
Lakehouse for Apache Iceberg is a managed data lakehouse platform on Google Cloud. At its core is the Lakehouse runtime catalog, a fully managed, serverless metastore service that serves as the single source of truth for your data. By centralizing this metadata, multiple processing engines—including Apache Spark, Apache Flink, Apache Hive, and BigQuery—can seamlessly share tables without duplicating files.
To connect your query engines to the metastore, you configure a client using an endpoint such as the Apache Iceberg REST catalog. This acts as a management interface within the Lakehouse runtime catalog to handle table metadata, while relying on Cloud Storage to store the underlying metadata and data files.
Key capabilities
As a key component of Lakehouse, the Lakehouse runtime catalog provides several advantages for data management and analysis, including a serverless architecture, engine interoperability with open APIs, a unified user experience, and high-performance analytics, streaming, and AI when you use it with BigQuery. For more information about these benefits, see What is Lakehouse?
How Lakehouse integrates with Google Cloud
To understand how Lakehouse manages your data, see how the Lakehouse for Apache Iceberg architecture integrates with Google Cloud services. Apache Iceberg doesn't store data in monolithic tables. Instead, it uses a layered architecture of metadata files to organize data files into a cohesive table structure with ACID transaction support.
The following diagram illustrates how compute engines like Managed Service for Apache Spark use the Lakehouse runtime catalog to manage table metadata to read and write underlying Parquet data files directly in Cloud Storage.
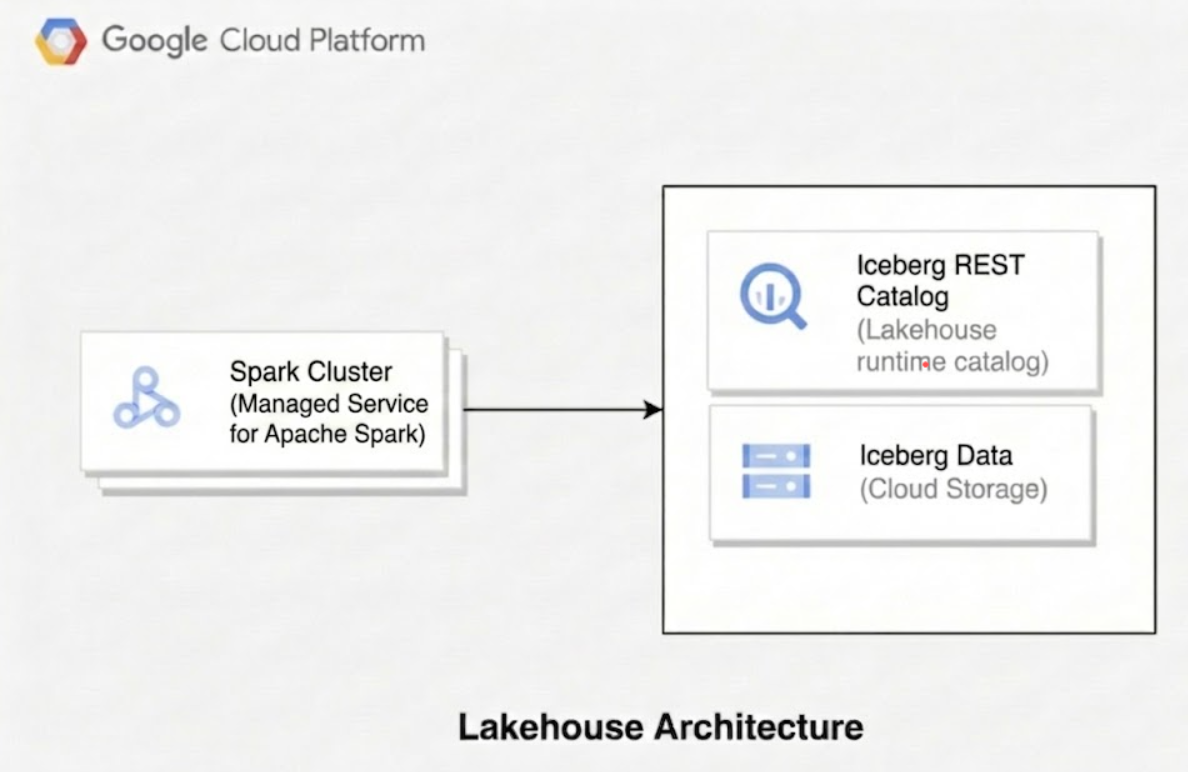
When you use Lakehouse for Apache Iceberg, the technical architecture consists of three distinct layers:
Catalog layer:
- Core Iceberg concept: The catalog stores the current state of the table by maintaining a pointer to the latest metadata file. This layer facilitates ACID compliance and transaction isolation to ensure that concurrent writes don't interfere with each other.
- Lakehouse implementation: The Lakehouse runtime catalog acts as the top-level regional metastore service. Within this service, you create individual catalogs to manage your data hierarchy. Client query engines connect to these catalogs by using specific endpoint catalog types, such as the Apache Iceberg REST catalog endpoint. The metastore manages transaction commits, credential vending for storage access delegation, and pointer management across your catalogs.
Metadata layer:
- Core Iceberg concept: This layer tracks the table structure,
snapshots, and file locations by using a hierarchy of three file types:
- Metadata files: Store the table's schema, partition specification, and a log of snapshot pointers.
- Manifest lists: Represent a single snapshot of the table by grouping a collection of manifest files.
- Manifest files: Track data at the individual file level, storing file paths, partition information, and column-level statistics, for example, row counts and minimum and maximum values, which are used for query optimization and partition pruning.
