
במדריך הזה מוסבר איך להתחבר לטבלה ב-BigQuery או לתצוגה כדי לקרוא ולכתוב נתונים ממחברת Databricks. השלבים מפורטים במאמר בנושא Google Cloud מסוף וסביבות עבודה של Databricks.
אפשר גם לבצע את השלבים האלה באמצעות כלי שורת הפקודה gcloud ו-databricks, אבל ההנחיות האלה לא נכללות במדריך הזה.
Databricks on Google Cloud הוא סביבת Databricks שמארחת ב- Google Cloud, פועלת ב-Google Kubernetes Engine (GKE) ומספקת שילוב מובנה עם BigQuery ועם טכנולוגיות אחרות של Google Cloud . אם אתם חדשים ב-Databricks, כדאי לצפות בסרטון Introduction to Databricks Unified Data Platform כדי לקבל סקירה כללית של פלטפורמת Databricks lakehouse.
מטרות
- מגדירים את Google Cloud כדי להתחבר ל-Databricks.
- פריסת Databricks ב- Google Cloud.
- הרצת שאילתות ב-BigQuery מ-Databricks.
עלויות
במדריך הזה נעשה שימוש ברכיבים של מסוף Google Cloud שחלים עליהם חיובים, כולל BigQuery ו-GKE. יחולו על כך התמחור של BigQuery והתמחור של GKE. מידע על העלויות שמשויכות לחשבון Databricks שפועל ב- Google Cloudמופיע בקטע הגדרת החשבון ויצירת סביבת עבודה במסמכי Databricks.
לפני שמתחילים
לפני שמקשרים את Databricks ל-BigQuery, צריך לבצע את השלבים הבאים:
- מפעילים את BigQuery Storage API.
- יוצרים חשבון שירות ל-Databricks.
- יוצרים קטגוריה של Cloud Storage לאחסון זמני.
הפעלת BigQuery Storage API
BigQuery Storage API מופעל כברירת מחדל בכל פרויקט חדש שבו נעשה שימוש ב-BigQuery. אם יש לכם פרויקטים קיימים שבהם ה-API לא מופעל, אתם צריכים לפעול לפי ההוראות הבאות:
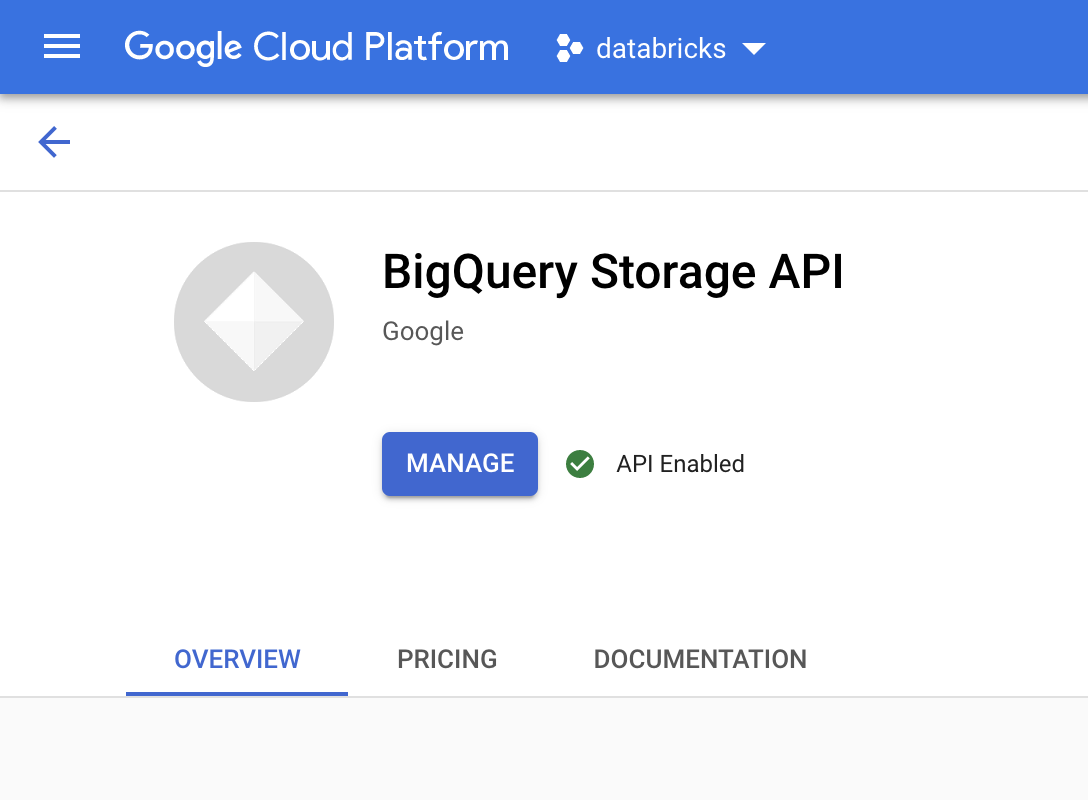
במסוף Google Cloud , עוברים לדף BigQuery Storage API.
