
תרחישים לדוגמה
ארכיטקטורת ההפניה הזו של זמינות מתאימה לתרחישי השימוש הבאים:
- אפליקציות קריטיות לעסק שדורשות RTO ו-RPO נמוכים יותר.
- אתם רוצים לפרוס רפליקה באזור או בצומת אחרים שמספקים זמינות גבוהה למסדי הנתונים שלכם ומגנים מפני כשלים במופע, בשרת ובאזור.
- אתם רוצים הגנה מפני טעויות משתמשים ופגיעה בנתונים (באמצעות גיבויים).
איך פועלת ארכיטקטורת ההפניה
הזמינות המשופרת מוסיפה לזמינות הרגילה על ידי הוספה של מופעי העתקה לקריאה באזור כדי לאפשר זמינות גבוהה (HA) שמקצרת את היעד לזמן השחזור (RTO). בנוסף, הגישה הזו מקטינה את יעד נקודת השחזור (RPO) כי היא מאפשרת להזרים שינויים טרנזקציוניים אל הרפליקה.
זמינות גבוהה ב-AlloyDB Omni מתבססת על לפחות שני מופעי מסד נתונים. מופע אחד מתפקד כמסד הנתונים הראשי, שתומך בפעולות קריאה וכתיבה. המופעים הנותרים משמשים כרפליקות לקריאה, ופועלים במצב קריאה בלבד.
אלה מושגים חשובים שקשורים לזמינות גבוהה:
- יתירות כשל (Failover) הוא התהליך שמתבצע במהלך הפסקה זמנית בשירות לא מתוכננת, שבה המופע הראשי נכשל או הופך ללא זמין, והרפליקה במצב המתנה מופעלת כדי לעבור למצב ראשי (קריאה-כתיבה). התהליך הזה נקרא קידום. בדרך כלל, בתרחישים כאלה, כשהשרת הראשי או מסד הנתונים חוזרים למצב אונליין, צריך לבנות מחדש את מסד הנתונים ואז הוא צריך לפעול כגיבוי. כדי לספק זמינות גבוהה, יש מנגנונים שמבצעים מעבר לגיבוי אוטומטי.
- מעבר, שנקרא גם היפוך תפקידים, הוא הליך שמשמש למעבר בין המצבים של מסד הנתונים הראשי ואחד ממסדי הנתונים במצב המתנה, כך שמסד הנתונים הראשי הופך למסד נתונים במצב המתנה ומסד הנתונים במצב המתנה הופך למסד הנתונים הראשי. המעבר מתבצע בדרך כלל בצורה מבוקרת וחלקה, ויכולות להיות לכך סיבות שונות, למשל כדי לאפשר השבתה ותיקון של מסד הנתונים הראשי הקודם. מעברים חלקים צריכים לאפשר מעבר חזרה בעתיד בלי ליצור מחדש את הגיבוי החדש או היבטים אחרים של הגדרת השכפול.
אפשרויות לזמינות גבוהה
בפריסות שאינן Kubernetes, משתמשים ב-Patroni וב-HAProxy. מידע נוסף זמין במאמר ארכיטקטורת זמינות גבוהה ב-AlloyDB Omni ל-PostgreSQL.
| הערה: Patroni ו-HAProxy הם כלים לשימוש לא מסחרי של צד שלישי, והם תואמים ל-AlloyDB Omni. |
|---|
מומלץ להגדיר לפחות שני מסדי נתונים במצב המתנה, כדי שאובדן של מסד נתונים אחד לא ישפיע על הזמינות הגבוהה של האשכול. במצב הזה, יש לכם לפחות זוג HA אחד במקרה של מעבר לגיבוי או במהלך תחזוקה מתוכננת של צומת.
כדי לתכנן את הגודל והצורה של פריסת AlloyDB Omni, אפשר לעיין במאמר תכנון ההתקנה של AlloyDB Omni במכונה וירטואלית.
מאזני עומסים
מנגנון חשוב נוסף שמסייע להחלפה חלקה יותר של שרתים ולמעבר לגיבוי הוא נוכחות של מאזן עומסים.
