
En esta página se explica cómo ejecutar una canalización de Apache Beam en Dataflow con GPUs. Las tareas que usan GPUs generan cargos según lo especificado en la página de precios de Dataflow.
Para obtener más información sobre cómo usar GPUs con Dataflow, consulta el artículo sobre la compatibilidad de Dataflow con GPUs. Para obtener más información sobre el flujo de trabajo de los desarrolladores para crear canalizaciones con GPUs, consulta el artículo Acerca de las GPUs con Dataflow.
Usar cuadernos de Apache Beam
Si ya tienes una canalización que quieres ejecutar con GPUs en Dataflow, puedes saltarte esta sección.
Los cuadernos de Apache Beam ofrecen una forma cómoda de crear prototipos y desarrollar tu flujo de procesamiento de forma iterativa con GPUs sin tener que configurar un entorno de desarrollo. Para empezar, lee la guía Desarrollar con cuadernos de Apache Beam, inicia una instancia de cuadernos de Apache Beam y sigue el cuaderno de ejemplo Usar GPUs con Apache Beam.
Asignar cuota de GPU
Los dispositivos de GPU están sujetos a la disponibilidad de cuota de tu proyecto de Google Cloud Platform. Solicita una cuota de GPU en la región que quieras.
Instalar controladores de GPU
Para instalar los controladores de NVIDIA en los trabajadores de Dataflow, añade install-nvidia-driver a la opción de servicio worker_accelerator.
Si especificas la opción install-nvidia-driver, Dataflow instala los controladores de NVIDIA en los trabajadores de Dataflow mediante la utilidad cos-extensions proporcionada por Container-Optimized OS. Al especificar install-nvidia-driver,
aceptas el contrato de licencia de NVIDIA.
Los archivos binarios y las bibliotecas proporcionados por el instalador del controlador de NVIDIA se montan en el contenedor que ejecuta el código de usuario de la canalización en /usr/local/nvidia/.
La versión del controlador de la GPU depende de la versión de Container-Optimized OS que utilice Dataflow. Para encontrar la versión del controlador de la GPU de una tarea de Dataflow concreta, busca GPU driver en los registros de pasos de Dataflow de la tarea.
Crear una imagen de contenedor personalizada
Para interactuar con las GPUs, es posible que necesites software adicional de NVIDIA, como bibliotecas aceleradas por GPU y el CUDA Toolkit. Proporciona estas bibliotecas en el contenedor Docker que ejecuta el código del usuario.
Para personalizar la imagen del contenedor, proporciona una imagen que cumpla el contrato de imagen del contenedor del SDK de Apache Beam y que tenga las bibliotecas de GPU necesarias.
Para proporcionar una imagen de contenedor personalizada, usa Dataflow Runner v2 y proporciona la imagen de contenedor mediante la opción de canalización sdk_container_image.
Si usas la versión 2.29.0 de Apache Beam o una anterior, utiliza la opción de canalización worker_harness_container_image. Para obtener más información, consulta Usar contenedores personalizados.
Para crear una imagen de contenedor personalizada, puede usar uno de estos dos métodos:
Usar una imagen configurada para usar la GPU
Puedes compilar una imagen Docker que cumpla el contrato de contenedor del SDK de Apache Beam a partir de una imagen base que ya esté preconfigurada para usar la GPU. Por ejemplo, las imágenes de Docker de TensorFlow y las imágenes de contenedor de NVIDIA están preconfiguradas para usar GPUs.
Un Dockerfile de ejemplo que se basa en la imagen Docker de TensorFlow con Python 3.6 tiene el siguiente aspecto:
ARG BASE=tensorflow/tensorflow:2.5.0-gpu
FROM $BASE
# Check that the chosen base image provides the expected version of Python interpreter.
ARG PY_VERSION=3.6
RUN [[ $PY_VERSION == `python -c 'import sys; print("%s.%s" % sys.version_info[0:2])'` ]] \
|| { echo "Could not find Python interpreter or Python version is different from ${PY_VERSION}"; exit 1; }