- Lakehouse implementation: Within a catalog container,
you organize your data into logical namespaces (similar to
datasets) and tables. For each table, the
Lakehouse runtime catalog generates and manages the
underlying Iceberg metadata hierarchy, starting with a root
metadata.jsonfile that points to the manifest lists and manifest files. The Lakehouse runtime catalog persists these files directly in your designated warehouse storage location.
- Core Iceberg concept: This layer tracks the table structure,
snapshots, and file locations by using a hierarchy of three file types:
Data layer:
- Core Iceberg concept: This component is the underlying storage where the actual raw data records reside, typically in optimized columnar or row-based open file formats such as Parquet, ORC, or Avro.
- Lakehouse implementation: When you configure Cloud
Storage warehouse locations (
bl://orgs://), the physical data files referenced by your tables are stored securely within your buckets. The Lakehouse runtime catalog manages access through storage access delegation (credential vending), vending short-lived access tokens directly to client engines. This lets engines read and write data files securely without requiring broad, direct IAM permissions on the underlying buckets.
How Lakehouse implements the Apache Iceberg REST Catalog API
The Lakehouse runtime catalog implements the open source Apache Iceberg REST Catalog API to manage namespaces and tables. It also provides an extensions API specifically for catalog management.
Client query engines interact with the metastore using these standard REST catalog APIs. For details about Google Cloud resources and endpoints, see the Lakehouse REST API reference.
You can create, configure, and manage these resources using the Google Cloud console, the gcloud CLI, the REST API, or Terraform. For more information, see the following pages:
- Manage Iceberg REST catalog resources
- Manage Lakehouse Iceberg REST catalog tables
- Use Terraform with Lakehouse
Query engine compatibility and configuration
To analyze and manage data in the Lakehouse runtime catalog, you can connect different open source and enterprise query engines. Depending on your existing architecture and workload requirements, you can choose from several supported engines and configure the appropriate catalog endpoint.
Supported engines
The Lakehouse runtime catalog is compatible with several query engines including (but not limited to) Apache Spark, Apache Flink, Apache Hive, and Trino. The following table provides links to documentation for each engine:
| Engine | Documentation |
|---|---|
| Apache Spark | Use with Apache Spark |
| Apache Hive | Use with Spark and the Hive catalog |
| Apache Flink | Use with Apache Flink |
| Trino | Use with Trino |
Catalog types and endpoint configuration
When configuring client engines to connect to the Lakehouse runtime catalog metastore, you select a specific catalog endpoint, such as the Apache Iceberg REST catalog endpoint or the Apache Hive endpoint. The best option depends on your use case, as shown in the following table:
| Use case | Recommendation |
|---|---|
| New Lakehouse runtime catalog users that want their open source engine to access data in Cloud Storage and need interoperability with other engines, including BigQuery and AlloyDB for PostgreSQL. | Use the Apache Iceberg REST catalog endpoint. |
| Users running Apache Hive or Spark workloads that depend on the Hive Metastore interface and want a fully managed metastore service. | Use the Apache Hive catalog endpoint. |
| Existing Lakehouse runtime catalog users that have current tables created with the custom Apache Iceberg catalog for BigQuery endpoint. | Continue using the custom Apache Iceberg catalog for BigQuery endpoint, but use the Apache Iceberg REST catalog for new workflows. |
Lakehouse runtime catalog limitations
The following general limitations apply to tables in the Lakehouse runtime catalog when querying them through BigQuery. Individual catalog endpoints (such as Apache Iceberg REST or Apache Hive) might have additional endpoint-specific limitations.
Table management
- Apache Iceberg V2 tables (GA) and V3 tables (Preview) are supported. Iceberg V1 tables aren't supported. Before you use existing V1 tables with the Lakehouse runtime catalog, you must upgrade them to a supported version. For more information, see Upgrade Iceberg V1 tables to V2.
- Tables in the Lakehouse runtime catalog don't support
renaming operations or the
ALTER TABLE ... RENAME TOSpark SQL statement. - Tables in the Lakehouse runtime catalog don't support clustering.
- Tables in the Lakehouse runtime catalog don't support flexible column names.
The Lakehouse runtime catalog doesn't support database or metastore views.
The Lakehouse runtime catalog doesn't support Apache Iceberg views.
Querying
- Query performance for tables in the Lakehouse runtime catalog from the BigQuery engine might be slow compared to querying data in standard BigQuery tables. In general, query speed should be equivalent to reading data from Cloud Storage.
- A BigQuery dry run of a query that uses a table in the Lakehouse runtime catalog might report a lower bound of 0 bytes of data, even if rows are returned. This result occurs because the amount of data that is processed from the table can't be determined until the full query is run. Running the query incurs a cost for processing this data.
- You can't reference a table in the Lakehouse runtime catalog in a wildcard table query.
API and metadata
- You can't use the
tabledata.listmethod to retrieve data from tables in the Lakehouse runtime catalog. Instead, you can save query results to a BigQuery table, and then use thetabledata.listmethod on that table. - The display of table storage statistics for tables in the Lakehouse runtime catalog isn't supported.
Quotas and limits
- Tables in the Lakehouse runtime catalog in BigQuery are subject to the same quotas and limits as standard tables.
Differences with BigLake metastore (classic)
The core differences between the Lakehouse runtime catalog and BigLake metastore (classic) include the following:
- The Lakehouse runtime catalog supports a direct integration with open source engines like Spark, which helps reduce redundancy when you store metadata and run jobs. Tables in the Lakehouse runtime catalog are directly accessible from multiple open source engines and BigQuery.
- The Lakehouse runtime catalog supports the Apache Iceberg REST catalog endpoint, while BigLake metastore (classic) doesn't.
What's next
- Understand the Apache Iceberg REST catalog endpoint.