
Pathways ist ein System, mit dem sich umfangreiche, auf mehrere Aufgaben ausgerichtete und spärlich aktivierte Machine-Learning-Systeme erstellen lassen. Es ermöglicht die Verwendung von Tausenden oder Zehntausenden von Beschleunigern und die dynamische Zuweisung unterschiedlicher Mengen an Rechenleistung für verschiedene Aufgaben basierend auf ihren Verarbeitungsanforderungen.
Pathways vereinfacht umfangreiche ML-Berechnungen, da ein einzelner JAX-Client Arbeitslasten über mehrere große TPU-Slices hinweg orchestrieren kann, die möglicherweise Tausende von TPU-Chips umfassen.
Pathways wird intern bei Google verwendet, um große Modelle wie Gemini zu trainieren. Pathways on Cloud bietet Google Cloud Kunden dieselben Vorteile.
Hinweis
Sie benötigen Folgendes:
In diesem Dokument wird beschrieben, wie Sie verwaltete TPUs von Pathways in Google Kubernetes Engine (GKE) für Batch-, Echtzeit- und interaktive Arbeitslasten verwenden. Es wird davon ausgegangen, dass Sie bereits mit der Verwendung von TPUs mit GKE vertraut sind, einschließlich Einzel- und Multislice-TPUs in Google Kubernetes Engine, sowie allgemeine Erfahrung mit Multislice-TPUs haben.
Einzelner Controller und mehrere Controller
Es gibt hauptsächlich zwei verschiedene Möglichkeiten, Berechnungen auf mehreren Geräten zu verwalten und zu orchestrieren:
Feature |
Einzelner Controller (Pathways) |
Mehrere Controller (JAX-Standard) |
Kontrolle |
Zentraler Kontrollpunkt: Ein einzelnes Clientprogramm fungiert als zentraler Controller. |
Verteilte Steuerung: Mehrere Prozesse sind beteiligt, jeder mit einer eigenen Python-Interpreterinstanz. |
Ansicht |
Ganzheitliche Übersicht: Der Client sieht alle Geräte als ein einziges, einheitliches System. |
Lokalisierte Ansicht: Jeder Python-Prozess sieht nur die Geräte, die mit ihm verbunden sind. |
Programmierung |
Vereinfachte Programmierung: Nutzer interagieren mit einem einzelnen Client, sodass das System als eine große Maschine mit vielen lokalen Beschleunigern erscheint. |
SPMD: Hier wird hauptsächlich das SPMD-Paradigma verwendet, bei dem auf allen Geräten dasselbe Programm ausgeführt werden muss. |
Flexibilität |
Unterstützt komplexere Rechenmuster als SPMD, einschließlich asymmetrischer Pipeline-Parallelität und Rechensparsamkeit. |
Die Ressourcenverwaltung kann weniger flexibel sein, insbesondere bei verschiedenen TPU-Slices. |
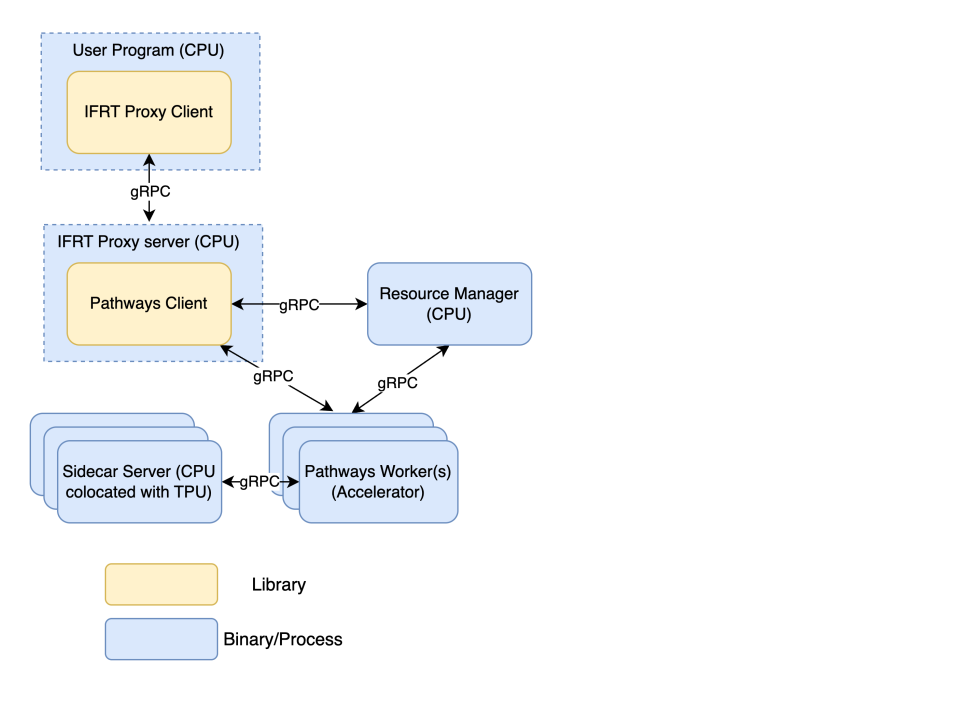
Pathways-Komponenten
Im folgenden Abschnitt werden die Hauptkomponenten der Pathways-Architektur beschrieben.
