
本頁說明如何使用查詢洞察資訊主頁,偵測及分析效能問題。如需這項功能的總覽,請參閱「查詢洞察總覽」。
您可以使用 Gemini Cloud Assist 監控及排解 AlloyDB 資源問題。詳情請參閱「透過 Gemini 輔助監控及排解問題」。
限制
如果您的執行個體使用 PostgreSQL 18 (搶先版),且查詢在 SQL 陳述式開頭前有註解標記,則使用查詢洞察時,系統可能不會儲存應用程式標記。
事前準備
如要查看查詢計畫或執行端對端追蹤,您或其他使用者必須具備特定的 Identity and Access Management (IAM) 權限。您可以建立自訂角色,並新增必要的 IAM 權限。接著,您可以將這個角色新增至每個使用查詢洞察資料排解問題的使用者帳戶。請參閱「建立自訂角色」。
自訂角色必須具備下列 IAM 權限:cloudtrace.traces.get。
開啟查詢洞察資訊主頁
如要開啟查詢洞察資訊主頁,請按照下列步驟操作:
- 在叢集和執行個體清單中,按一下執行個體。
- 在叢集總覽頁面的指標圖表下方,按一下「前往查詢洞察,深入瞭解查詢和效能」,或選取左側導覽面板中的「查詢洞察」分頁標籤。
在後續頁面中,您可以使用下列選項篩選結果:
- 執行個體選取器。可讓您選取叢集中的主要執行個體或讀取集區執行個體。根據預設,系統會選取主要執行個體。 顯示的詳細資料是所有已連線讀取集區執行個體及其節點的匯總資料。
- 資料庫。篩選特定資料庫或所有資料庫的查詢負載。
- 使用者。篩選特定使用者帳戶的查詢負載。
- 用戶端位址。篩選來自特定 IP 位址的查詢負載。
- 時間範圍。依時間範圍 (例如小時、天、週或自訂範圍) 篩選查詢負載。
編輯查詢洞察設定
AlloyDB 執行個體預設會啟用查詢洞察功能。您可以編輯預設的查詢洞察設定。
如要編輯 AlloyDB 執行個體的查詢洞察設定,請按照下列步驟操作:
控制台
前往 Google Cloud 控制台的「Clusters」(叢集) 頁面。
按一下「資源名稱」欄中的叢集。
按一下左側導覽面板中的「查詢洞察」。
從「查詢洞察」清單中選取「主要」或「讀取集區」,然後按一下「編輯」。
編輯「查詢洞察」欄位:
如要變更 AlloyDB 分析查詢長度的預設限制 (1024 個位元組),請在「查詢長度」欄位中輸入 256 到 4500 之間的數字。
編輯這個欄位後,執行個體會重新啟動。
注意:查詢長度限制越高,所需記憶體就越多。
如要自訂查詢洞察特徵集,請調整下列選項:
查詢計畫取樣:選取這個核取方塊,即可查看用來完成查詢取樣的作業。取樣率決定 AlloyDB 每分鐘可為每個節點取樣的查詢數量上限。
在「Maximum sampling rate」(取樣率上限) 欄位中,輸入 1 到 20 之間的數字。取樣率預設為 5。如要停用取樣,請取消勾選「查詢計畫取樣」核取方塊。
儲存用戶端 IP 位址:選取這個核取方塊,即可瞭解查詢的來源,並將相關資訊分組來計算指標。