RUN pip install --upgrade pip \
&& pip install --no-cache-dir apache-beam[gcp]==2.29.0 \
# Verify that there are no conflicting dependencies.
&& pip check
# Copy the Apache Beam worker dependencies from the Beam Python 3.6 SDK image.
COPY --from=apache/beam_python3.6_sdk:2.29.0 /opt/apache/beam /opt/apache/beam
# Apache Beam worker expects pip at /usr/local/bin/pip by default.
# Some images have pip in a different location. If necessary, make a symlink.
# This line can be omitted in Beam 2.30.0 and later versions.
RUN [[ `which pip` == "/usr/local/bin/pip" ]] || ln -s `which pip` /usr/local/bin/pip
# Set the entrypoint to Apache Beam SDK worker launcher.
ENTRYPOINT [ "/opt/apache/beam/boot" ]
Si usas imágenes Docker de TensorFlow, utiliza TensorFlow 2.5.0 o una versión posterior. Las imágenes de Docker de versiones anteriores de TensorFlow instalan el paquete tensorflow-gpu en lugar del paquete tensorflow. Esta distinción no es importante después del lanzamiento de TensorFlow 2.1.0, pero varios paquetes posteriores, como tfx, requieren el paquete tensorflow.
Los contenedores de gran tamaño ralentizan el tiempo de inicio de los trabajadores. Este cambio en el rendimiento puede producirse cuando se usan contenedores como Deep Learning Containers.
Instalar una versión específica de Python
Si tienes requisitos estrictos para la versión de Python, puedes crear tu imagen a partir de una imagen base de NVIDIA que tenga las bibliotecas de GPU necesarias. A continuación, instala el intérprete de Python.
En el siguiente ejemplo se muestra cómo seleccionar una imagen de NVIDIA que no incluya el intérprete de Python del catálogo de imágenes de contenedor de CUDA. Ajusta el ejemplo para instalar la versión necesaria de Python 3 y pip. En el ejemplo se usa TensorFlow. Por lo tanto, al elegir una imagen, las versiones de CUDA y cuDNN de la imagen base cumplen los requisitos de la versión de TensorFlow.
Un Dockerfile de ejemplo tiene el siguiente aspecto:
# Select an NVIDIA base image with needed GPU stack from https://ngc.nvidia.com/catalog/containers/nvidia:cuda
FROM nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04
RUN \
# Add Deadsnakes repository that has a variety of Python packages for Ubuntu.
# See: https://launchpad.net/~deadsnakes/+archive/ubuntu/ppa
apt-key adv --keyserver keyserver.ubuntu.com --recv-keys F23C5A6CF475977595C89F51BA6932366A755776 \
&& echo "deb http://ppa.launchpad.net/deadsnakes/ppa/ubuntu focal main" >> /etc/apt/sources.list.d/custom.list \
&& echo "deb-src http://ppa.launchpad.net/deadsnakes/ppa/ubuntu focal main" >> /etc/apt/sources.list.d/custom.list \
&& apt-get update \
&& apt-get install -y curl \
python3.8 \
# With python3.8 package, distutils need to be installed separately.
python3-distutils \
&& rm -rf /var/lib/apt/lists/* \
&& update-alternatives --install /usr/bin/python python /usr/bin/python3.8 10 \
&& curl https://bootstrap.pypa.io/get-pip.py | python \
&& pip install --upgrade pip \
# Install Apache Beam and Python packages that will interact with GPUs.
&& pip install --no-cache-dir apache-beam[gcp]==2.29.0 tensorflow==2.4.0 \
# Verify that there are no conflicting dependencies.
&& pip check
# Copy the Apache Beam worker dependencies from the Beam Python 3.8 SDK image.
COPY --from=apache/beam_python3.8_sdk:2.29.0 /opt/apache/beam /opt/apache/beam
# Set the entrypoint to Apache Beam SDK worker launcher.
ENTRYPOINT [ "/opt/apache/beam/boot" ]
En algunas distribuciones del SO, puede ser difícil instalar versiones específicas de Python mediante el gestor de paquetes del SO. En este caso, instala el intérprete de Python con herramientas como Miniconda o pyenv.