Pathways Resource Manager
Dies ist die zentrale Steuerungsebene des Pathways-Systems. Sie verwaltet alle Beschleunigerressourcen und ist für die Koordinierung der Zuweisung von Beschleunigern für Nutzerjobs verantwortlich. Sie überwacht den Zustand der Worker und kümmert sich um die Planung, das Pausieren und das Fortsetzen von Jobs. Es dient als zentrale Anlaufstelle für Fehler und Systemstatus. Für diese Komponente sind nur CPU-Ressourcen erforderlich.
Pathways-Client
Dies ist eine Implementierung der Interim Framework Runtime (IFRT), die als Einstiegspunkt in das Pathways-System dient. Sie empfängt High-Level Operations (HLOs) von Ihrem Programm. Der Pathways-Client ist dafür verantwortlich, mit dem Pathways-Ressourcenmanager abzustimmen, wo kompilierte Programme basierend auf dem Nutzercode zur Ausführung platziert werden sollen. Es bietet einem bestimmten JAX-Client eine einheitliche Ansicht des Systems. Für diese Komponente sind nur CPU-Ressourcen erforderlich.
Pathways-Mitarbeiter
Dies sind die Prozesse, die auf den Beschleuniger-Maschinen (TPU-VMs) ausgeführt werden. Sie empfangen kompilierte ausführbare Dateien Ihres Programms vom IFRT-Proxyserver und führen die Berechnungen auf den TPUs aus. Pathways-Worker senden Daten über den IFRT-Proxyserver zurück an Ihr Programm. Für diese Komponente sind Accelerator-Ressourcen erforderlich.
IFRT-Proxyclient
Dies ist eine OSS-Implementierung der Interim Framework Runtime (IFRT)-API, die den Nutzercode von der zugrunde liegenden Laufzeit entkoppelt und die Portabilität und Transparenz des Codes verbessert. JAX verwendet diese Implementierung als Alternative zur standardmäßigen Laufzeit mit mehreren Controllern. Der IFRT-Proxy-Client fungiert als Kommunikationsbrücke zwischen Ihrem Programm und den Pathways-Komponenten. Er sendet Anfragen an den IFRT-Proxy-Server und empfängt Ergebnisse von ihm. Es handelt sich um eine OSS-Implementierung der IFRT-API. Für diese Komponente sind nur CPU-Ressourcen erforderlich.
IFRT-Proxyserver
Dieser gRPC-Server empfängt Anfragen vom IFRT-Proxy-Client und leitet sie an den Pathways-Client weiter, der die eigentliche Verteilung der Arbeit übernimmt. Für diese Komponente sind nur CPU-Ressourcen erforderlich.
Sidecar-Server
Dieser gRPC-Server befindet sich zusammen mit dem Pathways-Worker auf der Accelerator-VM, um nutzerspezifischen Python-Code direkt auf der Accelerator-VM auszuführen. So wird die Latenz für die Datenübertragung vom Controller zu den Accelerators reduziert. Der Sidecar-Server interagiert mit dem Pathways-Worker über ein benutzerdefiniertes versioniertes Protokoll auf dem gRPC-Transport.
