
Anwendungsfälle
Diese Referenzarchitektur für die Verfügbarkeit eignet sich für die folgenden Anwendungsfälle:
- Geschäftskritische Anwendungen, die niedrigere RTO und RPO erfordern.
- Sie möchten ein Replikat in einer anderen Zone oder auf einem anderen Knoten bereitstellen, das Hochverfügbarkeit für Ihre Datenbanken bietet und vor Instanz-, Server- und Zonenausfällen schützt.
- Sie möchten sich vor Nutzerfehlern und Datenbeschädigung schützen (mithilfe von Sicherungen).
Funktionsweise der Referenzarchitektur
Die erweiterte Verfügbarkeit ergänzt die Standardverfügbarkeit durch das Hinzufügen von Lesereplikat-Instanzen in der Region, um Hochverfügbarkeit (HA) zu ermöglichen, die das Recovery Time Objective (RTO) reduziert. Dieser Ansatz reduziert auch das Recovery Point Objective (RPO), da transaktionale Änderungen an das Replikat gestreamt werden können.
Die Hochverfügbarkeit in AlloyDB Omni nutzt mindestens zwei Datenbankinstanzen. Eine Instanz fungiert als primäre Datenbank und unterstützt Lese- und Schreibvorgänge. Die verbleibenden Instanzen dienen als Lesereplikate und werden im Lesemodus ausgeführt.
Im Folgenden finden Sie wichtige HA-Konzepte:
- Failover ist das Verfahren bei einem ungeplanten Ausfall, bei dem die primäre Instanz ausfällt oder nicht mehr verfügbar ist und das Standby-Replikat aktiviert wird, um den primären (Lese-/Schreib-)Modus zu übernehmen. Dieser Vorgang wird als Promotion bezeichnet. Wenn der primäre Server oder die primäre Datenbank in diesen Szenarien wieder online ist, muss die Datenbank in der Regel neu erstellt werden und dann als Standby-Datenbank fungieren. Für eine hohe Verfügbarkeit sind Mechanismen vorhanden, die Failovers automatisch ausführen.
- Ein Wechsel, auch Rollenumkehr genannt, ist ein Verfahren, mit dem die Modi zwischen der primären Datenbank und einer der Standby-Datenbanken gewechselt werden. Die primäre Datenbank wird dabei zur Standby-Datenbank und die Standby-Datenbank zur primären Datenbank. Wechsel erfolgen in der Regel kontrolliert und reibungslos. Sie können aus verschiedenen Gründen initiiert werden, z. B. um Ausfallzeiten und Patches der bisherigen primären Datenbank zu ermöglichen. Ein reibungsloser Wechsel muss die Möglichkeit bieten, dass es einen nachfolgenden Rückwechsel geben kann, ohne dass die neue Standby-Datenbank oder andere Aspekte der Replikationskonfiguration neu instanziiert werden müssen.
Optionen für Hochverfügbarkeit
Verwenden Sie in Nicht-Kubernetes-Bereitstellungen Patroni und HAProxy. Weitere Informationen finden Sie unter Hochverfügbarkeitsarchitektur für AlloyDB Omni for PostgreSQL.
| Hinweis: Patroni und HAProxy sind nicht kommerzielle Drittanbietertools, die mit AlloyDB Omni kompatibel sind. |
|---|
Wir empfehlen, mindestens zwei Standby-Datenbanken zu haben, damit der Verlust einer Datenbank die Hochverfügbarkeit des Clusters nicht beeinträchtigt. In diesem Modus haben Sie im Falle eines Failovers oder während einer geplanten Wartung eines Knotens mindestens ein HA-Paar.
Informationen zur Planung der Größe und Form Ihrer AlloyDB Omni-Bereitstellung finden Sie unter AlloyDB Omni-Installation auf einer VM planen.
Load Balancer
Ein weiterer wichtiger Mechanismus, der reibungslosere Wechsel- und Failover-Verfahren unterstützt, ist das Vorhandensein eines Load Balancers.
