
Verknüpfung mit Salesforce Marketing Cloud
Auf dieser Seite werden die erforderlichen Konfigurationen beschrieben, um Daten aus Salesforce Marketing Cloud (SFMC) als Datenquelle für die Marketing-Arbeitslast der Cortex Framework Data Foundation zu verwenden.
SFMC ist eine von Salesforce angebotene Plattform für die Automatisierung von digitalem Marketing. Unternehmen erhalten damit eine umfassende Suite von Tools, mit denen sie verschiedene Marketingaktivitäten über mehrere Kanäle hinweg verwalten und automatisieren können. Das Cortex Framework dient als Datenanalyse- und KI-Engine, mit der Sie die Ergebnisse besser nachvollziehen, Bereiche mit Verbesserungspotenzial identifizieren und Ihre Marketingstrategie optimieren können, um bessere Ergebnisse zu erzielen.
Das folgende Diagramm zeigt, wie SFMC-Daten über die Marketing-Arbeitslast von Cortex Framework Data Foundation verfügbar sind:
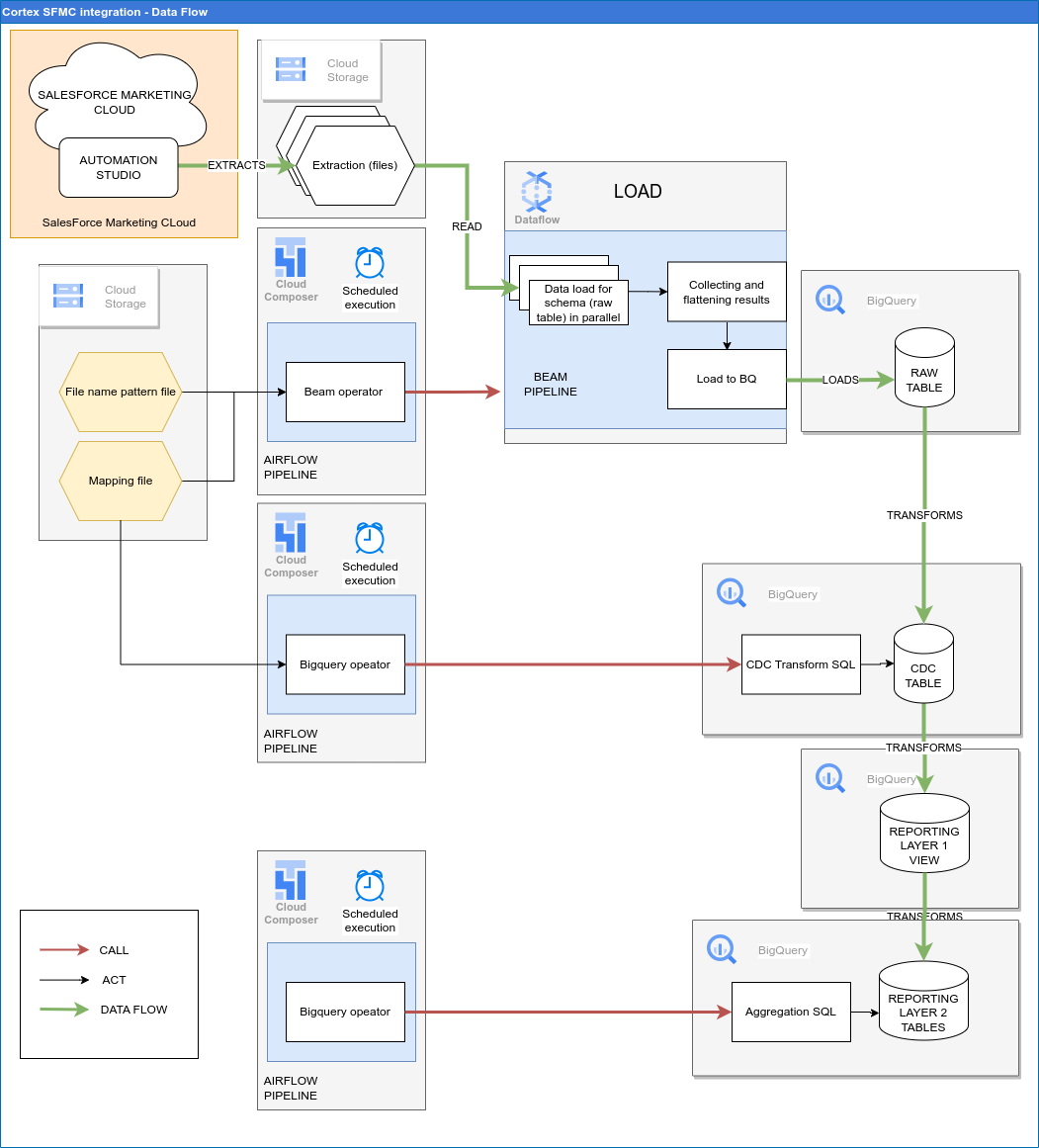
Konfigurationsdatei
In der Datei config.json werden die Einstellungen konfiguriert, die für die Verbindung zu Datenquellen zum Übertragen von Daten aus verschiedenen Arbeitslasten erforderlich sind. Diese Datei enthält die folgenden Parameter für SFMC:
"marketing": {
"deploySFMC": true,
"SFMC": {
"deployCDC": true,
"fileTransferBucket": "",
"datasets": {
"cdc": "",
"raw": "",
"reporting": "REPORTING_SFMC"
}
}
}
In der folgenden Tabelle wird der Wert für jeden Marketingparameter beschrieben:
| Parameter | Bedeutung | Standardwert | Beschreibung |
marketing.deploySFMC
|
SFMC bereitstellen | true
|