מוודאים ש-BigQuery Storage API מופעל.
יצירת חשבון שירות ל-Databricks
לאחר מכן, יוצרים חשבון שירות לניהול זהויות והרשאות גישה (IAM) כדי לאפשר לאשכול Databricks להריץ שאילתות ב-BigQuery. מומלץ לתת לחשבון השירות הזה את ההרשאות המינימליות שנדרשות לביצוע המשימות שלו. מידע נוסף זמין במאמר תפקידים והרשאות ב-BigQuery.
נכנסים לדף Service Accounts במסוף Google Cloud .
לוחצים על יצירת חשבון שירות, נותנים שם לחשבון השירות
databricks-bigquery, מזינים תיאור קצר כמוDatabricks tutorial service accountולוחצים על יצירה והמשך.בקטע Grant this service account access to project (הענקת גישה של חשבון השירות הזה לפרויקט), מציינים את התפקידים של חשבון השירות. כדי להעניק לחשבון השירות הרשאה לקרוא נתונים באמצעות סביבת העבודה של Databricks והטבלה ב-BigQuery באותו פרויקט, בלי להפנות לתצוגה מהותית, צריך להעניק את התפקידים הבאים:
- BigQuery Read Session User
- BigQuery Data Viewer (צפייה בנתוני BigQuery)
כדי לתת הרשאה לכתיבת נתונים, צריך להקצות את התפקידים הבאים:
- BigQuery Job User
- עריכה של נתוני BigQuery
כדאי לרשום את כתובת האימייל של חשבון השירות החדש כדי להשתמש בה בשלבים הבאים.
לוחצים על סיום.
יצירת קטגוריה של Cloud Storage
כדי לכתוב ל-BigQuery, לאשכול Databricks צריכה להיות גישה לקטגוריה של Cloud Storage כדי לשמור את הנתונים שנכתבו.
במסוף Google Cloud , נכנסים אל Cloud Storage Browser.
לוחצים על Create bucket (יצירת קטגוריה) כדי לפתוח את תיבת הדו-שיח Create a bucket (יצירת קטגוריה).
מציינים שם למאגר שמשמש לכתיבת נתונים ב-BigQuery. שם הקטגוריה חייב להיות שם ייחודי גלובלי. אם מציינים שם של קטגוריה שכבר קיימת, Cloud Storage מגיב בהודעת שגיאה. במקרה כזה, צריך לציין שם אחר לקטגוריה.
