
Halaman ini menjelaskan cara menjalankan pipeline Apache Beam di Dataflow dengan GPU. Tugas yang menggunakan GPU dikenai biaya seperti yang ditentukan di halaman harga Dataflow.
Untuk mengetahui informasi selengkapnya tentang penggunaan GPU dengan Dataflow, lihat Dukungan Dataflow untuk GPU. Untuk mengetahui informasi selengkapnya tentang alur kerja developer untuk membangun pipeline menggunakan GPU, lihat Tentang GPU dengan Dataflow.
Menggunakan notebook Apache Beam
Jika sudah memiliki pipeline yang ingin dijalankan dengan GPU di Dataflow, Anda dapat melewati bagian ini.
Notebook Apache Beam menawarkan cara mudah untuk membuat prototipe dan mengembangkan pipeline Anda secara iteratif dengan GPU tanpa menyiapkan lingkungan pengembangan. Untuk memulai, baca panduan Mengembangkan dengan notebook Apache Beam, luncurkan instance notebook Apache Beam, dan ikuti contoh notebook Menggunakan GPU dengan Apache Beam.
Menyediakan kuota GPU
Perangkat GPU tunduk pada ketersediaan kuota project Google Cloud Anda. Minta kuota GPU di region pilihan Anda.
Menginstal driver GPU
Untuk menginstal driver NVIDIA di pekerja Dataflow, tambahkan install-nvidia-driver ke
opsi layanan worker_accelerator.
Saat Anda menentukan opsi install-nvidia-driver,
Dataflow akan menginstal driver NVIDIA ke worker Dataflow menggunakan
utilitas cos-extensions
yang disediakan oleh Container-Optimized OS. Dengan menentukan install-nvidia-driver,
Anda setuju untuk menyetujui perjanjian lisensi NVIDIA.
Dataflow mendukung penambahan versi ke opsi install-nvidia-driver
sebagai install-nvidia-driver:VERSION. Versi berikut didukung:
- default
- terbaru
Jika tidak ada versi yang diberikan, maka sama dengan
install-nvidia-driver:default. Jika versi yang tidak dikenal diberikan, penginstalan driver GPU akan gagal.
Biner dan library yang disediakan oleh penginstal driver NVIDIA di-mount ke dalam
penampung yang menjalankan kode pengguna pipeline di /usr/local/nvidia/.
Versi driver GPU
untuk versi default dan latest bergantung pada
versi Container-Optimized OS yang digunakan oleh Dataflow. Untuk menemukan versi driver GPU untuk tugas Dataflow tertentu, di Log Langkah Dataflow tugas Anda, telusuri GPU driver.
Saat memeriksa log Dataflow setelah penginstalan driver, Anda mungkin melihat baris seperti:
| NVIDIA-SMI 535.261.03 Driver Version: 535.261.03 CUDA Version: 12.2 |
"Versi CUDA" dalam hal ini adalah versi CUDA driver, yang berbeda dengan versi CUDA runtime yang diinstal di image container kustom atau yang ada. Jika versi driver ini lebih besar dari atau sama dengan versi runtime, tidak ada langkah lain yang perlu dilakukan. Jika versi lebih lama, Anda harus mengikuti dokumen kompatibilitas NVIDIA CUDA saat membuat image container.
Membangun image container kustom
Untuk berinteraksi dengan GPU, Anda mungkin memerlukan software NVIDIA tambahan, seperti library yang dipercepat GPU dan CUDA Toolkit. Sediakan library ini di container Docker yang menjalankan kode pengguna.
Untuk menyesuaikan image container, berikan image yang memenuhi kontrak image container Apache Beam SDK dan memiliki library GPU yang diperlukan.
Untuk menyediakan image container kustom, gunakan
Dataflow Runner v2 dan berikan
image container menggunakan opsi pipeline sdk_container_image.