Führen Sie die Bereitstellung für die SFMC-Datenquelle aus. |
marketing.SFMC.deployCDC
|
CDC-Skripts für SFMC bereitstellen | true
|
Generieren Sie Salesforce Marketing Cloud-Scripts (SFMC) für die CDC-Verarbeitung, die als DAGs in Managed Airflow ausgeführt werden. |
marketing.SFMC.fileTransferBucket
|
Bucket mit Data Extract-Dateien | - | Bucket, in dem Salesforce Marketing Cloud (SFMC) Automation Studio-Dateien für den Datenexport gespeichert werden. |
marketing.SFMC.datasets.cdc
|
CDC-Dataset für SFMC | CDC-Dataset für Salesforce Marketing Cloud (SFMC). | |
marketing.SFMC.datasets.raw
|
Rohdaten-Dataset für SFMC | Rohdatensatz für Salesforce Marketing Cloud (SFMC) | |
marketing.SFMC.datasets.reporting
|
Berichts-Dataset für SFMC | "REPORTING_SFMC"
|
Berichtsdataset für Salesforce Marketing Cloud (SFMC). |
Datenmodell
In diesem Abschnitt wird das Salesforce Marketing Cloud-Datenmodell (SFMC) anhand des Entity-Relationship-Diagramms (ERD) beschrieben.
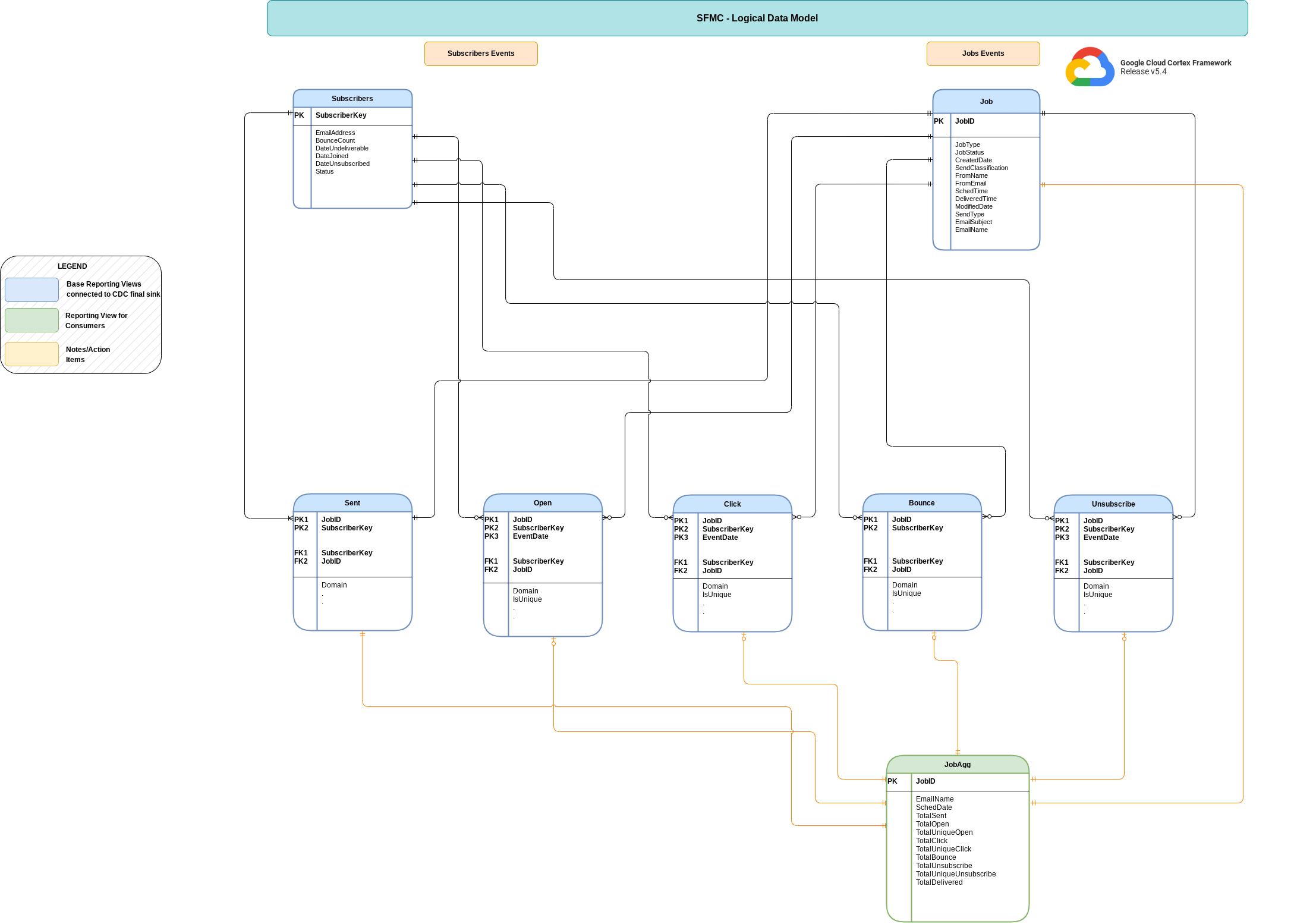
Basisansichten
Das sind die blauen Objekte im ERD. Sie sind Ansichten von CDC-Tabellen ohne Transformationen, abgesehen von einigen Aliasen für Spaltennamen. Scripts finden Sie unter src/marketing/src/SFMC/src/reporting/ddls.
Berichtsdatenansichten
Das sind die grünen Objekte im ERD. Sie sind Berichtsansichten, die aggregierte Messwerte enthalten. Scripts finden Sie unter src/marketing/src/SFMC/src/reporting/ddls.
Datenextraktion mit Automation Studio