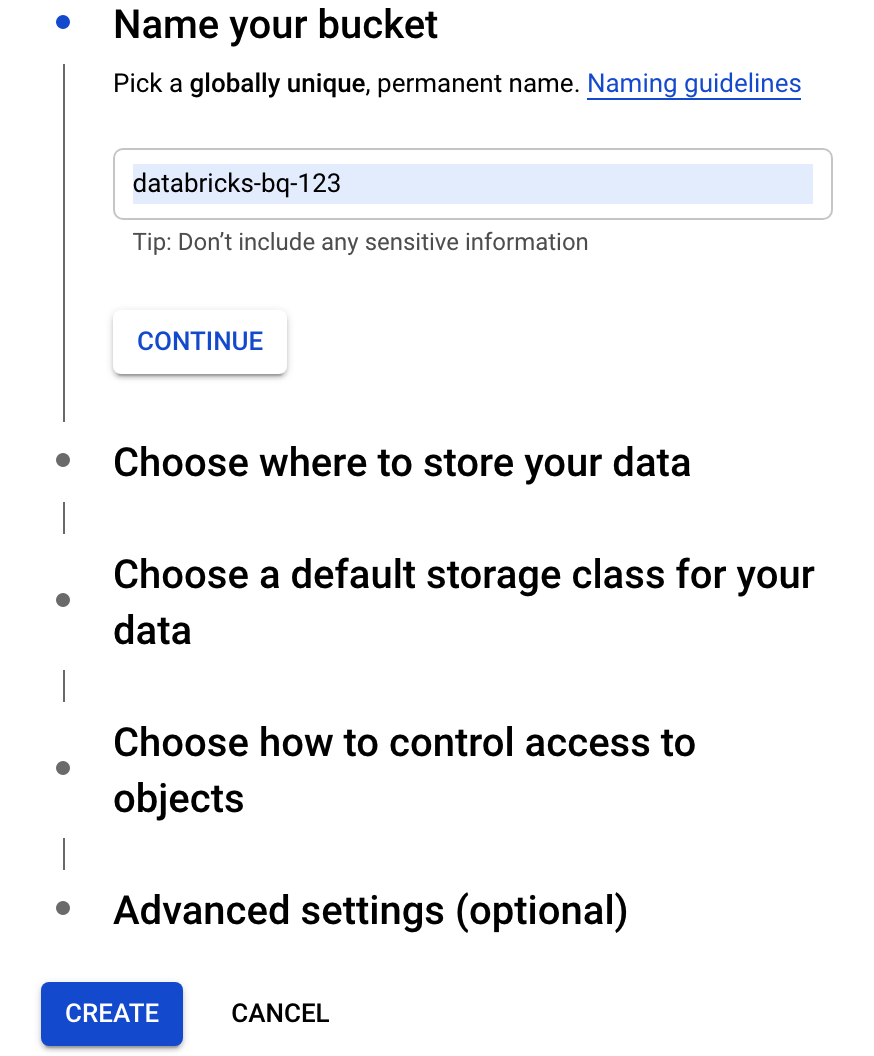
במדריך הזה, משתמשים בהגדרות ברירת המחדל למיקום האחסון, לסוג האחסון, לבקרת הגישה ולהגדרות המתקדמות.
לוחצים על יצירה כדי ליצור את הקטגוריה של Cloud Storage.
לוחצים על Permissions, לוחצים על Add ומציינים את כתובת האימייל של חשבון השירות שיצרתם לגישה ל-Databricks בדף Service Accounts.
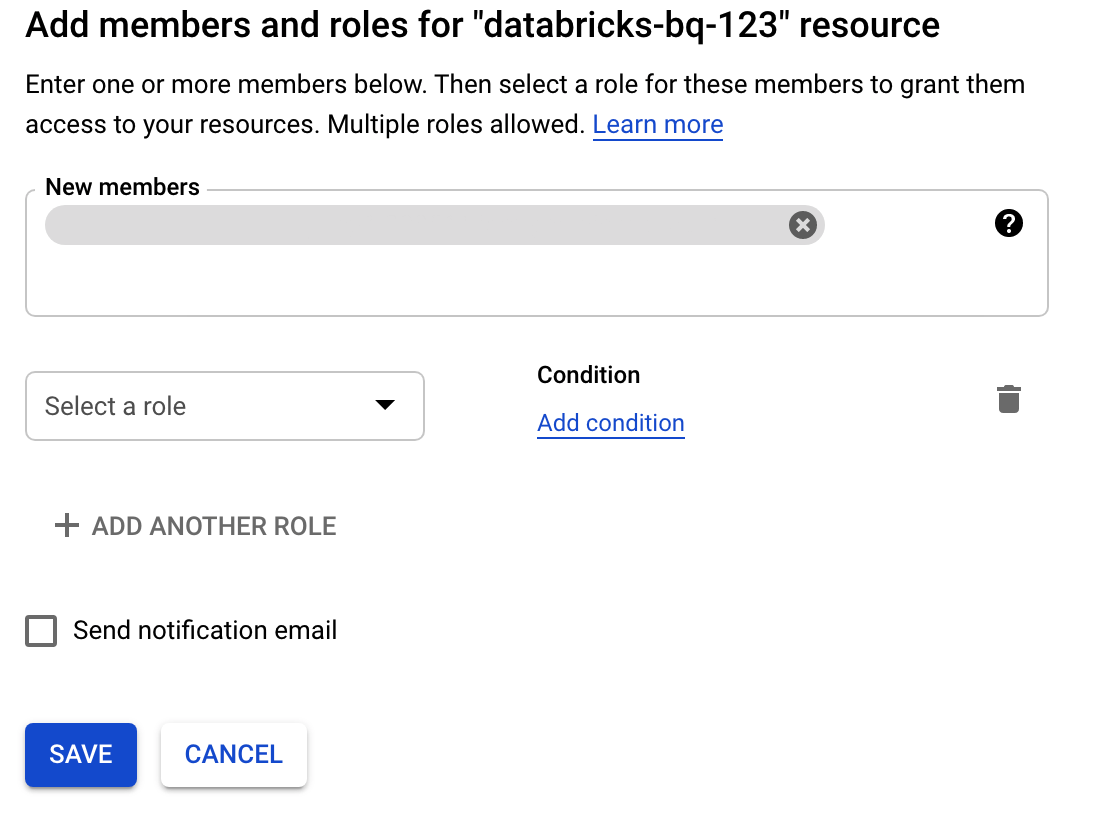
לוחצים על Select a role ומוסיפים את התפקיד Storage admin.
