
Salesforce(SFDC)との統合
このページでは、Cortex Framework Data Foundation で Salesforce(SFDC)の運用ワークロードを統合する手順について説明します。Cortex Framework は、Salesforce から Dataflow パイプラインを介して BigQuery にデータを統合します。一方、Managed Service for Apache Airflow は、これらの Dataflow パイプラインをスケジュールし、モニタリングすることで、データから分析情報を取得します。
構成ファイル
Cortex Framework Data Foundation リポジトリの config.json
ファイルは、
Salesforce を含む
任意のデータソースから
データを転送するために必要な設定を構成します。このファイルには、運用 Salesforce ワークロードの次のパラメータが含まれています。
"SFDC": {
"deployCDC": true,
"createMappingViews": true,
"createPlaceholders": true,
"datasets": {
"cdc": "",
"raw": "",
"reporting": "REPORTING_SFDC"
}
}
次の表に、SFDC 運用パラメータの値を示します。
| パラメータ | 意味 | デフォルト値 | 説明 |
SFDC.deployCDC
|
CDC をデプロイする | true
|
Managed Service for Apache Airflow で DAG として実行する CDC 処理スクリプトを生成します。Salesforce Sales Cloud のさまざまな 取り込みオプションについては、ドキュメントをご覧ください。 |
SFDC.createMappingViews
|
マッピング ビューを作成する | true
|
Salesforce API から新しいレコードを取得するために提供された DAG は、ランディング時にレコードを更新します。この値を true に設定すると
、CDC 処理済みデータセットにビューが生成され、元データセットから
「最新バージョンの真実」を含むテーブルが公開されます。false で
SFDC.deployCDC が true の場合、DAG は SystemModstamp に基づいて変更データ キャプチャ(CDC)処理で生成されます。Salesforce の CDC 処理の詳細をご覧ください。 |
SFDC.createPlaceholders
|
プレースホルダを作成する | true
|
取り込みプロセスで生成されない場合に、空のプレースホルダ テーブルを作成して、ダウンストリーム レポートのデプロイが失敗せずに実行できるようにします。 |
SFDC.datasets.raw
|
元のランディング データセット | - | CDC プロセスで使用されます。レプリケーション ツールは、Salesforce からのデータをここに配置します。テストデータを使用する場合は、 空のデータセットを作成します。 |
SFDC.datasets.cdc
|
CDC 処理済みデータセット | - | レポートビューのソースとして機能するデータセットと、処理済み DAG のレコードのターゲット。テストデータを使用する場合は、空のデータセットを作成します。 |
SFDC.datasets.reporting
|
レポート データセット SFDC | "REPORTING_SFDC"
|
レポート作成のためにエンドユーザーがアクセスできるデータセットの名前。ビューとユーザー向けのテーブルがデプロイされます。 |
SFDC.currencies
|
通貨のフィルタリング | [ "USD" ]
|
テストデータを使用していない場合は、ビジネスに関連する
単一の通貨([ "USD" ]など)または複数の通貨
([ "USD", "CAD" ]など)を入力します。
これらの値は、使用可能な分析モデルの SQL のプレースホルダを置き換えるために使用されます。
使用可能な場合。
|
データモデル
このセクションでは、エンティティ関連図(ERD)を使用して Salesforce(SFDC)データモデルについて説明します。
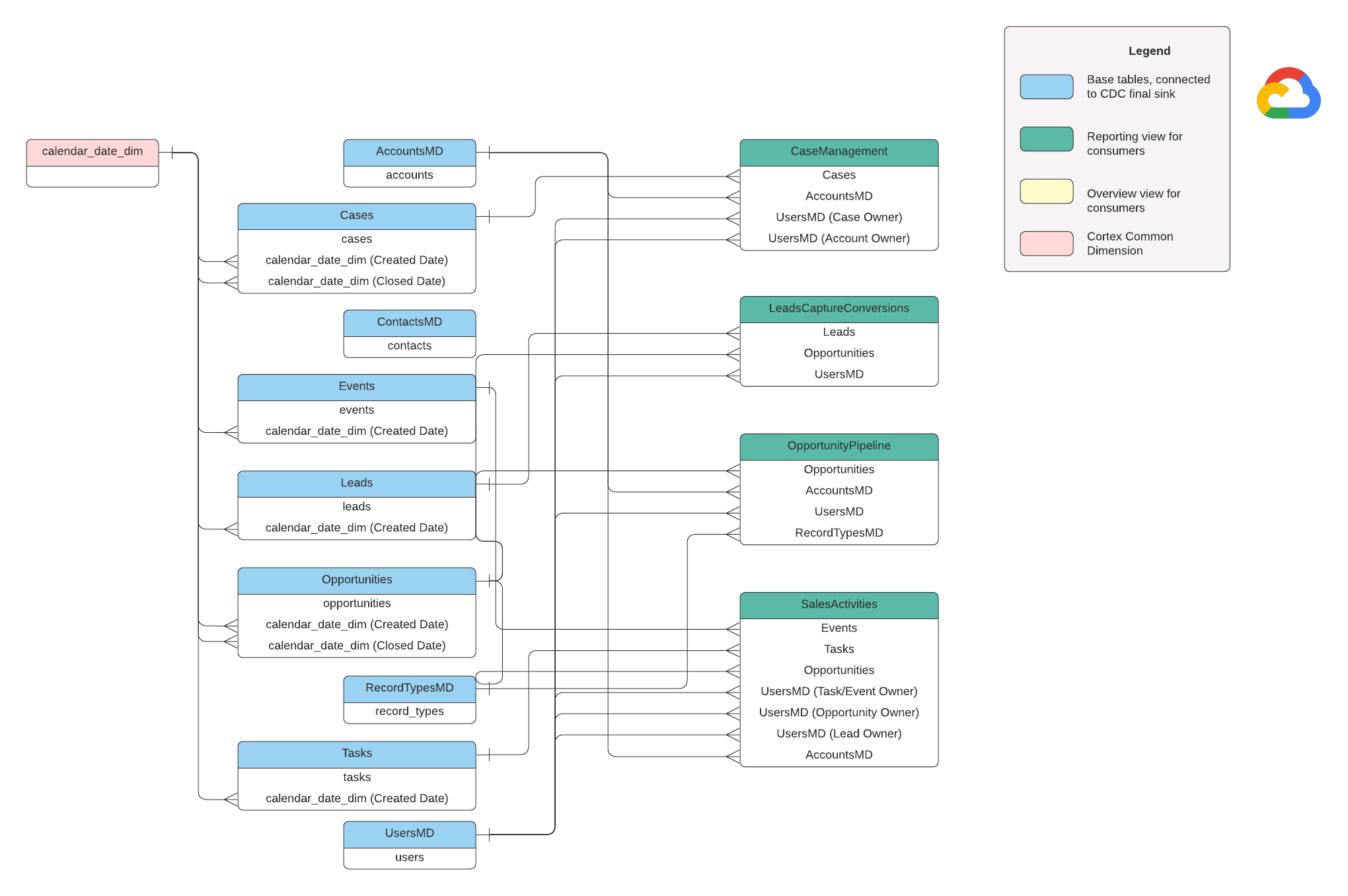
