
O Pathways é um sistema projetado para permitir a criação de sistemas de machine learning em grande escala, com várias tarefas e ativados esparsamente. Ele permite o uso de milhares ou dezenas de milhares de aceleradores, com a capacidade de alocar dinamicamente quantidades variadas de computação para diferentes tarefas com base nos requisitos de processamento delas.
O Pathways simplifica computações de machine learning em grande escala, permitindo que um único cliente JAX orquestre cargas de trabalho em várias frações grandes de TPU, que podem abranger milhares de chips de TPU.
O Pathways é usado internamente no Google para treinar modelos grandes, como o Gemini. Os programas do Cloud oferecem os mesmos benefícios aos clientes do Google Cloud .
Antes de começar
Você precisa ter:
- Ferramentas do Kubernetes instaladas
- Instale a CLI gcloud.
- Ativar a API TPU
- Ativou a API Google Kubernetes Engine
Este documento oferece uma visão geral de como usar TPUs gerenciadas do programa Pathways no Google Kubernetes Engine (GKE) para cargas de trabalho em lote, em tempo real e interativas. Pressupomos que você já tenha familiaridade com o uso de TPUs com o GKE, incluindo TPUs de fatia única e multifatia no Google Kubernetes Engine, além de experiência geral com TPUs multifatia.
Controlador único e vários controladores
Há principalmente duas maneiras diferentes de gerenciar e orquestrar computações em vários dispositivos:
Recurso |
Controlador único (módulos) |
Multicontrolador (padrão do JAX) |
Controle |
Ponto único de controle: um único programa cliente atua como o controlador central. |
Controle distribuído: vários processos participam, cada um com sua própria instância de interpretador Python. |
Ver |
Visualização unificada: o cliente vê todos os dispositivos como um único sistema unificado. |
Visualização localizada: cada processo Python vê apenas os dispositivos conectados a ele. |
Programação |
Programação simplificada: os usuários interagem com um único cliente, fazendo com que o sistema pareça uma única máquina grande com muitos aceleradores locais. |
SPMD: usa principalmente o paradigma SPMD, exigindo que todos os dispositivos executem o mesmo programa. |
Flexibilidade |
Oferece suporte a padrões de computação mais complexos além do SPMD, incluindo paralelismo de pipeline assimétrico e esparsidade computacional. |
Pode ser menos flexível no gerenciamento de recursos, especialmente em diferentes fatias de TPU. |
Componentes dos programas
A seção a seguir descreve os principais componentes da arquitetura do programa.
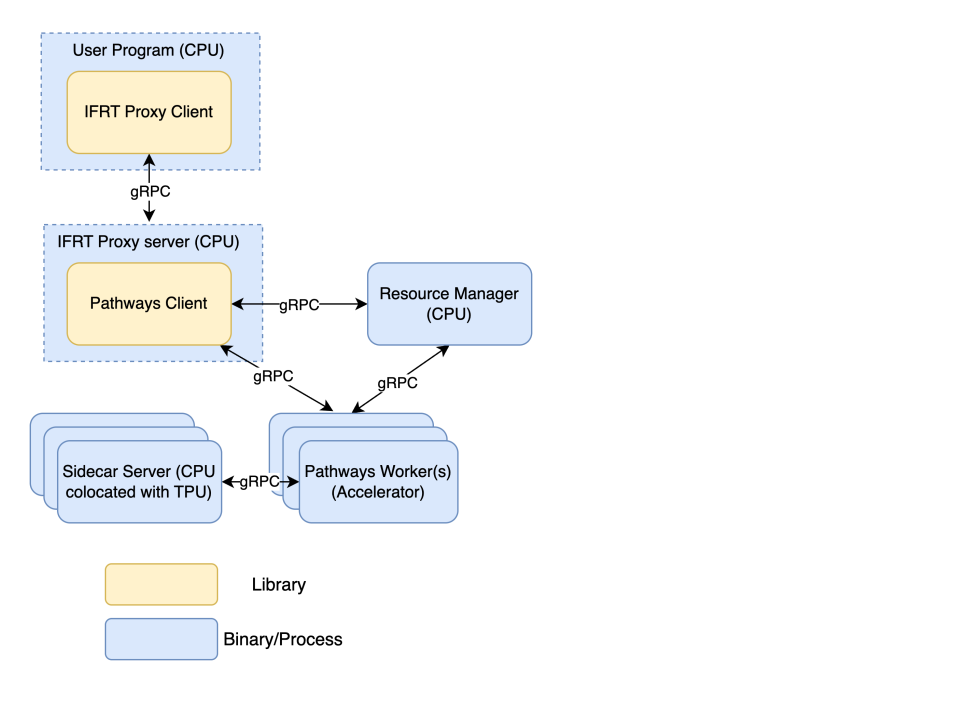
Gerenciador de recursos dos programas
É o plano de controle central do sistema de programas. Ele gerencia todos os recursos do acelerador e é responsável por coordenar a alocação de aceleradores para jobs do usuário. Ele monitora a integridade dos workers e processa o agendamento, a pausa e a retomada de jobs. Ele serve como um único ponto de contato para erros e status do sistema. Esse componente exige apenas recursos de CPU.
