
Les zones d'IA sont des zones spécialisées utilisées pour les charges de travail d'entraînement et d'inférence de l'intelligence artificielle et du machine learning (IA et ML). Elles offrent une capacité importante d'accélérateurs de ML (GPU et TPU).
Dans une région, les zones d'IA sont géographiquement éloignées des zones standards (non liées à l'IA). La figure suivante montre un exemple de zone d'IA (us-central1-ai1a) située plus loin par rapport aux zones standards de la région us-central1.
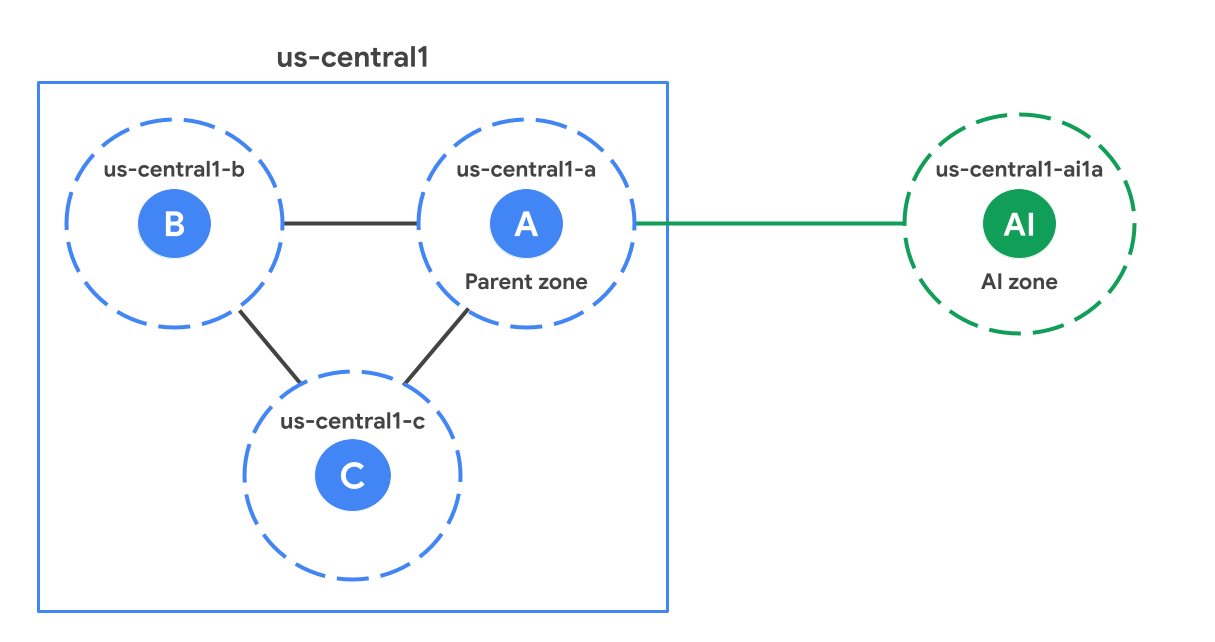
Espace parents
Chaque zone d'IA est associée à une zone standard de la région, appelée zone parente. Une zone parente est une zone standard avec le même suffixe que la zone d'IA. Par exemple, dans le diagramme, us-central1-a est la zone parente de us-central1-ai1a. Ils partagent les plannings de mise à jour logicielle et parfois l'infrastructure. Cela signifie que tout problème logiciel ou d'infrastructure affectant une zone parente peut également affecter la zone d'IA. Lorsque vous concevez vos solutions de haute disponibilité, consultez les points à prendre en compte pour la haute disponibilité afin de tenir compte de la dépendance vis-à-vis de la zone parente.
Quand utiliser les zones d'IA ?
Les zones d'IA sont optimisées pour les charges de travail d'IA et de ML. Suivez les conseils ci-dessous pour déterminer quelles charges de travail sont les mieux adaptées aux zones d'IA et lesquelles sont mieux adaptées aux zones standards.