PathwaysJob API
Die PathwaysJob API ist eine Kubernetes-native OSS-API, mit der Sie ML-Trainings- und Batchinferenz-Arbeitslasten bereitstellen. Der Controller für PathwaysJob nutzt die JobSet API, um den Lebenszyklus und die Koordination aller Pathways-Komponenten zu verwalten. Diese benutzerdefinierte Ressourcendefinition (Custom Resource Definition, CRD) bietet Ihnen eine allgemeine Schnittstelle zum Definieren Ihrer Pathways-Arbeitslasten. So müssen Sie in gängigen Szenarien nicht direkt einzelne Pod-Spezifikationen verwalten. Eine umfassende Liste aller Parameter und ihrer spezifischen Bedeutungen finden Sie in der PathwaysJob API-Dokumentation auf GitHub.
apiVersion: pathways-job.pathways.domain/v1 kind: PathwaysJob metadata: name: pathways-USER spec: maxRestarts: MAX_RESTARTS pathwaysVersion: jax-JAX_VERSION workers: - type: $(TPU_MACHINE_TYPE) topology: $(TOPOLOGY) numSlices: $(WORKLOAD_NODEPOOL_COUNT) maxSliceRestarts: # Optional customComponents: # This section is completely optional - componentType: proxy_server image: CUSTOM_PROXY_SERVER customFlags: - --flag_name_1=value_1 customEnv: - name: key_1 value: value_1 - componentType: pathways_server image: CUSTOM_PATHWAYS_SERVER customFlags: - --flag_name_1=value_1 customEnv: - name: key_1 value: value_1 - componentType: worker image: CUSTOM_WORKER customFlags: - --flag_name_1=value_1 customEnv: - name: key_1 value: value_1 - componentType: colocated_python_sidecar image: CUSTOM_SIDECAR_IMAGE customFlags: - --flag_name_1=value_1 customEnv: - name: key_1 value: value_1 pathwaysDir: "gs://BUCKET_NAME" # Pre-create this bucket. controller: deploymentMode: default # Default mode deploys pathways cpu resources (resource # manager and proxy server) on a dedicated CPU node, recommended for training elasticSlices: ELASTIC_SLICES template: spec: containers: - name: main image: python:3.11 command: - bash - -c - | pip install pathwaysutils python3 -c 'import pathwaysutils; import jax; pathwaysutils.initialize(); print(jax.devices())'
In der folgenden Tabelle werden die Einstellungen für die PathwaysJob API beschrieben:
| Attribut | Beschreibung |
|---|---|
apiVersion |
Gibt die API-Version für die benutzerdefinierte Ressourcendefinition (Custom Resource Definition, CRD) PathwaysJob an: pathways-job.pathways.domain/v1. |
kind |
Gibt an, dass das Kubernetes-Objekt ein PathwaysJob ist. |
metadata.name |
Der Name des PathwaysJob-Objekts in Kubernetes, das in der Regel dem Muster „pathways- |
spec |
Definiert den gewünschten Status und die Konfiguration für PathwaysJob. |
spec.maxRestarts |
Die maximale Anzahl an automatischen Neustarts des PathwaysJob durch das System bei Fehlern. |
spec.pathwaysVersion |
(Optional) Gibt die gewünschte Version des JAX-Frameworks an, die in der Pathways-Umgebung für diesen Job verwendet werden soll (z. B. jax-0.5.3). |
spec.workers |
Ein Array, das die Konfiguration für den Worker-Pool von PathwaysJob definiert, in der Regel mit TPU-Ressourcen. |
spec.workers[].type |
Der Typ der TPU-Maschine, die für die Worker-Knoten verwendet werden soll (z. B. könnte $TPU_MACHINE_TYPE ct6e-standard-4t sein) |
spec.workers[].topology |
Die Topologie der den Workern zugewiesenen TPU-Slices (z. B. $TOPOLOGY = 2x2, 4x4, 2x2x2). |
spec.workers[].numSlices |
Die Anzahl der TPU-Slices, die für den Worker-Pool bereitgestellt werden sollen (z. B. könnte $WORKLOAD_NODEPOOL_COUNT gleich 2 sein). |
spec.workers[].maxSliceRestarts |
(Optional) Die maximale Anzahl an Neustarts für einen einzelnen Worker in einem Slice, wenn er fehlschlägt. |
spec.customComponents |
(Optional) Ein Array, mit dem Sie benutzerdefinierte Komponenten (z. B. Proxyserver, Pathways-Server oder zusätzliche Worker) zusammen mit dem Hauptjob definieren und bereitstellen können. |
spec.customComponents[].componentType |
Gibt den Typ der benutzerdefinierten Komponente an, die definiert wird (z. B. „proxy_server“, „pathways_server“, „worker“, „colocated_python_sidecar“). |
spec.customComponents[].image |
Das Docker-Image, das für den Container dieser benutzerdefinierten Komponente verwendet werden soll. |
spec.customComponents[].customFlags |
Ein Array mit benutzerdefinierten Befehlszeilen-Flags, die beim Start an den Container übergeben werden. |
spec.customComponents[].customEnv |
Ein Array mit benutzerdefinierten Umgebungsvariablen, die im Container festgelegt werden sollen. Jedes Element hat einen Namen und einen Wert. |
spec.pathwaysDir |
Der Cloud Storage-Bucket, der von PathwaysJob zum Speichern von Kompilierungsartefakten und anderen temporären Daten verwendet wird.