Jika Anda menggunakan Apache Beam versi 2.29.0 atau yang lebih lama, gunakan opsi pipeline worker_harness_container_image. Untuk mengetahui informasi selengkapnya, lihat
Menggunakan container kustom.
Untuk membuat image container kustom, gunakan salah satu dari dua pendekatan berikut:
- Menggunakan image yang sudah ada yang dikonfigurasi untuk penggunaan GPU
- Menggunakan image container Apache Beam
Menggunakan image yang ada yang dikonfigurasi untuk penggunaan GPU
Anda dapat membuat image Docker yang memenuhi kontrak container Apache Beam SDK dari image dasar yang sudah ada dan telah dikonfigurasi sebelumnya untuk penggunaan GPU. Misalnya, image Docker TensorFlow, dan image container NVIDIA telah dikonfigurasi sebelumnya untuk penggunaan GPU.
Contoh Dockerfile yang dibangun di image Docker TensorFlow dengan Python 3.6 terlihat seperti contoh berikut:
ARG BASE=tensorflow/tensorflow:2.5.0-gpu
FROM $BASE
# Check that the chosen base image provides the expected version of Python interpreter.
ARG PY_VERSION=3.6
RUN [[ $PY_VERSION == `python -c 'import sys; print("%s.%s" % sys.version_info[0:2])'` ]] \
|| { echo "Could not find Python interpreter or Python version is different from ${PY_VERSION}"; exit 1; }
RUN pip install --upgrade pip \
&& pip install --no-cache-dir apache-beam[gcp]==2.29.0 \
# Verify that there are no conflicting dependencies.
&& pip check
# Copy the Apache Beam worker dependencies from the Beam Python 3.6 SDK image.
COPY --from=apache/beam_python3.6_sdk:2.29.0 /opt/apache/beam /opt/apache/beam
# Apache Beam worker expects pip at /usr/local/bin/pip by default.
# Some images have pip in a different location. If necessary, make a symlink.
# This line can be omitted in Beam 2.30.0 and later versions.
RUN [[ `which pip` == "/usr/local/bin/pip" ]] || ln -s `which pip` /usr/local/bin/pip
# Set the entrypoint to Apache Beam SDK worker launcher.
ENTRYPOINT [ "/opt/apache/beam/boot" ]
Saat Anda menggunakan
image Docker TensorFlow, gunakan
TensorFlow 2.5.0 atau yang lebih baru. Image Docker TensorFlow versi sebelumnya menginstal paket tensorflow-gpu, bukan paket tensorflow. Perbedaan ini tidak penting setelah rilis TensorFlow 2.1.0, tetapi beberapa paket hilir, seperti tfx, memerlukan paket tensorflow.
Ukuran penampung yang besar memperlambat waktu startup pekerja. Perubahan performa ini dapat terjadi saat Anda menggunakan container seperti Deep Learning Containers.
Menginstal versi Python tertentu
Jika memiliki persyaratan ketat untuk versi Python, Anda dapat mem-build image dari image dasar NVIDIA yang memiliki library GPU yang diperlukan. Kemudian, instal interpreter Python.
Contoh berikut menunjukkan cara memilih image NVIDIA yang tidak menyertakan interpreter Python dari katalog image container CUDA. Sesuaikan contoh untuk menginstal versi Python 3 dan pip yang diperlukan. Contoh ini menggunakan TensorFlow. Oleh karena itu, saat memilih image, versi CUDA dan cuDNN di image dasar memenuhi persyaratan untuk versi TensorFlow.