בפריסות שאינן Kubernetes, תוכנת HAProxy מספקת איזון עומסים. HAProxy מציע איזון עומסים על ידי חלוקת תנועת הרשת בין כמה שרתים. בנוסף, HAProxy מבצע בדיקות תקינות כדי לשמור על מצב התקינות של שרתי הקצה העורפי שאליהם הוא מתחבר. אם שרת נכשל בבדיקת תקינות, HAProxy מפסיק לשלוח אליו תנועה עד שהוא עובר שוב את בדיקות התקינות.
זמינות גבוהה
מסדי נתונים של רפליקות לקריאה שנפרסים באזור מסוים מספקים זמינות גבוהה אם מסד הנתונים הראשי נכשל. אם מתרחש כשל במסד הנתונים הראשי, מסד הנתונים במצב המתנה מקודם כדי להחליף את הראשי, והאפליקציה ממשיכה לפעול עם מעט שיבושים או ללא שיבושים בכלל.
מומלץ לבצע בדיקות שנתיות או דו-שנתיות קבועות בצורה של מעבר בין מסדי נתונים, כדי לוודא שכל האפליקציות שמסתמכות על מסדי הנתונים האלה עדיין יכולות להתחבר ולהגיב בפרק זמן מתאים.
אפשר להשיג הגנה ברמת האזור באמצעות כל אחד מסוגי הפריסה, על ידי הצבת אחת מהרפליקות לקריאה במצב המתנה באזור זמינות שונה ממסד הנתונים הראשי.
יתרון נוסף של רפליקות לקריאה הוא האפשרות להפחית עומס של פעולות לקריאה בלבד למסדי הנתונים במצב המתנה, שיכולים לשמש כמסדי נתונים לדיווח עם נתונים עדכניים. הגישה הזו מפחיתה את העומס ואת התקורה בשרת הראשי לקריאה וכתיבה.
גיבויים והגדרת זמינות גבוהה
אפשר להגדיר רפליקות לקריאה בכמה אזורים כדי לספק זמינות גבוהה. הם מספקים RTO ו-RPO נמוכים, אבל לא מגינים מפני הפסקות מסוימות, כמו פגם לוגי בנתונים, למשל מחיקה של טבלה בטעות או עדכוני נתונים שגויים. לכן, בנוסף להגדרת HA, צריך לבצע גיבויים באופן קבוע. פרטים נוספים זמינים במסמכי התיעוד בנושא ארכיטקטורה של זמינות רגילה.
איור 1 מציג הגדרת HA מומלצת עם שני מסדי נתונים של העתקי קריאה במצב המתנה בשני אזורי זמינות שונים.
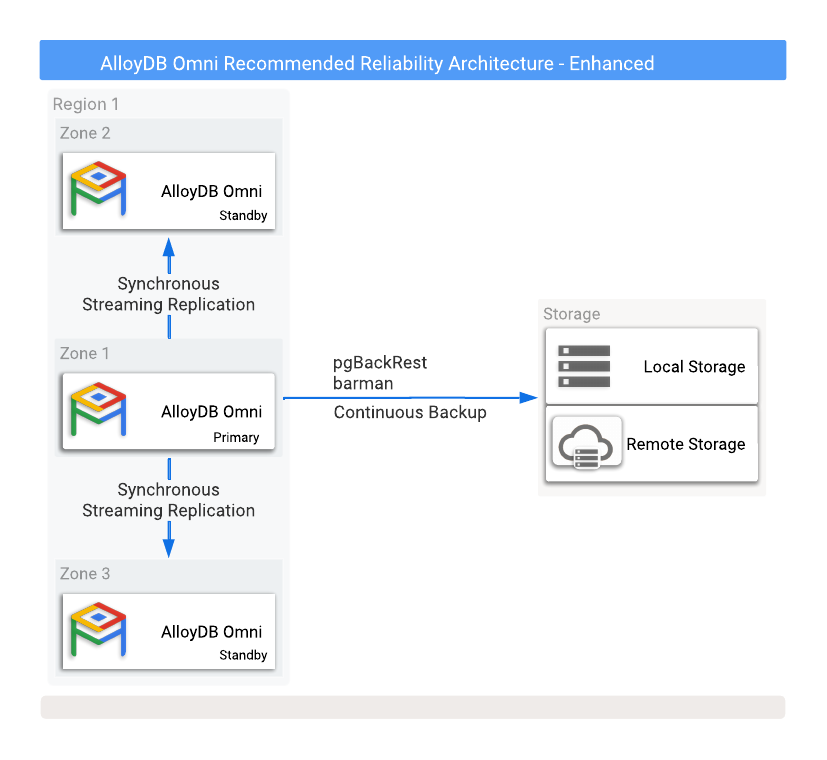
איור 1. AlloyDB Omni עם גיבויים ואפשרויות לזמינות גבוהה.
