
Salesforce Marketing Cloud との統合
このページでは、Salesforce Marketing Cloud(SFMC)から Cortex Framework Data Foundation のマーケティング ワークロードのデータソースとしてデータを取り込むために必要な構成について説明します。
SFMC は、Salesforce が提供するデジタル マーケティング自動化プラットフォームです。 企業は、複数のチャネルにわたるさまざまなマーケティング活動を管理、自動化するための包括的なツールスイートを利用できます。 Cortex Framework は、結果の把握、改善点の特定、より良い成果を得るためのマーケティング戦略の最適化に役立つデータ分析エンジンおよび AI エンジンとして機能します。
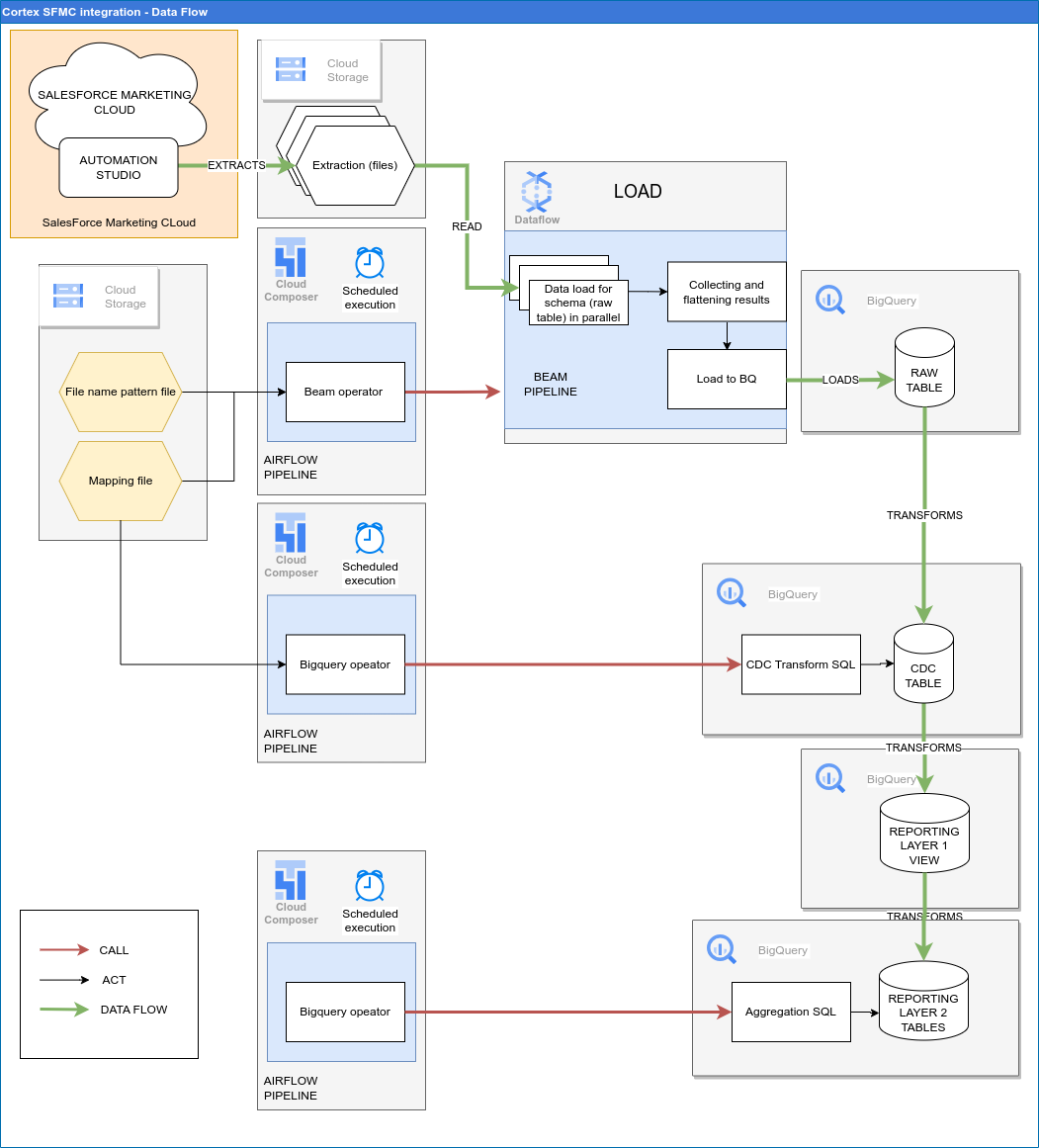
次の図は、Cortex Framework Data Foundation のマーケティング ワークロードを通じて SFMC データを利用できるようにする方法を示しています。
構成ファイル
config.json ファイルは、さまざまなワークロードからデータを転送するためにデータソースに接続するために必要な設定を構成します。このファイルには、SFMC
の次のパラメータが含まれています。
"marketing": {
"deploySFMC": true,
"SFMC": {
"deployCDC": true,
"fileTransferBucket": "",
"datasets": {
"cdc": "",
"raw": "",
"reporting": "REPORTING_SFMC"
}
}
}
次の表に、各マーケティング パラメータの値を示します。
| パラメータ | 意味 | デフォルト値 | 説明 |
marketing.deploySFMC
|
SFMC をデプロイする | true
|
SFMC データソースのデプロイを実行します。 |
marketing.SFMC.deployCDC
|
SFMC の CDC スクリプトをデプロイする | true
|
Salesforce Marketing Cloud(SFMC) の CDC 処理スクリプトを生成して、Managed Airflow で DAG として実行します。 |
marketing.SFMC.fileTransferBucket
|
データ抽出ファイルを含むバケット | - | Salesforce Marketing Cloud(SFMC) Automation Studio のデータ抽出ファイルが保存されるバケット。 |
marketing.SFMC.datasets.cdc
|
SFMC の CDC データセット | Salesforce Marketing Cloud(SFMC)の CDC データセット。 | |
marketing.SFMC.datasets.raw
|
SFMC の元データセット | Salesforce Marketing Cloud(SFMC)の元データセット。 | |