儲存應用程式標記:勾選這個核取方塊,即可瞭解哪些已標記的應用程式正在發出要求,並將相關資訊分組以計算指標。如要進一步瞭解應用程式標記,請參閱規格。
按一下「更新執行個體」。
gcloud
如要使用 Google Cloud CLI 指令為 AlloyDB 執行個體啟用查詢洞察,請按照下列步驟操作:
- 安裝 Google Cloud CLI。
- 執行下列指令,初始化 gcloud CLI:
gcloud init
如果您使用本機殼層,請為使用者帳戶建立本機驗證憑證:
gcloud auth application-default login
如果您使用 Cloud Shell,則不需要執行這項操作。
詳情請參閱「設定本機開發環境的驗證機制」。
範例如下:
gcloud alloydb instances update INSTANCE \
--cluster=CLUSTER \
--project=PROJECT \
--region=REGION \
--insights-config-query-string-length=QUERY_LENGTH \
--insights-config-query-plans-per-minute=QUERY_PLANS \
--insights-config-record-application-tags \
--insights-config-record-client-address更改下列內容:
INSTANCE:要更新的執行個體 IDCLUSTER:執行個體叢集的 IDPROJECT:叢集專案的 IDREGION:叢集所在的區域,例如us-central1QUERY_LENGTH:查詢長度,範圍為 256 到 4500QUERY_PLANS:每分鐘要設定的查詢計畫數量。
此外,您也可以使用下列一或多個選用旗標:
--insights-config-query-string-length:將預設查詢長度限制設為指定值,範圍為 256 到 4500 個位元組。預設查詢長度為 1024 個位元組。 查詢越長,越適合用於分析型查詢,但所需記憶體也越多。變更查詢長度後,您必須重新啟動執行個體。 即使查詢超過長度限制,您還是可以新增標記。--insights-config-query-plans-per-minute:根據預設,執行個體的所有資料庫每分鐘最多可擷取五個已執行的查詢方案樣本。請將這個值變更為介於 1 至 20 之間的數字。如要停用取樣功能,請輸入 0。 提高取樣率或許可以產生更多資料點,但也有可能增加效能負擔。--insights-config-record-client-address:儲存查詢來源的用戶端 IP 位址,並協助您將資料分組,據此計算指標。查詢來自多個主機。查看來自用戶端 IP 位址的查詢圖表,有助於找出問題來源。如不想儲存用戶端 IP 位址,請使用--no-insights-config-record-client-address。--insights-config-record-application-tags:儲存應用程式標記,協助您判斷哪些 API 和模型檢視控制器 (MVC) 路徑正在發出要求,並將資料分組以產生相關指標。這個選項需要您使用特定標記組合註解查詢。如不想儲存應用程式標記,請使用--no-insights-config-record-application-tags。
