
與 SAP 整合
本頁面說明如何整合 Cortex Framework 資料基礎中的 SAP 作業工作負載 (SAP ECC 和 SAP S/4 HANA)。Cortex Framework 可透過 Dataflow 管道,使用預先定義的資料處理範本,加快 SAP 資料與 BigQuery 的整合速度,而 Managed Service for Apache Airflow 則會排定及監控這些 Dataflow 管道,從 SAP 營運資料取得洞察資訊。
Cortex Framework Data Foundation 存放區中的 config.json 檔案會設定從任何資料來源 (包括 SAP) 移轉資料所需的設定。這個檔案包含下列作業 SAP 工作負載的參數:
"SAP": {
"deployCDC": true,
"datasets": {
"cdc": "",
"raw": "",
"reporting": "REPORTING"
},
"SQLFlavor": "ecc",
"mandt": "100"
}
下表說明各項 SAP 作業參數的值:
| 參數 | 意義 | 預設值 | 說明 |
SAP.deployCDC
|
部署 CDC | true
|
產生 CDC 處理指令碼,在 Managed Airflow 中以 DAG 形式執行。 |
SAP.datasets.raw
|
原始登陸資料集 | - | 這是 CDC 程序使用的位置,複製工具會將 SAP 的資料放在這裡。如要使用測試資料,請建立空白資料集。 |
SAP.datasets.cdc
|
CDC 處理的資料集 | - | 這個資料集可做為報表檢視畫面的來源,以及記錄處理 DAG 的目標。如要使用測試資料,請建立空白資料集。 |
SAP.datasets.reporting
|
報表資料集 SAP | "REPORTING"
|
使用者可存取並用於報表的資料集名稱,其中部署了檢視區塊和面向使用者的資料表。 |
SAP.SQLFlavor
|
來源系統的 SQL 類型 | "ecc"
|
s4 或 ecc。
測試資料請保留預設值 (ecc)。
|
SAP.mandt
|
Mandant 或 Client | "100"
|
SAP 的預設 mandant 或用戶端。
測試資料請保留預設值 (100)。
|
SAP.languages
|
語言篩選器 | ["E","S"]
|
用於相關欄位 (例如名稱) 的 SAP 語言代碼 (SPRAS)。 |
SAP.currencies
|
幣別篩選器 | ["USD"]
|
貨幣換算的 SAP 目標貨幣代碼 (TCURR)。 |
雖然沒有最低 SAP 版本要求,但 ECC 模型是在目前最早支援的 SAP ECC 版本上開發。無論版本為何,本系統與其他系統的欄位差異都是預期會發生的情況。
資料模型
本節將說明使用實體關係圖 (ERD) 的 SAP (ECC 和 S/4 HANA) 資料模型。
SAP ECC

SAP S/4 HANA
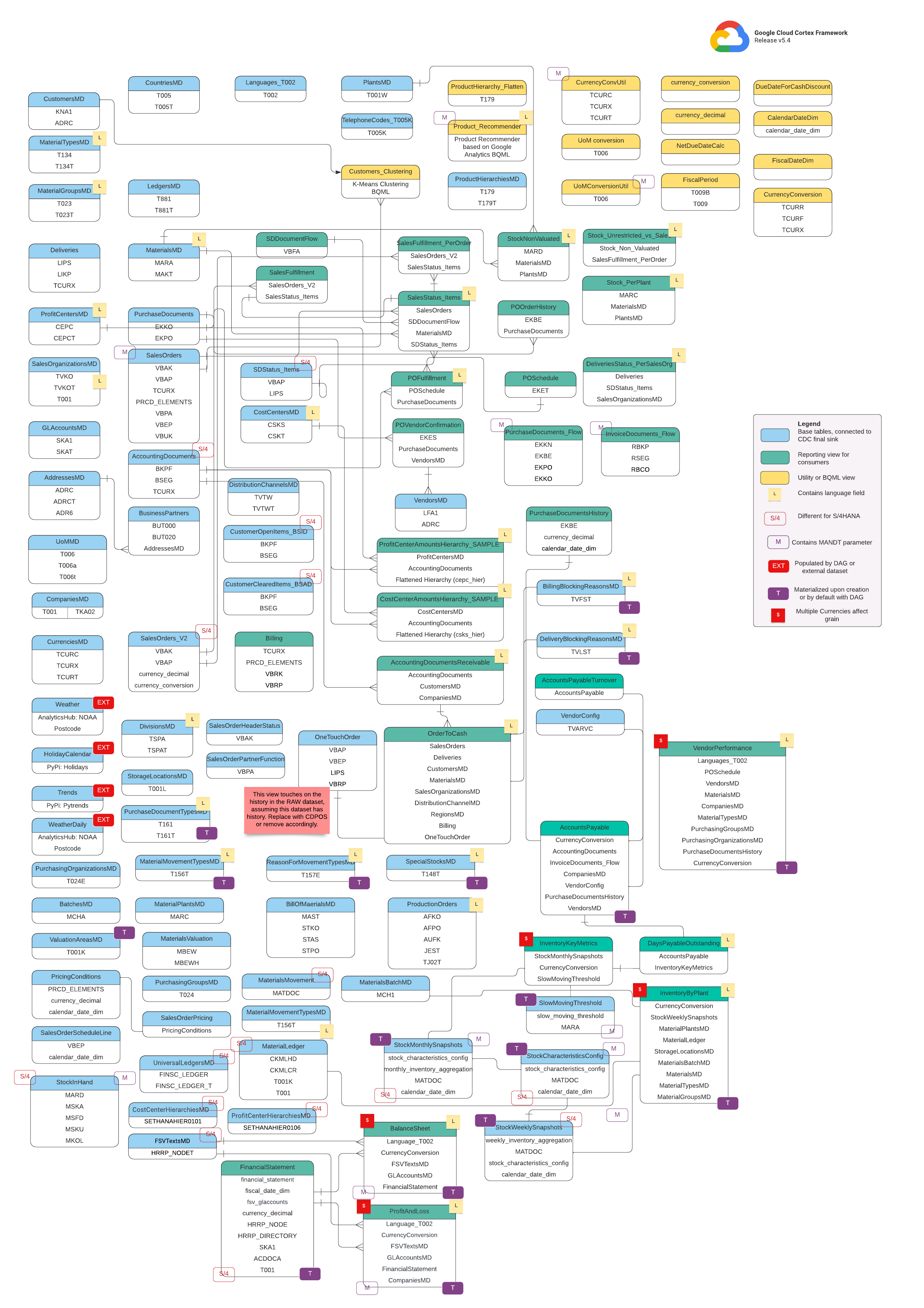
基本檢視
這些是 ERD 中的藍色物件,也是 CDC 資料表上的檢視畫面,除了部分資料欄名稱別名外,沒有任何轉換。請參閱src/SAP/SAP_REPORTING中的指令碼。
報表資料檢視
這些是 ERD 中的綠色物件,包含報表資料表使用的相關維度屬性。請參閱src/SAP/SAP_REPORTING中的指令碼。
公用程式或 BQML 檢視畫面
這些是 ERD 中的黃色物件,包含用於資料分析和報表的特定檢視類型所彙整的事實和維度。請參閱src/SAP/SAP_REPORTING上的指令碼。
其他標記