marketing.SFMC.datasets.reporting
|
SFMC のレポート データセット | "REPORTING_SFMC"
|
Salesforce Marketing Cloud(SFMC)のレポート データセット。 |
データモデル
このセクションでは、エンティティ関連図(ERD)を使用して Salesforce Marketing Cloud(SFMC)データモデルについて説明します。
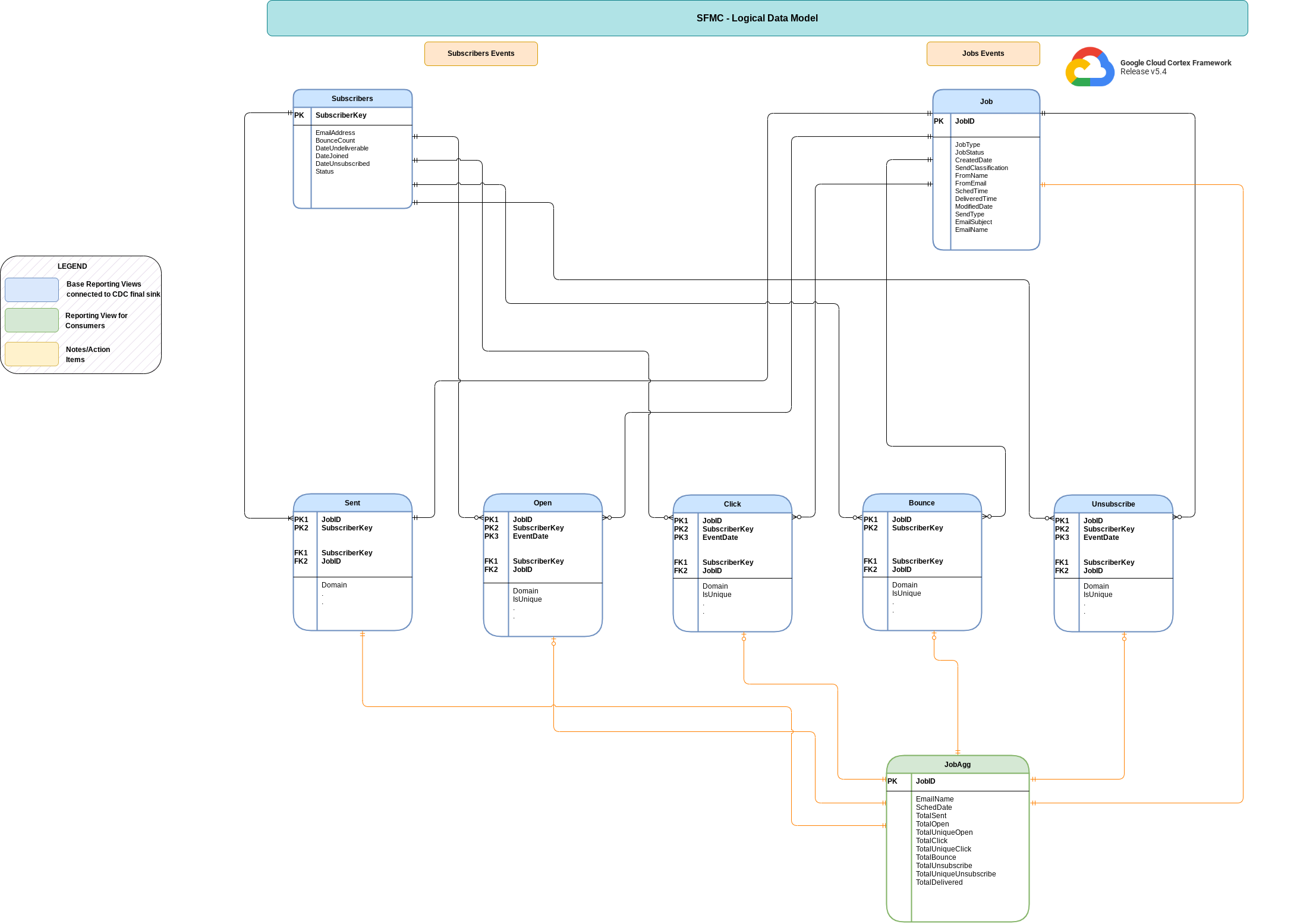
ベースビュー
これらは ERD の青いオブジェクトで、列名のエイリアス以外の変換がない CDC テーブルのビューです。
src/marketing/src/SFMC/src/reporting/ddls のスクリプトをご覧ください。
レポートビュー
これらは ERD の緑色のオブジェクトで、集計指標を含むレポートビューです。
src/marketing/src/SFMC/src/reporting/ddls のスクリプトをご覧ください。
Automation Studio を使用したデータ抽出
SFMC Automation Studio を使用すると、SFMC のユーザーは SFMC データをさまざまなストレージ システムにエクスポートできます。 Cortex Framework Data Foundation は、Cloud Storage バケット内の Automation Studio で作成された一連のファイルを検索します。このプロセスでは、 SFMC Email Studio も使用する必要があります。
データ抽出プロセスとエクスポート プロセスを設定する手順は次のとおりです。
- Cloud Storage バケットを設定します。このバケットには、SFMC からエクスポートされたファイルが保存されます。バケットに
marketing.SFMC.fileTransferBucket構成パラメータの名前を付けます。手順については、Salesforce のドキュメントをご覧ください。 データ エクステンションを作成します。データを抽出するエンティティごとに、 Email Studio でデータ エクステンションを作成します。 これは、SFMC 内部データベースからデータソースを識別するために必要です。
- エンティティの
src/SFMC/config/table_schemaで定義されているすべてのフィールドを一覧表示します。これをカスタマイズしてフィールドの数を増減する場合は、これらの手順とテーブル スキーマ ファイルでフィールドのリストが揃っていることを確認してください。次に例を示します。
Entity: unsubscribe Fields: AccountID OYBAccountID JobID ListID BatchID SubscriberID SubscriberKey EventDate IsUnique Domain- エンティティの
SQL クエリ アクティビティを作成します。エンティティごとに SQL クエリ アクティビティを作成します。 このアクティビティは、先ほど作成した対応するデータ エクステンションに接続されています。 この手順については、Salesforce のドキュメント をご覧ください。