Bei Nicht-Kubernetes-Bereitstellungen sorgt die HAProxy-Software für Load-Balancing. HAProxy bietet Load-Balancing, indem es den Netzwerkverkehr auf mehrere Server verteilt. HAProxy führt auch Systemdiagnosen durch, um den Status der Backend-Server zu ermitteln, mit denen es eine Verbindung herstellt. Wenn ein Server eine Systemdiagnose nicht besteht, sendet HAProxy keinen Traffic mehr an ihn, bis er die Systemdiagnosen wieder besteht.
Hochverfügbarkeit
Die in einer Region bereitgestellten Lesereplikat-Datenbanken bieten Hochverfügbarkeit, falls die primäre Datenbank ausfällt. Wenn die primäre Datenbank ausfällt, wird die Standby-Datenbank zur primären Datenbank hochgestuft und die Anwendung wird mit geringen oder keinen Ausfallzeiten fortgesetzt.
Es empfiehlt sich generell, regelmäßig (jährlich oder halbjährlich) Prüfungen in Form von Wechseln durchzuführen, um sicherzustellen, dass alle Anwendungen, die auf diese Datenbanken angewiesen sind, weiterhin innerhalb eines angemessenen Zeitrahmens eine Verbindung herstellen und reagieren können.
Der Schutz auf Zonenebene kann mit beiden Bereitstellungstypen erreicht werden, indem eines der Standby-Lesereplikate in einer anderen Verfügbarkeitszone als der der primären Datenbank platziert wird.
Ein weiterer Vorteil von Lesereplikaten ist die Möglichkeit, schreibgeschützte Vorgänge auf die Standby-Datenbanken auszulagern, die als Berichtsdatenbanken mit aktuellen Daten fungieren können. Dieser Ansatz reduziert die Last und den Aufwand für die primäre Lese-/Schreib-Datenbank.
Sicherungen und Konfiguration für Hochverfügbarkeit
Lesereplikate können in mehreren Zonen eingerichtet werden, die Hochverfügbarkeit bieten. Sie bieten zwar niedrige RTO und RPO, schützen aber nicht vor bestimmten Ausfällen wie logischer Datenbeschädigung, z. B. versehentlichem Löschen von Tabellen oder falschen Datenaktualisierungen. Daher sind zusätzlich zur HA-Einrichtung regelmäßige Sicherungen erforderlich. Weitere Informationen finden Sie in der Dokumentation zur Standard-Verfügbarkeitsarchitektur.
Abbildung 1 zeigt eine empfohlene HA-Konfiguration mit zwei Lesereplikat-Standbydatenbanken in zwei verschiedenen Verfügbarkeitszonen.
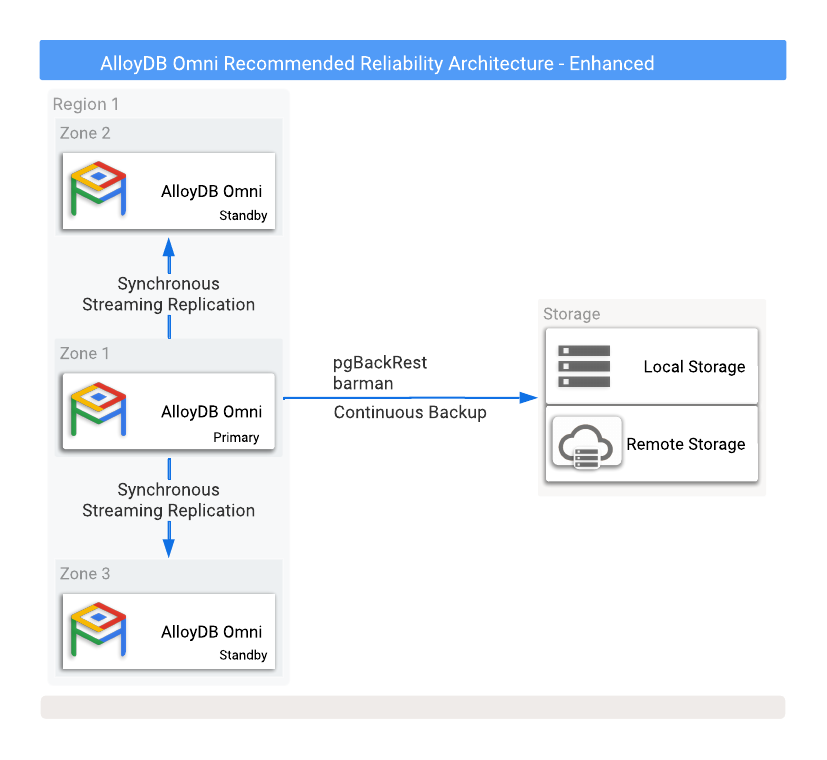
Abbildung 1. AlloyDB Omni mit Optionen für Sicherungen und Hochverfügbarkeit
Um Datenverlust zu vermeiden, wenn die primäre Instanz ausfällt, ist es erforderlich, die Replikation im synchronen Modus zu konfigurieren. Diese Methode bietet zwar einen hohen Datenschutz, kann sich aber auf die Leistung der primären Datenbank auswirken, da alle Commits sowohl in die primäre als auch in alle synchronisierten Standby-Datenbanken geschrieben werden müssen. Für diese Einrichtung ist eine Netzwerkverbindung mit geringer Latenz zwischen diesen Datenbankinstanzen von entscheidender Bedeutung.