לוחצים על Save.
פריסת Databricks ב- Google Cloud
כדי להתכונן לפריסת Databricks ב- Google Cloud, צריך לבצע את השלבים הבאים.
- כדי להגדיר את החשבון ב-Databricks, פועלים לפי ההוראות במסמכי התיעוד של Databricks, הגדרת חשבון ב-Databricks on Google Cloud.
- אחרי ההרשמה, תוכלו לקרוא מידע נוסף על ניהול חשבון Databricks.
יצירה של סביבת עבודה, אשכול ו-Notebook ב-Databricks
בשלבים הבאים מוסבר איך ליצור סביבת עבודה של Databricks, אשכול ומחברת Python כדי לכתוב קוד לגישה ל-BigQuery.
בודקים את הדרישות המוקדמות של Databricks.
יוצרים את סביבת העבודה הראשונה. במסוף החשבון של Databricks, לוחצים על Create Workspace (יצירת סביבת עבודה).
מציינים
gcp-bqבשדה שם סביבת העבודה ובוחרים את האזור.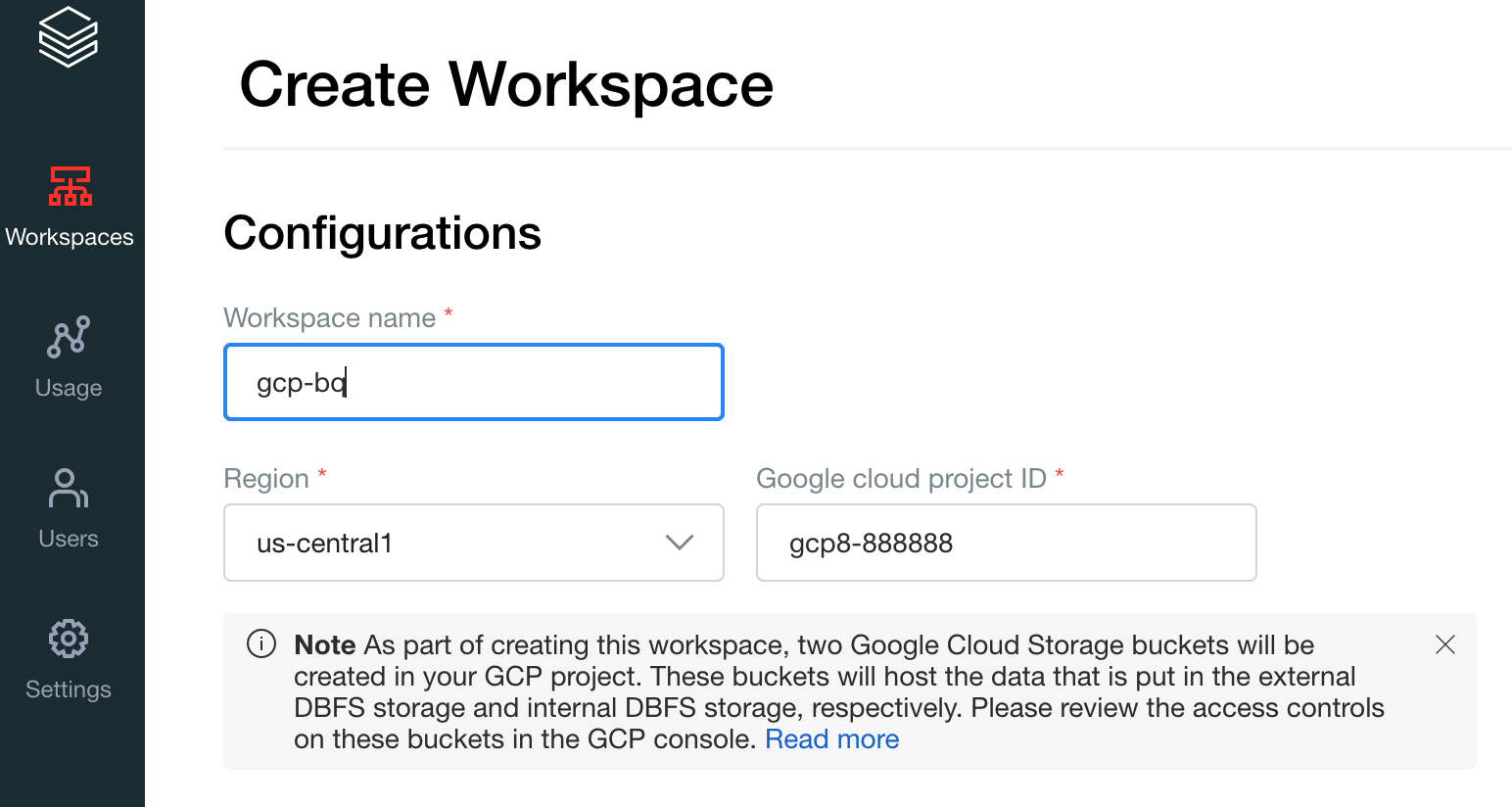
כדי לדעת מהו Google Cloud מזהה הפרויקט, נכנסים למסוף Google Cloud ומעתיקים את הערך לשדה Google Cloud מזהה הפרויקט.
לוחצים על Save כדי ליצור את סביבת העבודה של Databricks.
