
Aerospike から Bigtable への移行
このドキュメントでは、Aerospike から Bigtable にデータを移行するプロセスについて説明します。アダプター ライブラリなどの オープンソース ツールを使用して移行を行う方法について説明します。
移行を開始する前に、 Aerospike ユーザー向けの Bigtable をよく理解しておいてください。
移行の概要
Aerospike から Bigtable にデータを移行する際のダウンタイムは、最小限に抑えるか、ゼロにすることができます。
次の図は、移行手順の概要を示しています。
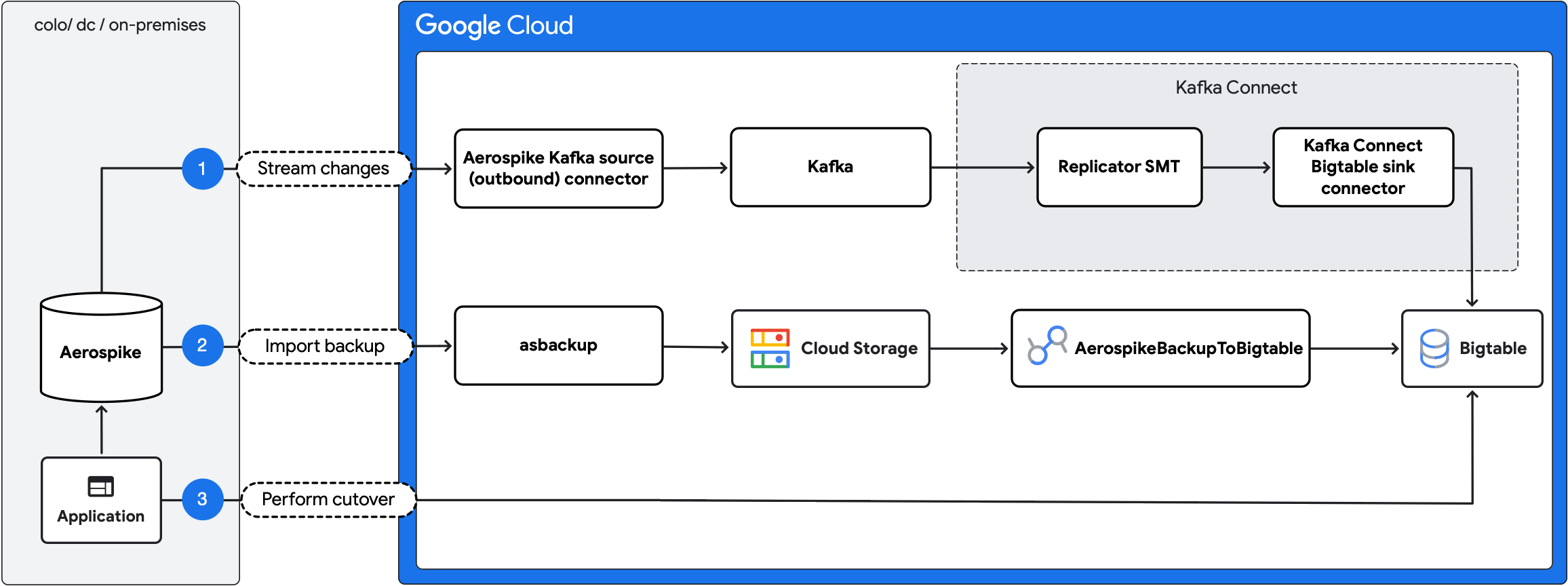
- 進行中の変更をストリーミングする: Aerospike Kafka ソース(アウトバウンド)コネクタと Kafka Connect Bigtable シンクコネクタを使用して、Aerospike から Bigtable に進行中の更新をレプリケートします。
- バックアップをインポートする: Aerospike バックアップを作成し、
AerospikeBackupToBigtableDataflow ジョブを使用して Bigtable にインポートします。 - カットオーバーを実行する: アプリケーション トラフィックを Bigtable に移動します。
移行の範囲と互換性
Bigtable は型付きのビンではなく未加工のバイトで動作するため、移行プロセスでは、Aerospike の機能と特徴を互換性のある Bigtable 構造にマッピングします。アダプター ライブラリには、構造的な互換性を実現し、オブジェクトのシリアル化などのギャップに対処するために必要なツールが用意されています。ただし、ユーザー定義関数(UDF)など、システム間の根本的な違いにより移行できない機能もあります。
次の表に、移行プロセスで Aerospike の機能がどのように処理されるかを示します。
| 機能 | サポート | 説明 |
|---|---|---|
| Aerospike ハイブリッド メモリ アーキテクチャ(HMA) | サポート対象 | SSD ストレージ階層または インメモリ階層に移行されます。Bigtable Enterprise Plus エディションでは、Aerospike のパフォーマンスと同様にミリ秒未満の応答時間を必要とするレイテンシの影響を受けやすいワークロードに対して、インメモリ ストレージにアクセスできます。 |
スカラー (Int、Float、String、Bool) |
サポート対象 | Bigtable セルに移行されます。 |
| リストとマップ | サポート対象 | マップには文字列キーが必要です。リストとマップは、アダプター ライブラリによって別々の列にシリアル化されます。 |
| セカンダリ インデックス | 一部サポート対象 | 直接移行されません。非同期セカンダリ インデックスとして再実装する必要があります。 |
| レコードレベルの有効期間(TTL) | サポート対象 | Bigtable の列ファミリー レベルで構成するか、セルごとにシミュレートします。 |
| UDF | 対象外 | カスタム サーバーサイド ロジックは、クライアントサイド アプリケーションに移動する必要があります。 |
| HyperLogLog | 対象外 | 移行プロセスではサポートされていません。 |
| GeoJSON | 対象外 | 移行プロセスではサポートされていません。 |
| レコードキー | 対象外 | レコードキーは直接移行されません。代わりに、移行ではレコード ダイジェストが行キーとして使用されます。 |
始める前に
移行を開始する前に、次の準備手順を完了してリスクを軽減し、スムーズな移行を実現します。
- データを検証する: Aerospike デプロイが、サポートされていないデータ型、セカンダリ インデックス、UDF に依存していないことを確認します。安全のため、データの代表的なサブセットを Bigtable にインポートして、スキーマ設計を検証できます。
- インフラストラクチャをプロビジョニングする: 移行パイプラインに必要なサービス(Bigtable、Kafka、Kafka Connect)を設定します。
- キャパシティ プランニング: 予想されるワークロードを処理するのに十分な容量で Bigtable をプロビジョニングします。既存の Aerospike クラスタに近いリージョンを選択します。必要なリソースの見積もりについては、Bigtable のパフォーマンスについてをご覧ください。
- ストレージ階層: ミリ秒未満の応答時間を必要とするワークロードの場合は、Bigtable インメモリ階層の使用を検討してください。この階層では、データを RAM に保存して、読み取り負荷の高いアプリケーションやレイテンシの影響を受けやすいアプリケーションに最高のパフォーマンスを提供します。詳細については、インメモリ階層の概要をご覧ください。