Cliente de módulos
Essa é uma implementação do Interim Framework Runtime (IFRT), que serve como ponto de entrada no sistema Pathways. Ele recebe operações de alto nível (HLOs, na sigla em inglês) do seu programa. O cliente do Pathways é responsável por coordenar com o gerenciador de recursos do Pathways para determinar onde colocar programas compilados para execução com base no código do usuário. Ele apresenta uma visualização unificada do sistema para um determinado cliente JAX. Esse componente exige apenas recursos de CPU.
Trabalhador de vias
São os processos executados nas máquinas aceleradoras (VMs de TPU). Eles recebem executáveis compilados do seu programa do servidor proxy IFRT e realizam os cálculos nas TPUs. Os workers do programa de aprendizado enviam dados de volta ao seu programa pelo servidor proxy IFRT. Esse componente exige recursos de acelerador.
Cliente proxy IFRT
Essa é uma implementação de código aberto da API Interim Framework Runtime (IFRT), que separa o código do usuário do ambiente de execução subjacente e melhora a portabilidade e a transparência do código. O JAX usa essa implementação como alternativa ao ambiente de execução padrão de vários controladores. O cliente proxy do IFRT atua como uma ponte de comunicação entre seu programa e os componentes do Pathways. Ele envia solicitações ao servidor proxy do IFRT e recebe resultados dele. É uma implementação OSS da API IFRT. Esse componente exige apenas recursos de CPU.
Servidor proxy do IFRT
Esse servidor gRPC recebe solicitações do cliente proxy IFRT e as encaminha para o cliente do Pathways, que lida com a distribuição real do trabalho. Esse componente exige apenas recursos de CPU.
Servidor secundário
Esse servidor gRPC fica localizado com o worker do Pathways na VM aceleradora para executar o código Python especificado pelo usuário diretamente na VM aceleradora e reduzir a latência de transferência de dados do controlador para os aceleradores. O servidor secundário interage com o worker do Pathways usando um protocolo personalizado com controle de versão no transporte gRPC.
API PathwaysJob
A API PathwaysJob é uma API OSS
nativa do Kubernetes que você usa para implantar treinamento de ML e inferência em lote
cargas de trabalho. O controlador do PathwaysJob usa a API JobSet para gerenciar
o ciclo de vida e a coordenação de todos os componentes do Pathways. Essa definição de recurso personalizado (CRD) oferece uma interface de alto nível para definir as cargas de trabalho do Pathways, abstraindo a necessidade de gerenciar diretamente as especificações individuais de pods para cenários comuns. Para uma lista completa de todos os parâmetros e seus significados específicos, consulte a documentação da API PathwaysJob no GitHub (link em inglês).