ベースビュー
これらは ERD の青いオブジェクトで、列名のエイリアス以外の変換がない CDC テーブルのビューです。
src/SFDC/src/reporting/ddls のスクリプトをご覧ください。
レポートビュー
これらは ERD の緑色のオブジェクトで、レポートテーブルで使用される関連するディメンション属性が含まれています。
src/SFDC/src/reporting/ddls のスクリプトをご覧ください。
Salesforce データの要件
このセクションでは、Cortex Framework で使用するために Salesforce データを構造化する方法について説明します。
- テーブル構造:
- 命名: テーブル名には
snake_case(小文字の単語をアンダースコアで区切る)を使用し、複数形にします。例:some_objects - データ型: 列は、Salesforce 内で表現されるものと同じデータ型を維持します。
- 可読性: レポートレイヤでわかりやすくするために、一部のフィールド名が若干調整される場合があります。
- 命名: テーブル名には
- 空のテーブルとデプロイ: 元データセットに不足している必要なテーブルは、デプロイ プロセス中に空のテーブルとして自動的に作成されます。これにより、CDC デプロイ ステップがスムーズに実行されます。
- CDC の要件:
IdおよびSystemModstampフィールドは、CDC スクリプトがデータの変更を追跡するために不可欠です。これらの名前は、正確な名前でも異なる名前でもかまいません。提供されている元の処理スクリプトは、これらのフィールドを API から自動的に取得し、ターゲット レプリケーション テーブルを更新します。Id: 各レコードの一意の識別子として機能します。SystemModstamp: このフィールドには、レコードが最後に変更された日時を示すタイムスタンプが格納されます。
- 元の処理スクリプト:提供されている元の処理スクリプトでは、 追加の(CDC)処理は必要ありません。この動作は、デフォルトでデプロイ時に設定されます。
通貨換算のソーステーブル
Salesforce では、次の 2 つの方法で通貨を管理できます。
- 基本: これはデフォルトで、すべてのデータで単一の通貨が使用されます。
- 詳細: 為替レートに基づいて複数の通貨間で変換します(高度な通貨管理を有効にする必要があります)。
高度な通貨管理を使用する場合、Salesforce は次の 2 つの特別なテーブルを使用します。
- CurrencyTypes: このテーブルには、使用するさまざまな 通貨(USD、EUR など)に関する情報が格納されます。
- DatedConversionRates: このテーブルには、通貨間の為替レートが経時的に保持されます。
高度な通貨管理を使用する場合、Cortex Framework はこれらのテーブルが存在することを想定しています。高度な通貨管理を使用しない場合は、構成ファイル(src/SFDC/config/ingestion_settings.yaml)からこれらのテーブルに関連するエントリを削除できます。この手順により、存在しないテーブルからデータを抽出する不要な試行を防ぐことができます。
SFDC データを BigQuery に読み込む
Cortex Framework は、Apache Airflow と Salesforce Bulk API 2.0 でスケジュールされた Python スクリプトに基づくレプリケーション ソリューションを提供します。これらの Python スクリプトは、任意のツールで調整してスケジュールできます。詳細については、SFDC 抽出モジュールをご覧ください。
Cortex Framework には、データの取得元と管理方法に応じて、データを統合する 3 つの方法もあります。
- API 呼び出し: このオプションは、API を介して直接アクセスできるデータ用です。Cortex Framework は API を呼び出してデータを取得し、BigQuery 内の「Raw」データセットに保存できます。データセットに既存のレコードがある場合、Cortex Framework は新しいデータで更新できます。