Contoh Dockerfile terlihat seperti berikut:
# Select an NVIDIA base image with needed GPU stack from https://ngc.nvidia.com/catalog/containers/nvidia:cuda
FROM nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04
RUN \
# Add Deadsnakes repository that has a variety of Python packages for Ubuntu.
# See: https://launchpad.net/~deadsnakes/+archive/ubuntu/ppa
apt-key adv --keyserver keyserver.ubuntu.com --recv-keys F23C5A6CF475977595C89F51BA6932366A755776 \
&& echo "deb http://ppa.launchpad.net/deadsnakes/ppa/ubuntu focal main" >> /etc/apt/sources.list.d/custom.list \
&& echo "deb-src http://ppa.launchpad.net/deadsnakes/ppa/ubuntu focal main" >> /etc/apt/sources.list.d/custom.list \
&& apt-get update \
&& apt-get install -y curl \
python3.8 \
# With python3.8 package, distutils need to be installed separately.
python3-distutils \
&& rm -rf /var/lib/apt/lists/* \
&& update-alternatives --install /usr/bin/python python /usr/bin/python3.8 10 \
&& curl https://bootstrap.pypa.io/get-pip.py | python \
&& pip install --upgrade pip \
# Install Apache Beam and Python packages that will interact with GPUs.
&& pip install --no-cache-dir apache-beam[gcp]==2.29.0 tensorflow==2.4.0 \
# Verify that there are no conflicting dependencies.
&& pip check
# Copy the Apache Beam worker dependencies from the Beam Python 3.8 SDK image.
COPY --from=apache/beam_python3.8_sdk:2.29.0 /opt/apache/beam /opt/apache/beam
# Set the entrypoint to Apache Beam SDK worker launcher.
ENTRYPOINT [ "/opt/apache/beam/boot" ]
Pada beberapa distribusi OS, mungkin sulit untuk menginstal versi Python tertentu menggunakan pengelola paket OS. Dalam kasus ini, instal interpreter Python dengan alat seperti Miniconda atau pyenv.
Contoh Dockerfile terlihat seperti berikut:
FROM nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04
# The Python version of the Dockerfile must match the Python version you use
# to launch the Dataflow job.
ARG PYTHON_VERSION=3.8
# Update PATH so we find our new Conda and Python installations.
ENV PATH=/opt/python/bin:/opt/conda/bin:$PATH
RUN apt-get update \
&& apt-get install -y wget \
&& rm -rf /var/lib/apt/lists/* \
# The NVIDIA image doesn't come with Python pre-installed.
# We use Miniconda to install the Python version of our choice.
&& wget -q https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh \
&& bash Miniconda3-latest-Linux-x86_64.sh -b -p /opt/conda \
&& rm Miniconda3-latest-Linux-x86_64.sh \
# Create a new Python environment with needed version, and install pip.
&& conda create -y -p /opt/python python=$PYTHON_VERSION pip \
# Remove unused Conda packages, install necessary Python packages via pip
# to avoid mixing packages from pip and Conda.
&& conda clean -y --all --force-pkgs-dirs \
&& pip install --upgrade pip \
# Install Apache Beam and Python packages that will interact with GPUs.
&& pip install --no-cache-dir apache-beam[gcp]==2.29.0 tensorflow==2.4.0 \
# Verify that there are no conflicting dependencies.
&& pip check \
# Apache Beam worker expects pip at /usr/local/bin/pip by default.
# You can omit this line when using Beam 2.30.0 and later versions.
&& ln -s $(which pip) /usr/local/bin/pip
# Copy the Apache Beam worker dependencies from the Apache Beam SDK for Python 3.8 image.
COPY --from=apache/beam_python3.8_sdk:2.29.0 /opt/apache/beam /opt/apache/beam
# Set the entrypoint to Apache Beam SDK worker launcher.
ENTRYPOINT [ "/opt/apache/beam/boot" ]
Menggunakan image container Apache Beam
Anda dapat mengonfigurasi image container untuk penggunaan GPU tanpa menggunakan image yang telah dikonfigurasi sebelumnya. Pendekatan ini hanya direkomendasikan jika image yang telah dikonfigurasi sebelumnya tidak berfungsi untuk Anda. Untuk menyiapkan image container Anda sendiri, Anda perlu memilih pustaka yang kompatibel dan mengonfigurasi lingkungan eksekusinya.