Terraform
如要使用 Terraform 設定查詢洞察,請使用 google_alloydb_instance 資源。
範例如下:
query_insights_config {
query_string_length = QUERY_STRING_LENGTH_VALUE
record_application_tags = RECORD_APPLICATION_TAG_VALUE
record_client_address = RECORD_CLIENT_ADDRESS_VALUE
query_plans_per_minute = QUERY_PLANS_PER_MINUTE_VALUE5
}
更改下列內容:
QUERY_STRING_LENGTH_VALUE:查詢字串長度。預設值為1024。介於 256 到 4500 之間的任何整數都有效。RECORD_APPLICATION_TAG_VALUE:記錄執行個體的應用程式標記。預設值為true。RECORD_CLIENT_ADDRESS_VALUE:執行個體的記錄用戶端位址。預設值為true。QUERY_PLANS_PER_MINUTE_VALUE:洞察功能每分鐘擷取的查詢執行計畫數量 (所有查詢加總)。預設值為5。介於 0 到 20 之間的任何整數皆有效。如要瞭解如何套用或移除 Terraform 設定,請參閱「基本 Terraform 指令」。
新增查詢洞察設定後,範例執行個體設定應如下所示:
resource "google_alloydb_instance" "instance_name" { provider = "google-beta" cluster = google_alloydb_cluster.default.name instance_id = "instance_id" instance_type = "PRIMARY" machine_config { cpu_count = 8 } query_insights_config { query_string_length = 1024 record_application_tags = false record_client_address = false query_plans_per_minute = 5 } depends_on = [google_alloydb_instance.default] }
REST v1