這個 ERD 上的顏色編碼標記代表報表資料表的下列功能:
| 標記 | 顏色 | 說明 |
L
|
黃色 | 這個標記是指資料元素或屬性,用於指定資料儲存或顯示的語言。 |
S/4
|
紅色 | 這個標記表示特定屬性是 SAP S/4 HANA 特有 (這個物件可能不在 SAP ECC 中)。 |
MANDT
|
紫色 | 這個標記表示特定屬性含有 MANDT 參數 (代表用戶端或用戶端 ID),可判斷特定資料記錄所屬的用戶端或公司例項。 |
EXT
|
紅色 | 這個標記表示特定物件是由 DAG 或外部資料集填入。這表示標記的實體或表格不會直接儲存在 SAP 系統中,但可以使用 DAG 或其他機制擷取並載入 SAP。 |
T
|
紫色 | 這個標記表示系統會使用設定的 DAG 自動具體化特定屬性。 |
S
|
紅色 | 這個標記表示實體或表格中的資料受到多種幣別影響。 |
SAP 複製作業的必要條件
使用 Cortex Framework 資料基礎複製 SAP 資料時,請注意下列必要條件:
- 資料完整性:Cortex Framework 資料基礎會複製 SAP 資料表,並確保欄位名稱、類型和資料結構與 SAP 中的完全相同。只要資料表是以與來源相同的格式、欄位名稱和細微程度複製,就不需要使用特定複製工具。
- 資料表命名:BigQuery 資料表名稱必須以小寫字母建立。
- 資料表設定:SAP 模型使用的資料表清單可在 CDC (變更資料擷取)
cdc_settings.yaml檔案中查看及設定。如果部署期間未列出某個表格,則取決於該表格的模型會失敗,但其他不相依的模型會成功部署。 - 特定注意事項:BigQuery Connector for SAP:
- 表格對應:如要瞭解轉換選項,請參閱預設表格對應說明文件。
- 停用記錄壓縮:我們建議停用 記錄壓縮,這可能會影響 Cortex CDC 層和 Cortex 報表資料集。
- 中繼資料複製:如果您未在部署期間部署測試資料並產生 CDC DAG 指令碼,請確保 SAP 中繼資料的資料表
DD03L已從來源專案中的 SAP 複製。這個資料表包含資料表的中繼資料,例如鍵清單,是 CDC 產生器和依附元件解析器運作時的必要條件。您也可以透過這個表格新增模型未涵蓋的資料表 (例如自訂資料表或 Z 資料表),以便產生 CDC 指令碼。 處理資料表名稱的微小差異:如果資料表名稱有微小差異,部分檢視畫面可能無法找到必要欄位,因為 SAP 系統可能因版本或外掛程式而有微小差異,或某些複製工具處理特殊字元的方式略有不同。建議您使用
turboMode : false執行部署作業,一次找出最多失敗項目。常見問題包括:- 開頭為
_的欄位 (例如_DATAAGING) 會移除_。 - BigQuery 中的欄位開頭不得為
/。請務必更新 CDC 指令碼產生程式碼,與複製設定保持一致。
在這種情況下,您可以調整失敗的檢視畫面,選取所選複製工具登陸的欄位。
- 開頭為
複製 SAP 的原始資料
資料基礎的目的是公開資料和分析模型,以供報表和應用程式使用。模型會使用偏好的複製工具 (例如 SAP 資料整合指南中列出的工具),從 SAP 系統複製資料。
SAP 系統 (ECC 或 S/4 HANA) 的資料會以原始形式複製。資料會直接從 SAP 複製到 BigQuery,結構不會有任何變更。這基本上是 SAP 系統中資料表的鏡像。BigQuery 的資料模型會使用小寫的資料表名稱。因此,即使 SAP 資料表可能使用大寫名稱 (例如 MANDT),在 BigQuery 中也會轉換為小寫 (例如 mandt)。
變更資料擷取 (CDC) 處理
選擇下列其中一種 CDC 處理模式,Cortex Framework 會提供給複製工具,從 SAP 載入記錄:
- 一律附加:在記錄中插入每個變更,並附上時間戳記和作業旗標 (插入、更新、刪除),以便識別最後一個版本。
- 更新到達網頁 (合併或 upsert):在
change data capture processed中建立到達網頁的更新版記錄。並在 BigQuery 中執行 CDC 作業。
Cortex Framework Data Foundation 支援這兩種模式,但對於一律附加的模式,系統會提供 CDC 處理範本。部分功能需要註解,才能在登陸頁面更新。例如 OneTouchOrder.sql 和所有依附查詢。這項功能可以由 CDPOS 等資料表取代。

為以「一律附加」模式複製的工具設定 CDC 範本
強烈建議您根據需求設定 cdc_settings.yaml。
如果商家不需要這麼新的資料,某些預設頻率可能會導致不必要的費用。如果使用以「一律附加」模式執行的工具,Cortex Framework Data Foundation 會提供 CDC 範本,自動更新並在 CDC 處理的資料集中建立最新版本的實況或數位孿生。
如需產生 CDC 處理指令碼,可以使用 cdc_settings.yaml 檔案中的設定。如需相關選項,請參閱「設定 CDC 處理程序」。如果是測試資料,您可以將這個檔案保留為預設值。
根據 Airflow 或 Managed Airflow 執行個體,對 DAG 範本進行所有必要變更。詳情請參閱「收集 Managed Airflow 設定」。
選用:如要在部署後個別新增及處理資料表,可以修改 cdc_settings.yaml 檔案,只處理所需的資料表,然後直接重新執行指定的模組呼叫 src/SAP_CDC/cloudbuild.cdc.yaml。
設定 CDC 處理程序
部署期間,您可以選擇使用 BigQuery 中的檢視畫面即時合併變更,或在 Managed Airflow (或任何其他 Apache Airflow 執行個體) 中排定合併作業。Managed Airflow 可以排定腳本,定期處理合併作業。每次執行合併作業時,資料都會更新至最新版本,但合併作業越頻繁,費用就越高。根據業務需求自訂排定頻率。詳情請參閱 Apache Airflow 支援的排程。
以下範例指令碼顯示設定檔的摘錄內容:
data_to_replicate:
- base_table: adrc
load_frequency: "@hourly"
- base_table: adr6
target_table: adr6_cdc
load_frequency: "@daily"
這個設定範例檔案會執行下列作業:
- 如果
TARGET_PROJECT_ID.DATASET_WITH_LATEST_RECORDS.adrc不存在,請從SOURCE_PROJECT_ID.REPLICATED_DATASET.adrc建立副本到TARGET_PROJECT_ID.DATASET_WITH_LATEST_RECORDS.adrc。 - 在指定 bucket 中建立 CDC 指令碼。
- 如果
TARGET_PROJECT_ID.DATASET_WITH_LATEST_RECORDS.adr6_cdc不存在,請從SOURCE_PROJECT_ID.REPLICATED_DATASET.adr6建立副本到TARGET_PROJECT_ID.DATASET_WITH_LATEST_RECORDS.adr6_cdc。 - 在指定 bucket 中建立 CDC 指令碼。