Contoh Dockerfile terlihat seperti berikut:
FROM apache/beam_python3.7_sdk:2.24.0
ENV INSTALLER_DIR="/tmp/installer_dir"
# The base image has TensorFlow 2.2.0, which requires CUDA 10.1 and cuDNN 7.6.
# You can download cuDNN from NVIDIA website
# https://developer.nvidia.com/cudnn
COPY cudnn-10.1-linux-x64-v7.6.0.64.tgz $INSTALLER_DIR/cudnn.tgz
RUN \
# Download CUDA toolkit.
wget -q -O $INSTALLER_DIR/cuda.run https://developer.download.nvidia.com/compute/cuda/10.1/Prod/local_installers/cuda_10.1.243_418.87.00_linux.run && \
# Install CUDA toolkit. Print logs upon failure.
sh $INSTALLER_DIR/cuda.run --toolkit --silent || (egrep '^\[ERROR\]' /var/log/cuda-installer.log && exit 1) && \
# Install cuDNN.
mkdir $INSTALLER_DIR/cudnn && \
tar xvfz $INSTALLER_DIR/cudnn.tgz -C $INSTALLER_DIR/cudnn && \
cp $INSTALLER_DIR/cudnn/cuda/include/cudnn*.h /usr/local/cuda/include && \
cp $INSTALLER_DIR/cudnn/cuda/lib64/libcudnn* /usr/local/cuda/lib64 && \
chmod a+r /usr/local/cuda/include/cudnn*.h /usr/local/cuda/lib64/libcudnn* && \
rm -rf $INSTALLER_DIR
# A volume with GPU drivers will be mounted at runtime at /usr/local/nvidia.
ENV LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/nvidia/lib64:/usr/local/cuda/lib64
Library driver di /usr/local/nvidia/lib64 harus dapat ditemukan di
container sebagai library bersama. Agar library driver dapat ditemukan,
konfigurasi variabel lingkungan LD_LIBRARY_PATH.
Jika menggunakan TensorFlow, Anda harus memilih kombinasi versi cuDNN dan CUDA Toolkit yang kompatibel. Untuk mengetahui informasi selengkapnya, baca Persyaratan software dan Konfigurasi build yang diuji.
Pilih jenis dan jumlah GPU untuk pekerja Dataflow
Untuk mengonfigurasi jenis dan jumlah GPU yang akan dilampirkan ke worker Dataflow, gunakan
opsi layanan worker_accelerator.
Pilih jenis dan jumlah GPU berdasarkan kasus penggunaan Anda dan cara Anda berencana menggunakan GPU dalam pipeline.
Untuk mengetahui daftar jenis GPU yang didukung dengan Dataflow, lihat Dukungan Dataflow untuk GPU.
Menjalankan tugas dengan GPU
Pertimbangan untuk menjalankan tugas Dataflow dengan GPU mencakup hal-hal berikut:
Karena container GPU biasanya berukuran besar, untuk menghindari kehabisan ruang disk, lakukan hal berikut:
- Tingkatkan ukuran boot disk default menjadi 50 gigabyte atau lebih.
Pertimbangkan jumlah proses yang secara bersamaan menggunakan GPU yang sama di VM pekerja. Kemudian, putuskan apakah Anda ingin membatasi GPU ke satu proses atau mengizinkan beberapa proses menggunakan GPU.
- Jika satu proses Apache Beam SDK dapat menggunakan sebagian besar memori GPU yang tersedia, misalnya dengan memuat model besar ke GPU, Anda mungkin ingin mengonfigurasi pekerja untuk menggunakan satu proses dengan menyetel opsi pipeline
--experiments=no_use_multiple_sdk_containers. Atau, gunakan pekerja dengan satu vCPU menggunakan jenis mesin kustom, sepertin1-custom-1-NUMBER_OF_MBataun1-custom-1-NUMBER_OF_MB-ext, untuk memori yang diperluas. Untuk mengetahui informasi selengkapnya, lihat Menggunakan jenis mesin dengan memori per vCPU yang lebih besar. - Jika GPU digunakan bersama oleh beberapa proses, aktifkan pemrosesan serentak pada GPU bersama menggunakan NVIDIA Multi-Processing Service (MPS).