- 構造マッピング ビュー: この方法は、別のツールを使用して BigQuery にデータを読み込んでいるが、データ構造が Cortex Framework で必要なものと一致しない場合に便利です。 Cortex Framework は「ビュー」(仮想テーブルなど)を使用して、既存のデータ構造を Cortex Framework のレポート機能で想定される形式に変換します。
CDC(変更データ キャプチャ)処理スクリプト: このオプションは、常に変化するデータ用に設計されています。CDC スクリプトはこれらの変更を追跡し、BigQuery のデータを適宜更新します。これらのスクリプトは、データ内の次の 2 つの特別なフィールドに依存しています。
Id: 各レコードの一意の識別子。SystemModstamp: レコードが変更された日時を示すタイムスタンプ。
データにこれらの正確な名前がない場合、スクリプトを調整して別の名前で認識できます。このプロセス中に、データ スキーマにカスタム フィールドを追加することもできます。たとえば、Account オブジェクトのデータを含むソーステーブルには、元の
IdフィールドとSystemModstampフィールドが必要です。これらのフィールドの名前が異なる場合は、src/SFDC/src/table_schema/accounts.csvファイルを更新して、Idフィールドの名前をAccountIdにマッピングし、システム変更タイムスタンプ フィールドをSystemModstampにマッピングする必要があります。詳細については、 SystemModStamp のドキュメントをご覧ください。
別のツールを使用してデータを読み込んでいる場合(常に更新されている場合)、Cortex は引き続き使用できます。CDC スクリプトには、既存のデータ構造を Cortex Framework で必要な形式に変換できるマッピング ファイルが付属しています。このプロセス中に、データにカスタム フィールドを追加することもできます。
API 統合と CDC を構成する
Salesforce データを BigQuery に取り込むには、次の方法を使用します。
- API 呼び出し用の Cortex スクリプト: Salesforce または任意のデータ レプリケーション ツール用のレプリケーション スクリプトを提供します。重要なのは、取り込むデータが Salesforce API から取得したデータと同じように見えることです。
- レプリケーション ツールと常に追記 : レプリケーションにツールを使用している場合、この方法は、新しいデータレコード (_appendalways_pattern) を追加するか、既存のレコードを更新できるツール用です。
- レプリケーション ツールと新しいレコードの追加: ツールがレコードを更新せず、 変更を新しいレコードとしてターゲット(Raw)テーブルに複製する場合、Cortex Data Foundation には CDC 処理スクリプトを作成するオプションが用意されています。詳細については、CDC プロセスをご覧ください。

データが Cortex Framework で想定されるものと一致するように、マッピング構成を調整して、レプリケーション ツールまたは既存のスキーマをマッピングできます。これにより、Cortex Framework Data Foundation で想定される構造と互換性のあるマッピング ビューが生成されます。
ingestion_settings.yaml ファイルを使用して、
Salesforce API を呼び出してデータを Raw データセット(salesforce_to_raw_tables セクション)に複製するスクリプトの生成と、
Raw データセットに受信した変更を処理して CDC 処理済みデータセット(raw_to_cdc_tables セクション)に処理するスクリプトの生成を構成します。
デフォルトでは、API から読み取るために提供されるスクリプトは、Raw データセットに変更を更新するため、CDC 処理スクリプトは必要ありません。代わりに、ソース スキーマを想定されるスキーマに合わせるためのマッピング ビューが作成されます。
config.json で SFDC.createMappingViews=true
の場合、CDC 処理スクリプトの生成は実行されません(デフォルトの動作)。CDC スクリプトが必要な場合は、SFDC.createMappingViews=false を設定します。この 2 つ目の手順では、Cortex Framework Data Foundation で必要なソース スキーマと必要なスキーマ間のマッピングも可能になります。