Mit SFMC Automation Studio können SFMC-Nutzer ihre SFMC-Daten in verschiedene Speichersysteme exportieren. Cortex Framework Data Foundation sucht in einem Cloud Storage-Bucket nach einer Reihe von Dateien, die mit Automation Studio erstellt wurden. Außerdem müssen Sie SFMC Email Studio verwenden.
So richten Sie die Prozesse zum Extrahieren und Exportieren von Daten ein:
- Cloud Storage-Bucket einrichten In diesem Bucket werden aus SFMC exportierte Dateien gespeichert. Nennen Sie den Bucket
marketing.SFMC.fileTransferBucketconfig-Parameter. Weitere Informationen Daten-Erweiterungen erstellen Erstellen Sie für jede Entität, für die Sie Daten extrahieren möchten, eine Data Extension in Email Studio. Dies ist erforderlich, um die Datenquellen aus der internen SFMC-Datenbank zu identifizieren.
- Listen Sie alle Felder auf, die in
src/SFMC/config/table_schemafür die Entität definiert sind. Wenn Sie diese Anpassung vornehmen müssen, um mehr oder weniger Felder zu extrahieren, achten Sie darauf, dass die Liste der Felder in diesen Schritten sowie in den Tabellenschemadateien übereinstimmt. Beispiel:
Entity: unsubscribe Fields: AccountID OYBAccountID JobID ListID BatchID SubscriberID SubscriberKey EventDate IsUnique Domain- Listen Sie alle Felder auf, die in
SQL-SQL-Abfrage erstellen Erstellen Sie für jede Entität eine SQL-Abfrageaktivität. Diese Aktivität ist mit der entsprechenden Daten-Extension verknüpft, die zuvor erstellt wurde. Salesforce-Dokumentation für diesen Schritt:
- Definieren Sie eine SQL-Abfrage mit allen relevanten Feldern. In der Abfrage müssen alle Felder ausgewählt werden, die für die im vorherigen Schritt in der Data Extension definierte Einheit relevant sind.
