
Intégration à Salesforce Marketing Cloud
Cette page décrit les configurations requises pour importer des données de Salesforce Marketing Cloud (SFMC) en tant que source de données de la charge de travail marketing de Cortex Framework Data Foundation.
SFMC est une plate-forme d'automatisation du marketing numérique proposée par Salesforce. Elle fournit aux entreprises une suite complète d'outils pour gérer et automatiser diverses activités marketing sur plusieurs canaux. Cortex Framework sert de moteur d'analyse de données et d'IA qui vous aide à comprendre les résultats, à identifier les points à améliorer et à optimiser votre stratégie marketing pour obtenir de meilleurs résultats.
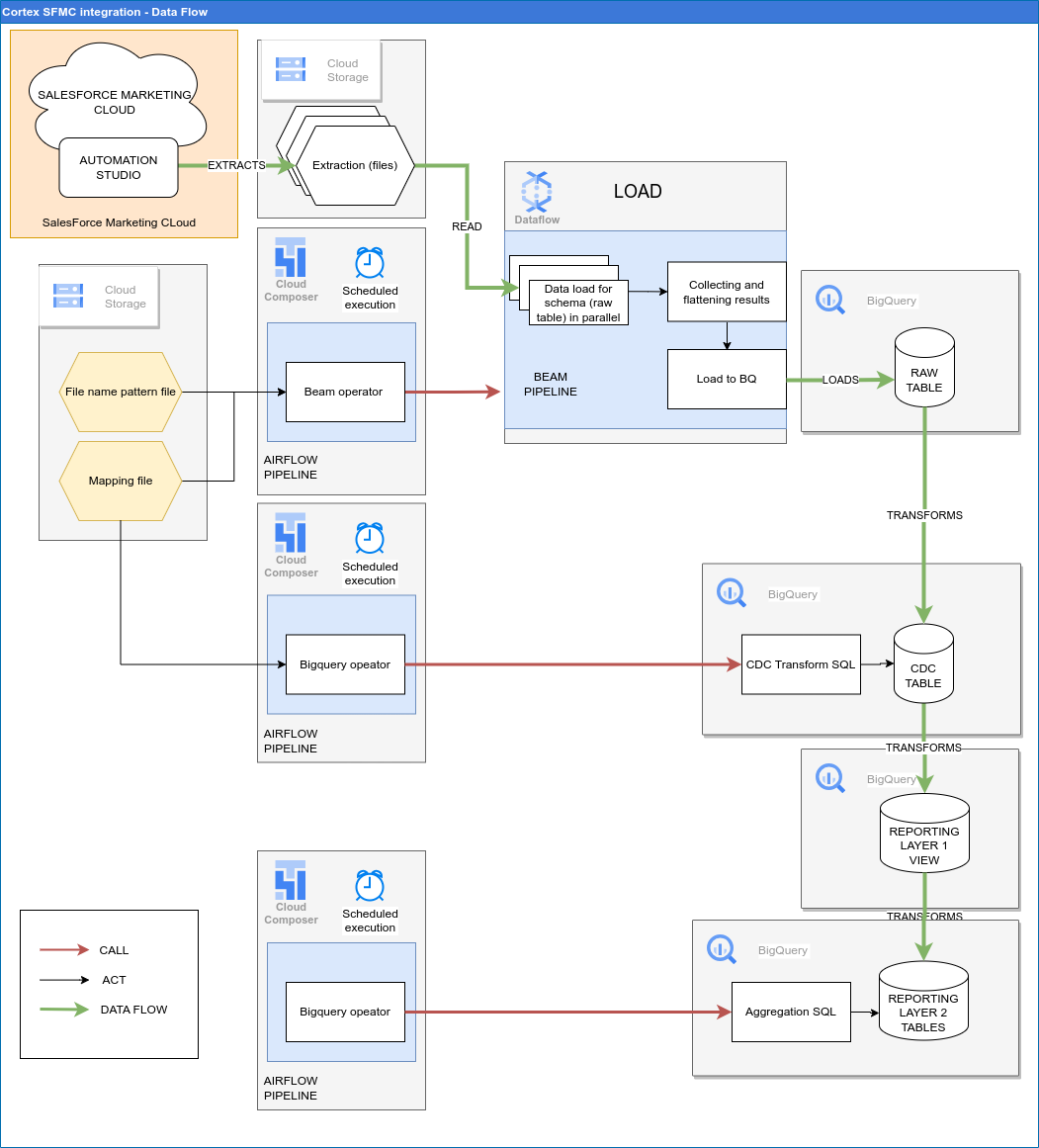
Le schéma suivant décrit comment les données SFMC sont disponibles via la charge de travail marketing de Cortex Framework Data Foundation :
Fichier de configuration
Le fichier config.json configure les paramètres requis pour se connecter aux sources de données afin de transférer
des données à partir de différentes charges de travail. Ce fichier contient les paramètres suivants pour SFMC :
"marketing": {
"deploySFMC": true,
"SFMC": {
"deployCDC": true,
"fileTransferBucket": "",
"datasets": {
"cdc": "",
"raw": "",
"reporting": "REPORTING_SFMC"
}
}
}
Le tableau suivant décrit la valeur de chaque paramètre marketing :
| Paramètre | Signification | Valeur par défaut | Description |
marketing.deploySFMC
|
Déployer SFMC | true
|
Exécutez le déploiement pour la source de données SFMC. |
marketing.SFMC.deployCDC
|
Déployer des scripts CDC pour SFMC | true
|
Générez des scripts de traitement CDC Salesforce Marketing Cloud (SFMC) à exécuter en tant que DAG dans Managed Airflow. |
marketing.SFMC.fileTransferBucket
|
Bucket avec des fichiers d'extraction de données | - | Bucket dans lequel sont stockés les fichiers d'extraction de données Salesforce Marketing Cloud (SFMC) Automation Studio. |
marketing.SFMC.datasets.cdc
|