apiVersion: pathways-job.pathways.domain/v1 kind: PathwaysJob metadata: name: pathways-USER spec: maxRestarts: MAX_RESTARTS pathwaysVersion: jax-JAX_VERSION workers: - type: $(TPU_MACHINE_TYPE) topology: $(TOPOLOGY) numSlices: $(WORKLOAD_NODEPOOL_COUNT) maxSliceRestarts: # Optional customComponents: # This section is completely optional - componentType: proxy_server image: CUSTOM_PROXY_SERVER customFlags: - --flag_name_1=value_1 customEnv: - name: key_1 value: value_1 - componentType: pathways_server image: CUSTOM_PATHWAYS_SERVER customFlags: - --flag_name_1=value_1 customEnv: - name: key_1 value: value_1 - componentType: worker image: CUSTOM_WORKER customFlags: - --flag_name_1=value_1 customEnv: - name: key_1 value: value_1 - componentType: colocated_python_sidecar image: CUSTOM_SIDECAR_IMAGE customFlags: - --flag_name_1=value_1 customEnv: - name: key_1 value: value_1 pathwaysDir: "gs://BUCKET_NAME" # Pre-create this bucket. controller: deploymentMode: default # Default mode deploys pathways cpu resources (resource # manager and proxy server) on a dedicated CPU node, recommended for training elasticSlices: ELASTIC_SLICES template: spec: containers: - name: main image: python:3.11 command: - bash - -c - | pip install pathwaysutils python3 -c 'import pathwaysutils; import jax; pathwaysutils.initialize(); print(jax.devices())'
A tabela a seguir descreve as configurações da API PathwaysJob:
| Atributo | Descrição |
|---|---|
apiVersion |
Especifica a versão da API para a definição de recurso personalizado (CRD) PathwaysJob: pathways-job.pathways.domain/v1. |
kind |
Identifica o objeto do Kubernetes como um PathwaysJob. |
metadata.name |
O nome do objeto PathwaysJob no Kubernetes, geralmente seguindo o padrão pathways- |
spec |
Define o estado e a configuração desejados para o PathwaysJob. |
spec.maxRestarts |
O número máximo de vezes que o PathwaysJob pode ser reiniciado automaticamente pelo sistema se encontrar falhas. |
spec.pathwaysVersion |
(Opcional) Especifica a versão desejada do framework JAX a ser usada no ambiente do Pathways para este job (por exemplo, jax-0.5.3). |
spec.workers |
Uma matriz que define a configuração do pool de workers do PathwaysJob, geralmente usando recursos de TPU. |
spec.workers[].type |
O tipo de máquina de TPU a ser usada para os nós de trabalho. Por exemplo, $TPU_MACHINE_TYPE pode ser ct6e-standard-4t. |
spec.workers[].topology |
A topologia das frações de TPU alocadas aos trabalhadores (por exemplo, $TOPOLOGY pode ser 2x2, 4x4, 2x2x2). |
spec.workers[].numSlices |
O número de frações de TPU a serem provisionadas para o pool de workers (por exemplo, $WORKLOAD_NODEPOOL_COUNT pode ser 2). |
spec.workers[].maxSliceRestarts |
(Opcional) O número máximo de vezes que um worker individual em uma fração pode ser reiniciado se falhar. |
spec.customComponents |
(Opcional) Uma matriz que permite definir e implantar componentes personalizados (como servidores proxy, servidores do Pathways ou workers adicionais) junto com o job principal. |
spec.customComponents[].componentType |
Especifica o tipo do componente personalizado que está sendo definido (por exemplo, proxy_server, pathways_server, worker, colocated_python_sidecar). |
spec.customComponents[].image |
A imagem Docker a ser usada para o contêiner deste componente personalizado. |
spec.customComponents[].customFlags |
Uma matriz de flags de linha de comando personalizadas que serão transmitidas ao contêiner quando ele for iniciado. |
spec.customComponents[].customEnv |
Uma matriz de variáveis de ambiente personalizadas a serem definidas no contêiner. Cada elemento tem um nome e um valor. |
spec.pathwaysDir |
O bucket do Cloud Storage usado pelo PathwaysJob para
armazenar artefatos de compilação e outros dados temporários.
Ele precisa ser criado antes da execução da carga de trabalho. |
spec.controller |
Configurações do controlador de programas, que gerenciam a execução geral do job. |
spec.controller.deploymentMode |
Especifica como os recursos da CPU do controlador do Pathways (gerenciador de recursos do Pathways e servidor proxy) são implantados. O modo padrão os implanta em um nó de CPU dedicado, enquanto colocate_head_with_workers os implanta ao lado de um worker de TPU. |
spec.controller.elasticSlices |
(Opcional) O número máximo de frações de TPU que podem ficar indisponíveis durante a execução do job antes de serem consideradas não íntegras. |
spec.controller.template |
(Opcional) Define o modelo de pod para o job do usuário. Isso é necessário para cargas de trabalho em lote, mas não para cargas de trabalho interativas. |
spec.controller.template.spec |
A especificação do pod para o job do usuário. |
spec.controller.template.spec.containers |
Uma matriz que define os contêineres que serão executados no job do usuário. |
spec.controller.template.spec.containers[].name |
O nome do contêiner no job do usuário. Neste exemplo, é "main". |
spec.controller.template.spec.containers[].image |
A imagem Docker a ser usada para o contêiner no contêiner principal (neste exemplo, é python:3.11). |
spec.controller.template.spec.containers[].command |
O comando a ser executado quando o contêiner principal for iniciado. Neste exemplo, ele instala `pathwaysutils`, inicializa o Pathways e imprime dispositivos JAX. |
Componentes do programa de aprendizado no GKE
Esta seção mapeia os componentes dos programas de aprendizado para os componentes do Google Kubernetes Engine, como contêineres e pods.
Você encontra as imagens de contêiner dos programas de aprendizado nos seguintes locais.
