
AI Hypercomputer は、GPU マシンを使用してマルチホストの人工知能(AI)と機械学習(ML)のワークロードをデプロイするのに役立つスーパーコンピューティング システムです。デプロイで使用する基盤となるネットワーク サービスは、選択したGPU マシンタイプによって決まります。
このドキュメントは、アーキテクト、ネットワーク エンジニア、デベロッパーが GPU マシンに関連する基盤となるネットワーク サービスを理解するのに役立ちます。このドキュメントは、クラウド ネットワーキングと分散コンピューティングのコンセプトを基本的な知識があることを前提としています。
GPU マシンのネットワーキング サービスを理解することは、ワークロードを正常にデプロイして管理するための第一歩であり、パフォーマンスとグッドプットを最適化するために不可欠です。 グッドプット(またはグッド スループット)は、システムによる ML トレーニング タスクの実質的な進行状況を測定します。この指標は、経過時間や生のスループット レートなどの指標と比較して、追加の分析情報を提供します。
一部の GPU マシンタイプには、すべてのレベルで通信を最適化する明確な階層構造があります。この階層は、データセンター ファブリックから AI 最適化クラスタ、Compute Engine インスタンスまで及びます。次のセクションでは、これらの階層コンポーネントについて説明します。
GPU ネットワーク アーキテクチャ
AI Hypercomputer は、階層型のレール整列型 ネットワーク アーキテクチャを使用するGPU マシンのデプロイに役立ちます。この設計の予測可能で高性能な接続により、通信のオーバーヘッドが最小限に抑えられます。これにより、GPU がデータの待機ではなくコンピューティングに費やす時間を増やすことで、グッドプットが直接向上します。
GPU のレール整列型配置は、主に次の 3 つのコンポーネントで構成されています。
- サブブロック: これは基盤となる単位であり、単一ラック上に物理的に同居するホスト群で構成されています。トップオブラック(ToR)スイッチはこれらのホストを接続し、サブブロック内の任意の 2 つの GPU 間で非常に効率的なシングルホップ通信を可能にします。RDMA over Converged Ethernet(RoCE)により、この直接通信を容易に行うことができます。Google のレール整列型トポロジに最適化された拡張 NCCL ライブラリは、GPU 通信コレクティブを処理します。
- ブロック: これは、ノンブロッキング ファブリックで相互接続された複数のサブブロックで構成されており、高帯域幅の相互接続を可能にします。ブロック内の GPU は、最大 2 つのネットワーク ホップで到達できます。システムは、最適なジョブ配置を可能にするために、ブロックとサブブロックのメタデータを公開します。
- クラスタ: これは、相互接続された複数のブロックで構成され、数千の GPU にスケールできるため、大規模なトレーニング ワークロードを実行できます。異なるブロック間の通信では、ホップが 1 つ追加されるだけです。大規模な場合でも、高パフォーマンスと予測可能性が維持されます。 インテリジェントな大規模ジョブの配置を可能にするために、クラスタレベルのメタデータはオーケストレーターでも使用できます。
GPU 間通信のテクノロジー
GPU マシンは、複数のテクノロジーを組み合わせて使用し、ワークロードに対して高パフォーマンス、高スループット、低レイテンシを実現します。これらのテクノロジーには、RDMA over Converged Ethernet(RoCE)、NVIDIA NIC、Google のデータセンター全体を網羅するレール整列型ネットワーク トポロジが含まれます。
これらのマシンタイプは、NVIDIA の NVLink テクノロジーを使用して、各マシン上の NVIDIA NIC 間に超高速の直接データパスを作成します。また、RoCE により、異なるマシン上の GPU 間で効率的な RDMA が可能になります。
GPU ネットワーキング スタック