כדי ליצור אשכול Databricks עם Databricks runtime 7.6 ואילך, בסרגל התפריטים השמאלי בוחרים באפשרות Clusters ואז לוחצים על Create Cluster בחלק העליון.
מציינים את השם של האשכול ואת הגודל שלו, ואז לוחצים על אפשרויות מתקדמות ומציינים את כתובת האימייל של חשבון השירות שלכם, Google Cloud.
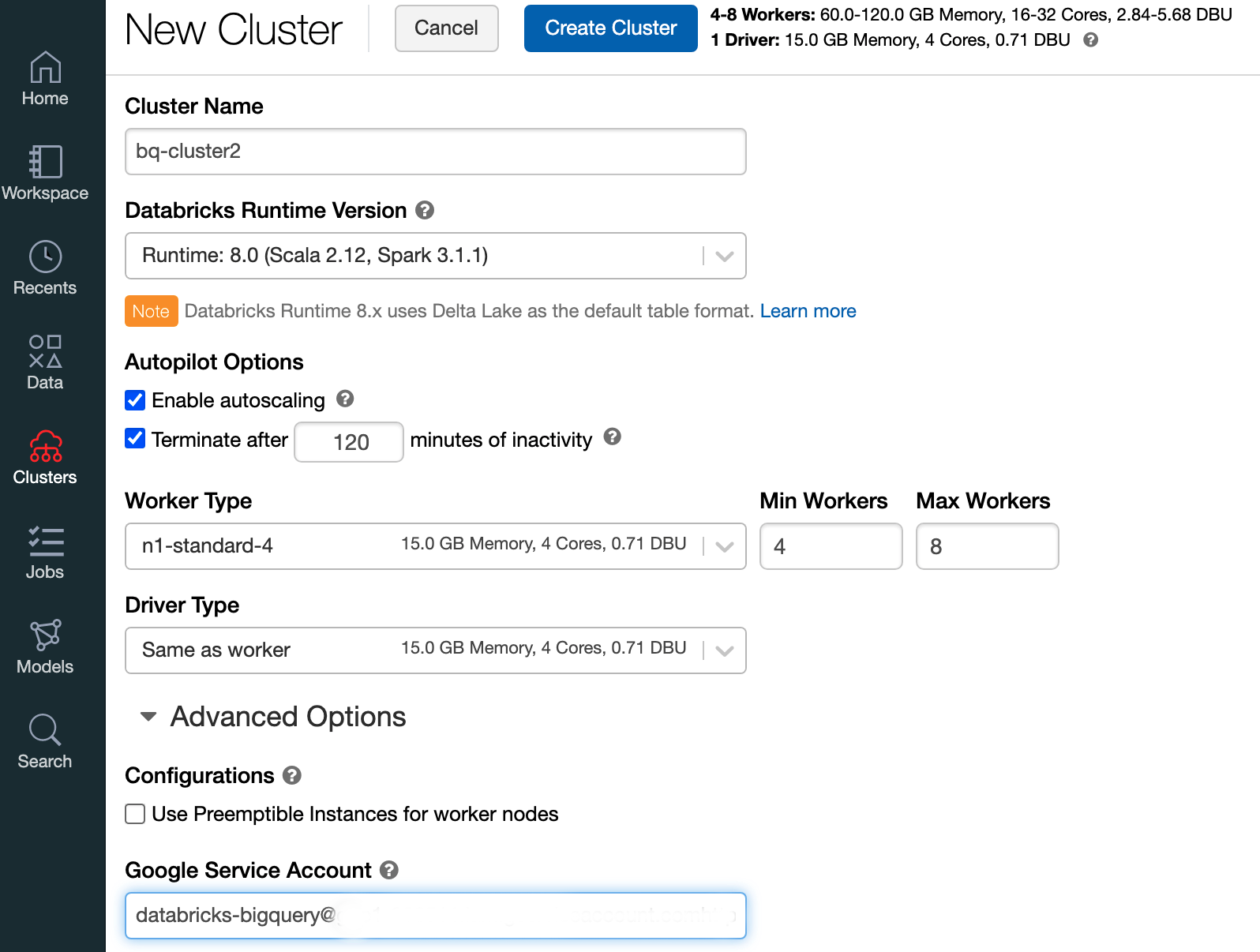
לוחצים על יצירת אשכול.
כדי ליצור מחברת Python ל-Databricks, פועלים לפי ההוראות במאמר יצירת מחברת.
הרצת שאילתות ב-BigQuery מ-Databricks
עם ההגדרות שלמעלה, אפשר לחבר את Databricks ל-BigQuery בצורה מאובטחת. Databricks משתמשת בפיצול של מתאם Google Spark בקוד פתוח כדי לגשת ל-BigQuery.
Databricks מצמצם את העברת הנתונים ומאיץ את השאילתות על ידי דחיפה אוטומטית של פרדיקטים מסוימים של שאילתות, למשל סינון של עמודות מקוננות אל BigQuery. בנוסף, היכולת החדשה להריץ קודם שאילתת SQL ב-BigQuery באמצעות ממשק query() API מצמצמת את גודל ההעברה של מערך הנתונים שמתקבל.