- 関連するすべてのフィールドを含む SQL クエリを定義します。クエリでは、前のステップでデータ エクステンションで定義されたエンティティに関連するすべてのフィールドを選択する必要があります。
- 正しいデータ エクステンションをターゲットとして選択します。
- [データ アクション] で [上書き] を選択します。
- 次のクエリの例をご覧ください。
SELECT AccountID, OYBAccountID, JobID, ListID, BatchID, SubscriberID, SubscriberKey, EventDate, IsUnique, Domain FROM _Unsubscribeデータ抽出アクティビティを作成します。エンティティごとに データ抽出アクティビティ を作成する方法については、Salesforce のドキュメントをご覧ください。このアクティビティは、Salesforce データ エクステンションからデータを取得し、csv ファイルに抽出します。 この手順では、次の操作を行います。
- 正しい命名パターンを使用します。設定で定義されているパターンと一致する必要があります。
settings.たとえば、
Unsubscribeエンティティの場合、ファイル名はunsubscribe_%%Year%%_%%Month%%_%%Day%% %%Hour%%.csvのようになります。 - [抽出タイプ] を
Data Extension Extractに設定します。 - [列ヘッダーがある] オプションと [テキストの引用符] オプションを選択します。
- 正しい命名パターンを使用します。設定で定義されているパターンと一致する必要があります。
settings.たとえば、
ファイル変換アクティビティを作成して、形式を UTF-16 から UTF-8 に変換します 。デフォルトでは、Salesforce は CSV ファイルを UTF-16 でエクスポートします。このステップでは、UTF-8 形式に変換します。エンティティごとに、ファイル変換用の別のデータ抽出アクティビティ を作成します。この手順では、次の操作を行います。
- データ抽出アクティビティの前のステップで使用したのと同じファイル名パターンを使用します。
- [抽出タイプ] を
File Convertに設定します。 - [
Convert To] のプルダウンからUTF8を選択します。
ファイル転送アクティビティを作成します。エンティティごとにファイル転送アクティビティ を作成します。これらのアクティビティは、抽出された csv ファイルを Salesforce Safehouse から Cloud Storage バケットに移動します。この手順では、次の操作を行います。
- 前のステップで使用したのと同じファイル名パターンを使用します。
- プロセスで以前に設定した Cloud Storage バケットを宛先として選択します。