這個範例會設定 AlloyDB 執行個體的觀測性設定。如需此呼叫的完整參數清單,請參閱「方法:projects.locations.clusters.instances.patch」。
如要設定查詢洞察,請視需要修改選填欄位。如需這項呼叫的完整欄位清單,請參閱 QueryInsightsInstanceConfig。
使用任何要求資料之前,請先替換以下項目:
CLUSTER_ID:您建立的叢集 ID。開頭須為小寫英文字母,且只能由小寫英文字母、數字和連字號組成。PROJECT_ID:您要放置叢集的專案 ID。LOCATION_ID:叢集所在區域的 ID。INSTANCE_ID:要建立的主要執行個體名稱。
如要修改執行個體設定,請使用下列 PATCH 要求:
PATCH https://alloydb.googleapis.com/v1beta/{instance.name=projects/PROJECT_ID/locations/LOCATION_ID/clusters/CLUSTER_ID/instances/INSTANCE_ID?updateMask=observabilityConfig.enabled}
設定所有可觀測性欄位的要求 JSON 主體如下所示:
{
"queryStringLength": integer,
"recordApplicationTags": boolean,
"recordClientAddress": boolean,
"queryPlansPerMinute": integer
}
改善查詢效能
查詢洞察功能可對 AlloyDB 查詢進行疑難排解,找出效能問題。查詢洞察資訊主頁會根據您選取的因素,顯示查詢負載。查詢負載可測量指定時間範圍內,執行個體中所有查詢的總工作量。
查詢洞察功能可協助您偵測及分析查詢效能問題。如要使用查詢洞察功能排解查詢問題,請按照下列步驟操作:
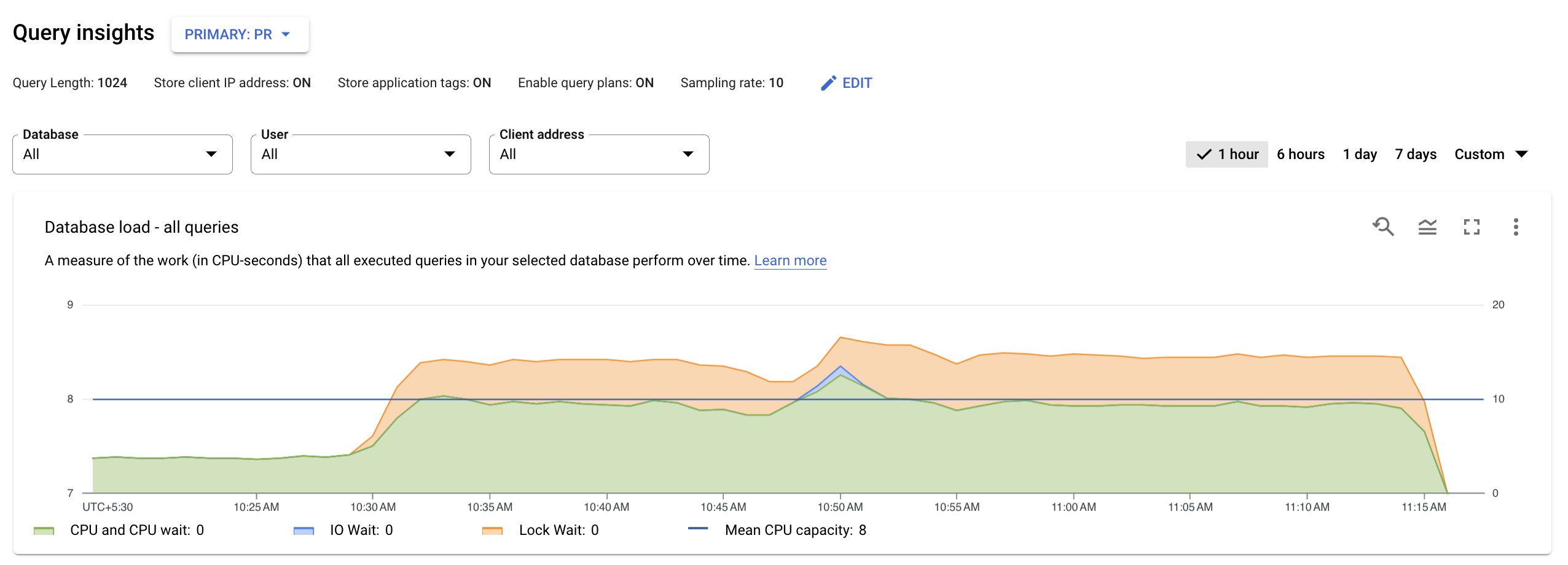
查看所有查詢的資料庫負載
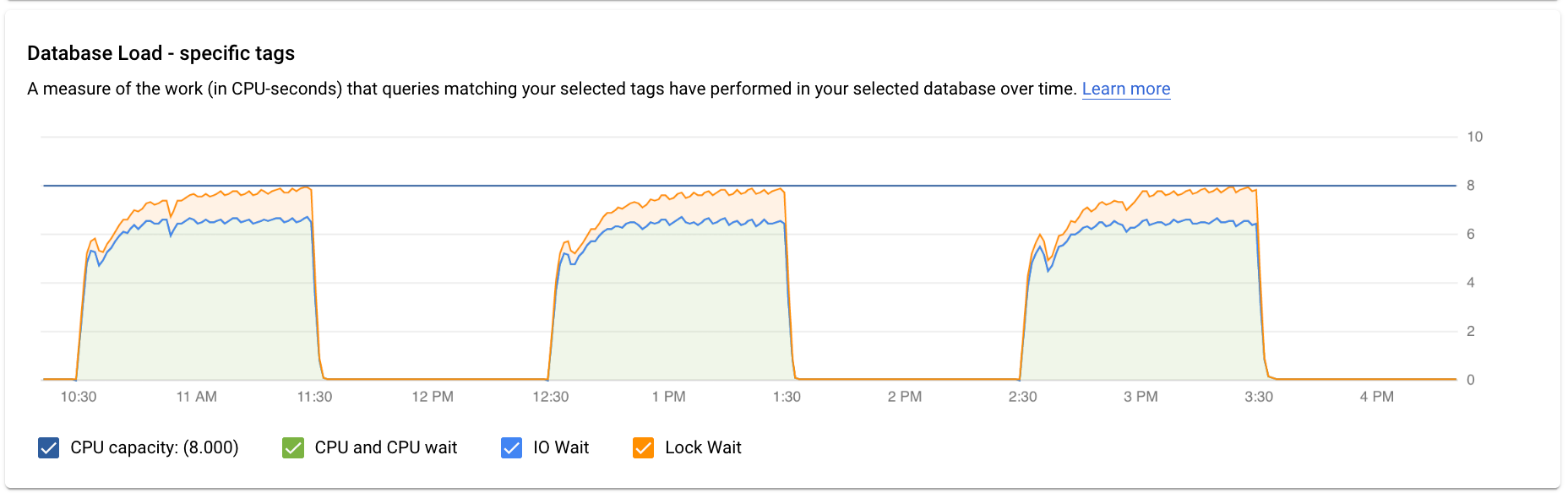
最上層的查詢洞察資訊主頁會使用篩選後的資料,顯示「資料庫負載 - 所有熱門查詢」圖表。資料庫查詢負載是衡量所選資料庫中執行的查詢作業,在一段時間內完成的工作量 (以 CPU 使用秒數為單位)。每個執行中的查詢都會使用或等待 CPU 資源、IO 資源或鎖定資源。資料庫查詢負載是指特定時間範圍內完成的所有查詢耗用的時間與實際時間的比率。
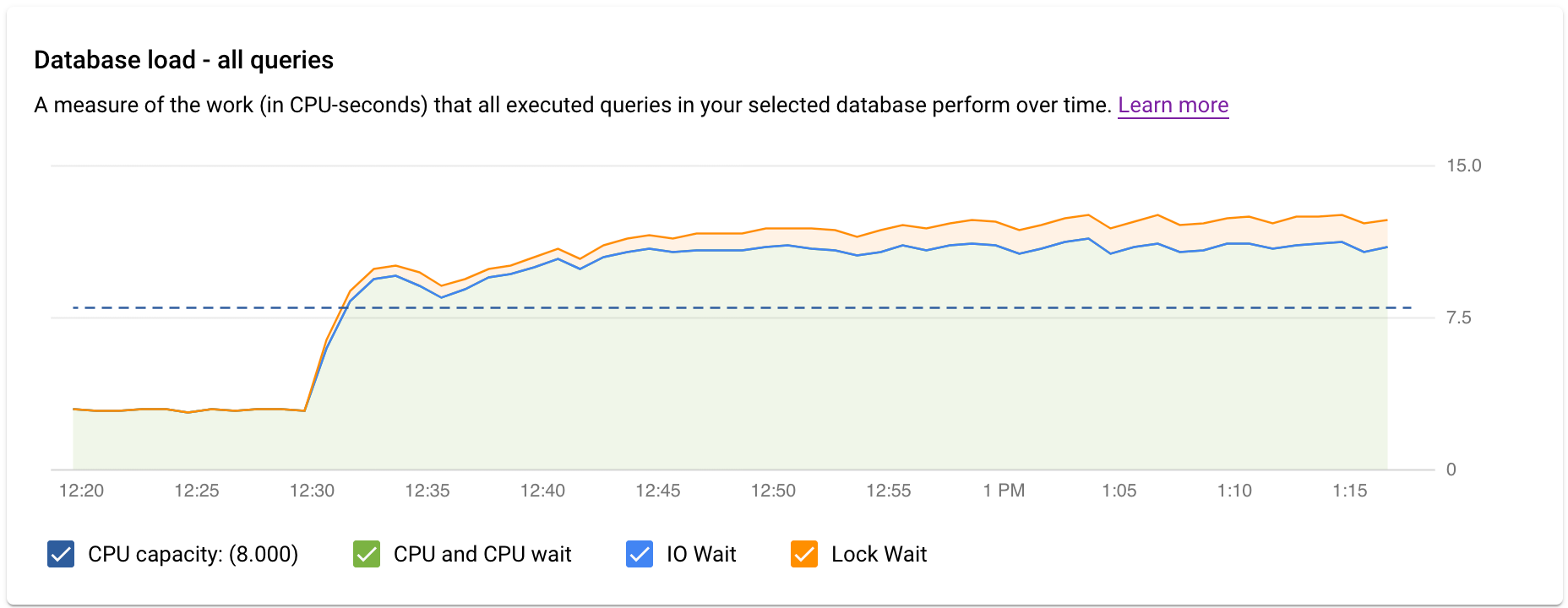
圖表中的彩色線條會顯示查詢負載,並分成四個類別:
- CPU 容量:執行個體可用的 CPU 數量。
CPU 和 CPU 等待:處於有效狀態的查詢耗用的時間與實際時間的比率。IO 和鎖定等待時間不會封鎖處於有效狀態的查詢。這項指標可能表示查詢正在使用 CPU,或是等待 Linux 排程器排定執行查詢的伺服器程序,而其他程序正在使用 CPU。