Recommandé pour :
Entraînement à grande échelle : idéal pour les charges de travail d'entraînement à grande échelle, telles que l'entraînement de grands modèles de langage (LLM) et de modèles de fondation, en raison de la disponibilité d'un grand nombre d'accélérateurs.
Entraînement, affinage, inférence par lot et réentraînement à petite échelle : les zones d'IA sont performantes pour les charges de travail qui nécessitent une capacité d'accélérateur importante.
Inférence ML en temps réel : les zones d'IA sont compatibles avec les charges de travail d'inférence en temps réel. Les performances dépendent de la conception de l'application et des exigences de latence du modèle, en particulier si la charge de travail nécessite des requêtes aller-retour vers la région parente.
Il n'est pas recommandé pour :
- Charges de travail non liées au ML : comme les zones d'IA ne proposent pas tous les services Google Cloud localement, nous vous recommandons d'exécuter vos charges de travail non liées au ML dans les zones standards.
Accéder aux services depuis une zone d'IA
Vous pouvez accéder à tous les produits Google Cloud d'une région Google Cloud depuis sa zone d'IA. Toutefois, l'accès aux services d'une région Google Cloud à partir d'une zone d'IA peut ajouter de la latence réseau, car la zone d'IA est physiquement distincte des emplacements des zones standards de la région.
Certains produits permettent de créer des ressources zonales ou d'y accéder localement dans une zone d'IA. Pour en savoir plus sur ces services, consultez le tableau suivant :
| Produit | Description |
|---|---|
| Google Kubernetes Engine (GKE) | Configuration pour utiliser les zones d'IA dans les clusters GKE, y compris la configuration à l'aide de ComputeClasses, du provisionnement automatique des nœuds et des pools de nœuds GKE Standard. Utiliser des zones d'IA dans GKE |
| Cloud Storage | Configuration du stockage d'objets pour les charges de travail dans les zones d'IA, y compris le stockage zonal pour maximiser les performances pendant les jobs actifs et le stockage persistant pour les ensembles de données et les points de contrôle des modèles. Utiliser des zones d'IA avec Cloud Storage |
| Compute Engine | Méthodes permettant d'identifier les zones d'IA disponibles à l'aide de la console, de la Google Cloud CLI et de l'API REST, y compris comment filtrer par convention d'attribution de nom, type d'accélérateur ou type de machine Trouver les zones d'IA disponibles |
Zones
Les zones d'IA sont disponibles dans les pays suivants :
| Zone d'IA | Emplacement de la zone d'IA | Google Cloud région | Emplacement de la régionGoogle Cloud | Zone parente |
|---|---|---|---|---|
us-south1-ai1b |
Austin, Texas, Amérique du Nord | us-south1 |
Dallas, Texas, Amérique du Nord | us-south1-b |
us-central1-ai1a |
Lincoln, Nebraska, Amérique du Nord | us-central1 |
Council Bluffs, Iowa, Amérique du Nord | us-central1-a |
Utiliser les zones d'IA
Les zones d'IA sont accessibles via la console Google Cloud , Google Cloud CLI ou REST. Toutefois, lorsque vous utilisez la consoleGoogle Cloud pour créer vos VM, vous devez sélectionner manuellement une zone d'IA. Contrairement aux zones standards, elle n'est pas sélectionnée pour vous. Pour utiliser les zones d'IA avec les fonctionnalités suivantes, vous devez sélectionner explicitement une zone d'IA lorsque vous configurez ces ressources.
Certaines fonctionnalités de Compute Engine et de GKE : les zones d'IA ne sont pas sélectionnées automatiquement dans certaines fonctionnalités régionales de Compute Engine et de GKE (par exemple, les groupes d'instances gérés régionaux et les clusters GKE régionaux). Pour en savoir plus sur GKE, consultez la documentation GKE.
Restrictions concernant les charges de travail sans accélérateur : lorsque vous exécutez des VM avec processeur uniquement dans des zones d'IA, tenez compte des restrictions appliquées par Compute Engine. Il peut s'agir d'exigences concernant les ratios GPU/CPU et les réservations.
