
Cuando graficas el rendimiento a lo largo del tiempo a medida que se modifica otra variable, por lo general, ves que el rendimiento aumenta hasta que alcanza un punto de agotamiento de recursos.
En la siguiente figura, se muestra un gráfico típico de ajuste del procesamiento. A medida que aumenta la cantidad de clientes, también lo hacen la carga de trabajo y el rendimiento hasta que se agotan todos los recursos.
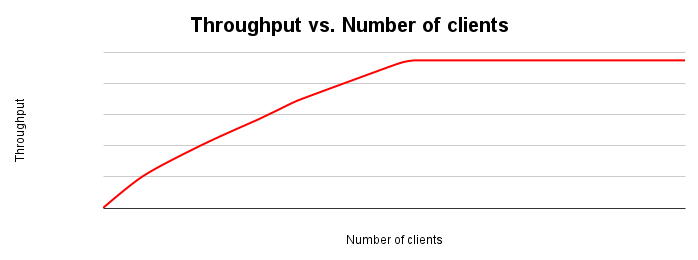
Lo ideal es que, a medida que dupliques la carga en el sistema, también se duplique la capacidad de procesamiento. En la práctica, habrá contención en los recursos, lo que generará aumentos más pequeños en la capacidad de procesamiento. En algún momento, el agotamiento o la contención de recursos harán que el rendimiento se estabilice o incluso disminuya. Si optimizas la capacidad de procesamiento, este es un punto clave que debes identificar, ya que dirige tus esfuerzos hacia dónde ajustar el sistema de la aplicación o la base de datos para mejorar la capacidad de procesamiento.
Entre los motivos típicos por los que el rendimiento se estabiliza o disminuye, se incluyen los siguientes:
- Agotamiento de los recursos de CPU en el servidor de la base de datos
- Agotamiento de los recursos de CPU en el cliente, por lo que no se envía más trabajo al servidor de la base de datos
- Contención de bloqueo de la base de datos
- Tiempo de espera de E/S cuando los datos superan el tamaño del grupo de búfer de Postgres
- Tiempo de espera de E/S debido a la utilización del motor de almacenamiento
- Cuellos de botella en el ancho de banda de la red que devuelven datos al cliente
La latencia y la capacidad de procesamiento son inversamente proporcionales. A medida que aumenta la latencia, disminuye la capacidad de procesamiento. Intuitivamente, esto tiene sentido. A medida que comienza a materializarse un cuello de botella, las operaciones tardan más y el sistema realiza menos operaciones por segundo.
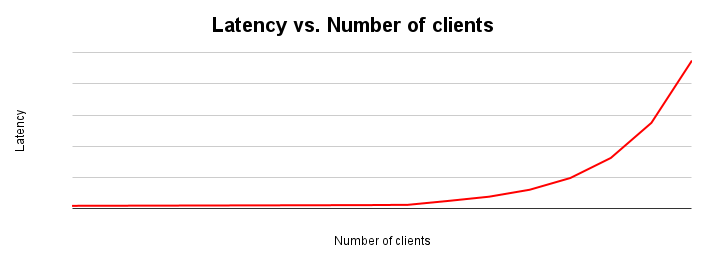
El gráfico de ajuste de la latencia muestra cómo cambia la latencia a medida que aumenta la carga que se aplica a un sistema. La latencia se mantiene relativamente constante hasta que se produce fricción debido a la contención de recursos. El punto de inflexión de esta curva generalmente corresponde al aplanamiento de la curva de capacidad de procesamiento en el gráfico de ajuste de la capacidad de procesamiento.
Otra forma útil de evaluar la latencia es como un histograma. En esta representación, agrupamos las latencias en buckets y contamos cuántas solicitudes corresponden a cada bucket.
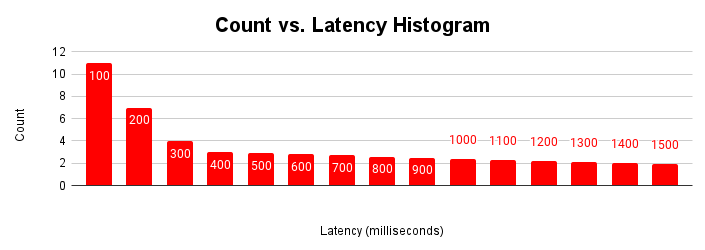
Este histograma de latencia muestra que la mayoría de las solicitudes tienen una latencia inferior a 100 milisegundos y que las latencias superiores a 100 milisegundos son menos frecuentes. Comprender la causa de las solicitudes con una latencia final más larga puede ayudar a explicar las variaciones en el rendimiento de la aplicación que se observan. Las causas de la cola larga de latencias aumentadas corresponden a las latencias aumentadas que se observan en el gráfico típico de ajuste de latencia y el aplanamiento del gráfico de capacidad de procesamiento.
El histograma de latencia es más útil cuando hay varias modalidades en una aplicación. Una modalidad es un conjunto normal de condiciones de funcionamiento. Por ejemplo, la mayoría de las veces, la aplicación accede a páginas que se encuentran en la caché de búfer. La mayoría de las veces, la aplicación actualiza las filas existentes, pero puede haber varios modos. En ocasiones, la aplicación recupera páginas del almacenamiento, inserta filas nuevas o experimenta contención de bloqueo.
Cuando una aplicación encuentra estos diferentes modos de operación con el tiempo, el histograma de latencia muestra estas múltiples modalidades.
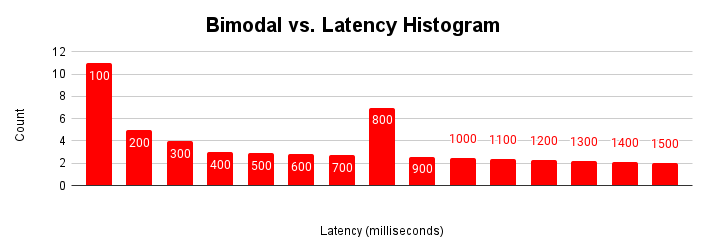
En esta figura, se muestra un histograma bimodal típico en el que la mayoría de las solicitudes se atienden en menos de 100 milisegundos, pero hay otro clúster de solicitudes que tardan entre 401 y 500 milisegundos. Comprender la causa de esta segunda modalidad puede ayudar a mejorar el rendimiento de tu aplicación. También puede haber más de dos modalidades.
La segunda modalidad podría deberse a operaciones normales de la base de datos, a una infraestructura y topología heterogéneas, o bien al comportamiento de la aplicación. Estos son algunos ejemplos que debes tener en cuenta:
- La mayoría de los accesos a los datos provienen del búfer de PostgreSQL, pero algunos provienen del almacenamiento.
- Diferencias en las latencias de red para algunos clientes en el servidor de la base de datos
- Lógica de la aplicación que realiza diferentes operaciones según la entrada o la hora del día
- Contención de bloqueo esporádica
- Aumentos repentinos en la actividad del cliente