setting.yaml 構成ファイルの次の例は、レプリケーション ツールが複製されたデータセットにデータを直接更新する場合のマッピング ビューの生成を示しています(option 3 のように、CDC は不要で、テーブルとフィールド名の再マッピングのみが必要です)。CDC は不要なため、config.json ファイルのパラメータ SFDC.createMappingViews が true のままであれば、このオプションは実行されます。
salesforce_to_raw_tables:
- base_table: accounts
raw_table: Accounts
api_name: Account
load_frequency: "@daily"
- base_table: cases
raw_table: cases2
api_name: Case
load_frequency: "@daily"
この例では、ベーステーブルの構成またはセクションからすべての構成を削除すると、salesforce_to_raw_tables で説明されているように、そのベーステーブルまたはセクション全体の DAG の生成がスキップされます。このシナリオでは、CDC 処理スクリプトを生成する必要がないため、パラメータ deployCDC : False を設定しても同じ効果があります。
データ マッピング
受信データ フィールドを Cortex Data Foundation で想定される形式にマッピングする必要があります。たとえば、ソースデータ システムの unicornId という名前のフィールドは、Cortex Data Foundation 内で AccountId(文字列データ型)として名前を変更して認識する必要があります。
- ソース フィールド:
unicornId(ソースシステムで使用される名前) - Cortex フィールド:
AccountId(Cortex で想定される名前) - データ型:
String(Cortex で想定されるデータ型)
ポリモーフィック フィールドのマッピング
Cortex Framework Data Foundation は、名前は異なるが構造は一貫しているポリモーフィック フィールドのマッピングをサポートしています。ポリモーフィック フィールド
の型名(Who.Type など)は、対応するマッピング CSV ファイル
src/SFDC/src/table_schema/tasks.csv に [Field Name]_Type アイテムを追加することで複製できます。たとえば、Task オブジェクトの Who.Type フィールドを複製する必要がある場合は、Who_Type,Who_Type,STRING 行を追加します。これにより、Who.Type という名前の新しいフィールドが定義され、そのフィールド自体にマッピングされ(同じ名前を保持)、文字列データ型が設定されます。
DAG テンプレートを変更する
Airflow または Managed Airflow のインスタンスで必要な場合は、CDC または 元のデータ処理用の DAG テンプレートを調整する必要があります。詳細については、 Managed Airflow の設定を収集するをご覧ください。
API 呼び出しから CDC または元のデータ生成が不要な場合は、deployCDC=false を設定します。または、
セクションの内容をingestion_settings.yamlから削除することもできます。データ構造が Cortex Framework Data Foundation で想定されるものと一致していることがわかっている場合は、SFDC.createMappingViews=false を設定して、マッピング ビューの生成をスキップできます。
抽出モジュールを構成する
このセクションでは、Data Foundation が提供する Salesforce から BigQuery への抽出モジュールを使用する手順について説明します。要件とフローは、システムと既存の構成によって異なる場合があります。他の利用可能なツールを使用することもできます。
認証情報と接続済みアプリを設定する
管理者として Salesforce インスタンスにログインして、次の操作を行います。
