
Pathways è un sistema progettato per consentire la creazione di sistemi di machine learning su larga scala, multi-task e attivati in modo sparso. Consente l'utilizzo di migliaia o decine di migliaia di acceleratori, con la possibilità di allocare dinamicamente quantità variabili di risorse di calcolo per attività diverse in base ai relativi requisiti di elaborazione.
Pathways semplifica i calcoli di machine learning su larga scala consentendo a un singolo client JAX di orchestrare i carichi di lavoro su più slice TPU di grandi dimensioni, potenzialmente su migliaia di chip TPU.
Pathways viene utilizzato internamente in Google per addestrare modelli di grandi dimensioni come Gemini. Pathways su Cloud offre gli stessi vantaggi ai Google Cloud clienti.
Prima di iniziare
Assicurati di avere:
Questo documento fornisce una panoramica su come utilizzare le TPU gestite da Pathways su Google Kubernetes Engine (GKE) per carichi di lavoro batch, in tempo reale e interattivi. Si presuppone che tu abbia già familiarità con l'utilizzo delle TPU con GKE incluse le TPU a slice singola e multipla su Google Kubernetes Engine, nonché un'esperienza generale con le TPU a slice multipla
Controller singolo e multi-controller
Esistono principalmente due modi diversi per gestire e orchestrare i calcoli su più dispositivi:
Funzionalità |
Controller singolo (Pathways) |
Multi-controller (JAX predefinito) |
Controllo |
Punto di controllo singolo: un singolo programma client funge da controller centrale. |
Controllo distribuito: partecipano più processi, ognuno con la propria istanza dell'interprete Python. |
Visualizza |
Visualizzazione unificata: il client vede tutti i dispositivi come un unico sistema unificato. |
Visualizzazione localizzata: ogni processo Python vede solo i dispositivi a cui è connesso. |
Programmazione |
Programmazione semplificata: gli utenti interagiscono con un singolo client, facendo apparire il sistema come una singola macchina di grandi dimensioni con molti acceleratori locali. |
SPMD: utilizza principalmente il paradigma SPMD, che richiede che tutti i dispositivi eseguano lo stesso programma. |
Flessibilità |
Supporta pattern di calcolo più complessi oltre a SPMD, tra cui il parallelismo della pipeline asimmetrica e la sparsità computazionale. |
Può essere meno flessibile nella gestione delle risorse, soprattutto tra diverse slice TPU. |
Componenti di Pathways
La sezione seguente descrive i componenti principali dell'architettura di Pathways.
Gestore risorse di Pathways
Questo è il control plane centrale del sistema Pathways. Gestisce tutte le risorse dell'acceleratore ed è responsabile del coordinamento dell'allocazione degli acceleratori per i job utente. Monitora l'integrità dei worker e gestisce la pianificazione, la sospensione e la ripresa dei job. Funge da punto di contatto unico per gli errori e lo stato del sistema. Questo componente richiede solo risorse CPU.
Client Pathways
Si tratta di un'implementazione di Interim Framework Runtime (IFRT) che funge da punto di accesso al sistema Pathways. Riceve operazioni di alto livello (HLO) dal tuo programma. Il client Pathways è responsabile del coordinamento con il gestore risorse Pathways per determinare dove inserire i programmi compilati per l'esecuzione in base al codice utente. Presenta una visualizzazione unificata del sistema a un determinato client JAX. Questo componente richiede solo risorse CPU.
Worker Pathways
Questi sono i processi eseguiti sulle macchine dell'acceleratore (VM TPU). Ricevono gli eseguibili compilati del tuo programma dal server proxy IFRT ed eseguono i calcoli sulle TPU. I worker Pathways inviano i dati al tuo programma tramite il server proxy IFRT. Questo componente richiede risorse dell'acceleratore.