如要建立 DAG 或執行階段檢視畫面,處理 SAP 中現有但未列於檔案中的表格變更,請在部署前將這些表格新增至這個檔案。只要資料表 DD03L 複製到來源資料集,且自訂資料表的結構定義位於該資料表中,這項功能就能正常運作。舉例來說,下列設定會為自訂資料表 zztable_customer 建立 CDC 指令碼,並建立執行階段檢視畫面,即時掃描另一個名為 zzspecial_table 的自訂資料表中的變更:
- base_table: zztable_customer
load_frequency: "@daily"
- base_table: zzspecial_table
load_frequency: "RUNTIME"
生成的範本範例
下列範本會產生變更的處理程序。您可以在這個時間點修改時間戳記欄位名稱等項目,或進行其他作業:
MERGE `${target_table}` T
USING (
SELECT *
FROM `${base_table}`
WHERE
recordstamp > (
SELECT IF(
MAX(recordstamp) IS NOT NULL,
MAX(recordstamp),
TIMESTAMP("1940-12-25 05:30:00+00"))
FROM `${target_table}` )
) S
ON ${p_key}
WHEN MATCHED AND S.operation_flag='D' AND S.is_deleted = true THEN
DELETE
WHEN NOT MATCHED AND S.operation_flag='I' THEN
INSERT (${fields})
VALUES
(${fields})
WHEN MATCHED AND S.operation_flag='U' THEN
UPDATE SET
${update_fields}
或者,如果您的業務需要近乎即時的洞察資料,且複製工具支援這項功能,部署工具就會接受 RUNTIME 選項。也就是說,系統不會產生 CDC 指令碼。而是會在執行階段掃描並擷取最新的可用記錄,以確保立即一致性。
CDC DAG 和指令碼的目錄結構
SAP CDC DAG 的 Cloud Storage bucket 結構會預期在 /data/bq_data_replication 中產生 SQL 檔案,如下列範例所示。您可以在部署前修改這個路徑。如果您還沒有 Managed Service for Apache Airflow 環境,可以稍後再建立,然後將檔案移至 DAG 儲存空間。
with airflow.DAG("CDC_BigQuery_${base table}",
template_searchpath=['/home/airflow/gcs/data/bq_data_replication/'], ##example
default_args=default_dag_args,
schedule_interval="${load_frequency}") as dag:
start_task = DummyOperator(task_id="start")
copy_records = BigQueryOperator(
task_id='merge_query_records',
sql="${query_file}",
create_disposition='CREATE_IF_NEEDED',
bigquery_conn_id="sap_cdc_bq", ## example
use_legacy_sql=False)
stop_task = DummyOperator (task_id="stop")
start_task >> copy_records >> stop_task