Ensemble de données CDC pour SFMC | Ensemble de données CDC pour Salesforce Marketing Cloud (SFMC). | |
marketing.SFMC.datasets.raw
|
Ensemble de données brutes pour SFMC | Ensemble de données brutes pour Salesforce Marketing Cloud (SFMC). | |
marketing.SFMC.datasets.reporting
|
Ensemble de données de reporting pour SFMC | "REPORTING_SFMC"
|
Ensemble de données de reporting pour Salesforce Marketing Cloud (SFMC). |
Modèle de données
Cette section décrit le modèle de données Salesforce Marketing Cloud (SFMC) à l'aide du diagramme entité-association.

Vues de base
Il s'agit des objets bleus du diagramme entité-association. Ce sont des vues sur les tables CDC sans transformation autre que certains alias de noms de colonnes. Consultez les scripts dans
src/marketing/src/SFMC/src/reporting/ddls.
Vues de rapports
Il s'agit des objets verts du diagramme entité-association. Ce sont des vues de rapports qui contiennent des métriques agrégées. Consultez les scripts dans
src/marketing/src/SFMC/src/reporting/ddls.
Extraction de données à l'aide d'Automation Studio
SFMC Automation Studio permet aux consommateurs de SFMC d'exporter leurs données SFMC vers différents systèmes de stockage. Cortex Framework Data Foundation recherche un ensemble de fichiers créés avec Automation Studio dans un bucket Cloud Storage. Vous devez également utiliser SFMC Email Studio dans ce processus.
Pour configurer les processus d'extraction et d'exportation de données, procédez comme suit :
- Configurez un bucket Cloud Storage. Ce bucket stocke les fichiers exportés depuis SFMC. Nommez le paramètre de configuration du bucket
marketing.SFMC.fileTransferBucket. Consultez les instructions de la documentation Salesforce. Créez des extensions de données. Pour chaque entité pour laquelle vous souhaitez extraire des données, créez une extension de données dans Email Studio. Cela est nécessaire pour identifier les sources de données à partir de la base de données interne SFMC.