בשלבים הבאים מוסבר איך לגשת למערך נתונים ב-BigQuery ולכתוב נתונים משלכם ב-BigQuery.
גישה למערך נתונים ציבורי ב-BigQuery
ב-BigQuery יש רשימה של מערכי נתונים ציבוריים זמינים. כדי להריץ שאילתה במערך הנתונים של שייקספיר ב-BigQuery, שכלול במערכי הנתונים הציבוריים, מבצעים את השלבים הבאים:
כדי לקרוא את הטבלה ב-BigQuery, משתמשים בקטע הקוד הבא במחברת Databricks.
table = "bigquery-public-data.samples.shakespeare" df = spark.read.format("bigquery").option("table",table).load() df.createOrReplaceTempView("shakespeare")מריצים את הקוד על ידי לחיצה על
Shift+Return.עכשיו אפשר להריץ שאילתה על טבלת BigQuery באמצעות Spark DataFrame (
df). לדוגמה, אפשר להשתמש בפקודה הבאה כדי להציג את שלוש השורות הראשונות של ה-DataFrame:df.show(3)כדי לשלוח שאילתה לטבלה אחרת, מעדכנים את המשתנה
table.תכונה מרכזית של מחברות Databricks היא שאפשר לשלב תאים בשפות שונות כמו Scala, Python ו-SQL במחברת אחת.