Untuk mengetahui informasi latar belakang, lihat GPU dan paralelisme pekerja.
- Jika satu proses Apache Beam SDK dapat menggunakan sebagian besar memori GPU yang tersedia, misalnya dengan memuat model besar ke GPU, Anda mungkin ingin mengonfigurasi pekerja untuk menggunakan satu proses dengan menyetel opsi pipeline
Untuk menjalankan tugas Dataflow dengan GPU, gunakan perintah berikut.
Untuk menggunakan pas kanan, alih-alih menggunakan
opsi layanan worker_accelerator,
gunakan
hint resource accelerator.
Python
python PIPELINE \
--runner "DataflowRunner" \
--project "PROJECT" \
--temp_location "gs://BUCKET/tmp" \
--region "REGION" \
--worker_harness_container_image "IMAGE" \
--disk_size_gb "DISK_SIZE_GB" \
--dataflow_service_options "worker_accelerator=type:GPU_TYPE;count:GPU_COUNT;install-nvidia-driver" \
--experiments "use_runner_v2"
Ganti kode berikut:
- PIPELINE: file kode sumber pipeline Anda
- PROJECT: Google Cloud nama project
- BUCKET: bucket Cloud Storage
- REGION: region Dataflow, misalnya,
us-central1. Pilih `REGION` yang memiliki zona yang mendukungGPU_TYPE. Dataflow otomatis menetapkan pekerja ke zona dengan GPU di region ini. - IMAGE: jalur Artifact Registry untuk image Docker Anda
- DISK_SIZE_GB: Ukuran boot disk untuk setiap VM pekerja, misalnya,
50 - GPU_TYPE: jenis GPU yang tersedia, misalnya,
nvidia-tesla-t4. - GPU_COUNT: jumlah GPU yang akan dilampirkan ke setiap VM pekerja, misalnya,
1
Memverifikasi tugas Dataflow Anda
Untuk mengonfirmasi bahwa tugas menggunakan VM pekerja dengan GPU, ikuti langkah-langkah berikut:
- Verifikasi bahwa pekerja Dataflow untuk tugas telah dimulai.
- Saat tugas sedang berjalan, temukan VM pekerja yang terkait dengan tugas.
- Di perintah Search Products and Resources, tempelkan Job ID.
- Pilih instance VM Compute Engine yang terkait dengan tugas.
Anda juga dapat menemukan daftar semua instance yang sedang berjalan di konsol Compute Engine.
Di konsol Google Cloud , buka halaman VM instances.
Klik VM instance details.
Verifikasi bahwa halaman detail memiliki bagian GPU dan GPU Anda terpasang.
Jika tugas Anda tidak diluncurkan dengan GPU, periksa apakah opsi layanan worker_accelerator dikonfigurasi dengan benar dan terlihat di antarmuka pemantauan Dataflow di dataflow_service_options. Urutan token dalam metadata akselerator penting.
Misalnya, opsi pipeline dataflow_service_options di
antarmuka pemantauan Dataflow mungkin terlihat seperti berikut:
['worker_accelerator=type:nvidia-tesla-t4;count:1;install-nvidia-driver', ...]
Melihat pemakaian GPU
Untuk melihat pemanfaatan GPU di VM pekerja, ikuti langkah-langkah berikut:
Di konsol Google Cloud , buka Monitoring atau gunakan tombol berikut:
Di panel navigasi Monitoring, klik Metrics Explorer.
Untuk Resource Type, tentukan
Dataflow Job. Untuk metrik, tentukanGPU utilizationatauGPU memory utilization, bergantung pada metrik yang ingin Anda pantau.
Untuk mengetahui informasi selengkapnya, lihat Metrics Explorer.