Un Dockerfile de ejemplo tiene el siguiente aspecto:
FROM nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04
# The Python version of the Dockerfile must match the Python version you use
# to launch the Dataflow job.
ARG PYTHON_VERSION=3.8
# Update PATH so we find our new Conda and Python installations.
ENV PATH=/opt/python/bin:/opt/conda/bin:$PATH
RUN apt-get update \
&& apt-get install -y wget \
&& rm -rf /var/lib/apt/lists/* \
# The NVIDIA image doesn't come with Python pre-installed.
# We use Miniconda to install the Python version of our choice.
&& wget -q https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh \
&& bash Miniconda3-latest-Linux-x86_64.sh -b -p /opt/conda \
&& rm Miniconda3-latest-Linux-x86_64.sh \
# Create a new Python environment with needed version, and install pip.
&& conda create -y -p /opt/python python=$PYTHON_VERSION pip \
# Remove unused Conda packages, install necessary Python packages via pip
# to avoid mixing packages from pip and Conda.
&& conda clean -y --all --force-pkgs-dirs \
&& pip install --upgrade pip \
# Install Apache Beam and Python packages that will interact with GPUs.
&& pip install --no-cache-dir apache-beam[gcp]==2.29.0 tensorflow==2.4.0 \
# Verify that there are no conflicting dependencies.
&& pip check \
# Apache Beam worker expects pip at /usr/local/bin/pip by default.
# You can omit this line when using Beam 2.30.0 and later versions.
&& ln -s $(which pip) /usr/local/bin/pip
# Copy the Apache Beam worker dependencies from the Apache Beam SDK for Python 3.8 image.
COPY --from=apache/beam_python3.8_sdk:2.29.0 /opt/apache/beam /opt/apache/beam
# Set the entrypoint to Apache Beam SDK worker launcher.
ENTRYPOINT [ "/opt/apache/beam/boot" ]
Usar una imagen de contenedor de Apache Beam
Puedes configurar una imagen de contenedor para usar la GPU sin usar imágenes preconfiguradas. Este método solo se recomienda cuando las imágenes preconfiguradas no te sirvan. Para configurar tu propia imagen de contenedor, debes seleccionar bibliotecas compatibles y configurar su entorno de ejecución.
Un Dockerfile de ejemplo tiene el siguiente aspecto:
FROM apache/beam_python3.7_sdk:2.24.0
ENV INSTALLER_DIR="/tmp/installer_dir"
# The base image has TensorFlow 2.2.0, which requires CUDA 10.1 and cuDNN 7.6.
# You can download cuDNN from NVIDIA website
# https://developer.nvidia.com/cudnn
COPY cudnn-10.1-linux-x64-v7.6.0.64.tgz $INSTALLER_DIR/cudnn.tgz
RUN \
# Download CUDA toolkit.
wget -q -O $INSTALLER_DIR/cuda.run https://developer.download.nvidia.com/compute/cuda/10.1/Prod/local_installers/cuda_10.1.243_418.87.00_linux.run && \
# Install CUDA toolkit. Print logs upon failure.
sh $INSTALLER_DIR/cuda.run --toolkit --silent || (egrep '^\[ERROR\]' /var/log/cuda-installer.log && exit 1) && \
# Install cuDNN.
mkdir $INSTALLER_DIR/cudnn && \
tar xvfz $INSTALLER_DIR/cudnn.tgz -C $INSTALLER_DIR/cudnn && \
cp $INSTALLER_DIR/cudnn/cuda/include/cudnn*.h /usr/local/cuda/include && \
cp $INSTALLER_DIR/cudnn/cuda/lib64/libcudnn* /usr/local/cuda/lib64 && \
chmod a+r /usr/local/cuda/include/cudnn*.h /usr/local/cuda/lib64/libcudnn* && \
rm -rf $INSTALLER_DIR
# A volume with GPU drivers will be mounted at runtime at /usr/local/nvidia.
ENV LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/nvidia/lib64:/usr/local/cuda/lib64
Las bibliotecas de controladores de /usr/local/nvidia/lib64 deben poder detectarse en el contenedor como bibliotecas compartidas. Para que se puedan detectar las bibliotecas del controlador, configura la variable de entorno LD_LIBRARY_PATH.
Si usas TensorFlow, debes elegir una combinación compatible de versiones de CUDA Toolkit y cuDNN. Para obtener más información, consulta los requisitos de software y las configuraciones de compilación probadas.
Seleccionar el tipo y el número de GPUs para los trabajadores de Dataflow
Para configurar el tipo y el número de GPUs que se van a adjuntar a los trabajadores de Dataflow, usa la opción de servicio worker_accelerator.