在 Airflow 或 Managed Service for Apache Airflow 中處理資料的指令碼,是刻意與 Airflow 專屬指令碼分開產生。這樣您就能將這些指令碼匯入其他工具。
MERGE 作業所需的 CDC 欄位
指定下列參數,自動產生 CDC 批次程序:
- 來源專案 + 資料集:SAP 資料串流或複製的資料集。如要讓 CDC 指令碼預設運作,資料表必須具備時間戳記欄位 (稱為 recordstamp) 和作業欄位,且這些欄位在複製期間都設有下列值:
- I:插入。
- U:代表更新。
- D:刪除。
- 用於 CDC 處理的目標專案 + 資料集:如果預設產生的指令碼不存在,就會從來源資料集副本產生資料表。
- 複製的資料表:需要產生指令碼的資料表
- 處理頻率:按照 Cron 標記,預期 DAG 的執行頻率:
- 目標 Cloud Storage bucket,用於複製 CDC 輸出檔案。
- 連線名稱:Managed Airflow 使用的連線名稱。
- (選用) 目標資料表名稱:如果 CDC 處理結果與目標位於相同資料集,則可使用此選項。
CDC 資料表的效能最佳化
對於某些 CDC 資料集,您可能想利用 BigQuery 資料表分區、資料表分群或兩者。選擇取決於下列因素:
- 資料表的大小和資料。
- 表格中可用的資料欄。
- 需要提供檢視畫面中的即時資料。
- 具體化為資料表的資料。
根據預設,CDC 設定不會套用資料表分區或資料表叢集。你可以根據自己的需求設定。如要建立含有資料分割或叢集的資料表,請使用相關設定更新 cdc_settings.yaml 檔案。詳情請參閱「資料表分區」和「叢集設定」。
- 只有在
cdc_settings.yaml中的資料集設定為以資料表 (例如load_frequency = "@daily") 形式複製時,這項功能才適用,如果定義為檢視畫面 (load_frequency = "RUNTIME"),則不適用。 - 資料表可以同時是分區資料表和分群資料表。
如果您使用的複製工具允許原始資料集中的分區 (例如 BigQuery Connector for SAP),建議在原始資料表中設定以時間為準的分區。如果分割區類型與 cdc_settings.yaml 設定中的 CDC DAG 頻率相符,效果會更好。詳情請參閱「在 BigQuery 中進行 SAP 資料模型的設計考量」。
選用:設定 SAP 庫存模組
Cortex Framework SAP 庫存模組包含 InventoryKeyMetrics 和 InventoryByPlant 檢視畫面,可提供庫存的重要洞察資料。這些檢視畫面會使用專門的 DAG,以每月和每週的快照資料表為基礎。兩者可以同時執行,不會互相干擾。
如要更新任一或兩個快照資料表,請按照下列步驟操作:
根據需求更新
SlowMovingThreshold.sql和StockCharacteristicsConfig.sql,為不同物料類型定義滯銷門檻和庫存特徵。如要進行初始載入或完整重新整理,請執行
Stock_Monthly_Snapshots_Initial和Stock_Weekly_Snapshots_InitialDAG。如要後續重新整理,請排定或執行下列 DAG:
- 每月和每週更新:
Stock_Monthly_Snapshots_Periodical_UpdateStock_Weekly_Snapshots_periodical_Update
- 每日更新:
Stock_Monthly_Snapshots_Daily_UpdateStock_Weekly_Snapshots_Update_Daily
- 每月和每週更新:
依序重新整理中繼