注意:CPU 負載會同時考量執行階段和等待 Linux 排程器排定執行伺服器程序的時間。因此,CPU 負載可能會超過核心上限。
IO 等待:等待 IO 的查詢耗用的時間與實際時間的比率。IO 等待包含讀取 IO 等待和寫入 IO 等待。請參閱 PostgreSQL 事件資料表。如要查看 I/O 等待的資訊明細,請前往 Cloud Monitoring。詳情請參閱「指標圖表」。
鎖定等待:等待鎖定的查詢耗用的時間與實際時間的比率,當中包含鎖定等待、LwLock 等待與 BufferPin 鎖定等待。如要查看鎖定等待的資訊明細,請前往 Cloud Monitoring。詳情請參閱「指標圖表」。
接著,請查看圖表並使用篩選選項回答下列問題:
- 查詢負載是否偏高?圖表是否會隨著時間而出現尖峰或升高?如果沒有看到高負荷,表示問題不在於查詢。
- 負荷過高多久了?現在是否只有高?還是長時間處於高溫狀態?使用範圍選取功能選取不同時間範圍,瞭解問題發生時間長度。或者,您也可以放大檢視查詢負載尖峰時段的時間範圍。你可以縮小時間軸,查看最多一週的資料。
- 是什麼原因導致負載過高?您可以選取選項,查看 CPU 容量、CPU 和 CPU 等待時間、鎖定等待時間或 IO 等待時間。每個選項的圖表都會以不同顏色顯示,方便您查看哪個選項的負載最高。圖表中的深藍線代表系統的 CPU 最大容量。您可以比較查詢負載與 CPU 系統容量上限。這項比較有助於瞭解執行個體是否即將耗盡 CPU 資源。
- 哪個資料庫的負載過高?從「資料庫」下拉式選單選取不同資料庫,找出負載最高的資料庫。
- 特定使用者或 IP 位址是否導致負載增加?從下拉式選單中選取不同使用者和地址,比較哪些項目導致負載較高。
篩選資料庫負載
在「查詢和標記」部分,您可以篩選或排序所選查詢或 SQL 查詢標記的查詢負載。
依查詢篩選
「QUERIES」(查詢) 表格會概略顯示造成最多查詢負載的查詢。表格會顯示所選時間範圍內,查詢洞察資訊主頁上所有經過正規化的查詢。
根據預設,資料表會依據所選時間範圍內的總執行時間排序查詢。
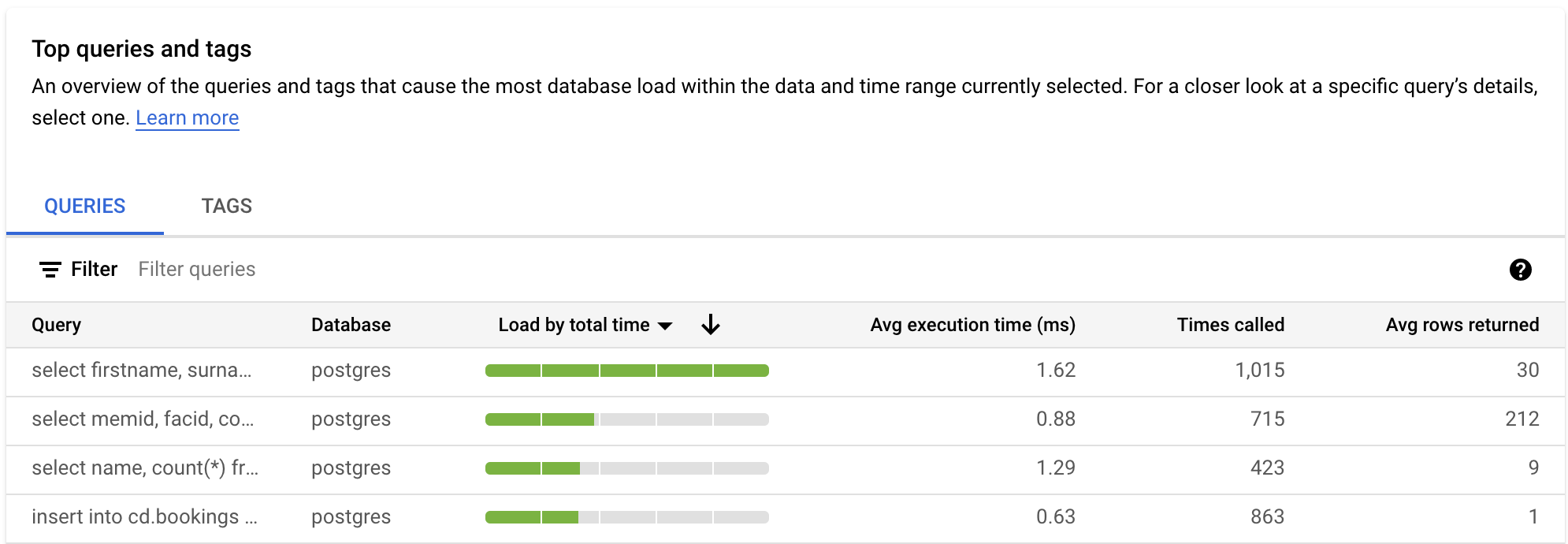
如要篩選表格,請從「篩選查詢」選取屬性。如要排序表格,請選取欄標題。表格會顯示下列屬性:
查詢字串。經過正規化的查詢字串。根據預設,查詢洞察資料只會顯示查詢字串中的 1024 個字元。
標示為
UTILITY COMMAND的查詢通常包含BEGIN、COMMIT和EXPLAIN指令或包裝函式指令。資料庫。查詢執行的資料庫。
負載 (根據總時間)/負載 (根據 CPU 時間)/負載 (根據 IO 等待時間)/負載 (根據鎖定等待時間)。您可以透過這些選項篩選特定查詢,找出每個選項的最大負載。
平均執行時間 (毫秒)。所有平行工作站完成查詢的所有子工作所花費的總時間。詳情請參閱「平均執行時間和持續時間」。
呼叫次數。應用程式呼叫查詢的次數。
平均擷取資料列數。查詢擷取的平均資料列數。