実行をスケジュールします。すべてのアクティビティが完了したら、 自動スケジュール を設定して実行します。
データの鮮度と遅延
原則として、Cortex Framework データソースのデータの更新速度は、アップストリーム接続で許可されるものと DAG の実行頻度によって制限されます。アップストリームの頻度、リソースの制約、ビジネスニーズに合わせて DAG の実行頻度を調整します。
SFMC Automation Studioでは、 データのエクスポートを設定する際のスケジュールの遅延によって、データの更新速度の遅延が決まります 。
Managed Service for Apache Airflow 接続の権限
マネージド Airflow で次の接続を作成します。詳細については、 Airflow 接続を管理するのドキュメントをご覧ください。
| 接続名 | 目的 |
sfmc_raw_dataflow
|
SFMC 抽出ファイル > BigQueryRaw データセットの場合。 |
sfmc_cdc_bq
|
元データセット > CDC データセット転送の場合。 |
sfmc_reporting_bq
|
CDC データセット > レポート データセット転送の場合。 |
Managed Airflow サービス アカウントの権限
Managed Airflow で使用されるサービス アカウント(sfmc_raw_dataflow 接続で構成)には、Dataflow 関連の権限が必要です。手順については、Dataflow のドキュメントをご覧ください。
取り込みに関する設定
Source to Raw と Raw to CDC データ パイプラインは、ファイル src/SFMC/config/ingestion_settings.yaml の設定で制御します。このセクションでは、各データ パイプラインのパラメータについて説明します。
元テーブルへのソース
このセクションには、Automation Studio から抽出されたファイルの使用方法を制御するエントリがあります。各エントリは 1 つの SFMC エンティティに対応します。 この構成に基づいて、Cortex Framework は、エクスポートされたファイルから元データセットの BigQuery テーブルにデータを読み込む Dataflow パイプラインを実行する Airflow DAG を作成します。
ディレクトリ src/SFMC/config/table_schema には、SFMC
から抽出されたエンティティごとにスキーマファイルが含まれています。各ファイルでは、Automation Studio から抽出された CSV ファイルを読み取って、BigQueryraw データセットに正常に読み込む方法について説明します。
各スキーマファイルには次の 3 つの列が含まれています。
SourceField: csv ファイルのフィールド名。TargetField: このエンティティの元テーブルの列名。DataType: 各元テーブル フィールドのデータ型。
次のパラメータは、エントリごとに Source to Raw の設定を制御します。
| パラメータ | 説明 |
base_table