שאילתת ה-SQL הבאה מאפשרת להציג את ספירת המילים בטקסט של שייקספיר אחרי שמריצים את התא הקודם שיוצר את התצוגה הזמנית.
%sql SELECT word, SUM(word_count) AS word_count FROM words GROUP BY word ORDER BY word_count DESC LIMIT 12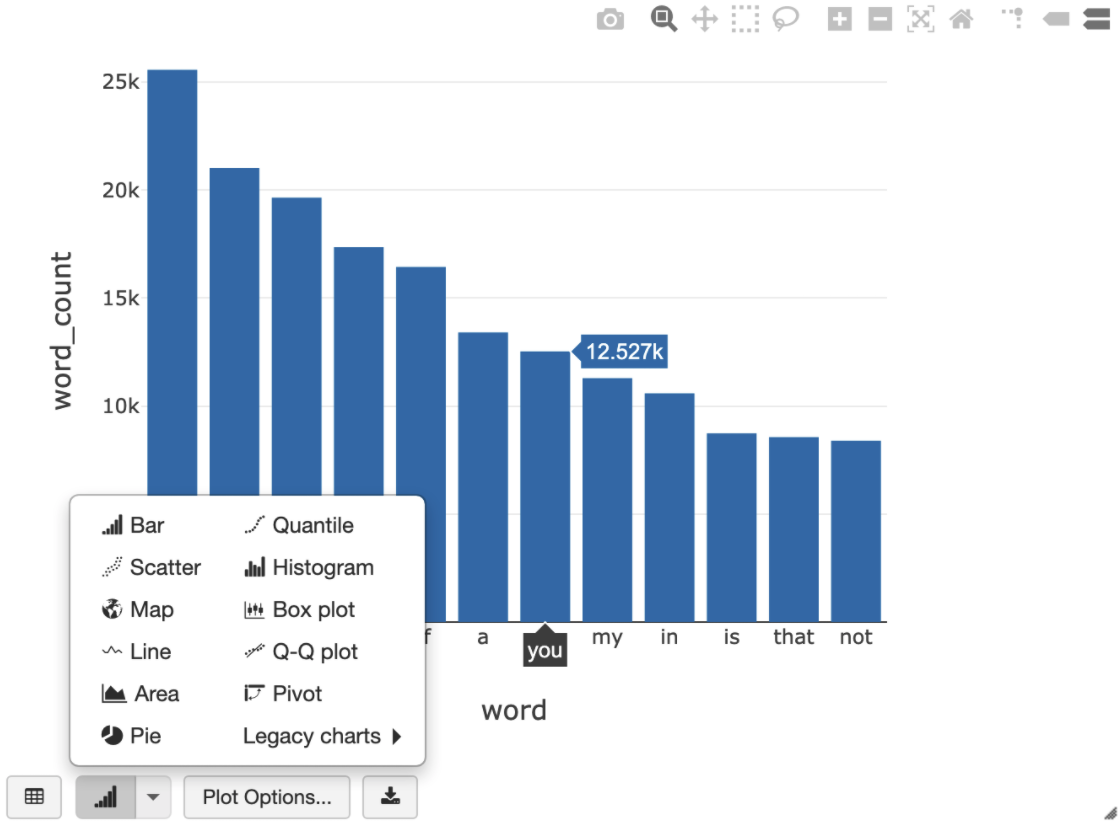
התא שלמעלה מריץ שאילתת Spark SQL על מסגרת הנתונים באשכול Databricks, ולא ב-BigQuery. היתרון בגישה הזו הוא שהניתוח של הנתונים מתבצע ברמת Spark, לא מתבצעות קריאות נוספות ל-BigQuery API ולא נוצרות עלויות נוספות ב-BigQuery.