Client proxy IFRT
Si tratta di un'implementazione open source dell'API Interim Framework Runtime (IFRT) che disaccoppia il codice utente dal runtime sottostante e migliora la portabilità e la trasparenza del codice. JAX utilizza questa implementazione come alternativa al runtime multi-controller predefinito. Il client proxy IFRT funge da ponte di comunicazione tra il tuo programma e i componenti Pathways. Invia richieste al server proxy IFRT e riceve i risultati. Si tratta di un'implementazione open source dell'API IFRT. Questo componente richiede solo risorse CPU.
Server proxy IFRT
Questo server gRPC riceve le richieste dal client proxy IFRT e le inoltra al client Pathways, che gestisce la distribuzione effettiva del lavoro. Questo componente richiede solo risorse CPU.
Server sidecar
Questo server gRPC si trova nella stessa posizione del worker Pathways sulla VM dell'acceleratore per eseguire direttamente il codice Python specificato dall'utente sulla VM dell'acceleratore al fine di ridurre la latenza di trasferimento dei dati dal controller agli acceleratori. Il server sidecar interagisce con il worker Pathways tramite un protocollo con versione personalizzata sul trasporto gRPC.
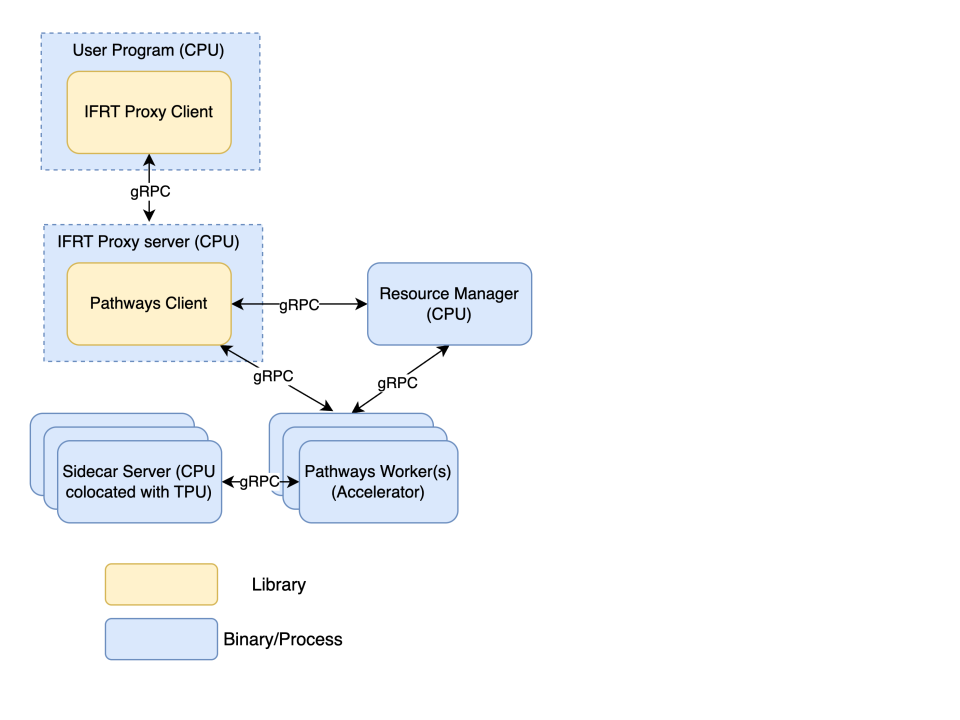
Componenti di Pathways su GKE
Questa sezione mappa i componenti di Pathways ai componenti di Google Kubernetes Engine, come container e pod.
Puoi trovare le immagini container di Pathways nelle seguenti posizioni.