查詢洞察會顯示正規化查詢,也就是以 $1、$2 等取代常值。例如:
UPDATE
"demo_customer"
SET
"customer_id" = $1::uuid,
"name" = $2,
"address" = $3,
"rating" = $4,
"balance" = $5,
"current_city" = $6,
"current_location" = $7
WHERE
"demo_customer"."id" = $8
系統會忽略常數的值,以便查詢洞察資料匯總類似查詢,並移除常數可能顯示的任何 PII 資訊。
依查詢標記篩選
如要排解應用程式問題,請先在 SQL 查詢中新增標記。
查詢洞察功能提供以應用程式為中心的監控工具,可診斷使用 ORM 建構的應用程式效能問題。
如果您負責整個應用程式堆疊,查詢洞察功能會從應用程式檢視畫面提供查詢監控功能。查詢標記可協助您找出較高層級建構中的問題,例如使用商業邏輯、微服務或其他建構。您可以依據業務邏輯標記查詢,例如使用付款、商品目錄、業務分析或運送標記。然後找出各種商業邏輯建立的查詢負載。舉例來說,您可能會發現非預期的事件,例如商家 Analytics 標記在下午 1 點出現尖峰。或者,您可能會發現某項付款服務的趨勢與前一週相比出現非預期的成長。
查詢負載標記會提供所選標記在一段時間內的查詢負載明細。
如要計算「代碼的資料庫負載」,查詢洞察會使用每個查詢所花費的時間量,這些查詢會使用您選取的代碼。查詢洞察會使用實際時間,以分鐘為界計算完成時間。
在查詢洞察資訊主頁上選取「標記」,即可查看標記表格。「標記」表格會依總時間的總負載量排序標記。

如要排序表格,請從「篩選查詢」選取屬性,或按一下欄標題。表格會顯示下列屬性:
- 動作、控制器、架構、路徑、應用程式、資料庫驅動程式。您新增至查詢的每個屬性都會顯示為一欄。如要依標記篩選,至少須新增其中一個屬性。
- 負載 (根據總時間)/負載 (根據 CPU 時間)/負載 (根據 IO 等待時間)/負載 (根據鎖定等待時間)。您可以透過這些選項篩選特定查詢,找出每個選項的最大負載。
- 平均執行時間 (毫秒)。所有平行工作站完成查詢的所有子工作所花費的總時間。詳情請參閱「平均執行時間和持續時間」。
- 呼叫次數。應用程式呼叫查詢的次數。
- 平均擷取資料列數。查詢擷取的平均資料列數。
- 資料庫。查詢執行的資料庫。
檢查特定查詢或標記
如要判斷查詢或代碼是否為問題的根本原因,請分別在「查詢」分頁或「代碼」分頁中執行下列操作:
- 點選「負載 (根據總時間)」標題,即可依遞減順序排序清單。
- 點選看起來負載最高,且處理時間比其他查詢或代碼長的項目。
系統會開啟資訊主頁,顯示所選查詢或代碼的詳細資料。
如果您選取查詢,系統會顯示所選查詢的總覽:

如果選取代碼,系統會顯示所選代碼的總覽。
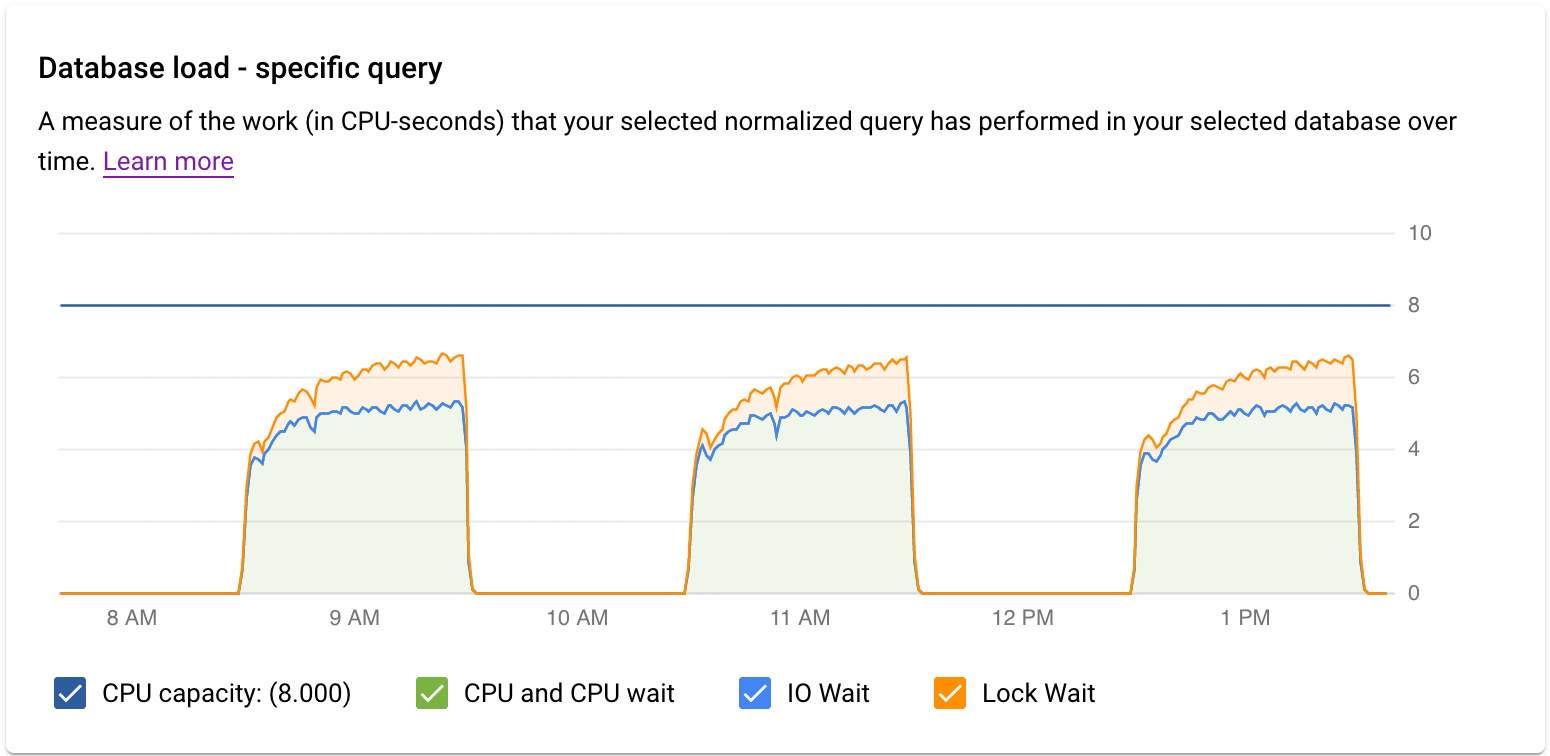
檢查特定查詢或標記的負載