כדי להגן מפני אובדן נתונים אם המופע הראשי נכשל, צריך להגדיר שכפול במצב סינכרוני. השיטה הזו מספקת הגנה חזקה על הנתונים, אבל היא עלולה להשפיע על הביצועים של מסד הנתונים הראשי כי צריך לכתוב את כל הפעולות גם במסד הנתונים הראשי וגם בכל מסדי הנתונים המסונכרנים של הגיבוי. חיבור רשת עם השהיה נמוכה בין מופעי מסד הנתונים האלה הוא חיוני להגדרה הזו.
פריסות HA שאינן Kubernetes
פריסת ה-standalone שאינה Kubernetes היא הגדרה ידנית שדורשת כלים של צד שלישי, והיא מורכבת יותר להגדרה ולתחזוקה מאשר פריסת Kubernetes.
כשמשתמשים בפריסה שאינה Kubernetes, יש כמה פרמטרים שמשפיעים על האופן שבו המערכת מזהה יתירות כשל ועל הזמן שחולף עד ליתירות כשל אחרי שהשרת הראשי הופך ללא זמין. בהמשך מופיע סיכום קצר של הפרמטרים האלה:
-
Ttl: הזמן המקסימלי שנדרש כדי לקבל נעילה של מסד הנתונים הראשי לפני הפעלת יתירות כשל. ברירת המחדל היא 30 שניות. -
Loop_wait: משך הזמן להמתנה לפני בדיקה חוזרת. ברירת המחדל היא 10 שניות. -
Retry_timeout: הזמן הקצוב לתפוגה לפני הורדת הרמה של המכונה הראשית בגלל כשל ברשת. ברירת המחדל היא 10 שניות.
למידע נוסף, ראו ארכיטקטורת זמינות גבוהה של AlloyDB Omni ל-PostgreSQL.
הטמעה
כשבוחרים ארכיטקטורת הפניה לזמינות, חשוב לקחת בחשבון את היתרונות, המגבלות והחלופות הבאים.
יתרונות
- הגנה מפני כשלים במופע.
- הגנה מפני כשלים בשרת.
- הגנה מפני כשלים באזורים.
- זמן ההתאוששות (RTO) קצר משמעותית בהשוואה לזמינות רגילה.
מגבלות
- אין הגנה נוספת מפני אסונות אזוריים.
- השפעה פוטנציאלית על הביצועים של השרת הראשי בגלל שכפול סינכרוני.
- הגדרת הזרמת WAL של PostgreSQL במצב סינכרוני מאפשרת אפס אובדן נתונים (
RPO=0) במהלך פעולה רגילה או מעברים סטנדרטיים לגיבוי. עם זאת, הגישה הזו לא מגנה מפני אובדן נתונים במצבים ספציפיים של כשל כפול, למשל כשכל המופעים במצב המתנה אובדים או שלא ניתן להגיע אליהם מהמופע הראשי, ומיד לאחר מכן מתבצעת הפעלה מחדש של המופע הראשי.
חלופות
- ארכיטקטורת זמינות רגילה לאפשרויות גיבוי ושחזור.
- ארכיטקטורת הזמינות של Premium עבור תוכנית התאוששות מאסון ברמת האזור, רפליקות קריאה נוספות והיקף תוכנית התאוששות מאסון מורחב.
המאמרים הבאים
- סקירה כללית של תרשים עזר לארכיטקטורת הזמינות של AlloyDB Omni.
- זמינות רגילה של AlloyDB Omni.
- זמינות של AlloyDB Omni Premium.
- תכנון ההתקנה של AlloyDB Omni במכונה וירטואלית
- ארכיטקטורה של זמינות גבוהה ב-AlloyDB Omni ל-PostgreSQL.