
Pathways est un système conçu pour permettre la création de systèmes de machine learning à grande échelle, multitâches et à activation partielle. Il permet d'utiliser des milliers ou des dizaines de milliers d'accélérateurs, avec la possibilité d'allouer dynamiquement différentes quantités de calcul pour différentes tâches en fonction de leurs besoins de traitement.
Pathways simplifie les calculs de machine learning à grande échelle en permettant à un seul client JAX d'orchestrer les charges de travail sur plusieurs grandes tranches de TPU, pouvant potentiellement s'étendre sur des milliers de puces TPU.
Pathways est utilisé en interne chez Google pour entraîner de grands modèles comme Gemini. Pathways on Cloud offre les mêmes avantages aux clients Google Cloud .
Avant de commencer
Vérifiez que vous disposez bien des éléments suivants :
Ce document explique comment utiliser les TPU gérés Pathways sur Google Kubernetes Engine (GKE) pour les charges de travail par lot, en temps réel et interactives. Il part du principe que vous savez déjà comment utiliser les TPU avec GKE, y compris les TPU multislices sur Google Kubernetes Engine, et que vous avez une expérience générale avec les TPU multislices.
Contrôleur unique et multicontrôleur
Il existe principalement deux façons de gérer et d'orchestrer les calculs sur plusieurs appareils :
Fonctionnalité |
Manette unique (Parcours) |
Plusieurs contrôleurs (par défaut dans JAX) |
Contrôle |
Point de contrôle unique : un seul programme client sert de contrôleur central. |
Contrôle distribué : plusieurs processus participent, chacun avec sa propre instance d'interpréteur Python. |
Afficher |
Vue unifiée : le client voit tous les appareils comme un seul système unifié. |
Vue localisée : chaque processus Python ne voit que les appareils qui lui sont connectés. |
Programmation |
Programmation simplifiée : les utilisateurs interagissent avec un seul client, ce qui fait apparaître le système comme une seule grande machine avec de nombreux accélérateurs locaux. |
SPMD : utilise principalement le paradigme SPMD, qui exige que tous les appareils exécutent le même programme. |
Flexibilité |
Il est compatible avec des schémas de calcul plus complexes que SPMD, y compris le parallélisme de pipeline asymétrique et la parcimonie de calcul. |
Peut être moins flexible dans la gestion des ressources, en particulier sur différentes tranches de TPU. |
Composants des parcours
La section suivante décrit les principaux composants de l'architecture Pathways.
Gestionnaire de ressources Pathways
Il s'agit du plan de contrôle central du système Pathways. Il gère toutes les ressources d'accélérateur et est responsable de la coordination de l'allocation des accélérateurs pour les jobs utilisateur. Il surveille l'état des nœuds de calcul et gère la planification, la mise en veille et la reprise des tâches. Il sert de point de contact unique pour les erreurs et l'état du système. Ce composant ne nécessite que des ressources de processeur.
Client Pathways
Il s'agit d'une implémentation du runtime du framework intermédiaire (IFRT, Interim Framework Runtime) qui sert de point d'entrée dans le système Pathways. Il reçoit des opérations de haut niveau (HLO) de votre programme. Le client Pathways est responsable de la coordination avec le gestionnaire de ressources Pathways pour déterminer où placer les programmes compilés pour l'exécution en fonction du code utilisateur. Il présente une vue unifiée du système à un client JAX donné. Ce composant ne nécessite que des ressources de processeur.
Employé Pathways
Il s'agit des processus qui s'exécutent sur les machines d'accélérateur (VM TPU). Ils reçoivent les exécutables compilés de votre programme à partir du serveur proxy IFRT et effectuent les calculs sur les TPU. Les employés Pathways renvoient les données à votre programme via le serveur proxy IFRT. Ce composant nécessite des ressources d'accélérateur.
Client proxy IFRT
Il s'agit d'une implémentation OSS de l'API Interim Framework Runtime (IFRT) qui découple le code utilisateur du runtime sous-jacent et améliore la portabilité et la transparence du code. JAX utilise cette implémentation comme alternative à son environnement d'exécution multi-contrôleur par défaut. Le client proxy IFRT sert de pont de communication entre votre programme et les composants Pathways. Il envoie des requêtes au serveur proxy IFRT et reçoit les résultats. Il s'agit d'une implémentation OSS de l'API IFRT. Ce composant ne nécessite que des ressources de processeur.