「資料庫負載 - 特定查詢」圖表會顯示所選正規化查詢在所選查詢中執行的工作量 (以 CPU 使用秒數為單位)。如要計算負載,系統會使用在分鐘界線完成的正規化查詢所耗用的時間,除以實際時間。表格頂端會顯示正規化查詢的前 1024 個字元 (為進行匯總和保護 PII,系統會移除常值)。與查詢總數圖表一樣,您可以依據「資料庫」、「使用者」和「用戶端位址」篩選特定查詢的負載。查詢負載會分為 CPU 容量、CPU 和 CPU 等待、IO 等待和鎖定等待。
「資料庫負載 - 特定標記」圖表會顯示符合所選標記的查詢,過去在所選資料庫中執行的工作量 (以 CPU 使用秒數為單位)。與查詢總數圖表一樣,您可以依「資料庫」、「使用者」和「用戶端地址」篩選特定標記的負載。
檢查延遲時間
您可以使用「延遲」圖表檢查查詢或標記的延遲時間。 延遲時間是指完成正規化查詢所需的實際時間。延遲時間資訊主頁會顯示第 50、第 95 和第 99 個百分位數的延遲時間,以找出離群值行為。
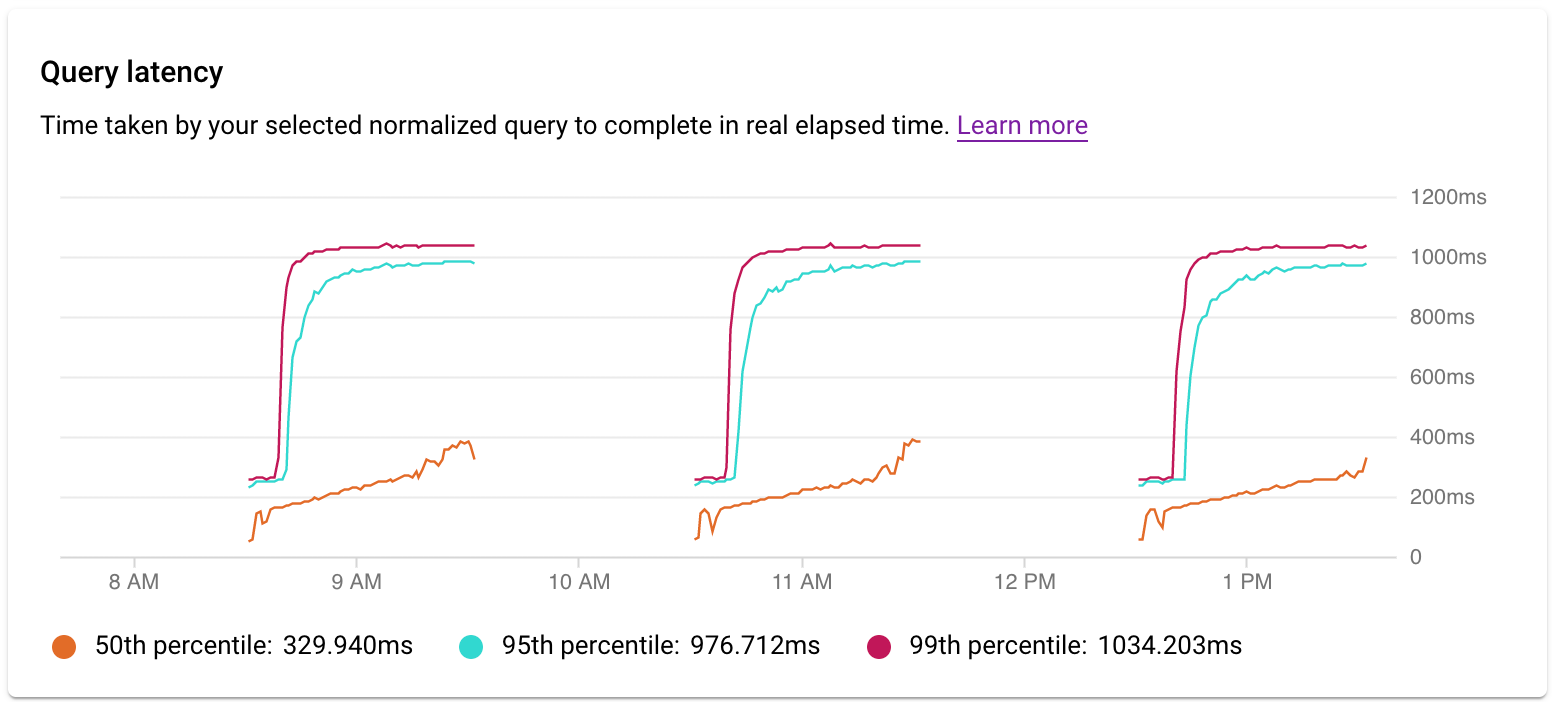
並行查詢的延遲時間以實際時間為計算單位,即便您為了執行部分查詢而使用多個核心,導致查詢負載超過查詢所需的量也一樣。
請查看下列項目,嘗試縮小問題範圍:
- 是什麼原因導致負載過高?選取選項,查看 CPU 容量、CPU 和 CPU 等待時間、鎖定等待時間或 IO 等待時間。
- 高負荷狀態持續多久了?現在是否只有高?還是長期偏高?�變更時間範圍,找出負載開始效能不佳的日期和時間。
- 延遲時間是否突然變長?您可以變更時間範圍,研究標準化查詢的延遲記錄。
找出負載量最高的區域和時間後,即可進一步深入瞭解。
檢查叢集的延遲情形
您可以使用「叢集內相同查詢第 99 個百分位數的延遲時間」圖表,檢查叢集內各個執行個體中查詢或標記的第 99 個百分位數延遲時間。

檢查取樣查詢計畫中的作業
查詢計畫會擷取查詢樣本,並細分成個別作業。並說明及分析查詢中的每項作業。「查詢計畫範例」圖表會顯示特定時間執行的所有查詢計畫,以及每個計畫的執行時間。
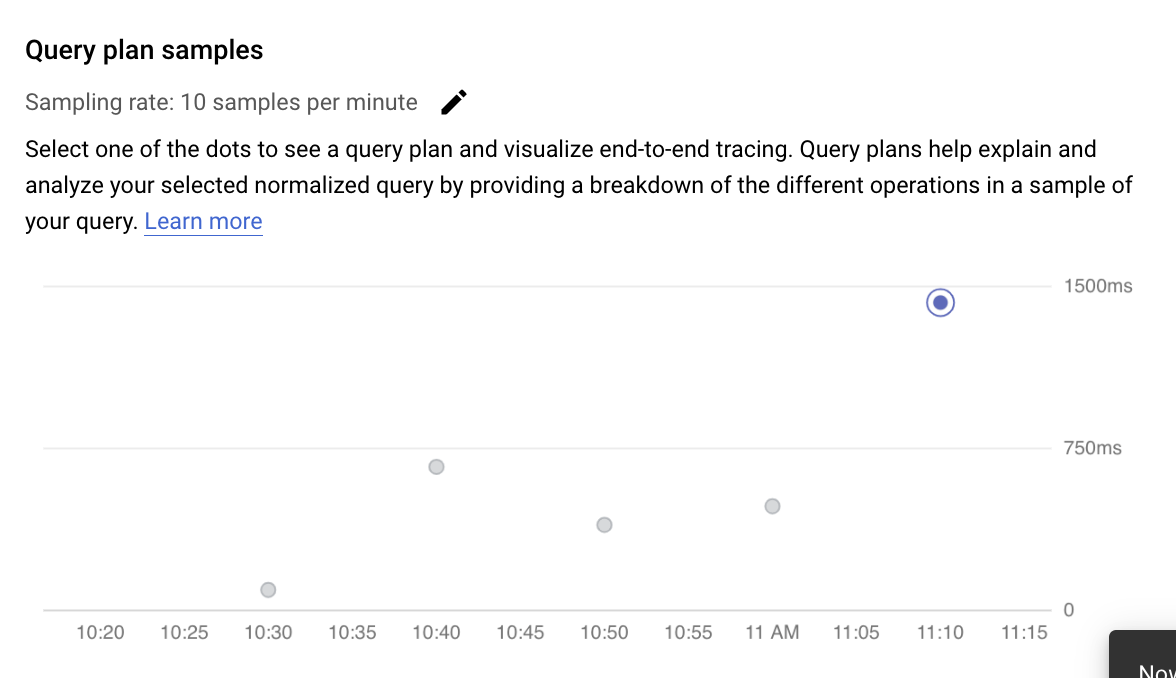
如要查看範例查詢計畫的詳細資料,請按一下「範例查詢計畫」圖表上的點。對於大多數 (但並非所有) 查詢,您都可以查看已執行的樣本查詢計畫。請注意,PostgreSQL 適用的 AlloyDB 會自動對查詢進行取樣。查詢執行次數越多,越有可能遭到取樣。如要查看更多查詢計畫範例,請按照編輯查詢洞察設定的說明,提高「最高取樣率」。
查看查詢計畫的展開詳細資料時,您會看到該計畫中所有作業的模型。每項作業都會顯示延遲時間、傳回的資料列數和作業費用。選取作業後,即可查看更多詳細資料,例如共用的命中區塊、結構定義類型、實際迴圈、計畫列等。
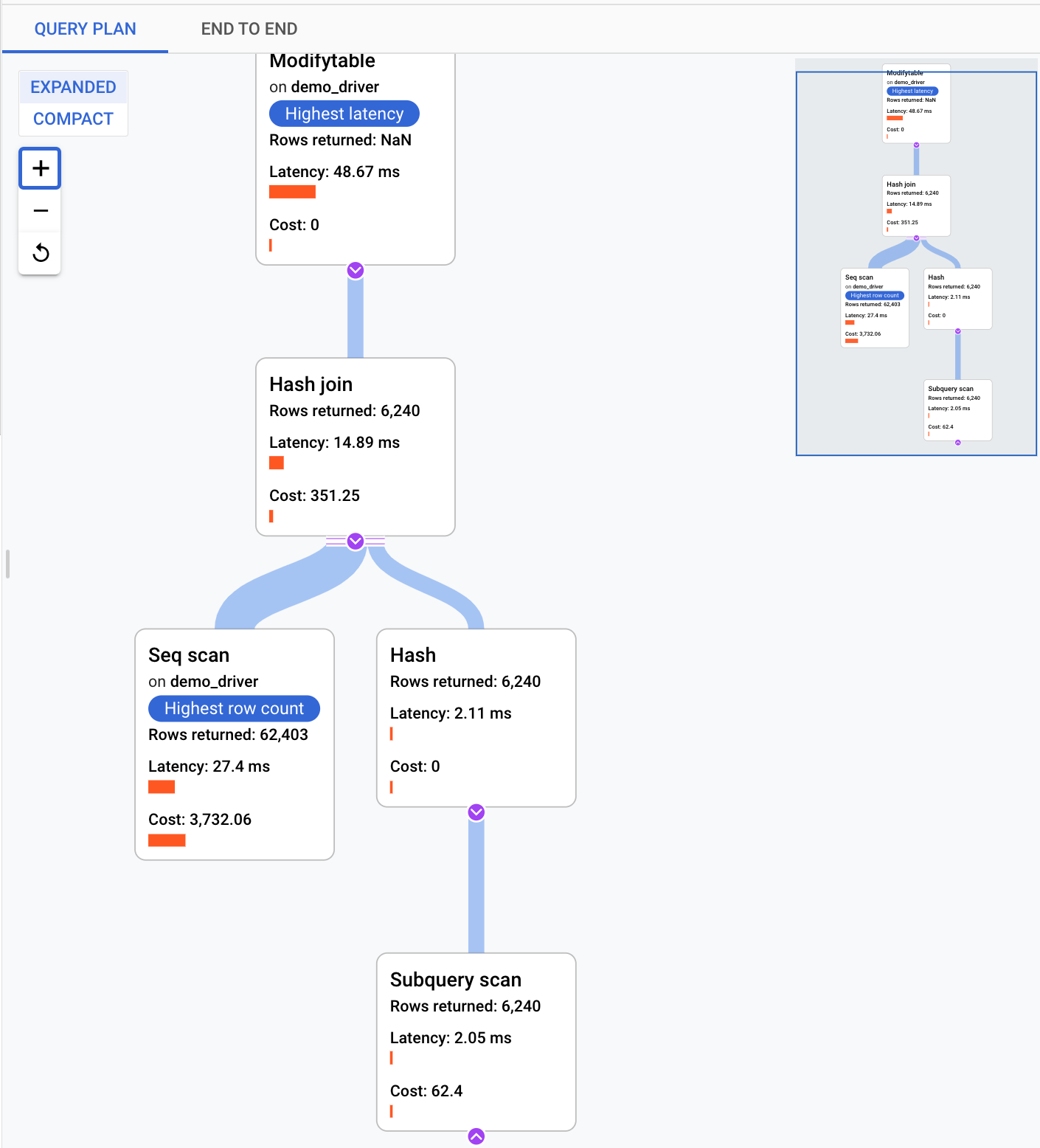
請參考下列問題,盡量縮小問題範圍:
- 資源用量是多少?