Mengaktifkan Layanan Multi-Processing NVIDIA
Pada pipeline Python yang berjalan di pekerja dengan lebih dari satu vCPU, Anda dapat meningkatkan konkurensi untuk operasi GPU dengan mengaktifkan NVIDIA Multi-Process Service (MPS). Untuk mengetahui informasi dan langkah-langkah selengkapnya tentang cara menggunakan MPS, lihat Meningkatkan performa di GPU bersama dengan menggunakan NVIDIA MPS.
Opsional: Mengonfigurasi model penyediaan
Anda dapat meningkatkan kemampuan untuk mendapatkan akses ke resource GPU dengan mengonfigurasi model penyediaan untuk pipeline Anda.
Model penyediaan berikut didukung oleh Dataflow: standar dan mulai fleksibel.
Penyediaan standar
Penyediaan standar adalah model penyediaan default untuk semua tugas Dataflow dengan GPU. Instance yang menggunakan resource akselerator akan segera dibuat berdasarkan ketersediaan resource.
Anda tidak perlu mengonfigurasi apa pun untuk menggunakan model penyediaan standar.
Jika GPU tidak langsung tersedia di zona atau region tempat Anda menjalankan tugas Dataflow, tugas Anda mungkin gagal dimulai. Untuk mengetahui informasi selengkapnya, lihat Tugas langsung gagal saat startup.
Penyediaan mulai fleksibel
Dengan model penyediaan mulai fleksibel, instance dan resource akselerator dijadwalkan untuk penyediaan dan dipenuhi berdasarkan ketersediaan resource. Anda dapat menggunakan model penyediaan mulai fleksibel untuk meningkatkan peluang mendapatkan GPU.
Untuk menggunakan model penyediaan mulai fleksibel, tambahkan provisioning_model:FLEX_START ke
opsi layanan worker_accelerator. Contoh:
worker_accelerator=type:nvidia-tesla-t4;count:1;install-nvidia-driver:latest;provisioning_model:FLEX_START
Tugas dengan flex-start yang diaktifkan dikirimkan untuk dieksekusi, tetapi hanya dieksekusi saat resource yang diperlukan tersedia. Untuk memverifikasi bahwa penyediaan mulai fleksibel telah diaktifkan, lihat entri log berikut di log job-message:
FLEX_START diaktifkan untuk tugas JOB_ID
Untuk menentukan apakah tugas telah mulai dieksekusi, lihat grafik penskalaan otomatis di halaman metrik tugas:
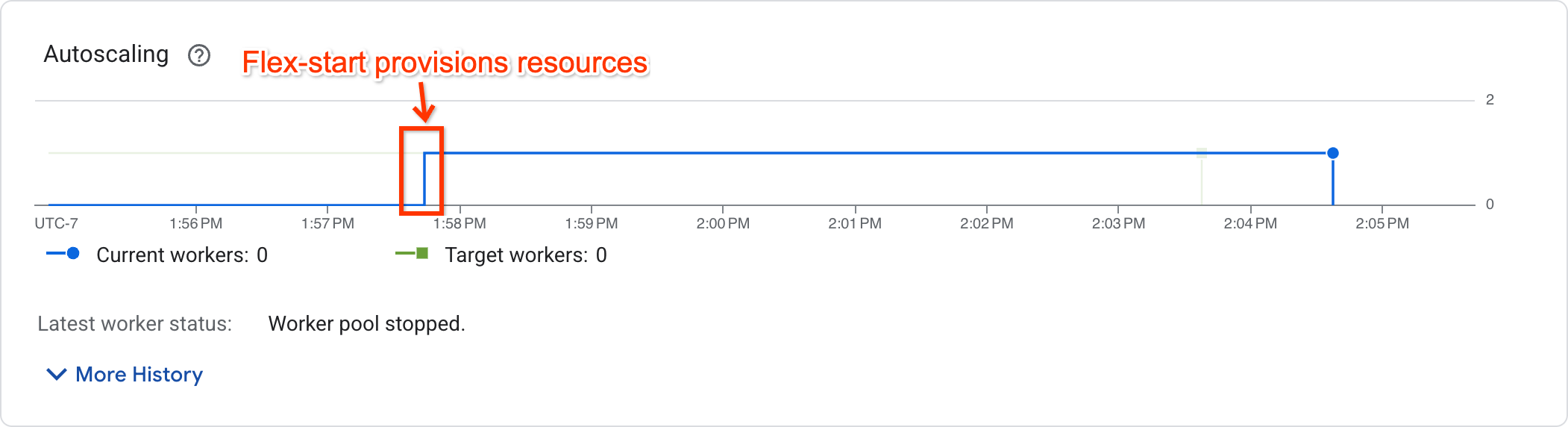
Tugas yang telah mulai dieksekusi akan menampilkan jumlah pekerja bukan nol, sedangkan tugas yang menunggu resource akan memiliki jumlah pekerja nol.
