
本页面介绍了如何在具有 GPU 的 Dataflow 上运行 Apache Beam 流水线。使用 GPU 的作业按 Dataflow 价格页面中指定的费用收费。
如需详细了解如何将 GPU 与 Dataflow 搭配使用,请参阅 Dataflow 对 GPU 的支持。如需详细了解使用 GPU 构建流水线的开发者工作流,请参阅将 GPU 与 Dataflow 搭配使用的简介。
使用 Apache Beam 笔记本
如果您已经有流水线,并且想在 Dataflow 上使用 GPU 运行,则可以跳过本部分。
Apache Beam 笔记本提供了一种便捷的方式,让您可以在不设置开发环境的情况下,使用 GPU 对流水线进行原型设计和迭代开发。如需开始使用,请阅读使用 Apache Beam 笔记本进行开发指南,启动 Apache Beam 笔记本实例,然后按照“将 GPU 与 Apache Beam 配合使用”示例笔记本进行操作。
预配 GPU 配额
GPU 设备受 Google Cloud Platform 项目的配额可用性的限制。请在您选择的区域中申请 GPU 配额。
安装 GPU 驱动程序
如需在 Dataflow 工作器上安装 NVIDIA 驱动程序,请将 install-nvidia-driver 附加到 worker_accelerator 服务选项。
指定 install-nvidia-driver 选项时,Dataflow 会使用 Container-Optimized OS 提供的 cos-extensions 实用程序将 NVIDIA 驱动程序安装到 Dataflow 工作器上。指定 install-nvidia-driver 即表示您同意接受 NVIDIA 许可协议。
NVIDIA 驱动程序安装程序提供的二进制文件和库会装载到运行 /usr/local/nvidia/ 下的流水线用户代码的容器中。
GPU 驱动程序版本取决于 Dataflow 使用的 Container-Optimized OS 版本。如需查找给定 Dataflow 作业的 GPU 驱动程序版本,请在作业的 Dataflow 步骤日志中搜索 GPU driver。
构建自定义容器映像
如需与 GPU 交互,您可能需要其他 NVIDIA 软件,例如 GPU 加速的库和 CUDA 工具包。请在运行用户代码的 Docker 容器中提供这些库。
如需自定义容器映像,请提供满足 Apache Beam SDK 容器映像合同并具有所需 GPU 库的映像。
如需提供自定义容器映像,请使用 Dataflow Runner v2 并使用 sdk_container_image 流水线选项提供容器映像。如果您使用的是 Apache Beam 2.29.0 或更低版本,请使用 worker_harness_container_image 流水线选项。如需了解详情,请参阅使用自定义容器。
如需构建自定义容器映像,请使用以下两种方法之一:
使用已为使用 GPU 而配置的现有映像
您可以基于为使用 GPU 预先配置的现有基础映像,构建满足 Apache Beam SDK 容器合同的 Docker 映像。 例如,TensorFlow Docker 映像和 NVIDIA 容器映像已预先配置以使用 GPU。
使用 Python 3.6 基于 TensorFlow Docker 映像构建的示例 Dockerfile 如以下示例所示:
ARG BASE=tensorflow/tensorflow:2.5.0-gpu
FROM $BASE
# Check that the chosen base image provides the expected version of Python interpreter.
ARG PY_VERSION=3.6
RUN [[ $PY_VERSION == `python -c 'import sys; print("%s.%s" % sys.version_info[0:2])'` ]] \
|| { echo "Could not find Python interpreter or Python version is different from ${PY_VERSION}"; exit 1; }
RUN pip install --upgrade pip \
&& pip install --no-cache-dir apache-beam[gcp]==2.29.0 \
# Verify that there are no conflicting dependencies.
&& pip check
# Copy the Apache Beam worker dependencies from the Beam Python 3.6 SDK image.
COPY --from=apache/beam_python3.6_sdk:2.29.0 /opt/apache/beam /opt/apache/beam
# Apache Beam worker expects pip at /usr/local/bin/pip by default.
# Some images have pip in a different location. If necessary, make a symlink.
# This line can be omitted in Beam 2.30.0 and later versions.
RUN [[ `which pip` == "/usr/local/bin/pip" ]] || ln -s `which pip` /usr/local/bin/pip