- 這項查詢與其他查詢有何關聯?
- 消費量是否會隨時間變化?
檢查範例查詢產生的追蹤記錄
除了查看查詢計畫範例,您也可以使用查詢洞察資料,查看查詢範例的應用程式端對端追蹤記錄。這項追蹤記錄會顯示特定要求的資料庫活動,有助於找出問題查詢的來源。此外,應用程式在要求期間傳送至 Cloud Logging 的記錄項目會連結至追蹤記錄,有助於您進行調查。
如要查看脈絡內追蹤記錄,請按照下列步驟操作:
在「Sample Query」(查詢範例) 窗格中,按一下「End-to-end Trace」(端對端追蹤記錄) 分頁標籤。這個分頁會顯示甘特圖,詳細列出查詢產生的追蹤記錄時距,也就是個別作業的記錄。
如要查看每個時距的詳細資料 (例如屬性和中繼資料),請按一下該時距。
您也可以在「Trace Explorer」頁面中查看追蹤記錄。如要查看,請按一下「在 Cloud Trace 查看」。如要瞭解如何使用「Trace 探索工具」頁面探索追蹤記錄資料,請參閱「尋找及探索追蹤記錄」。
為 SQL 查詢新增標記
標記 SQL 查詢可簡化應用程式疑難排解程序。您可以使用 sqlcommenter,透過物件關聯對應 (ORM) 自動或手動將標記新增至 SQL 查詢。
搭配 ORM 使用 sqlcommenter
如果使用 ORM 而非直接編寫 SQL 查詢,您可能找不到導致效能問題的應用程式程式碼。您可能也難以分析應用程式程式碼對查詢效能的影響。為解決這個痛點,查詢洞察提供名為 sqlcommenter 的開放原始碼程式庫,也就是 ORM 檢測程式庫。對於使用 ORM 的開發人員和管理員來說,這個程式庫有助於偵測造成效能問題的應用程式程式碼。
如果您同時使用 ORM 和 sqlcommenter,系統會自動建立標記,您不必變更或新增自訂程式碼至應用程式。
您可以在應用程式伺服器上安裝 sqlcommenter。使用檢測程式庫,即可將與 MVC 架構相關的應用程式資訊,連同查詢以 SQL 註解的形式傳播至資料庫。資料庫會擷取這些標記,並開始記錄及匯總標記的統計資料,這些資料與正規化查詢匯總的統計資料正交。查詢洞察會顯示標記,方便您瞭解是哪個應用程式造成查詢負載。這項資訊有助於找出造成效能問題的應用程式程式碼。
在 SQL 資料庫記錄中檢查結果時,會看到以下內容:
SELECT * from USERS /*action='run+this',
controller='foo%3',
traceparent='00-01',
tracestate='rojo%2'*/
支援的標記包括控制器名稱、路徑、架構和動作。
sqlcommenter 支援多種程式設計語言的 ORM:
| Python |
|
| Java |
|
| Ruby |
|
| Node.js |
|
如要進一步瞭解 sqlcommenter,以及如何在 ORM 架構中使用 sqlcommenter,請參閱 GitHub 中的 sqlcommenter 說明文件。
使用 sqlcommenter 手動新增標記
如果未使用 ORM,則必須手動將 sqlcommenter 代碼加入 SQL 查詢。在查詢中,您必須使用含有序列化鍵/值組合的註解,擴增每個 SQL 陳述式。請使用下列至少一個鍵:
action=''controller=''framework=''route=''application=''db driver=''
查詢洞察會捨棄所有其他鍵。如要瞭解正確的 SQL 註解格式,請參閱 sqlcommenter 說明文件。
執行時間和時長
查詢洞察提供「平均執行時間 (毫秒)」指標,可回報所有平行工作站完成查詢的所有子工作所花費的總時間。這項指標可協助您找出並最佳化 CPU 負荷最高的查詢,進而提升資料庫的整體資源使用率。
如要查看經過的時間,您可以在 psql 用戶端上執行 \timing 指令,測量查詢的持續時間。這項指標會測量從收到查詢到 PostgreSQL 伺服器傳送回應之間經過的時間。這項指標可協助您分析特定查詢耗時過長的原因,並決定是否要進行最佳化,以加快查詢速度。
如果查詢是由單一工作以單一執行緒完成,則持續時間和平均執行時間會維持不變。
啟用 AlloyDB 適用的進階查詢洞察功能
AlloyDB 的進階查詢洞察功能資訊主頁已整合至標準查詢洞察資訊主頁。 如要進一步瞭解如何啟用進階查詢洞察功能,請參閱「使用進階查詢洞察功能提高查詢成效」。
後續步驟
- 查詢深入分析總覽
- 使用 AlloyDB 的進階查詢洞察功能提升查詢效能
- AlloyDB 指標
- SQL Commenter 網誌:介紹 Sqlcommenter:開放原始碼 ORM 自動檢測程式庫
- 操作說明網誌:使用 Sqlcommenter 啟用查詢標記