ネットワーキング スタックは、GPU 間通信を実装するために連携して動作するソフトウェア プロトコル、ドライバ、レイヤのコレクションです。GPU マシンタイプごとに異なるネットワーキング スタックを使用します。次の表に、ネットワーキング スタックとそれに関連するマシンタイプを示します。
| ネットワーキング スタック | 説明 | GPU マシンタイプ |
|---|---|---|
| GPUDirect RDMA | GPUDirect RDMA により、GPU と別のデバイス間でデータを直接交換するためのパスが有効になります。A4X Max インスタンスと A4X インスタンスの場合、 このネットワーキング スタックは RDMA over Converged Ethernet(RoCE)を使用します。このテクノロジー により、ピアデバイスは GPU のメモリから直接読み取りと書き込みを行うことができます。 CPU をバイパスして、高性能な データ交換のためのより効率的な接続を作成します。詳細については、Cluster 構成オプションと GPUDirect RDMA をご覧ください。 | |
| GPUDirect-TCPXO | GPUDirect-TCPXO は、TCP プロトコルをオフロードすることで GPUDirect-TCPX を改善します。GPUDirect-TCPXO を使用すると、A3 Mega マシンタイプ では、A3 High マシンタイプと A3 Edge マシンタイプ と比較して 2 倍のネットワーク帯域幅を使用できます。GPUDirect-TCPXO を使用する GKE クラスタでネットワーク帯域幅を最大化する方法については、Standard モードのクラスタで GPU ネットワーク帯域幅を最大にするをご覧ください。[GPUDirect-TCPXO] タブを選択します。 | |
| GPUDirect-TCPX | GPUDirect-TCPX では、データパケットのペイロードを GPU メモリからネットワーク インターフェースに直接転送できるため、ネットワーク パフォーマンスが向上します。GPUDirect-TCPX を使用する GKE クラスタでネットワーク帯域幅を最大化する方法については、Standard モードのクラスタで GPU ネットワーク帯域幅を最大にするをご覧ください。[GPUDirect-TCPX] タブを選択します。 |
ホストとストレージのデータプレーン ネットワーク
GPU 間の直接通信を除き、すべてのトラフィックは別個のネットワーク パスで処理されます。このトラフィックには、Cloud Storage へのアクセス、ホストレベル の管理、他の Google Cloud サービスとの通信が含まれます。このトラフィックを管理するために、GPU マシンタイプは Google Titanium NIC を使用します。
Titanium NIC は、CPU からネットワーク処理タスクをオフロードし、CPU がワークロードに集中できるようにします。この分離により、汎用トラフィックと専用の GPU 間トラフィックは異なる物理インターフェースを使用し、同じシステム リソースを競合しないようにします。
マルチ VPC 環境
すべてのワークロードは、 Google Cloudの Virtual Private Cloud(VPC)内で動作します。
高パフォーマンスのアクセラレータ マシンは、複数の物理ネットワーク インターフェースを使用してさまざまな種類のトラフィックを処理する特殊なハードウェア設計を備えています。 この特殊なハードウェア設計を処理するには、ワークロードの実行に Slurm、GKE、Compute Engine のいずれを使用する場合でも、マルチ VPC 環境が必要です。
具体的なマルチ VPC 構成は、GPU マシンタイプとそのネットワーキング スタックによって異なります。
GPUDirect RDMA を使用する A4X Max、A4X、A4、A3 Ultra: これらのマシンは、汎用ホスト トラフィック(gVNIC)にデフォルトの VPC ネットワークを使用し、汎用ホスト トラフィック用に 1 つの追加の VPC ネットワークと、すべての GPU 間トラフィック用に 1 つの共有 VPC ネットワークが必要です。GPU トラフィック VPC で RDMA ネットワーク プロファイルを有効にする必要があります。A4 VM と A3 Ultra VM のこの 構成の詳細については、VPC と サブネットを作成するをご覧ください。