- Wählen Sie die richtige Daten-Extension als Ziel aus.
- Wählen Sie Überschreiben als Datenvorgang aus.
- Hier ein Beispiel für eine Abfrage:
SELECT AccountID, OYBAccountID, JobID, ListID, BatchID, SubscriberID, SubscriberKey, EventDate, IsUnique, Domain FROM _UnsubscribeAktivitäten zum Datenextrakt erstellen: In der Salesforce-Dokumentation finden Sie Informationen zum Erstellen einer Data Extract Activity für jede Entität. Bei dieser Aktivität werden die Daten aus der Salesforce-Data Extension abgerufen und in eine CSV-Datei extrahiert. Für diesen Schritt gilt:
- Verwenden Sie das richtige Namensmuster. Er sollte dem in den Einstellungen definierten Muster entsprechen.
Für die Entität
Unsubscribekönnte der Dateiname beispielsweiseunsubscribe_%%Year%%_%%Month%%_%%Day%% %%Hour%%.csvlauten. - Legen Sie für Extract Type (Extraktionstyp) den Wert
Data Extension Extractfest. - Wählen Sie die Optionen Hat Spaltenüberschriften und Text qualifiziert aus.
- Verwenden Sie das richtige Namensmuster. Er sollte dem in den Einstellungen definierten Muster entsprechen.
Für die Entität
Dateikonvertierungsaktivitäten erstellen, um das Format von UTF-16 in UTF-8 zu konvertieren: Standardmäßig exportiert Salesforce CSV-Dateien in UTF-16. In diesem Schritt konvertieren Sie die Datei in das UTF‑8-Format. Erstellen Sie für jede Entität eine weitere Data Extract Activity (Aktivität zum Datenexport) für die Dateikonvertierung. Für diesen Schritt gilt:
- Verwenden Sie dasselbe Dateinamenmuster wie im vorherigen Schritt der Aktivität „Datenextraktion“.
- Legen Sie für Extract Type (Extraktionstyp) den Wert
File Convertfest. - Wählen Sie im Drop-down-Menü unter
Convert Todie OptionUTF8aus.
Aktivitäten für die Dateiübertragung erstellen: Erstellen Sie für jede Einheit eine Aktivität zum Übertragen von Dateien. Bei diesen Aktivitäten werden die extrahierten CSV-Dateien aus dem Salesforce Safehouse in Cloud Storage-Buckets verschoben. Für diesen Schritt gilt:
- Verwenden Sie dasselbe Dateinamenmuster wie in den vorherigen Schritten.
- Wählen Sie einen Cloud Storage-Bucket aus, der zuvor im Prozess als Ziel festgelegt wurde.
Ausführung planen: Nachdem alle Aktivitäten abgeschlossen sind, können Sie automatische Zeitpläne für die Ausführung einrichten.
Datenaktualität und ‑verzögerung
Im Allgemeinen wird die Datenaktualität für Cortex Framework-Datenquellen durch die Upstream-Verbindung und die Häufigkeit der DAG-Ausführung begrenzt. Passen Sie die Ausführungshäufigkeit Ihres DAG an die Upstream-Häufigkeit, Ressourcenbeschränkungen und Ihre geschäftlichen Anforderungen an.
Bei SFMC Automation Studio hängt die Verzögerung bei der Datenaktualität von der Planungsverzögerung ab, die beim Einrichten des Datenexports festgelegt wird.
Berechtigungen für Managed Service for Apache Airflow-Verbindungen
Erstellen Sie die folgenden Verbindungen in Managed Airflow. Weitere Informationen finden Sie in der Dokumentation zum Verwalten von Airflow-Verbindungen.
| Verbindungsname | Purpose |
sfmc_raw_dataflow
|
Für SFMC-extrahierte Dateien > BigQueryRaw-Dataset. |
sfmc_cdc_bq
|
Für die Übertragung von Rohdaten-Datasets zu CDC-Datasets. |
sfmc_reporting_bq
|
Für CDC-Dataset > Übertragung von Berichts-Datasets. |
Dienstkontoberechtigungen für Managed Airflow
Das in Managed Airflow verwendete Dienstkonto (wie in der sfmc_raw_dataflow-Verbindung konfiguriert) benötigt Dataflow-bezogene Berechtigungen.
Eine Anleitung finden Sie in der Dataflow-Dokumentation.
Aufnahmeeinstellungen
Sie können die Datenpipelines Source to Raw und Raw to CDC über die Einstellungen in der Datei src/SFMC/config/ingestion_settings.yaml steuern.