- 次の要件を満たすプロファイルを Salesforce で作成または特定します。
Permission for Apex REST Services and API Enabledが [システム権限] で付与されている。- 複製するすべてのオブジェクトに対して
View All権限が付与されている。例: Account、Cases。セキュリティ管理者による制限や問題がないか確認してください。 - ユーザー インターフェース ログインに関連する権限( Lightning Experience の Salesforce Anywhere、 モバイル版の Salesforce Anywhere、Lightning Experience ユーザー、Lightning ログイン ユーザーなど)が付与されていない。セキュリティ管理者による制限や問題がないか確認してください。
- Salesforce で既存のユーザーを作成または使用します。ユーザーのユーザー名、パスワード、およびセキュリティ トークンを知っておく必要があります。次の点を考慮してください。
- これは、このレプリケーションを実行するための専用ユーザーにするのが理想的です。
- ユーザーは、ステップ 1 で作成または特定したプロファイルに割り当てる必要があります。
- ユーザー名 を確認し、パスワード を再設定できます。
- セキュリティ トークンがない場合や、別のプロセスで使用されていない場合は、セキュリティ トークンを再設定できます。
- 接続済みアプリを作成します。これは、プロファイル、Salesforce
API、標準ユーザー認証情報、そのセキュリティ トークンを使用して、外部から Salesforce への接続を確立する唯一の通信チャネルです。
- 手順に沿って、API 統合の OAuth 設定を有効にします。
- [API(OAuth 設定を有効にする)] セクションで、
Require Secret for Web Server FlowとRequire Secretfor Refresh Token Flowが有効になっていることを確認します。 - ドキュメントで、 コンシューマ キー(後でクライアント IDとして使用されます)を取得する方法をご覧ください。問題や制限については、セキュリティ管理者にお問い合わせください。
- 作成したプロファイルに接続済みアプリを割り当てます。
- Salesforce ホーム画面の右上にある [設定] を選択します。
- [クイック検索 ] ボックスに「
profile」と入力し、[プロファイル] を選択します。ステップ 1 で作成したプロファイルを検索します。 - プロファイルを開きます。
- [割り当てられた接続済みアプリ] リンクをクリックします。
- [編集] をクリックします。
- 新しく作成した接続済みアプリを追加します。
- [保存] をクリックします。
Secret Manager を設定する
接続の詳細を保存するように Secret Manager を構成します。Salesforce から BigQuery へのモジュールは、Salesforce と BigQuery に接続するために必要な認証情報を安全に保存するために Secret Manager に依存しています。この方法では、パスワードなどの機密情報をコードや構成ファイルに直接公開することを回避し、セキュリティを強化できます。
次の仕様で Secret を作成します。詳細な手順については、 Secret を作成するをご覧ください。
- Secret 名:
airflow-connections-salesforce-conn Secret の値:
http://USERNAME:PASSWORD@https%3A%2F%2FINSTANCE_NAME.lightning.force.com?client_id=CLIENT_ID&security_token=SECRET_TOKEN`次のように置き換えます。
USERNAMEは、ユーザー名に置き換えます。PASSWORDは、パスワードに置き換えます。INSTANCE_NAMEは、インスタンス名に置き換えます。CLIENT_IDは、クライアント ID に置き換えます。SECRET_TOKENは、Secret トークンに置き換えます。
詳細については、インスタンス名を確認する方法をご覧ください。