Tipo di container |
Località |
Server proxy IFRT |
|
Gestore risorse/worker Pathways |
|
Gestore risorse di Pathways
Dopo aver creato un cluster GKE, puoi utilizzare il seguente containerSpec per eseguire il deployment del gestore risorse Pathways:
- name: pathways-rm image: us-docker.pkg.dev/cloud-tpu-v2-images/pathways/server:latest imagePullPolicy: Always env: - name: HOST_ADDRESS valueFrom: fieldRef: fieldPath: "metadata.labels['jobset.sigs.k8s.io/coordinator']" - name: TPU_SKIP_MDS_QUERY value: "true" args: - --server_port=29001 - --node_type=resource_manager - --instance_count=WORKLOAD_NODEPOOL_COUNT - --instance_type=SLICE_TOPOLOGY - --gcs_scratch_location=gs://BUCKET_NAME
Descrizioni degli argomenti:
--server_port: il gestore risorse Pathways utilizza questa porta per comunicare con altri componenti Pathways.--node_type: il tipo di nodo. Per il gestore risorse Pathways, questo valore deve essere impostato su "resource_manager" e non è necessario per gli altri container.--instance_count: il numero di slice TPU.--instance_type: il tipo di TPU e la topologia della slice. Nel formatotpu{TPU type}:{TPU topology}, ad esempiotpuv5e:4x4.--gcs_scratch_location: un bucket Cloud Storage utilizzato per i file temporanei.
Server proxy IFRT
Puoi utilizzare il seguente containerSpec per eseguire il deployment di un server proxy IFRT:
- name: pathways-proxy image: us-docker.pkg.dev/cloud-tpu-v2-images/pathways/proxy_server:latest imagePullPolicy: Always env: - name: PATHWAYS_HEAD valueFrom: fieldRef: fieldPath: "metadata.labels['jobset.sigs.k8s.io/coordinator']" args: - --resource_manager_address=$(PATHWAYS_HEAD):29001 - --server_port=29000 - --gcs_scratch_location=gs://BUCKET_NAME ports: - containerPort: 29000
Descrizioni degli argomenti:
--resource_manager_address: il nome host e la porta utilizzati dal server proxy per comunicare con il gestore risorse Pathways. La porta deve essere uguale al valore--server_portutilizzato per il container del gestore risorse Pathways.--server_port: il server proxy IFRT utilizza questa porta per comunicare con il client proxy IFRT.--gcs_scratch_location: un bucket Cloud Storage utilizzato per i file temporanei.
Worker Pathways
Puoi utilizzare il seguente containerSpec per eseguire il deployment dei worker Pathways:
- name: worker image: us-docker.pkg.dev/cloud-tpu-v2-images/pathways/server:latest imagePullPolicy: Always env: - name: PATHWAYS_HEAD valueFrom: fieldRef: fieldPath: "metadata.labels['jobset.sigs.k8s.io/coordinator']" - name: MEGASCALE_NUM_SLICES valueFrom: fieldRef: fieldPath: "metadata.labels['jobset.sigs.k8s.io/replicatedjob-replicas']" - name: MEGASCALE_SLICE_ID valueFrom: fieldRef: fieldPath: "metadata.labels['jobset.sigs.k8s.io/job-index']" - name: MEGASCALE_COORDINATOR_ADDRESS value: "$(PATHWAYS_HEAD)" args: - --server_port=29001 - --resource_manager_address=$(PATHWAYS_HEAD):29001 - --gcs_scratch_location=gs://BUCKET_NAME ports: - containerPort: 29001 resources: limits: google.com/tpu: "4"
Descrizioni degli argomenti:
--resource_manager_address: il nome host e la porta utilizzati dai worker TPU per comunicare con il gestore risorse Pathways. La porta deve essere uguale al valore--server_portutilizzato per il container del gestore risorse Pathways.--server_port: i worker utilizzano questa porta per comunicare con il server proxy e il gestore risorse Pathways.--gcs_scratch_location: un bucket Cloud Storage utilizzato per i file temporanei.
Il gestore risorse Pathways, il server proxy IFRT e i worker Pathways possono avere porte diverse, ma in questo esempio il gestore risorse Pathways e il worker Pathways condividono la stessa porta.
Passaggi successivi
- Crea un cluster GKE con Pathways
- Esegui un carico di lavoro batch con Pathways
- Esegui l'inferenza multihost utilizzando Pathways
- Esegui un carico di lavoro interattivo con Pathways
- Addestramento resiliente con Pathways
- Porta i carichi di lavoro JAX su Pathways
- Risolvi i problemi di Pathways su Cloud