- Répertoriez tous les champs définis dans
src/SFMC/config/table_schemapour l'entité. Si vous devez personnaliser cette liste pour extraire plus ou moins de champs, assurez-vous que la liste des champs est alignée dans ces étapes ainsi que dans les fichiers de schéma de table. Exemple :
Entity: unsubscribe Fields: AccountID OYBAccountID JobID ListID BatchID SubscriberID SubscriberKey EventDate IsUnique Domain- Répertoriez tous les champs définis dans
Créez des activités de requête SQL. Pour chaque entité, créez une activité de requête SQL. Cette activité est connectée à l'extension de données correspondante créée précédemment. Consultez la documentation Salesforce pour cette étape :
- Définissez une requête SQL avec tous les champs pertinents. La requête doit sélectionner tous les champs pertinents pour l'entité définie dans l'extension de données à l'étape précédente.
- Sélectionnez l'extension de données appropriée comme cible.
- Sélectionnez Écraser comme action sur les données.
- Consultez l'exemple de requête suivant :
SELECT AccountID, OYBAccountID, JobID, ListID, BatchID, SubscriberID, SubscriberKey, EventDate, IsUnique, Domain FROM _UnsubscribeCréez des activités d'extraction de données. Consultez la documentation Salesforce pour créer une activité d'extraction de données pour chaque entité. Cette activité récupère les données de l'extension de données Salesforce et les extrait dans un fichier CSV. Pour cette étape :
- Utilisez le modèle de nommage approprié. Il doit correspondre au modèle défini dans les
paramètres.
Par exemple, pour l'entité
Unsubscribe, le nom de fichier peut être quelque chose commeunsubscribe_%%Year%%_%%Month%%_%%Day%% %%Hour%%.csv. - Définissez Extract Type (Type d'extraction) sur
Data Extension Extract. - Sélectionnez les options Has column Headers (Comporte des en-têtes de colonne) et Text Qualified (Texte qualifié).
- Utilisez le modèle de nommage approprié. Il doit correspondre au modèle défini dans les
paramètres.
Par exemple, pour l'entité
Créez des activités de conversion de fichiers pour convertir le format UTF-16 en UTF-8. Par défaut, Salesforce exporte les fichiers CSV au format UTF-16. Au cours de cette étape, vous le convertissez au format UTF-8. Pour chaque entité, créez une autre activité d'extraction de données, pour la conversion de fichiers. Pour cette étape :
- Utilisez le même modèle de nom de fichier que celui utilisé à l'étape précédente de l'activité d'extraction de données.
- Définissez Extract Type (Type d'extraction) sur
File Convert. - Sélectionnez
UTF8dans le menu déroulantConvert To(Convertir en).
Créez des activités de transfert de fichiers. Créez une activité de transfert de fichiers pour chaque entité. Ces activités déplacent les fichiers CSV extraits du Safehouse Salesforce vers des buckets Cloud Storage. Pour cette étape :
- Utilisez le même modèle de nom de fichier que celui utilisé lors des étapes précédentes.
- Sélectionnez un bucket Cloud Storage configuré précédemment dans le processus comme destination.
Planifiez l'exécution. Une fois toutes les activités terminées, configurez des planifications automatisées pour les exécuter.
Fraîcheur et délai des données
En règle générale, la fraîcheur des données pour les sources de données Cortex Framework est limitée par ce que la connexion en amont autorise, ainsi que par la fréquence d'exécution de votre DAG. Ajustez la fréquence d'exécution de votre DAG pour l'aligner sur la fréquence en amont, les contraintes de ressources et vos besoins commerciaux.
Avec SFMC Automation Studio, le délai de fraîcheur des données dépend du délai de planification lorsque l'exportation de données est configurée.
Autorisations de connexion Managed Service pour Apache Airflow
Créez les connexions suivantes dans Managed Airflow. Pour en savoir plus, consultez la documentation Gérer les connexions Airflow.
| Nom de la connexion | Purpose |
sfmc_raw_dataflow
|
Pour les fichiers extraits SFMC > ensemble de données BigQueryRaw. |
sfmc_cdc_bq
|
Pour l'ensemble de données brutes > transfert de l'ensemble de données CDC. |
sfmc_reporting_bq
|
Pour l'ensemble de données CDC > transfert de l'ensemble de données de reporting. |
Autorisations du compte de service Managed Airflow
Le compte de service utilisé dans Managed Airflow (tel que configuré dans la connexion sfmc_raw_dataflow) a besoin d'autorisations liées à Dataflow.
