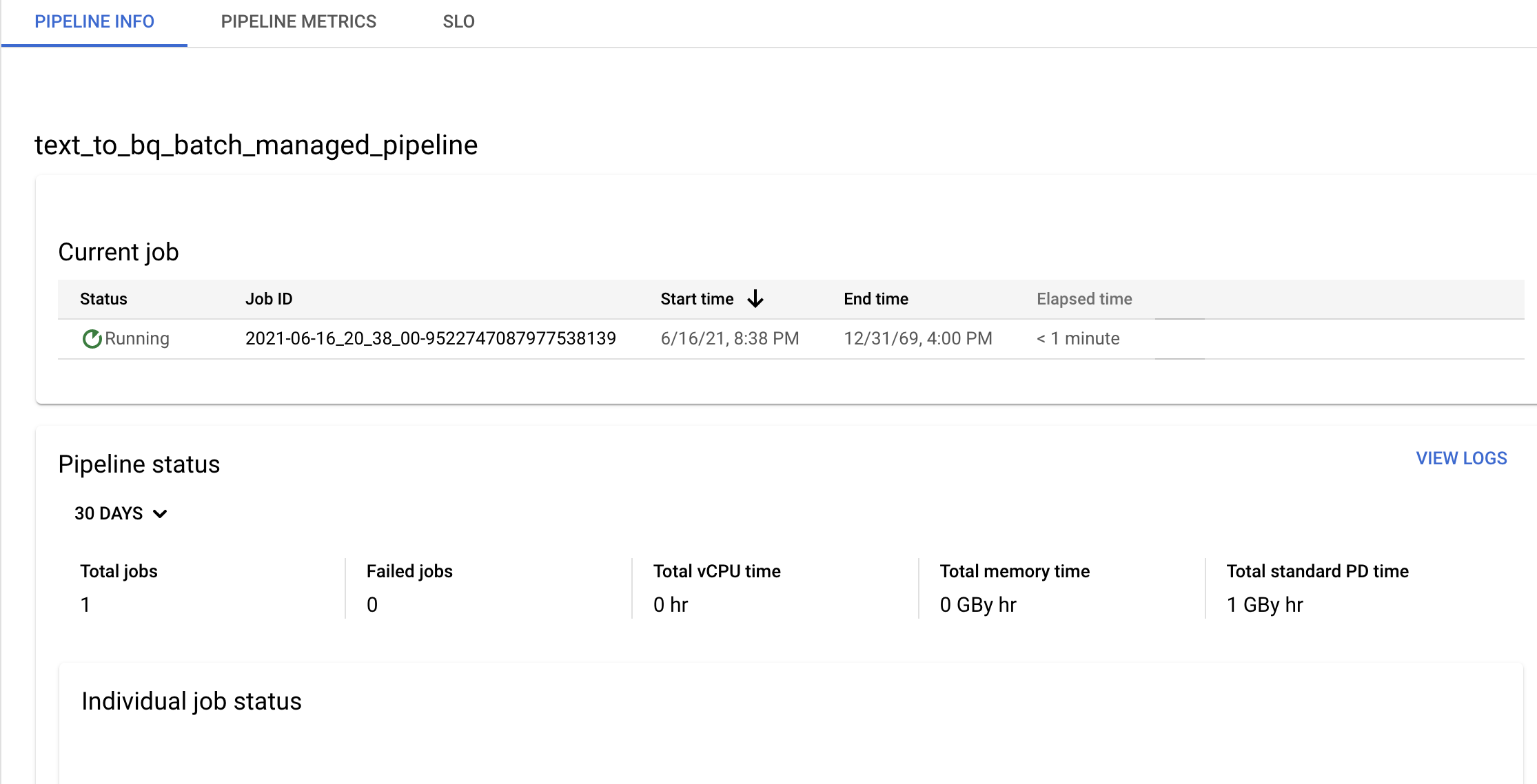
אפשר לערוך את התזמון של צינור הנתונים בחלונית פרטי צינור בדף פרטי צינור.
אפשר גם להפעיל צינור עיבוד נתונים באצווה לפי דרישה באמצעות הלחצן הפעלה במסוף Dataflow Pipelines.