Dieser Bucket muss vor dem Ausführen Ihrer Arbeitslast erstellt werden. |
spec.controller |
Konfigurationseinstellungen für den Pathways-Controller, mit denen die gesamte Jobausführung verwaltet wird. |
spec.controller.deploymentMode |
Gibt an, wie die CPU-Ressourcen des Pathways-Controllers (Pathways-Ressourcenmanager und Proxyserver) bereitgestellt werden. Im Standardmodus werden sie auf einem dedizierten CPU-Knoten bereitgestellt, während sie mit colocate_head_with_workers zusammen mit einem TPU-Worker bereitgestellt werden. |
spec.controller.elasticSlices |
(Optional) Die maximale Anzahl von TPU-Slices, die während der Ausführung des Jobs nicht verfügbar sein dürfen, bevor der Job als fehlerhaft eingestuft wird. |
spec.controller.template |
Optional: Definiert die Pod-Vorlage für den Nutzerjob. Dies ist für Batcharbeitslasten erforderlich, nicht aber für interaktive Arbeitslasten. |
spec.controller.template.spec |
Die Spezifikation des Pods für den Nutzerjob. |
spec.controller.template.spec.containers |
Ein Array, das die Container definiert, die im Nutzerjob ausgeführt werden |
spec.controller.template.spec.containers[].name |
Der Name des Containers im Nutzerjob (in diesem Beispiel „main“). |
spec.controller.template.spec.containers[].image |
Das Docker-Image, das für den Container im Hauptcontainer verwendet werden soll (in diesem Beispiel python:3.11). |
spec.controller.template.spec.containers[].command |
Der Befehl, der beim Start des Hauptcontainers ausgeführt werden soll. In diesem Beispiel wird `pathwaysutils` installiert, Pathways initialisiert und JAX-Geräte werden ausgegeben. |
Pathways-Komponenten in GKE
In diesem Abschnitt werden die Komponenten von Pathways den Komponenten von Google Kubernetes Engine wie Containern und Pods zugeordnet.
Sie finden die Container-Images für Pathways an den folgenden Speicherorten.
Containertyp |
Standort |
IFRT-Proxyserver |
|
Pathways-Ressourcenmanager/-Worker |
|
Pathways Resource Manager
Nachdem Sie einen GKE-Cluster erstellt haben, können Sie den Pathways Resource Manager mit dem folgenden containerSpec bereitstellen:
- name: pathways-rm image: us-docker.pkg.dev/cloud-tpu-v2-images/pathways/server:latest imagePullPolicy: Always env: - name: HOST_ADDRESS valueFrom: fieldRef: fieldPath: "metadata.labels['jobset.sigs.k8s.io/coordinator']" - name: TPU_SKIP_MDS_QUERY value: "true" args: - --server_port=29001 - --node_type=resource_manager - --instance_count=WORKLOAD_NODEPOOL_COUNT - --instance_type=SLICE_TOPOLOGY - --gcs_scratch_location=gs://BUCKET_NAME
Argumentbeschreibungen:
--server_port: Der Pathways-Ressourcenmanager verwendet diesen Port für die Kommunikation mit anderen Pathways-Komponenten.--node_type: der Knotentyp. Für den Pathways-Ressourcenmanager sollte dieser Wert auf „resource_manager“ festgelegt werden. Für die anderen Container ist er nicht erforderlich.--instance_count: die Anzahl der TPU-Slices.--instance_type: Der TPU-Typ und die Topologie des Slice. Im Formattpu{TPU type}:{TPU topology}, z. B.tpuv5e:4x4.--gcs_scratch_location: Ein Cloud Storage-Bucket, der für temporäre Dateien verwendet wird.