Consultez les instructions de la documentation Dataflow.
Paramètres d'ingestion
Contrôlez les pipelines de données Source to Raw et Raw to CDC via les paramètres
du fichier src/SFMC/config/ingestion_settings.yaml .
Cette section décrit les paramètres de chaque pipeline de données.
Source vers les tables brutes
Cette section contient des entrées qui contrôlent l'utilisation des fichiers extraits d'Automation Studio. Chaque entrée correspond à une entité SFMC. En fonction de cette configuration, Cortex Framework crée des DAG Airflow qui exécutent des pipelines Dataflow pour charger des données à partir de fichiers exportés dans des tables BigQuery dans l'ensemble de données brutes.
Le répertoire src/SFMC/config/table_schema contient un fichier de schéma pour chaque entité extraite de SFMC. Chaque fichier explique comment lire les fichiers CSV extraits d'Automaton Studio afin de les charger correctement dans l'ensemble de données BigQueryraw.
Chaque fichier de schéma contient trois colonnes :
SourceField: nom de champ du fichier CSV.TargetField: nom de colonne dans la table brute pour cette entité.DataType: type de données de chaque champ de table brute.
Les paramètres suivants contrôlent les paramètres de Source to Raw pour chaque entrée :
| Paramètre | Description |
base_table
|
Nom de la table brute dans laquelle les données extraites d'une entité SFMC sont chargées. |
load_frequency
|
Fréquence à laquelle un DAG pour cette entité s'exécute pour charger des données à partir de fichiers extraits. Pour en savoir plus sur les valeurs possibles, consultez la documentation Airflow. |
file_pattern
|
Modèle de fichier pour cette table exportée d'Automation Studio vers un bucket Cloud Storage. Ne modifiez cette valeur que si vous avez choisi un nom différent de ceux suggérés pour les fichiers extraits. |
partition_details
|
Mode de partitionnement de la table brute pour des raisons de performances. Pour en savoir plus, consultez la section Partitionnement des tables. |
cluster_details
|
Facultatif : si vous souhaitez que la table brute soit en cluster pour des raisons de performances. Pour en savoir plus, consultez Paramètres de cluster. |
Tables brutes vers CDC
Cette section décrit les entrées qui contrôlent le déplacement des données des tables brutes vers les tables CDC. Chaque entrée correspond à une table brute.
Les paramètres suivants contrôlent les paramètres de Raw to CDC pour chaque entrée :
| Paramètre | Description |
base_table
|
Table de l'ensemble de données CDC dans laquelle sont stockées les données brutes après la transformation CDC. |
load_frequency
|
Fréquence à laquelle un DAG pour cette entité s'exécute pour remplir la table CDC. Pour en savoir plus sur les valeurs possibles, consultez la documentation Airflow. |
raw_table
|
Table source de l'ensemble de données brutes. |
row_identifiers
|
Colonnes (séparées par une virgule) qui forment un enregistrement unique pour cette table. |
partition_details
|
Mode de partitionnement de la table CDC pour des raisons de performances. Pour en savoir plus, consultez la section Partitionnement des tables. |
cluster_details
|
Facultatif : si vous souhaitez que cette table soit en cluster pour des raisons de performances. Pour en savoir plus, consultez Paramètres de cluster. |
Paramètres de création de rapports
Vous pouvez configurer et contrôler la façon dont Cortex Framework génère des données pour la couche de reporting finale SFMC à l'aide du fichier de paramètres de reporting (src/SFMC/config/reporting_settings.yaml). Ce fichier contrôle la génération des objets BigQuery de la couche de reporting (tables, vues,fonctions ou procédures stockées).
Pour en savoir plus, consultez la section Personnaliser le fichier de paramètres de reporting.
Étape suivante
- Pour en savoir plus sur les autres sources de données et charges de travail, consultez la section Sources de données et charges de travail.
- Pour en savoir plus sur les étapes de déploiement dans les environnements de production, consultez la section Prérequis de déploiement de Cortex Framework Data Foundation.