- アクセスとネットワークを構成する: 適切な Identity and Access Management(IAM)ロールを割り当て、ネットワーク接続を確保します。
- モニタリングとエラー報告を有効にする: ロギング、指標、アラートなど、新しい環境のオブザーバビリティを構成します。
- ベースライン パフォーマンスのベンチマーク測定: 現在のシステム パフォーマンスを記録して、移行後の検証の基準とします。
- バックアップを作成する: Aerospike データの完全バックアップを作成します。
- テスト移行を実行する: 本番環境への移行を試みる前に、ステージング環境で設定を検証します。
データの移行
Aerospike から Bigtable にデータを移行する手順は次のとおりです。
変更ストリームを開始する
Aerospike 変更ストリームを有効にすると、Aerospike Kafka ソース(アウトバウンド)コネクタが Aerospike レコードの更新を Kafka トピックにパブリッシュします。Kafka に変更をバッファリングするのに十分なストレージ容量があることを確認し、JSON 形式でデータを出力するようにコネクタを構成します。
Kafka コネクタ構成の例を次に示します。
service:
port: <port_to_run_on>
producer-props:
bootstrap.servers:
- <kafka_host>
format:
mode: json
metadata-key: metadata
routing:
mode: static
destination: <kafka_topic>
Aerospike Kafka ソース(アウトバウンド)コネクタを使用して Kafka と通信するには、Aerospike クロス データセンター レプリケーション(XDR)が必要です。これにより、レイテンシの高いリンクを介してクラスタの変更が非同期でレプリケートされます。XDR は、Aerospike Enterprise Edition でのみ使用できます。Aerospike Community Edition を使用している場合は、Enterprise Edition に切り替えるか、AerospikeBackupToBigtable Dataflow ジョブのみを使用してオフライン移行を行います。
Aerospike での XDR の構成例は次のようになります。
xdr {
dc aerospike-kafka-source {
connector true
node-address-port <aerospike_connect_host> <aerospike_connect_port>
namespace <your_namespace_to_replicate> {
}
}
}
Aerospike からデータをエクスポートする
変更ストリームを開始したら、既存の Aerospike データセットのバックアップを生成します。asbackup コマンドライン ツールを使用して、Aerospike データベース クラスタからバックアップを作成します。一部の更新はバックアップと変更ストリームの両方に表示される場合がありますが、これは想定される動作であり、移行には影響しません。復元時に並列インポートを許可するには、バックアップを複数のファイルに分割します。
Bigtable にデータをインポートする
バックアップしたデータを Bigtable にインポートする手順は次のとおりです。
- バックアップを Cloud Storage バケットにアップロードします。
AerospikeBackupToBigtableDataflow ジョブを実行して、バックアップを Bigtable にインポートします。バックアップが複数のファイルに分割されている場合、ジョブはそれらを並行して処理します。書き込み負荷の増加に対応し、最適なスループットを維持するには、追加の Bigtable リソースをプロビジョニングします。
レコードの更新を Bigtable に適用する
バックアップを Bigtable にインポートしたら、Kafka Connect Bigtable シンクコネクタを使用して、Kafka のバッファリングされたレコードの更新を Bigtable に適用します。
メッセージを互換性のある形式に変換する
Aerospike 移行ツールには、Kafka Connect 内で実行される Replicator SMT が含まれています。レプリケータは、Aerospike Kafka ソース(アウトバウンド)コネクタによってパブリッシュされたメッセージを、レコードを Bigtable に書き込むターゲット シンクと互換性のある形式に変換します。 シンクは、Aerospike が変更をストリーミングする方法とは異なる特定の形式でデータを想定しているため、変換が必要です。