|
SFMC エンティティの抽出データが読み込まれる元テーブル名。 |
load_frequency
|
抽出ファイルからデータを読み込むために、このエンティティの DAG が実行される頻度。使用可能な値の詳細については、Airflow のドキュメントをご覧ください。 |
file_pattern
|
Automation Studio から Cloud Storage バケットにエクスポートされるこのテーブルのファイルのパターン。抽出ファイルに推奨されている名前とは異なる名前を選択した場合にのみ、これを変更してください。 |
partition_details
|
パフォーマンス上の考慮事項に基づいて元テーブルをパーティション分割する方法 。詳細については、 テーブル パーティションをご覧ください。 |
cluster_details
|
省略可: パフォーマンス上の考慮事項に基づいて元テーブル をクラスタ化する場合。詳細については、 クラスタの設定をご覧ください。 |
元テーブルから CDC テーブルへ
このセクションでは、元テーブルから CDC テーブルにデータを移動する方法を制御するエントリについて説明します。各エントリは元テーブルに対応します。
次のパラメータは、エントリごとに Raw to CDC の設定を制御します。
| パラメータ | 説明 |
base_table
|
CDC 変換後の元データが保存される CDC データセット内のテーブル。 |
load_frequency
|
このエンティティの DAG が CDC テーブルへのデータの入力のために実行される頻度。使用可能な値の詳細については、 Airflow のドキュメントをご覧ください。 |
raw_table
|
元データセットのソーステーブル。 |
row_identifiers
|
このテーブルの一意のレコードを形成する列(カンマ区切り) |
partition_details
|
パフォーマンス上の考慮事項に基づいて CDC テーブルをパーティション分割する方法 。詳細については、 テーブル パーティションをご覧ください。 |
cluster_details
|
省略可: パフォーマンス上の考慮事項に基づいてこのテーブルを クラスタ化する場合。詳細については、 クラスタの設定をご覧ください。 |
レポート設定
レポート設定ファイル(src/SFMC/config/reporting_settings.yaml)を使用して、Cortex Framework が SFMC
の最終レポート レイヤのデータを生成する方法を構成および制御できます。このファイルは、レポート レイヤの BigQuery
オブジェクト(テーブル、ビュー、関数、ストアド プロシージャ)の生成方法を制御します。
詳細については、レポート設定ファイルのカスタマイズをご覧ください。
次のステップ
- 他のデータソースとワークロードの詳細については、 データソースとワークロードをご覧ください。
- 本番環境でのデプロイの手順の詳細については、 Cortex Framework Data Foundation のデプロイの前提条件をご覧ください。