Dukungan dan batasan
- Mulai fleksibel hanya didukung di pipeline Batch. Pipeline streaming tidak didukung.
- VM pekerja yang disediakan menggunakan model penyediaan flex-start memiliki runtime maksimum tujuh hari. Setelah periode ini, VM Pekerja dengan akselerator akan di-preempt. Dataflow akan mencoba menyediakan ulang resource. Jika resource tidak dapat diprovisi ulang, pipeline akan gagal.
- Flex-start akan mencoba menyediakan resource hingga 1 jam setelah pengiriman tugas. Jika tidak dapat menyediakan resource setelah 1 jam, tugas akan gagal.
- Flex-start menggunakan kuota yang dapat diakhiri. Jika project Anda tidak memiliki kuota preemptible, kuota standar akan digunakan. Untuk mengetahui informasi selengkapnya, lihat Kuota preemptible.
- Jika konfigurasi zona pekerja tidak diberikan, Dataflow akan memilih satu zona untuk membuat semua resource berdasarkan dukungan hardware, ketersediaan resource dan kuota saat ini, serta pemesanan yang cocok. Zona ini dapat berbeda dengan zona tempat sumber daya layanan untuk tugas berada.
- Penskalaan otomatis horizontal tidak didukung. Untuk menggunakan lebih dari satu worker, tetapkan opsi pipeline
--num_workers. - TPU tidak didukung.
- Penyesuaian kanan tidak didukung.
Memecahkan masalah flex-start
Jika tugas Anda gagal 1 jam setelah pengiriman dengan error:
The Dataflow job appears to be stuck because no worker activity has been seen in the last 1h.
Buka halaman Kuota di konsol Google Cloud untuk memastikan project Anda memiliki kuota PREEMPTIBLE_GPU_TYPE_GPUS yang cukup di region yang dikonfigurasi tugas Anda.
Jika kuota dalam project Anda mencukupi, maka mulai fleksibel tidak dapat menyediakan resource dalam 1 jam. Pertimbangkan untuk meluncurkan pipeline di zona lain, atau dengan jenis akselerator yang berbeda.
Menggunakan GPU dengan Dataflow Prime
Dataflow Prime memungkinkan Anda
meminta akselerator untuk langkah tertentu dalam pipeline Anda. Untuk menggunakan GPU dengan
Dataflow Prime, jangan gunakan opsi
pipeline --dataflow-service_options=worker_accelerator. Sebagai gantinya, minta GPU dengan petunjuk resource accelerator.
Untuk mengetahui informasi selengkapnya, lihat
Menggunakan petunjuk resource.
Memecahkan masalah tugas Dataflow
Jika Anda mengalami masalah saat menjalankan tugas Dataflow dengan GPU, lihat Memecahkan masalah tugas GPU Dataflow.
Langkah berikutnya
- Pelajari lebih lanjut dukungan GPU di Dataflow.
- Jalankan pipeline inferensi machine learning Anda dengan jenis GPU NVIDIA L4.
- Pelajari Memproses gambar satelit Landsat dengan GPU.