StockMonthlySnapshots和StockWeeklySnapshots檢視畫面,然後是InventoryKeyMetrics和InventoryByPlants檢視畫面,即可顯示重新整理的資料。
選用:設定「產品階層文字」檢視畫面
「產品階層文字」檢視畫面會將素材資源及其產品階層攤平。產生的資料表可用於提供 Trends 外掛程式字詞清單,以擷取「隨時間變化的興趣」。如要設定這個檢視畫面,請按照下列步驟操作:
- 在
## CORTEX-CUSTOMER的標記下方,調整prod_hierarchy_texts.sql檔案中的階層和語言。 如果產品階層包含更多層級,您可能需要新增類似於通用資料表運算式的 SELECT 陳述式。
h1_h2_h3視來源系統而定,可能還會有其他自訂項目。建議您在流程初期就讓業務使用者或分析師參與,協助找出這些問題。
選用:設定階層壓平檢視畫面
自 v6.0起,Cortex Framework 支援將階層結構扁平化為報表檢視畫面。這項工具會取代舊版階層結構平坦化工具,是重大改良措施,因為現在會平坦化整個階層結構,並利用 S/4 專屬資料表 (而非舊版 ECC 資料表) 進行最佳化,還能大幅提升效能。
報表資料檢視摘要
找出與階層壓平合併相關的下列檢視畫面:
| 階層類型 | 僅含扁平化階層的表格 | 用於視覺化壓平合併階層的檢視畫面 | 使用這個階層的損益整合邏輯 |
| 財務報表版本 (FSV) | fsv_glaccounts
|
FSVHierarchyFlattened
|
ProfitAndLossOverview
|
| 利潤中心 | profit_centers
|
ProfitCenterHierarchyFlattened
|
ProfitAndLossOverview_ProfitCenterHierarchy
|
| 成本中心 | cost_centers
|
CostCenterHierarchyFlattened
|
ProfitAndLossOverview_CostCenterHierarchy
|
使用階層壓平檢視畫面時,請注意下列事項:
- 壓平合併階層檢視區塊在功能上等同於舊版階層壓平合併解決方案產生的表格。
- 總覽檢視畫面預設不會部署,因為這些畫面僅用於展示 BI 邏輯。您可以在
src/SAP/SAP_REPORTING目錄下找到這些檔案的原始碼。
設定階層壓平合併
根據您使用的階層,需要下列輸入參數:
| 階層類型 | 必要參數 | 來源欄位 (ECC) | 來源欄位 (S4) |
| 財務報表版本 (FSV) | 科目表 | ktopl
|
nodecls
|
| 階層名稱 | versn
|
hryid
|
|
| 利潤中心 | 集合的類別 | setclass
|
setclass
|
| 機構單位:控制範圍或設定的其他金鑰。 | subclass
|
subclass
|
|
| 成本中心 | 集合的類別 | setclass
|
setclass
|
| 機構單位:控制範圍或設定的其他金鑰。 | subclass
|
subclass
|
如果不確定確切的參數,請諮詢財務或控制 SAP 顧問。
收集參數後,請根據需求更新每個對應目錄中的 ## CORTEX-CUSTOMER 註解:
| 階層類型 | 程式碼位置 |
| 財務報表版本 (FSV) | src/SAP/SAP_REPORTING/local_k9/fsv_hierarchy
|
| 利潤中心 | src/SAP/SAP_REPORTING/local_k9/profitcenter_hierarchy
|
| 成本中心 | src/SAP/SAP_REPORTING/local_k9/costcenter_hierarchy