Tipo de contêiner |
Local |
Servidor proxy do IFRT |
|
Gerenciador/worker de recursos de programas |
|
Gerenciador de recursos dos programas
Depois de criar um cluster do GKE, use o seguinte containerSpec para implantar o gerenciador de recursos de programas:
- name: pathways-rm image: us-docker.pkg.dev/cloud-tpu-v2-images/pathways/server:latest imagePullPolicy: Always env: - name: HOST_ADDRESS valueFrom: fieldRef: fieldPath: "metadata.labels['jobset.sigs.k8s.io/coordinator']" - name: TPU_SKIP_MDS_QUERY value: "true" args: - --server_port=29001 - --node_type=resource_manager - --instance_count=WORKLOAD_NODEPOOL_COUNT - --instance_type=SLICE_TOPOLOGY - --gcs_scratch_location=gs://BUCKET_NAME
Descrições dos argumentos:
--server_port: o gerenciador de recursos do programa usa essa porta para se comunicar com outros componentes do programa.--node_type: o tipo de nó. Defina como "resource_manager" para o gerenciador de recursos do Pathways. Não é necessário para os outros contêineres.--instance_count: o número de frações de TPU.--instance_type: o tipo de TPU e a topologia da fração. No formatotpu{TPU type}:{TPU topology}, por exemplo,tpuv5e:4x4.--gcs_scratch_location: um bucket do Cloud Storage usado para arquivos temporários.
Servidor proxy do IFRT
Use o seguinte containerSpec para implantar um servidor proxy IFRT:
- name: pathways-proxy image: us-docker.pkg.dev/cloud-tpu-v2-images/pathways/proxy_server:latest imagePullPolicy: Always env: - name: PATHWAYS_HEAD valueFrom: fieldRef: fieldPath: "metadata.labels['jobset.sigs.k8s.io/coordinator']" args: - --resource_manager_address=$(PATHWAYS_HEAD):29001 - --server_port=29000 - --gcs_scratch_location=gs://BUCKET_NAME ports: - containerPort: 29000
Descrições dos argumentos:
--resource_manager_address: o nome do host e a porta que o servidor proxy usa para se comunicar com o gerenciador de recursos do Pathways. A porta precisa ser a mesma do valor--server_portusado para o contêiner do gerenciador de recursos do Pathways.--server_port: o servidor proxy do IFRT usa essa porta para se comunicar com o cliente proxy do IFRT.--gcs_scratch_location: um bucket do Cloud Storage usado para arquivos temporários.
Trabalhador de vias
Você pode usar os seguintes containerSpec para implantar trabalhadores do Pathways:
- name: worker image: us-docker.pkg.dev/cloud-tpu-v2-images/pathways/server:latest imagePullPolicy: Always env: - name: PATHWAYS_HEAD valueFrom: fieldRef: fieldPath: "metadata.labels['jobset.sigs.k8s.io/coordinator']" - name: MEGASCALE_NUM_SLICES valueFrom: fieldRef: fieldPath: "metadata.labels['jobset.sigs.k8s.io/replicatedjob-replicas']" - name: MEGASCALE_SLICE_ID valueFrom: fieldRef: fieldPath: "metadata.labels['jobset.sigs.k8s.io/job-index']" - name: MEGASCALE_COORDINATOR_ADDRESS value: "$(PATHWAYS_HEAD)" args: - --server_port=29001 - --resource_manager_address=$(PATHWAYS_HEAD):29001 - --gcs_scratch_location=gs://BUCKET_NAME ports: - containerPort: 29001 resources: limits: google.com/tpu: "4"
Descrições dos argumentos:
--resource_manager_address: o nome do host e a porta que os workers da TPU usam para se comunicar com o gerenciador de recursos do Pathways. A porta precisa ser a mesma que o valor--server_portusado para o contêiner do gerenciador de recursos do Pathways.--server_port: os workers usam essa porta para se comunicar com o servidor proxy e o gerenciador de recursos do Pathways.--gcs_scratch_location: um bucket do Cloud Storage usado para arquivos temporários.
O gerenciador de recursos do Pathways, o servidor proxy IFRT e os workers do Pathways podem ter portas diferentes, mas, neste exemplo, o gerenciador de recursos e o worker do Pathways compartilham a mesma porta.
A seguir
- Criar um cluster do GKE com o Pathways
- Executar uma carga de trabalho em lote com o Pathways
- Realizar a inferência com vários hosts usando o Pathways
- Executar uma carga de trabalho interativa com o Pathways
- Treinamento resiliente com programas
- Portar cargas de trabalho do JAX para o Pathways
- Resolver problemas dos programas de treinamentos no cloud