レプリケーション用の Managed Airflow ライブラリ
Cortex Framework Data Foundation が提供する DAG で Python スクリプトを実行するには、いくつかの依存関係をインストールする必要があります。Airflow バージョン 1.10 の場合は、Managed Service for Apache Airflow 1 の Python 依存関係をインストールするの手順 に沿って、次のパッケージを順番にインストールします。
tableauserverclient==0.17
apache-airflow-backport-providers-salesforce==2021.3.3
Airflow バージョン 2.x の場合は、Managed Service for Apache Airflow 2 の Python 依存関係をインストールするのドキュメントを参照して、apache-airflow-providers-salesforce~=5.2.0 をインストールします。
次のコマンドを使用して、必要なパッケージをそれぞれ インストールします。
gcloud composer environments update ENVIRONMENT_NAME \
--location LOCATION \
--update-pypi-package PACKAGE_NAME EXTRAS_AND_VERSION
次のように置き換えます。
ENVIRONMENT_NAMEは、割り当てられた環境名に置き換えます。LOCATIONは、ロケーションに置き換えます。PACKAGE_NAMEは、選択したパッケージ名に置き換えます。EXTRAS_AND_VERSIONは、Extras とバージョンの仕様に置き換えます。
必要なパッケージのインストール例を次のコマンドに示します。
gcloud composer environments update my-composer-instance \
--location us-central1 \
--update-pypi-package apache-airflow-backport-providers-salesforce>=2021.3.3
Secret Manager をバックエンドとして有効にする
Google Secret Manager をセキュリティ バックエンドとして有効にします。このステップでは、Managed Service for Apache Airflow 環境で使用されるパスワードや API キーなどの機密情報のプライマリ ストレージ ロケーションとして Secret Manager を有効にします。これにより、専用サービスで認証情報を一元管理することでセキュリティが強化されます。詳細については、Secret Manager をご覧ください。
Composer サービス アカウントに Secret へのアクセスを許可する
このステップでは、Managed Service for Apache Airflow に関連付けられたサービス アカウントに、Secret Manager に保存されている Secret にアクセスするために必要な権限があることを確認します。
デフォルトでは、Managed Service for Apache Airflow は Compute Engine サービス アカウントを使用します。
必要な権限は Secret Manager Secret Accessor です。
この権限により、サービス アカウントは Secret Manager に保存されている Secret を取得して使用できます。Secret Manager でアクセス制御を構成する方法については、アクセス制御のドキュメントをご覧ください。
Airflow の BigQuery 接続
Managed Airflow の設定を収集するに沿って、接続 sfdc_cdc_bq を作成してください。この接続は、Salesforce から BigQuery へのモジュールが BigQuery との通信を確立するために使用される可能性があります。
次のステップ
- 他のデータソースとワークロードの詳細については、 データソースとワークロードをご覧ください。
- 本番環境でのデプロイの手順の詳細については、 Cortex Framework Data Foundation のデプロイの前提条件をご覧ください。