יצירת צינור נתונים לדוגמה בסטרימינג
כדי ליצור צינור להעברת נתונים בסטרימינג, פועלים לפי ההוראות ליצירת צינור להעברת נתונים באצווה, עם ההבדלים הבאים:
- בקטע Pipeline schedule (תזמון צינור עיבוד הנתונים), לא מציינים תזמון לצינור עיבוד נתונים בסטרימינג. משימת הסטרימינג של Dataflow מתחילה באופן מיידי.
- בקטע תבנית Dataflow, באפשרות עיבוד נתונים באופן רציף (סטרימינג), בוחרים באפשרות קבצי טקסט ב-Cloud Storage ל-BigQuery.
- בסוג מכונת Worker, הפייפליין מעבד את קבוצת הקבצים הראשונית שתואמת לתבנית
gs://BUCKET_ID/inputs/file01.csvואת כל הקבצים הנוספים שתואמים לתבנית הזו שמעלים לתיקייהinputs/. אם הגודל של קובצי ה-CSV גדול מכמה GB, כדי להימנע משגיאות אפשריות של חוסר זיכרון, צריך לבחור סוג מכונה עם זיכרון גדול יותר מסוג מכונת ברירת המחדל של 4 vCPU, כמו סוג מכונה של 8 vCPU עם מכונה מרובת זיכרון (high-memory) (לדוגמה,n4-highmem-8).
פתרון בעיות
בקטע הזה מוסבר איך לפתור בעיות בצינורות נתונים של Dataflow.
הפעלת משימה של צינור נתונים נכשלת
כשמשתמשים ב-Data Pipelines כדי ליצור לוח זמנים של משימות חוזרות, יכול להיות שמשימת Dataflow לא תופעל, ושגיאת סטטוס 503 תופיע בקובצי היומן של Cloud Scheduler.
הבעיה הזו מתרחשת כשאין ל-Dataflow אפשרות להריץ את העבודה באופן זמני.
כדי לפתור את הבעיה, צריך להגדיר את Cloud Scheduler כך שינסה שוב להריץ את העבודה. מכיוון שהבעיה זמנית, יכול להיות שהניסיון החוזר של העבודה יצליח. למידע נוסף על הגדרת ערכי ניסיון חוזר ב-Cloud Scheduler, אפשר לעיין במאמר בנושא יצירת משימה.
בדיקת הפרות של יעדים בצינור עיבוד נתונים
בקטעים הבאים מוסבר איך לבדוק צינורות שלא עומדים ביעדי הביצועים.
צינורות עיבוד נתונים חוזרים של מקבצים
כדי לבצע ניתוח ראשוני של תקינות צינור הנתונים, בדף Pipeline info במסוף Google Cloud , משתמשים בתרשימים Individual job status ו-Thread time per step. התרשימים האלה נמצאים בחלונית 'סטטוס צינור המכירות'.
חקירה לדוגמה:
יש לכם צינור להעברת נתונים של אצווה שחוזר על עצמו ופועל כל שעה, 3 דקות אחרי תחילת השעה. כל משימה פועלת בדרך כלל במשך כ-9 דקות. יש לכם מטרה להשלים את כל העבודות תוך פחות מ-10 דקות.
בתרשים של סטטוס המשימה מוצג שמשימה רצה במשך יותר מ-10 דקות.
בטבלת ההיסטוריה Update/Execution, מחפשים את העבודה שהופעלה במהלך השעה הרלוונטית. לוחצים כדי לעבור לדף הפרטים של המשימה ב-Dataflow. בדף הזה, מאתרים את השלב שפועל הכי הרבה זמן, ואז מחפשים ביומנים שגיאות אפשריות כדי להבין מה הסיבה לעיכוב.
צינורות עיבוד נתונים בסטרימינג
כדי לבצע ניתוח ראשוני של תקינות הצינור, בדף Pipeline Details, בכרטיסייה Pipeline info, משתמשים בתרשים של רעננות הנתונים. התרשים הזה נמצא בחלונית הסטטוס של הצינור.
חקירה לדוגמה:
יש לכם צינור סטרימינג שבדרך כלל יוצר פלט עם רעננות נתונים של 20 שניות.
הגדרתם יעד של עדכניות נתונים למשך 30 שניות. כשבודקים את התרשים של עדכניות הנתונים, רואים שבין 9:00 ל-10:00, עדכניות הנתונים עלתה כמעט ל-40 שניות.