IFRT-Proxyserver
Sie können den folgenden containerSpec verwenden, um einen IFRT-Proxyserver bereitzustellen:
- name: pathways-proxy image: us-docker.pkg.dev/cloud-tpu-v2-images/pathways/proxy_server:latest imagePullPolicy: Always env: - name: PATHWAYS_HEAD valueFrom: fieldRef: fieldPath: "metadata.labels['jobset.sigs.k8s.io/coordinator']" args: - --resource_manager_address=$(PATHWAYS_HEAD):29001 - --server_port=29000 - --gcs_scratch_location=gs://BUCKET_NAME ports: - containerPort: 29000
Argumentbeschreibungen:
--resource_manager_address: Der Hostname und der Port, die der Proxyserver für die Kommunikation mit dem Pathways-Ressourcenmanager verwendet. Der Port sollte mit dem--server_port-Wert übereinstimmen, der für den Pathways-Ressourcenmanager-Container verwendet wird.--server_port: Der IFRT-Proxyserver verwendet diesen Port für die Kommunikation mit dem IFRT-Proxyclient.--gcs_scratch_location: Ein Cloud Storage-Bucket, der für temporäre Dateien verwendet wird.
Pathways-Mitarbeiter
Sie können die folgenden containerSpec verwenden, um Pathways-Worker bereitzustellen:
- name: worker image: us-docker.pkg.dev/cloud-tpu-v2-images/pathways/server:latest imagePullPolicy: Always env: - name: PATHWAYS_HEAD valueFrom: fieldRef: fieldPath: "metadata.labels['jobset.sigs.k8s.io/coordinator']" - name: MEGASCALE_NUM_SLICES valueFrom: fieldRef: fieldPath: "metadata.labels['jobset.sigs.k8s.io/replicatedjob-replicas']" - name: MEGASCALE_SLICE_ID valueFrom: fieldRef: fieldPath: "metadata.labels['jobset.sigs.k8s.io/job-index']" - name: MEGASCALE_COORDINATOR_ADDRESS value: "$(PATHWAYS_HEAD)" args: - --server_port=29001 - --resource_manager_address=$(PATHWAYS_HEAD):29001 - --gcs_scratch_location=gs://BUCKET_NAME ports: - containerPort: 29001 resources: limits: google.com/tpu: "4"
Argumentbeschreibungen:
--resource_manager_address: Der Hostname und der Port, die die TPU-Worker für die Kommunikation mit dem Pathways-Ressourcenmanager verwenden. Der Port sollte mit dem--server_port-Wert übereinstimmen, der für den Pathways-Ressourcenmanager-Container verwendet wird.--server_port: Die Worker verwenden diesen Port für die Kommunikation mit dem Proxyserver und dem Pathways-Ressourcenmanager.--gcs_scratch_location: Ein Cloud Storage-Bucket, der für temporäre Dateien verwendet wird.
Der Pathways-Ressourcenmanager, der IFRT-Proxyserver und die Pathways-Worker können alle unterschiedliche Ports haben. In diesem Beispiel verwenden der Pathways-Ressourcenmanager und der Pathways-Worker jedoch denselben Port.
Nächste Schritte
- GKE-Cluster mit Pathways erstellen
- Batch-Arbeitslast mit Pathways ausführen
- Inferenz auf mehreren Hosts mit Pathways durchführen
- Interaktive Arbeitslast mit Pathways ausführen
- Belastbares Training mit Pathways
- JAX-Arbeitslasten zu Pathways portieren
- Fehlerbehebung für Pathways on Cloud