次の表は、特定のスループットを実現するために必要なマシンリソースを見積もるのに役立ちます。
| レコード構造 | スループット | p99 レイテンシ |
|---|---|---|
| 平坦 | vCPU あたり 1 秒あたり最大 3,700 レコード | 300 ミリ秒 |
| ネスト | vCPU あたり 1 秒あたり最大 2,600 レコード | 300 ミリ秒 |
これらの推定値は、JSON シリアル化されたレコードのサイズが 1 KB であることを前提としています。メッセージ構造が複雑になるほど解析時間が長くなります。つまり、Aerospike レコードに保存されているネストされたオブジェクトの解析には時間がかかります。
consumer_lag 指標を使用して、処理キュー内のメッセージの数を確認し、レプリケーション ラグを測定できます。シンクがトピックのメッセージのバックログを処理すると、コンシューマー ラグはゼロ近くまで安定するまで減少します。この時点で、シンクは Aerospike の更新を準リアルタイムで処理し、カットオーバーの準備が整います。sink-record-active-count を使用して、すでに処理されたメッセージの数を確認できます。
Kafka Connect Bigtable シンクコネクタでメッセージを取り込む
Kafka Connect Bigtable シンクコネクタは、Kafka から Bigtable にメッセージを取り込みます。コネクタを構成するときに、insert.mode を REPLACE_IF_NEWEST に設定して、Bigtable のターゲット行に書き込まれるレコードが最新であることを確認します。詳細については、Kafka Connect Bigtable シンクコネクタの構成をご覧ください。
次の表に、さまざまなワークロードで発生するレイテンシと必要なコンピューティング リソースの目安を示します。
| レコード構造 | スループット | p99 レイテンシ |
|---|---|---|
| 平坦 | vCPU あたり 1 秒あたり最大 3,700 レコード | 74 ミリ秒 |
| ネスト | vCPU あたり 1 秒あたり最大 3,700 レコード | 100 ミリ秒 |
これらの推定値は、JSON シリアル化されたレコードのサイズが 1 KB であることを前提としています。報告されるレイテンシは、シンクでの処理時間です。Bigtable への書き込みリクエストを行うための追加のオーバーヘッドは約 600 ミリ秒と想定されます。
Bigtable に切り替える
アプリケーションを切り替えて、Bigtable をプライマリ データベースとして使用します。
読み取り後の書き込みの整合性を確保するため、レプリケーション ラグがゼロになるまでアプリケーションを一時的にシャットダウンします。これにより、ミューテーションが失われることなく、データ読み取りが最新の状態を反映します。
たとえば、カットオーバーの直前に Aerospike で適用されたミューテーションは、まだ Bigtable にレプリケートされていないため、古い読み取りが発生する可能性があります。このシナリオを回避するには、consumer_lag 指標と sink-record-active-count 指標が 0 になるまでアプリケーションをオフラインにします。保留中の変更がすべて伝播したら、Bigtable をプライマリ データベースとしてアプリケーションを再起動します。
ライブ マイグレーションではダウンタイムを回避できますが、次の制約があります。
- Bigtable で適用されたミューテーションは Aerospike にレプリケートされません。
- Aerospike からのミューテーションが Bigtable に遅れて表示されることがあります。
- Aerospike からの遅延ミューテーションにより、Bigtable の最新の更新が上書きされる可能性があります。
デプロイを確認する
デプロイ後、エラー率、レイテンシ、費用などの指標を確認して、アプリケーションのパフォーマンスを検証します。データの完全性チェックを行うこともできます。
モニタリングとオブザーバビリティ
移行中は、次の指標をモニタリングします。
- 合計ラグ: Kafka コンシューマー ラグと
sink-record-active-countを足した値として計算されます。これらの指標は、Bigtable が Aerospike からどの程度遅れているかを示します。トラフィックを Bigtable に再ルーティングする前に、ラグの値が安定している必要があります。 - CPU とメモリの使用率: すべての変更ストリーム パイプライン コンポーネントの CPU とメモリの使用率をモニタリングします。
- Kafka ストレージ容量: 自己管理型 Kafka デプロイの容量をモニタリングします。ストレージがいっぱいになると、新しいイベントをバッファリングできず、移行が失敗します。