Selecciona el tipo y el número de GPUs en función de tu caso práctico y de cómo tienes previsto usar las GPUs en tu canalización.
Para ver una lista de los tipos de GPU compatibles con Dataflow, consulta Compatibilidad de Dataflow con GPUs.
Ejecutar un trabajo con GPUs
Estas son algunas de las consideraciones que debes tener en cuenta al ejecutar una tarea de Dataflow con GPUs:
Como los contenedores de GPU suelen ser grandes, para evitar quedarte sin espacio en disco, haz lo siguiente:
- Aumenta el tamaño del disco de arranque predeterminado a 50 gigabytes o más.
Ten en cuenta cuántos procesos usan simultáneamente la misma GPU en una VM de trabajador. A continuación, decide si quieres limitar la GPU a un solo proceso o permitir que varios procesos la usen.
- Si un proceso del SDK de Apache Beam puede usar la mayor parte de la memoria de GPU disponible (por ejemplo, cargando un modelo grande en una GPU), puede configurar los trabajadores para que usen un solo proceso definiendo la opción de la canalización
--experiments=no_use_multiple_sdk_containers. También puedes usar trabajadores con una vCPU mediante un tipo de máquina personalizada, comon1-custom-1-NUMBER_OF_MBon1-custom-1-NUMBER_OF_MB-ext, para ampliar la memoria. Para obtener más información, consulta Usar un tipo de máquina con más memoria por vCPU. - Si varios procesos comparten la GPU, habilita el procesamiento simultáneo en una GPU compartida mediante el servicio de multiprocesamiento (MPS) de NVIDIA.
Para obtener información general, consulta GPUs y paralelismo de los trabajadores.
- Si un proceso del SDK de Apache Beam puede usar la mayor parte de la memoria de GPU disponible (por ejemplo, cargando un modelo grande en una GPU), puede configurar los trabajadores para que usen un solo proceso definiendo la opción de la canalización
Para ejecutar un trabajo de Dataflow con GPUs, usa el siguiente comando.
Para usar ajuste correcto, en lugar de usar la opción de servicio worker_accelerator, usa la sugerencia de recurso accelerator.
Python
python PIPELINE \
--runner "DataflowRunner" \
--project "PROJECT" \
--temp_location "gs://BUCKET/tmp" \
--region "REGION" \
--worker_harness_container_image "IMAGE" \
--disk_size_gb "DISK_SIZE_GB" \
--dataflow_service_options "worker_accelerator=type:GPU_TYPE;count:GPU_COUNT;install-nvidia-driver" \
--experiments "use_runner_v2"
Haz los cambios siguientes:
- PIPELINE: el archivo de código fuente de tu proceso
- PROJECT: el nombre del proyecto Google Cloud
- BUCKET: el segmento de Cloud Storage
- REGION: una región de Dataflow, por ejemplo,
us-central1. Selecciona una `REGION` que tenga zonas que admitanGPU_TYPE. Dataflow asigna automáticamente trabajadores a una zona con GPUs de esta región. - IMAGE: la ruta de Artifact Registry de tu imagen de Docker
- DISK_SIZE_GB: tamaño del disco de arranque de cada VM de trabajador (por ejemplo,
50) - GPU_TYPE: un tipo de GPU disponible, por ejemplo,
nvidia-tesla-t4. - GPU_COUNT: número de GPUs que se van a asociar a cada VM de trabajador. Por ejemplo,
1.
Verificar una tarea de Dataflow
Para confirmar que el trabajo usa máquinas virtuales de trabajador con GPUs, sigue estos pasos:
- Verifica que los trabajadores de Dataflow de la tarea se hayan iniciado.
- Mientras se ejecuta un trabajo, busca una VM de trabajador asociada al trabajo.
- En la petición Buscar productos y recursos, pega el ID de trabajo.
- Selecciona la instancia de VM de Compute Engine asociada al trabajo.
También puedes consultar la lista de todas las instancias en ejecución en la consola de Compute Engine.
En la consola de Google Cloud , ve a la página Instancias de VM.
Haz clic en Detalles de la instancia de VM.
Comprueba que la página de detalles tenga una sección GPUs y que tus GPUs estén conectadas.
Si tu trabajo no se ha iniciado con GPUs, comprueba que la opción de servicio worker_accelerator esté configurada correctamente y que se vea en la interfaz de monitorización de Dataflow en dataflow_service_options. El orden de los tokens en los metadatos del acelerador es importante.