Serveur proxy IFRT
Ce serveur gRPC reçoit les requêtes du client proxy IFRT et les transmet au client Pathways, qui gère la distribution réelle du travail. Ce composant ne nécessite que des ressources de processeur.
Serveur side-car
Ce serveur gRPC est colocalisé avec le nœud de calcul Pathways sur la VM de l'accélérateur pour exécuter le code Python spécifié par l'utilisateur directement sur la VM de l'accélérateur. Cela permet de réduire la latence de transfert de données du contrôleur vers les accélérateurs. Le serveur side-car interagit avec le worker Pathways via un protocole personnalisé versionné sur le transport gRPC.
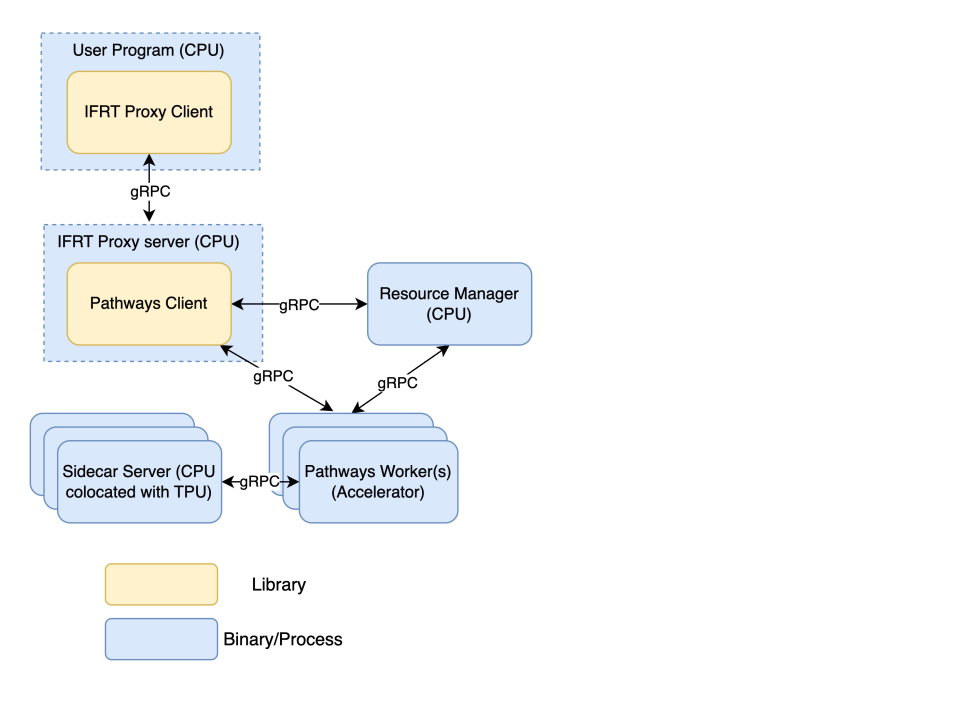
Composants Pathways sur GKE
Cette section mappe les composants Pathways aux composants Google Kubernetes Engine tels que les conteneurs et les pods.
Vous trouverez les images de conteneurs Pathways aux emplacements suivants.