GPUDirect-TCPXO を使用する A3 Mega: これらのマシンには、高帯域幅通信専用の GPU NIC 用に 8 つの個別の VPC が必要です。この構成を完了する手順については、VPC と サブネットを作成するをご覧ください。
GPUDirect-TCPX を使用する A3 High: これらのマシンには、高帯域幅通信専用の GPU NIC 用に 4 つの個別の VPC が必要です。この構成を完了する手順については、VPC と サブネットを作成するをご覧ください。
このマルチ VPC 構成により、ストレージ オペレーションやその他のシステムタスクが、重要な GPU 間通信と帯域幅を競合しないようにします。
設定する必要があるマルチ VPC ネットワーク構成は、GPU マシンタイプによって異なります。サポートされているすべての GPU マシンタイプのネットワーク構成、 帯域幅速度、NIC の詳細については、ネットワーキング と GPU マシンをご覧ください。
次の図は、GPU マシンのネットワーク アーキテクチャを示しています。汎用トラフィックと専用の GPU 間トラフィックが異なるネットワーク プレーンに分離されていることを示しています。
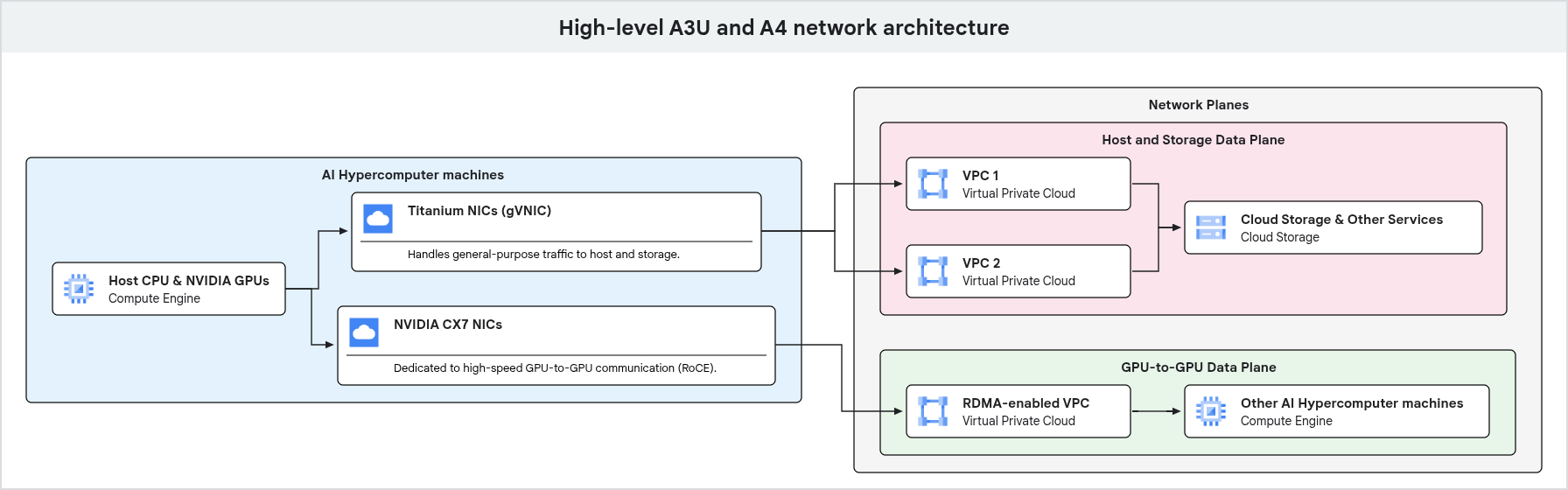
上の図に示すように、GPU マシンはさまざまな種類のトラフィックに専用のネットワーク パスを使用します。管理やストレージ アクセスなどの汎用トラフィックは、VPC に接続されている Google Titanium NIC を通過します。高性能な GPU 間通信では、RDMA などのテクノロジーで最適化された個別のネットワーク インターフェースと VPC を使用し、AI と ML のワークロードに対して高帯域幅と低レイテンシを実現します。
ネットワーキング ライブラリとコンポーネント
ネットワーク帯域幅とパフォーマンスを最大化するために、次のネットワーキング ライブラリとコンポーネントを使用すると、Google のネットワーキング スタックで GPU を使用できます。
- gVNIC: Google Virtual NIC(gVNIC)は、Compute Engine 専用に設計された仮想ネットワーク インターフェースです。gVNIC は、パフォーマンスの向上、一貫性の向上、ノイジー ネイバー問題の軽減を実現します。すべてのマシン ファミリー、マシンタイプ、世代でサポートおよび推奨されており、ホスト間通信に推奨される vNIC です。詳細については、Google Virtual NIC の使用をご覧ください。
- NCCL: NVIDIA Collective Communications Library(NCCL)は、集団通信オペレーション用に最適化されたプリミティブを提供します。NVIDIA GPU とネットワーキングを使用して、マルチ GPU 環境とマルチノード環境向けに特別に設計されています。NCCL テストを実行して、デプロイされたクラスタのパフォーマンスを評価します。 詳細については、NCCCL テストをデプロイして実行するをご覧ください。
- GKE マルチネットワーキング: Pod のマルチネットワーク サポートにより、GKE クラスタ内のノードと Pod で複数のインターフェースを有効にできます。GPUDirect のコンテキストでマルチネットワーキングを設定する方法については、Standard モードのクラスタで GPU ネットワーク帯域幅を最大にする および GPUDirect RDMA を使用したクラスタ構成オプションをご覧ください。
利用可能なソフトウェア スタックの詳細については、OS と Docker イメージをご覧ください。
次のステップ
- クラスタと VM のデプロイのネットワーク サービス について学習する。
- AI Hypercomputer のネットワーキングのベスト プラクティスについて学習する。
- AI Hypercomputer の GPU マシンタイプと ストレージ サービスについて学習する。