In diesem Abschnitt werden die Parameter der einzelnen Datenpipelines beschrieben.
Von Quell- zu Rohdatentabellen
Dieser Abschnitt enthält Einträge, mit denen gesteuert wird, wie aus Automation Studio extrahierte Dateien verwendet werden. Jeder Eintrag entspricht einer SFMC-Entität. Anhand dieser Konfiguration erstellt das Cortex Framework Airflow-DAGs, die Dataflow-Pipelines ausführen, um Daten aus exportierten Dateien in BigQuery-Tabellen im Rohdatensatz zu laden.
Das Verzeichnis src/SFMC/config/table_schema enthält eine Schemadatei für jede aus SFMC extrahierte Entität. In jeder Datei wird beschrieben, wie die aus Automaton Studio extrahierten CSV-Dateien gelesen werden, damit sie erfolgreich in das BigQuery-Rohdatenset geladen werden können.
Jede Schemadatei enthält drei Spalten:
SourceField: Feldname der CSV-Datei.TargetField: Spaltenname in der Rohdatentabelle für diese Einheit.DataType: Datentyp der einzelnen Rohdatenfelder.
Die folgenden Parameter steuern die Einstellungen für Source to Raw für jeden Eintrag:
| Parameter | Beschreibung |
base_table
|
Name der Rohdatentabelle, in die extrahierte Daten einer SFMC-Entität geladen werden. |
load_frequency
|
Wie oft ein DAG für diese Einheit ausgeführt wird, um Daten aus extrahierten Dateien zu laden. Weitere Informationen zu möglichen Werten finden Sie in der Airflow-Dokumentation. |
file_pattern
|
Muster für die Datei für diese Tabelle, die aus Automation Studio in den Cloud Storage-Bucket exportiert wird. Ändern Sie dies nur, wenn Sie einen anderen Namen als die vorgeschlagenen Namen für extrahierte Dateien ausgewählt haben. |
partition_details
|
Wie die Rohdatentabelle aus Leistungsgründen partitioniert wird. Weitere Informationen finden Sie unter Tabellenpartition. |
cluster_details
|
Optional:Wenn die Rohdatentabelle aus Leistungsgründen geclustert werden soll. Weitere Informationen finden Sie unter Clustereinstellungen. |
Rohdaten- in CDC-Tabellen
In diesem Abschnitt wird beschrieben, welche Einträge steuern, wie Daten aus Rohdatentabellen in CDC-Tabellen verschoben werden. Jeder Eintrag entspricht einer Rohdatentabelle.
Die folgenden Parameter steuern die Einstellungen für Raw to CDC für jeden Eintrag:
| Parameter | Beschreibung |
base_table
|
Tabelle im CDC-Dataset, in der die Rohdaten nach der CDC-Transformation gespeichert werden. |
load_frequency
|
Wie oft ein DAG für diese Einheit ausgeführt wird, um die CDC-Tabelle zu füllen. Weitere Informationen zu möglichen Werten finden Sie in der Airflow-Dokumentation. |
raw_table
|
Quelltabelle aus dem Rohdatensatz. |
row_identifiers
|
Spalten (durch Komma getrennt), die einen eindeutigen Datensatz für diese Tabelle bilden. |
partition_details
|
Wie die CDC-Tabelle aus Leistungsgründen partitioniert wird. Weitere Informationen finden Sie unter Tabellenpartition. |
cluster_details
|
Optional:Wenn Sie möchten, dass diese Tabelle aus Leistungsgründen gruppiert wird. Weitere Informationen finden Sie unter Clustereinstellungen. |
Berichtseinstellungen
Sie können konfigurieren und steuern, wie das Cortex Framework Daten für die letzte SFMC-Berichtsebene generiert. Dazu verwenden Sie die Datei mit den Berichtseinstellungen (src/SFMC/config/reporting_settings.yaml). Mit dieser Datei wird gesteuert, wie BigQuery-Objekte der Berichtsebene (Tabellen, Ansichten, Funktionen oder gespeicherte Verfahren) generiert werden.
Weitere Informationen finden Sie unter Datei mit Berichtseinstellungen anpassen.
Nächste Schritte
- Weitere Informationen zu anderen Datenquellen und Arbeitslasten finden Sie unter Datenquellen und Arbeitslasten.
- Weitere Informationen zu den Schritten für die Bereitstellung in Produktionsumgebungen finden Sie unter Voraussetzungen für die Bereitstellung der Cortex Framework Data Foundation.