Por ejemplo, una opción de canalización dataflow_service_options en la interfaz de monitorización de Dataflow podría tener el siguiente aspecto:
['worker_accelerator=type:nvidia-tesla-t4;count:1;install-nvidia-driver', ...]
Ver el uso de la GPU
Para ver la utilización de la GPU en las VMs de trabajador, sigue estos pasos:
En la Google Cloud consola, ve a Monitoring o haz clic en el siguiente botón:
En el panel de navegación de Monitoring, haz clic en Explorador de métricas.
En Resource Type (Tipo de recurso), especifica
Dataflow Job. En la métrica, especifiqueGPU utilizationoGPU memory utilization, según la métrica que quiera monitorizar.
Para obtener más información, consulta Explorador de métricas.
Habilitar el servicio multiproceso de NVIDIA
En las canalizaciones de Python que se ejecutan en trabajadores con más de una vCPU, puedes mejorar la simultaneidad de las operaciones de GPU habilitando el servicio multiproceso (MPS) de NVIDIA. Para obtener más información y los pasos para usar MPS, consulta Mejorar el rendimiento en una GPU compartida usando NVIDIA MPS.
Opcional: Configurar un modelo de aprovisionamiento
Puedes mejorar la capacidad de acceder a los recursos de GPU configurando un modelo de aprovisionamiento para tu canalización.
Dataflow admite los siguientes modelos de aprovisionamiento: estándar y flex-start.
Aprovisionamiento estándar
El aprovisionamiento estándar es el modelo predeterminado de todos los trabajos de Dataflow con GPUs. Las instancias que usan recursos de acelerador se crean inmediatamente en función de la disponibilidad de recursos.
No tienes que configurar nada para usar el modelo de aprovisionamiento estándar.
Si las GPUs no están disponibles inmediatamente en la zona o región en la que ejecutas tu trabajo de Dataflow, es posible que no se inicie. Para obtener más información, consulta La tarea falla inmediatamente al iniciarse.
Aprovisionamiento de flex-start
Con el modelo de aprovisionamiento de inicio flexible, las instancias y los recursos de acelerador se programan para el aprovisionamiento y se completan en función de la disponibilidad de los recursos. Puedes usar el modelo de aprovisionamiento flex-start para aumentar las probabilidades de obtener GPUs.
Para usar el modelo de aprovisionamiento flex-start, añade provisioning_model:FLEX_START a la opción de servicio worker_accelerator. Por ejemplo:
worker_accelerator=type:nvidia-tesla-t4;count:1;install-nvidia-driver:5xx;provisioning_model:FLEX_START
Los trabajos con flex-start habilitado se envían para su ejecución, pero solo se ejecutan cuando los recursos necesarios están disponibles. Para comprobar que se ha habilitado el aprovisionamiento de inicio flexible, busca la siguiente entrada de registro en el registro job-message:
FLEX_START está habilitado para el trabajo JOB_ID
Para determinar si el trabajo ha empezado a ejecutarse, consulta el gráfico de autoescalado en la página de métricas del trabajo:
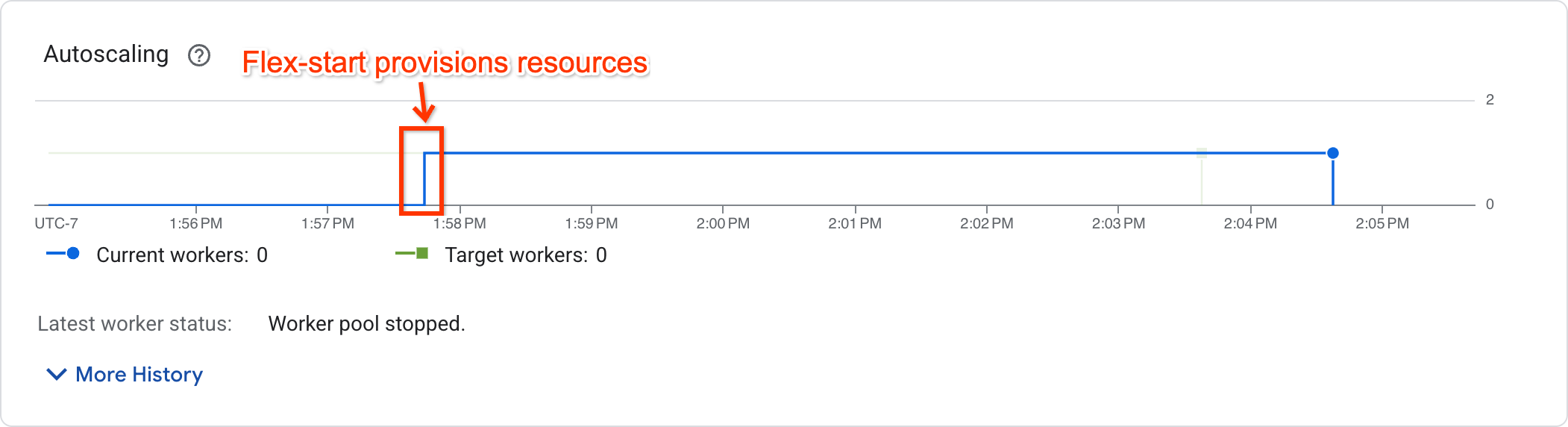