לחלופין, אפשר להעביר את הביצוע של שאילתת SQL ל-BigQuery באמצעות
query()API ולבצע אופטימיזציה כדי להקטין את גודל ההעברה של מסגרת הנתונים שמתקבלת. בניגוד לדוגמה שלמעלה, שבה העיבוד בוצע ב-Spark, אם משתמשים בגישה הזו, התמחור והאופטימיזציות של השאילתות חלים על ביצוע השאילתה ב-BigQuery.בדוגמה הבאה נעשה שימוש ב-Scala, ב-
query()API ובמערך הנתונים הציבורי של שייקספיר ב-BigQuery כדי לחשב את חמש המילים הנפוצות ביותר ביצירות של שייקספיר. לפני שמריצים את הקוד, צריך ליצור קודם מערך נתונים ריק ב-BigQuery בשםmdatasetשהקוד יוכל להתייחס אליו. מידע נוסף זמין במאמר כתיבת נתונים ל-BigQuery.%scala // public dataset val table = "bigquery-public-data.samples.shakespeare" // existing dataset where the Google Cloud user has table creation permission val tempLocation = "mdataset" // query string val q = s"""SELECT word, SUM(word_count) AS word_count FROM ${table} GROUP BY word ORDER BY word_count DESC LIMIT 10 """ // read the result of a GoogleSQL query into a DataFrame val df2 = spark.read.format("bigquery") .option("query", q) .option("materializationDataset", tempLocation) .load() // show the top 5 common words in Shakespeare df2.show(5)דוגמאות נוספות לקוד זמינות במחברת לדוגמה של Databricks BigQuery.
כתיבת נתונים ל-BigQuery
טבלאות BigQuery קיימות במערכי נתונים. כדי לכתוב נתונים בטבלה ב-BigQuery, צריך ליצור מערך נתונים חדש ב-BigQuery. כדי ליצור מערך נתונים למחברת Python ב-Databricks, פועלים לפי השלבים הבאים:
נכנסים לדף BigQuery במסוף Google Cloud .
מרחיבים את האפשרות פעולות, לוחצים על יצירת מערך נתונים ונותנים לו שם
together.ב-notebook של Databricks Python, יוצרים מסגרת נתונים פשוטה של Spark מרשימת Python עם שלוש רשומות מחרוזת באמצעות קטע הקוד הבא:
from pyspark.sql.types import StringType mylist = ["Google", "Databricks", "better together"] df = spark.createDataFrame(mylist, StringType())מוסיפים עוד תא למחברת שכותב את מסגרת הנתונים של Spark מהשלב הקודם לטבלה ב-BigQuery
myTableבמערך הנתוניםtogether. הטבלה נוצרת או נכתבת מחדש. משתמשים בשם של הקטגוריה שציינתם קודם.bucket = YOUR_BUCKET_NAME table = "together.myTable" df.write .format("bigquery") .option("temporaryGcsBucket", bucket) .option("table", table) .mode("overwrite").save()כדי לוודא שהנתונים נכתבו בהצלחה, מריצים שאילתה ומציגים את טבלת BigQuery דרך Spark DataFrame (
df):display(spark.read.format("bigquery").option("table", table).load)
הסרת המשאבים
כדי לא לצבור חיובים לחשבון Google Cloud על המשאבים שבהם השתמשתם במדריך הזה, אתם יכולים למחוק את הפרויקט שמכיל את המשאבים או להשאיר את הפרויקט ולמחוק את המשאבים בנפרד.
לפני שמסירים את Databricks, תמיד צריך לגבות את הנתונים ואת המחברות. כדי לנקות את Databricks ולהסיר אותו לגמרי, מבטלים את המינוי ל-Databricks במסוףGoogle Cloud ומסירים את כל המשאבים הקשורים שיצרתם במסוףGoogle Cloud .
אם מוחקים סביבת עבודה של Databricks, יכול להיות ששתי קטגוריות של Cloud Storage עם השמות databricks-WORKSPACE_ID ו-databricks-WORKSPACE_ID-system שנוצרו על ידי Databricks לא יימחקו אם הן לא ריקות. אחרי מחיקת סביבת העבודה, תוכלו למחוק את האובייקטים האלה באופן ידני בGoogle Cloud מסוף של הפרויקט.
המאמרים הבאים
בקטע הזה מופיעה רשימה של מסמכים נוספים ומדריכים:
- מידע על תקופת הניסיון בחינם של Databricks
- מידע נוסף על Databricks ב- Google Cloud
- מידע נוסף על Databricks BigQuery
- קראו את הודעה על תמיכה ב-BigQuery בבלוג של Databricks.
- מידע נוסף על מחברות לדוגמה של BigQuery
- מידע נוסף על ספק Terraform ל-Databricks ב- Google Cloud
- אפשר לקרוא את הבלוג של Databricks, כולל מידע נוסף על נושאים במדע הנתונים ועל קבוצות נתונים.