# Set the entrypoint to Apache Beam SDK worker launcher.
ENTRYPOINT [ "/opt/apache/beam/boot" ]
使用 TensorFlow Docker 映像时,请使用 TensorFlow 2.5.0 或更高版本。早期的 TensorFlow Docker 映像会安装 tensorflow-gpu 软件包而不是 tensorflow 软件包。TensorFlow 2.1.0 版发布后,两者的区别不重要,但多个下游软件包(如 tfx)需要 tensorflow 软件包。
较大的容器大小会减慢工作器的启动时间。使用 Deep Learning Containers 等容器时,可能会出现这种性能变化。
安装特定 Python 版本
如果您有严格的 Python 版本要求,则可以从具有所需 GPU 库的 NVIDIA 基础映像构建映像,然后安装 Python 解释器。
以下示例演示了如何从 CUDA 容器映像目录中选择不包含 Python 解释器的 NVIDIA 映像。调整示例以安装所需的 Python 3 和 pip 版本。该示例使用 TensorFlow。因此,在选择映像时,基础映像中的 CUDA 和 cuDNN 版本满足 TensorFlow 版本的要求。
示例 Dockerfile 如下所示:
# Select an NVIDIA base image with needed GPU stack from https://ngc.nvidia.com/catalog/containers/nvidia:cuda
FROM nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04
RUN \
# Add Deadsnakes repository that has a variety of Python packages for Ubuntu.
# See: https://launchpad.net/~deadsnakes/+archive/ubuntu/ppa
apt-key adv --keyserver keyserver.ubuntu.com --recv-keys F23C5A6CF475977595C89F51BA6932366A755776 \
&& echo "deb http://ppa.launchpad.net/deadsnakes/ppa/ubuntu focal main" >> /etc/apt/sources.list.d/custom.list \
&& echo "deb-src http://ppa.launchpad.net/deadsnakes/ppa/ubuntu focal main" >> /etc/apt/sources.list.d/custom.list \
&& apt-get update \
&& apt-get install -y curl \
python3.8 \
# With python3.8 package, distutils need to be installed separately.
python3-distutils \
&& rm -rf /var/lib/apt/lists/* \
&& update-alternatives --install /usr/bin/python python /usr/bin/python3.8 10 \
&& curl https://bootstrap.pypa.io/get-pip.py | python \
&& pip install --upgrade pip \
# Install Apache Beam and Python packages that will interact with GPUs.
&& pip install --no-cache-dir apache-beam[gcp]==2.29.0 tensorflow==2.4.0 \
# Verify that there are no conflicting dependencies.
&& pip check
# Copy the Apache Beam worker dependencies from the Beam Python 3.8 SDK image.
COPY --from=apache/beam_python3.8_sdk:2.29.0 /opt/apache/beam /opt/apache/beam
# Set the entrypoint to Apache Beam SDK worker launcher.
ENTRYPOINT [ "/opt/apache/beam/boot" ]
在某些操作系统发行版上,使用操作系统软件包管理系统安装特定 Python 版本可能很困难。在这种情况下,请使用 Miniconda 或 pyenv 等工具安装 Python 解释器。
示例 Dockerfile 如下所示:
FROM nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04
# The Python version of the Dockerfile must match the Python version you use
# to launch the Dataflow job.
ARG PYTHON_VERSION=3.8
# Update PATH so we find our new Conda and Python installations.
ENV PATH=/opt/python/bin:/opt/conda/bin:$PATH
RUN apt-get update \
&& apt-get install -y wget \
&& rm -rf /var/lib/apt/lists/* \
# The NVIDIA image doesn't come with Python pre-installed.
# We use Miniconda to install the Python version of our choice.
&& wget -q https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh \
&& bash Miniconda3-latest-Linux-x86_64.sh -b -p /opt/conda \
&& rm Miniconda3-latest-Linux-x86_64.sh \
# Create a new Python environment with needed version, and install pip.
&& conda create -y -p /opt/python python=$PYTHON_VERSION pip \
# Remove unused Conda packages, install necessary Python packages via pip
# to avoid mixing packages from pip and Conda.
&& conda clean -y --all --force-pkgs-dirs \
&& pip install --upgrade pip \
# Install Apache Beam and Python packages that will interact with GPUs.
&& pip install --no-cache-dir apache-beam[gcp]==2.29.0 tensorflow==2.4.0 \
# Verify that there are no conflicting dependencies.
&& pip check \
# Apache Beam worker expects pip at /usr/local/bin/pip by default.
# You can omit this line when using Beam 2.30.0 and later versions.
&& ln -s $(which pip) /usr/local/bin/pip
# Copy the Apache Beam worker dependencies from the Apache Beam SDK for Python 3.8 image.
COPY --from=apache/beam_python3.8_sdk:2.29.0 /opt/apache/beam /opt/apache/beam
# Set the entrypoint to Apache Beam SDK worker launcher.
ENTRYPOINT [ "/opt/apache/beam/boot" ]
使用 Apache Beam 容器映像
您可以配置容器映像以使用 GPU,而无需使用预配置的映像。仅当预配置的映像不适用时,才建议使用此方法。如需设置您自己的容器映像,您需要选择兼容的库并配置其执行环境。
示例 Dockerfile 如下所示:
FROM apache/beam_python3.7_sdk:2.24.0
ENV INSTALLER_DIR="/tmp/installer_dir"
# The base image has TensorFlow 2.2.0, which requires CUDA 10.1 and cuDNN 7.6.
# You can download cuDNN from NVIDIA website
# https://developer.nvidia.com/cudnn
COPY cudnn-10.1-linux-x64-v7.6.0.64.tgz $INSTALLER_DIR/cudnn.tgz
RUN \
# Download CUDA toolkit.
wget -q -O $INSTALLER_DIR/cuda.run https://developer.download.nvidia.com/compute/cuda/10.1/Prod/local_installers/cuda_10.1.243_418.87.00_linux.run && \
# Install CUDA toolkit. Print logs upon failure.
sh $INSTALLER_DIR/cuda.run --toolkit --silent || (egrep '^\[ERROR\]' /var/log/cuda-installer.log && exit 1) && \