|
如適用,請務必更新 src/SAP/SAP_REPORTING 目錄井下相關報表檢視畫面中的## CORTEX-CUSTOMER註解。
解決方案詳細資料
階層扁平化會使用下列來源資料表:
| 階層類型 | 來源資料表 (ECC) | 來源資料表 (S4) |
| 財務報表版本 (FSV) |
|
|
| 利潤中心 |
|
|
| 成本中心 |
|
|
將階層視覺化
Cortex 的 SAP 階層結構平坦化解決方案會將整個階層結構平坦化。如要建立載入階層的視覺化表示,與 SAP 在 UI 中顯示的內容相較,請查詢檢視畫面,以視覺化呈現扁平化階層,並使用 IsLeafNode=True 條件。
從舊版階層壓平合併解決方案遷移
如要從 Cortex 6.0 版之前的舊版階層扁平化解決方案遷移,請按照下表所示替換資料表。請務必檢查欄位名稱是否正確,因為部分欄位名稱已稍做修改。舉例來說,cepc_hier 中的 prctr 現在是 profit_centers 表格中的 profitcenter。
| 階層類型 | 取代這個表格: | 參加者: |
| 財務報表版本 (FSV) | ska1_hier
|
fsv_glaccounts
|
| 利潤中心 | cepc_hier
|
profit_centers
|
| 成本中心 | csks_hier
|
cost_centers
|
選用:設定 SAP 財務模組
Cortex Framework SAP Finance 模組包含 FinancialStatement、BalanceSheet 和 ProfitAndLoss 檢視畫面,可提供重要的財務洞察資訊。
如要更新這些財務資料表,請按照下列步驟操作:
初始載入
- 部署完成後,請確保 CDC 資料集已正確填入資料 (視需要執行任何 CDC DAG)。
- 請確認您使用的階層類型 (FSV、成本中心和利潤中心) 已正確設定階層扁平化檢視畫面。
執行
financial_statement_initial_loadDAG。如果以資料表形式部署 (建議),請依序執行對應的 DAG,以重新整理下列項目:
Financial_StatementsBalanceSheetsProfitAndLoss
定期更新
- 請確保已正確設定階層扁平化檢視畫面,並針對您使用的階層類型 (FSV、成本中心和利潤中心) 重新整理至最新狀態。
排定或執行
financial_statement_periodical_loadDAG。如果以資料表形式部署 (建議),請依序執行對應的 DAG,以重新整理下列項目:
Financial_StatementsBalanceSheetsProfitAndLoss
如要以視覺化方式呈現這些表格的資料,請參閱下列總覽檢視畫面:
ProfitAndLossOverview.sql(如果您使用 FSV 階層)。ProfitAndLossOverview_CostCenter.sql如果您使用成本中心階層。ProfitAndLossOverview_ProfitCenter.sql如果您使用利潤中心階層。
選用:啟用工作相依 DAG
Cortex Framework 可為大多數 SAP SQL 資料表 (ECC 和 S/4 HANA) 提供建議的依附元件設定,所有依附元件資料表都可以透過單一 DAG 更新。你還可以進一步自訂這些範本。詳情請參閱「工作依附 DAG」。
後續步驟
- 如要進一步瞭解其他資料來源和工作負載,請參閱「資料來源和工作負載」一文。
- 如要進一步瞭解在正式環境中部署的步驟,請參閱「Cortex Framework Data Foundation 部署作業的必要條件」。