Type de conteneur |
Emplacement |
Serveur proxy IFRT |
|
Gestionnaire/Worker de ressources Pathways |
|
Gestionnaire de ressources Pathways
Après avoir créé un cluster GKE, vous pouvez utiliser le containerSpec suivant pour déployer le gestionnaire de ressources de parcours :
- name: pathways-rm image: us-docker.pkg.dev/cloud-tpu-v2-images/pathways/server:latest imagePullPolicy: Always env: - name: HOST_ADDRESS valueFrom: fieldRef: fieldPath: "metadata.labels['jobset.sigs.k8s.io/coordinator']" - name: TPU_SKIP_MDS_QUERY value: "true" args: - --server_port=29001 - --node_type=resource_manager - --instance_count=WORKLOAD_NODEPOOL_COUNT - --instance_type=SLICE_TOPOLOGY - --gcs_scratch_location=gs://BUCKET_NAME
Descriptions des arguments :
--server_port: le gestionnaire de ressources Pathways utilise ce port pour communiquer avec d'autres composants Pathways.--node_type: type de nœud. Cette valeur doit être définie sur "resource_manager" pour le gestionnaire de ressources Pathways et n'est pas nécessaire pour les autres conteneurs.--instance_count: nombre de tranches de TPU.--instance_type: type et topologie de la tranche de TPU. Au formattpu{TPU type}:{TPU topology}, par exempletpuv5e:4x4.--gcs_scratch_location: bucket Cloud Storage utilisé pour les fichiers temporaires.
Serveur proxy IFRT
Vous pouvez utiliser le containerSpec suivant pour déployer un serveur proxy IFRT :
- name: pathways-proxy image: us-docker.pkg.dev/cloud-tpu-v2-images/pathways/proxy_server:latest imagePullPolicy: Always env: - name: PATHWAYS_HEAD valueFrom: fieldRef: fieldPath: "metadata.labels['jobset.sigs.k8s.io/coordinator']" args: - --resource_manager_address=$(PATHWAYS_HEAD):29001 - --server_port=29000 - --gcs_scratch_location=gs://BUCKET_NAME ports: - containerPort: 29000
Descriptions des arguments :
--resource_manager_address: nom d'hôte et port utilisés par le serveur proxy pour communiquer avec le gestionnaire de ressources Pathways. Le port doit être identique à la valeur--server_portutilisée pour le conteneur du gestionnaire de ressources Pathways.--server_port: le serveur proxy IFRT utilise ce port pour communiquer avec le client proxy IFRT.--gcs_scratch_location: bucket Cloud Storage utilisé pour les fichiers temporaires.
Employé Pathways
Vous pouvez utiliser les containerSpec suivants pour déployer des workers Pathways :
- name: worker image: us-docker.pkg.dev/cloud-tpu-v2-images/pathways/server:latest imagePullPolicy: Always env: - name: PATHWAYS_HEAD valueFrom: fieldRef: fieldPath: "metadata.labels['jobset.sigs.k8s.io/coordinator']" - name: MEGASCALE_NUM_SLICES valueFrom: fieldRef: fieldPath: "metadata.labels['jobset.sigs.k8s.io/replicatedjob-replicas']" - name: MEGASCALE_SLICE_ID valueFrom: fieldRef: fieldPath: "metadata.labels['jobset.sigs.k8s.io/job-index']" - name: MEGASCALE_COORDINATOR_ADDRESS value: "$(PATHWAYS_HEAD)" args: - --server_port=29001 - --resource_manager_address=$(PATHWAYS_HEAD):29001 - --gcs_scratch_location=gs://BUCKET_NAME ports: - containerPort: 29001 resources: limits: google.com/tpu: "4"
Descriptions des arguments :
--resource_manager_address: nom d'hôte et port utilisés par les workers TPU pour communiquer avec le gestionnaire de ressources Pathways. Le port doit être identique à la valeur--server_portutilisée pour le conteneur du gestionnaire de ressources Pathways.--server_port: les nœuds de calcul utilisent ce port pour communiquer avec le serveur proxy et le gestionnaire de ressources Pathways.--gcs_scratch_location: bucket Cloud Storage utilisé pour les fichiers temporaires.
Le gestionnaire de ressources Pathways, le serveur proxy IFRT et les workers Pathways peuvent tous avoir des ports différents, mais dans cet exemple, le gestionnaire de ressources Pathways et le worker Pathways partagent le même port.
Étapes suivantes
- Créer un cluster GKE avec Pathways
- Exécuter une charge de travail par lot avec Pathways
- Effectuer une inférence multihôte à l'aide de Pathways
- Exécuter une charge de travail interactive avec Pathways
- Entraînement résilient avec Pathways
- Transférer des charges de travail JAX vers Pathways
- Résoudre les problèmes liés aux parcours sur le cloud