# Install cuDNN.
mkdir $INSTALLER_DIR/cudnn && \
tar xvfz $INSTALLER_DIR/cudnn.tgz -C $INSTALLER_DIR/cudnn && \
cp $INSTALLER_DIR/cudnn/cuda/include/cudnn*.h /usr/local/cuda/include && \
cp $INSTALLER_DIR/cudnn/cuda/lib64/libcudnn* /usr/local/cuda/lib64 && \
chmod a+r /usr/local/cuda/include/cudnn*.h /usr/local/cuda/lib64/libcudnn* && \
rm -rf $INSTALLER_DIR
# A volume with GPU drivers will be mounted at runtime at /usr/local/nvidia.
ENV LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/nvidia/lib64:/usr/local/cuda/lib64
/usr/local/nvidia/lib64 中的驱动程序库必须是在容器中可发现的共享库。如需使驱动程序库可被发现,请配置 LD_LIBRARY_PATH 环境变量。
如果您使用 TensorFlow,则必须选择兼容的 CUDA 工具包和 cuDNN 版本。如需了解详情,请参阅软件要求和经过测试的构建配置。
为 Dataflow 工作器选择 GPU 类型和数量
如需配置要挂接到 Dataflow 工作器的 GPU 类型和数量,请使用 worker_accelerator 服务选项。您可以根据应用场景以及计划在流水线中使用 GPU 的方式选择 GPU 的类型和数量。
如需查看 Dataflow 支持的 GPU 类型列表,请参阅 Dataflow 对 GPU 的支持。
使用 GPU 运行作业
使用 GPU 运行 Dataflow 作业的注意事项如下:
由于 GPU 容器通常很大,为避免耗尽磁盘空间,请执行以下操作:
- 将默认启动磁盘大小增加到 50 GB 或更多。
考虑有多少进程在工作器虚拟机上同时使用同一 GPU。然后,决定您要将 GPU 限制为单个进程还是允许多个进程使用 GPU。
- 如果一个 Apache Beam SDK 进程可以使用大多数可用的 GPU 内存(例如通过将大型模型加载到 GPU 上),则建议您设置流水线选项
--experiments=no_use_multiple_sdk_containers以将工作器配置为使用单个进程。或者,使用具有一个 vCPU 的工作器,方法是将自定义机器类型(例如n1-custom-1-NUMBER_OF_MB或n1-custom-1-NUMBER_OF_MB-ext)用于扩展内存。如需了解详情,请参阅使用每个 vCPU 具有更多内存的机器类型。 - 如果 GPU 由多个进程共享,请使用 NVIDIA 多处理服务 (MPS) 在共享 GPU 上启用并发处理。
如需了解背景信息,请参阅 GPU 和工作器并行性。
- 如果一个 Apache Beam SDK 进程可以使用大多数可用的 GPU 内存(例如通过将大型模型加载到 GPU 上),则建议您设置流水线选项
如需使用 GPU 运行 Dataflow 作业,请使用以下命令。
如需使用适配,请使用 accelerator 资源提示,而不是使用 worker_accelerator 服务选项。
Python
python PIPELINE \
--runner "DataflowRunner" \
--project "PROJECT" \
--temp_location "gs://BUCKET/tmp" \
--region "REGION" \
--worker_harness_container_image "IMAGE" \
--disk_size_gb "DISK_SIZE_GB" \
--dataflow_service_options "worker_accelerator=type:GPU_TYPE;count:GPU_COUNT;install-nvidia-driver" \
--experiments "use_runner_v2"
请替换以下内容:
- PIPELINE:流水线源代码文件
- PROJECT: Google Cloud 项目名称
- BUCKET:Cloud Storage 存储桶
- REGION:Dataflow 区域,例如
us-central1。选择一个可用区支持GPU_TYPE的 `REGION`。Dataflow 会自动将工作器分配到此区域中具有 GPU 的可用区。 - IMAGE:Docker 映像的 Artifact Registry 路径
- DISK_SIZE_GB:每个工作器虚拟机的启动磁盘大小(例如
50) - GPU_TYPE:可用的 GPU 类型(例如
nvidia-tesla-t4)。 - GPU_COUNT:要挂接到每个工作器虚拟机的 GPU 数量(例如
1)
验证 Dataflow 作业
要确认作业使用具有 GPU 的工作器虚拟机,请按以下步骤操作:
- 验证作业的 Dataflow 工作器是否已启动。
- 在作业运行期间,查找与该作业关联的工作器虚拟机。
- 在搜索产品和资源提示框中,粘贴作业 ID。
- 选择与作业关联的 Compute Engine 虚拟机实例。
您还可以在 Compute Engine 控制台中找到所有正在运行的实例的列表。