Los trabajos que hayan empezado a ejecutarse mostrarán un número de trabajadores distinto de cero, mientras que los que estén esperando recursos tendrán un número de trabajadores igual a cero.
Compatibilidad y limitaciones
- El inicio flexible solo se admite en las canalizaciones por lotes. No se admiten flujos de procesamiento en streaming.
- Las VMs de trabajador aprovisionadas mediante el modelo de aprovisionamiento de inicio flexible tienen un tiempo de ejecución máximo de siete días. Una vez transcurrido este periodo, las VMs de trabajador con aceleradores se interrumpen. Dataflow intentará volver a aprovisionar los recursos. Si no se pueden volver a aprovisionar los recursos, se producirá un error en la canalización.
- Flex-start intentará aprovisionar recursos durante un máximo de 1 hora después de enviar la tarea. Si no puede aprovisionar recursos al cabo de 1 hora, el trabajo fallará.
- Flex-start consume la cuota de instancias no garantizadas. Si tu proyecto no tiene cuota interrumpible, se consumirá la cuota estándar. Para obtener más información, consulta Cuotas de recursos preemptibles.
- Si no se proporciona una configuración de zona de trabajador, Dataflow elegirá una única zona para crear todos los recursos en función de la compatibilidad con el hardware, la disponibilidad actual de recursos y cuotas, y las reservas coincidentes. Esta zona puede ser diferente de la zona en la que se encuentran los recursos de servicio de la tarea.
- No se admite el autoescalado horizontal. Para usar más de un trabajador, define la opción de flujo de procesamiento
--num_workers. - No se admiten TPUs.
- No se admite Ajuste perfecto.
Solucionar problemas de flex-start
Si tu trabajo falla 1 hora después de enviarlo y aparece el siguiente error:
The Dataflow job appears to be stuck because no worker activity has been seen in the last 1h.
Ve a la página Cuotas de la Google Cloud consola para comprobar que tu proyecto tiene suficiente cuota de PREEMPTIBLE_GPU_TYPE_GPUS en la región configurada para tu trabajo.
Si tu proyecto tenía suficiente cuota, significa que el inicio flexible no ha podido aprovisionar recursos en 1 hora. Prueba a iniciar la canalización en otra zona o con otro tipo de acelerador.
Usar GPUs con Dataflow Prime
Dataflow Prime te permite solicitar aceleradores para un paso específico de tu flujo de procesamiento. Para usar GPUs con Dataflow Prime, no utilices la opción --dataflow-service_options=worker_accelerator
de la canalización. En su lugar, solicita las GPUs con la sugerencia de recurso accelerator.
Para obtener más información, consulta Usar sugerencias de recursos.
Solucionar problemas de una tarea de Dataflow
Si tienes problemas para ejecutar tu tarea de Dataflow con GPUs, consulta el artículo Solucionar problemas de una tarea de Dataflow con GPUs.
Siguientes pasos
- Más información sobre la compatibilidad con GPUs en Dataflow
- Ejecuta tu canalización de inferencia de aprendizaje automático con el tipo de GPU NVIDIA L4.
- Sigue los pasos de Procesar imágenes de satélite Landsat con GPUs.