- アプリケーションのエラー率: すべての変更ストリーム パイプライン要素のエラー率とエラー出力をモニタリングします。
制限事項
次のセクションでは、Aerospike から Bigtable にデータを移行する際に考慮すべき制限について説明します。
移行中のデータの整合性
asbackup ツールを使用して Aerospike バックアップを生成する場合、バックアップ プロセスではアトミック バックアップがサポートされていないため、バックアップ プロセス中に変更されたレコードが除外されることがあります。この制限は、すべての変更が変更ストリームに表示されるため、正確性には影響しません。
Bigtable へのバックアップのインポート中、各行は最終更新時刻(LUT)のタイムスタンプ 0 で書き込まれます。
変更ストリームからの更新は、インポートされたバックアップに適用されます。ストリームから書き込まれた行は、LUT 値を Bigtable 行のタイムスタンプとして使用します。シンク構成により、新しいタイムスタンプの更新で古いタイムスタンプが上書きされます。これにより、ストリームから再生された変更で対応する行が上書きされます。
LUT の使用
移行プロセスでは、Aerospike XDR を使用して変更をレプリケートし、競合解決に LUT を使用します。LUT はノードのシステム クロックに基づいているため、厳密に単調でない可能性があります。その結果、古いレコードに新しい LUT が設定され、新しいレコードが上書きされることがあります。 また、Aerospike Kafka ソース(アウトバウンド)コネクタは、Kafka にパブリッシュするときに正確なメッセージ順序を保持しない場合があります。その結果、LUT は信頼できるバージョン マーカーとして機能し、最新の LUT を持つレコードのみが Bigtable に適用されます。
変更ストリームを開始してからバックアップを生成するまでの間にレコードが更新された場合、バックアップには新しいバージョンがキャプチャされ、ストリームには古いバージョンが含まれることがあります。この古いバージョンによって、新しいバージョンが一時的に上書きされる可能性があります。ただし、正しい LUT を持つ後続のストリーム イベントが到着すると、最新バージョンが復元されます。不整合を回避するには、レプリケーションが安定し、パイプライン内の最も古い未処理メッセージがバックアップよりも新しくなるまで、カットオーバーを行わないでください。
データの検証
移行パイプラインでは、転送中のデータのチェックサムは実行されません。エンドツーエンドのデータの完全性チェックが必要な場合は、検証を実装する必要があります。
トラブルシューティング
次のセクションでは、移行プロセス中に発生する可能性のある一般的なエラーと、その解決方法について説明します。
バックアップのインポート エラー
Aerospike バックアップを Bigtable にインポートする際に、次のエラーが発生することがあります。
| エラーの種類 | 原因 | ソリューション |
|---|---|---|
| バックアップ ファイルが破損している | バックアップ ファイルが読み取れないか、破損したレコードが含まれています。インポート ジョブが失敗します。 | 影響を受けるファイルに整合性の問題がないか確認します。復元できない場合は、新しいバックアップを生成してインポートを繰り返します。 |
| Bigtable の書き込みエラー | Bigtable の接続またはサービスの問題が発生します。インポートは失敗しません。 | 失敗したレコードは、JSON 形式のエラー出力ファイルにエクスポートされます。手動で再適用するか、完全なインポート ジョブを再試行します。 |
| サポートされていないデータ | バックアップに、Bigtable にインポートできないエントリが含まれています。インポートは失敗しません。 | UDF などのサポートされていないデータは、ジョブログに警告として報告されます。ログを確認して、サポートされていないエントリを確認します。 |
バックアップのインポートが完了し、無効なレコードが処理されたら、変更ストリームの適用に進むことができます。
変更ストリーム エラー
変更ストリームの適用中に、次のレベルでエラーが発生する可能性があります。
- レプリケータ SMT エラー: SMT が Aerospike によって生成されたデータを変換できません。
- シンクエラー: イベントを Bigtable に適用できません。
どちらの場合も、失敗したイベントは専用の Kafka トピックにリダイレクトされます。監査のためにイベントをログに記録するか、カスタム復旧ロジックを使用して処理できます。
次のステップ
- Bigtable スキーマの設計方法を確認する。
- への移行を開始する方法を確認する Google Cloud。
- 大規模なデータセットを転送するための 戦略を把握する。