在 Google Cloud 控制台中,前往虚拟机实例页面。
点击虚拟机实例详情。
验证详情页面是否包含 GPU 部分,以及是否已附加 GPU。
如果作业未使用 GPU 启动,请检查 worker_accelerator 服务选项是否配置正确并且显示在 Dataflow 监控界面的 dataflow_service_options 中。加速器元数据中的令牌顺序非常重要。
例如,Dataflow 监控界面中的 dataflow_service_options 流水线选项可能如下所示:
['worker_accelerator=type:nvidia-tesla-t4;count:1;install-nvidia-driver', ...]
查看 GPU 利用率
如需查看工作器虚拟机上的 GPU 利用率,请执行以下操作:
在 Google Cloud 控制台中,前往 Monitoring 或使用以下按钮:
在 Monitoring 导航窗格中,点击 Metrics Explorer。
对于资源类型,请指定
Dataflow Job。对于指标,请指定GPU utilization或GPU memory utilization,具体取决于您要监控的指标。
如需了解详情,请参阅 Metrics Explorer。
启用 NVIDIA 多处理服务
对于在具有多个 vCPU 的工作器上运行的 Python 流水线,您可以通过启用 NVIDIA 多进程服务 (MPS) 来提升 GPU 操作的并发性。如需了解详情以及使用 MPS 的步骤,请参阅使用 NVIDIA MPS 提高共享 GPU 的性能。
可选:配置预配模型
您可以为流水线配置预配模型,从而提高获取 GPU 资源的能力。
Dataflow 支持以下预配模型:标准和灵活启动。
标准配置
标准预配是所有使用 GPU 的 Dataflow 作业的默认预配模型。使用加速器资源的实例会根据资源可用性立即创建。
您无需进行任何配置即可使用标准配置模型。
如果您运行 Dataflow 作业的可用区或区域中没有可立即使用的 GPU,则作业可能无法启动。如需了解详情,请参阅作业在启动时立即失败。
灵活启动预配
如果使用灵活启动预配模型,系统会根据资源可用性来安排实例和加速器资源的预配和实现。您可以使用灵活启动预配模型来提高获得 GPU 的几率。
如需使用灵活启动预配模型,请将 provisioning_model:FLEX_START 附加到 worker_accelerator 服务选项。例如:
worker_accelerator=type:nvidia-tesla-t4;count:1;install-nvidia-driver:5xx;provisioning_model:FLEX_START
启用灵活启动的作业会提交以供执行,但仅在所需资源可用时才会执行。如需验证是否已启用弹性开始预配,请在 job-message 日志中查找以下日志条目:
已为作业 JOB_ID 启用 FLEX_START
如需确定作业是否已开始执行,请在作业指标页面中查看自动调节图表:
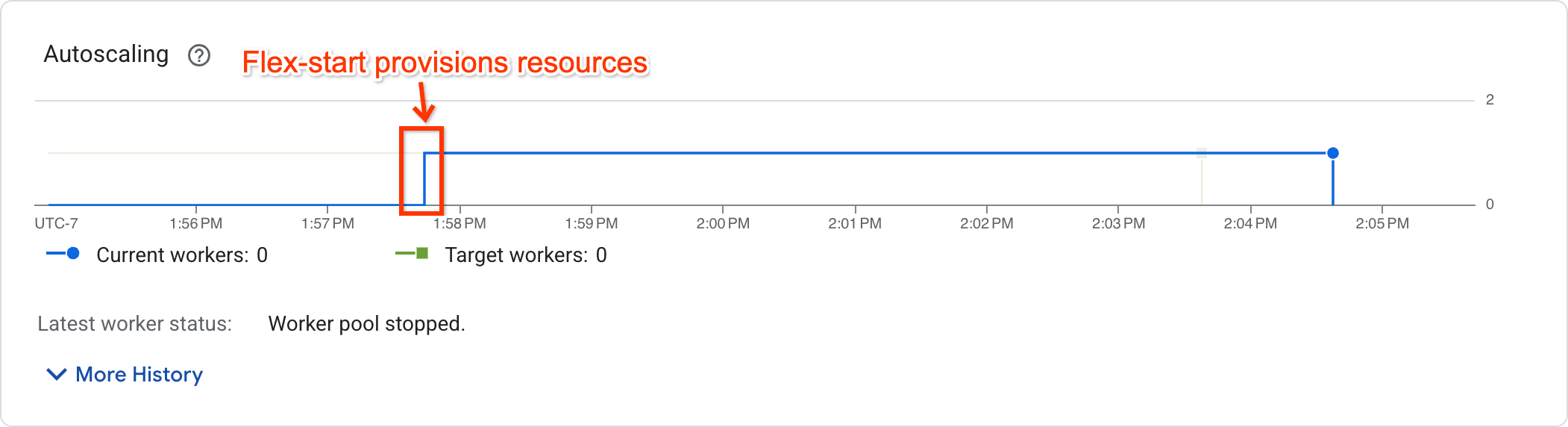
已开始执行的作业会显示非零工作器数量,而正在等待资源的作业的工作器数量为零。
支持和限制
- 只有批处理流水线支持灵活启动。不支持流处理流水线。
- 使用灵活启动预配模型预配的工作器虚拟机的最长运行时为 7 天。在此期限过后,具有加速器的工作器虚拟机会被抢占。Dataflow 将尝试重新配置资源。如果无法重新配置资源,流水线将失败。
- 灵活启动会在作业提交后尝试预配资源,最长尝试 1 小时。如果 1 小时后仍无法预配资源,作业将失败。
- 灵活启动会使用抢占式配额。如果您的项目缺少抢占式配额,则会使用标准配额。如需了解详情,请参阅抢占式配额。
- 如果未提供工作器可用区配置,Dataflow 将根据硬件支持、当前资源和配额可用性以及匹配的预留来选择一个可用区,以在该可用区中创建所有资源。此地区可能与作业的服务资源所在的地区不同。
- 不支持水平自动扩缩。如需使用多个工作器,请设置
--num_workers流水线选项。 - 不支持 TPU。
- 不支持合身度评估。
排查灵活启动问题
如果您的作业在提交 1 小时后失败,并显示以下错误:
The Dataflow job appears to be stuck because no worker activity has been seen in the last 1h.
前往 Google Cloud 控制台中的配额页面,确保您的项目在作业的配置区域中具有足够的 PREEMPTIBLE_GPU_TYPE_GPUS 配额。
如果您的项目中有足够的配额,则表示灵活启动无法在 1 小时内预配资源。不妨考虑在其他可用区或使用其他加速器类型启动流水线。
将 GPU 与 Dataflow Prime 搭配使用
利用 Dataflow Prime,您可以为流水线的特定步骤请求加速器。如需搭配使用 GPU 和 Dataflow Prime,请勿使用 --dataflow-service_options=worker_accelerator 流水线选项。请改为使用 accelerator 资源提示请求 GPU。如需了解详情,请参阅使用资源提示。
排查 Dataflow 作业问题
如果您在使用 GPU 运行 Dataflow 作业时遇到问题,请参阅排查 Dataflow GPU 作业问题。
后续步骤
- 详细了解 Dataflow 上的 GPU 支持。
- 使用 NVIDIA L4 GPU 类型运行机器学习推理流水线。
- 学习使用 GPU 处理 Landsat 卫星图像。