Vertex AI : les produits Vertex AI régionaux basés sur GKE doivent configurer GKE pour inclure des zones d'IA dans les clusters régionaux. Vous n'avez pas besoin d'activer Vertex AI. Vertex AI gère cette configuration.
API Service Metadata Locations : vous devez activer l'indicateur
--extraLocationTypeslorsque vous utilisez l'API locations.list pour vous assurer que les zones d'IA ne s'affichent que pour les utilisateurs qui ont l'intention de les utiliser.Google Cloud
Utiliser des zones d'IA dans GKE
Par défaut, GKE ne déploie pas vos charges de travail dans les zones d'IA. Pour utiliser une zone d'IA, vous devez configurer l'une des options suivantes :
ComputeClasses : définissez votre priorité la plus élevée pour demander des TPU à la demande dans une zone d'IA. Les classes de calcul vous aident à définir une liste hiérarchisée de configurations matérielles pour vos charges de travail. Pour obtenir un exemple, consultez À propos de ComputeClasses.
Provisionnement automatique des nœuds : utilisez un
nodeSelectorou unnodeAffinitydans la spécification de votre pod pour demander au provisionnement automatique des nœuds de créer un pool de nœuds dans la zone d'IA. Si votre charge de travail ne cible pas explicitement une zone d'IA, le provisionnement automatique de nœuds ne prend en compte que les zones standards lors de la création de pools de nœuds. Cette configuration garantit que les charges de travail qui n'exécutent pas de modèles d'IA/ML restent dans les zones standards, sauf si vous configurez explicitement le contraire. Pour obtenir un exemple de fichier manifeste qui utilise unnodeSelector, consultez Définir les zones par défaut pour les nœuds créés automatiquement.GKE Standard : si vous gérez directement vos pools de nœuds, utilisez une zone d'IA dans l'indicateur
--node-locationslorsque vous créez un pool de nœuds. Pour obtenir un exemple, consultez Déployer des charges de travail TPU dans GKE Standard.
Limites
Les éléments suivants ne sont pas disponibles dans les zones d'IA :
Considérations de conception avec les zones d'IA
Tenez compte des points suivants lorsque vous concevez vos applications pour utiliser des zones d'IA.
Points à prendre en compte concernant la haute disponibilité (HA)
Les zones d'IA partagent les déploiements de logiciels et l'infrastructure avec leurs zones parentes. Pour assurer la haute disponibilité de vos charges de travail, évitez ces schémas de déploiement lorsque vous sélectionnez des zones, que ce soit automatiquement ou manuellement :
Évitez de déployer des charges de travail HA dans une zone d'IA et sa zone parente.
Évitez de déployer des charges de travail HA sur deux zones d'IA qui partagent la même zone parente.
Bonnes pratiques de stockage
Nous vous recommandons d'utiliser une architecture de stockage par niveaux pour équilibrer les coûts, la durabilité et les performances :
- Couche de stockage à froid : utilisez des buckets Cloud Storage régionaux dans des zones standards pour stocker de manière persistante et très durable vos ensembles de données d'entraînement et vos points de contrôle de modèle.
Couche de performances : utilisez des services de stockage zonal spécialisés pour servir de cache haute vitesse ou d'espace de travail temporaire. Cette approche élimine la latence entre les zones et maximise le débit utile pendant les jobs actifs.
Pour vous assurer que les GPU et les TPU restent entièrement saturés et maximisent le débit utile, provisionnez votre couche de performances dans la même zone d'IA que vos ressources de calcul.
Les solutions de stockage suivantes sont recommandées pour optimiser les performances des systèmes d'IA et de ML avec les zones d'IA :
| Service de stockage | Description | Cas d'utilisation |
|---|---|---|
| Fonctionnalité Anywhere Cache de Cloud Storage | Cache de lecture zonal entièrement géré et basé sur un disque SSD qui transfère les données fréquemment lues d'un bucket vers la zone d'IA. | Recommandé pour :
|
Étape suivante
- Afficher la liste des zones d'IA
- Afficher les types et les emplacements de TPU disponibles dans les zones d'IA
- Configurer une règle d'administration pour limiter la création de VM dans les zones d'IA