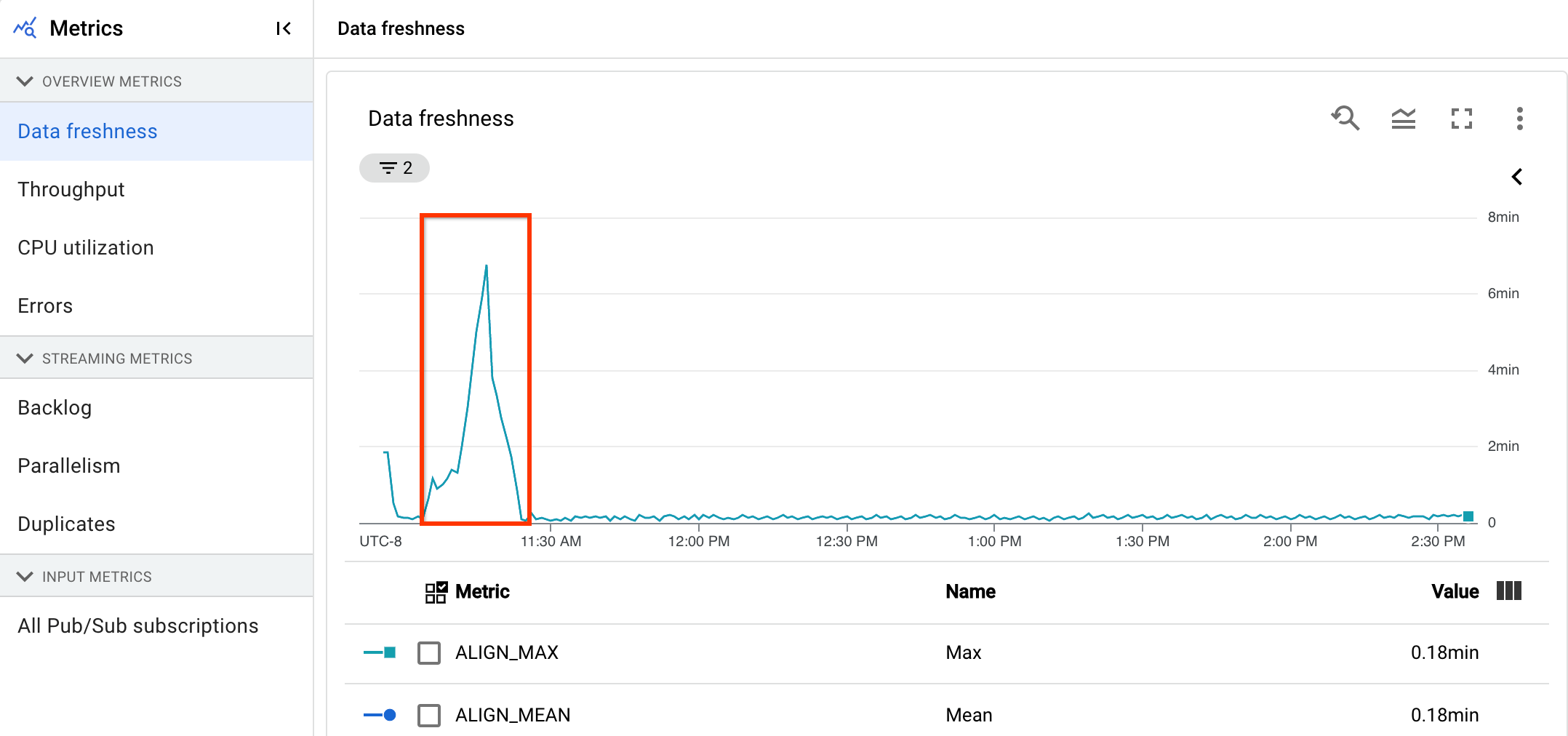
עוברים לכרטיסייה Pipeline metrics וצופים בתרשימים CPU Utilization ו-Memory Utilization כדי לבצע ניתוח נוסף.
שגיאה: מזהה צינור העיבוד כבר קיים בפרויקט
אם מנסים ליצור צינור חדש עם שם שכבר קיים בפרויקט, מוצגת הודעת השגיאה Pipeline Id already exist within the
project. כדי להימנע מהבעיה הזו, חשוב לבחור תמיד שמות ייחודיים לצינורות.