HA-Deployments ohne Kubernetes
Die eigenständige Bereitstellung ohne Kubernetes ist eine manuelle Konfiguration, für die Drittanbietertools erforderlich sind. Die Einrichtung und Wartung ist komplexer als bei der Kubernetes-Bereitstellung.
Wenn Sie ein Nicht-Kubernetes-Deployment verwenden, gibt es einige Parameter, die sich darauf auswirken, wie ein Failover erkannt wird und wie schnell ein Failover erfolgt, nachdem der primäre Server nicht mehr verfügbar ist. Im Folgenden finden Sie eine kurze Zusammenfassung dieser Parameter:
Ttl: Die maximale Zeit, die zum Erwerben einer Sperre für die primäre Datenbank benötigt wird, bevor ein Failover eingeleitet wird. Der Standardwert ist 30 Sekunden.Loop_wait: Die Wartezeit vor dem erneuten Prüfen. Der Standardwert beträgt 10 Sekunden.Retry_timeout: Das Zeitlimit, bevor die primäre Instanz aufgrund eines Netzwerkfehlers herabgestuft wird. Der Standardwert beträgt 10 Sekunden.
Weitere Informationen finden Sie unter Hochverfügbarkeitsarchitektur für AlloyDB Omni for PostgreSQL.
Implementierung
Wenn Sie eine Referenzarchitektur für die Verfügbarkeit auswählen, sollten Sie die folgenden Vorteile, Einschränkungen und Alternativen berücksichtigen.
Vorteile
- Schützt vor Instanzfehlern
- Schützt vor Serverausfällen
- Schützt vor Zonenausfällen
- RTO im Vergleich zur Standardverfügbarkeit deutlich kürzer
Beschränkungen
- Kein zusätzlicher Schutz vor regionalen Katastrophen
- Mögliche Auswirkungen auf die Leistung der primären Datenbank aufgrund der synchronen Replikation
- Wenn Sie das PostgreSQL-WAL-Streaming im synchronen Modus konfigurieren, kommt es bei normalem Betrieb oder typischen Failovern zu keinem Datenverlust (
RPO=0). Dieser Ansatz schützt jedoch nicht vor Datenverlust in bestimmten Situationen mit doppelten Fehlern, z. B. wenn alle Standby-Instanzen verloren gehen oder von der primären Datenbank aus nicht mehr erreichbar sind und dies unmittelbar von einem Neustart der primären Datenbank gefolgt wird.
Alternativen
- Die Standard-Verfügbarkeitsarchitektur für Sicherungs- und Wiederherstellungsoptionen.
- Die Premium-Verfügbarkeitsarchitektur für die Notfallwiederherstellung auf Regionsebene, zusätzliche Lesereplikate und eine erweiterte Reichweite der Notfallwiederherstellung.
Nächste Schritte
- Referenzarchitektur für die AlloyDB Omni-Verfügbarkeit – Übersicht
- AlloyDB Omni-Standardverfügbarkeit.
- AlloyDB Omni-Premiumverfügbarkeit.
- AlloyDB Omni-Installation auf einer VM planen
- Hochverfügbarkeitsarchitektur für AlloyDB Omni for PostgreSQL