
AI 하이퍼컴퓨터는 GPU 머신을 사용하여 멀티 호스트 인공지능 (AI) 및 머신러닝 (ML) 워크로드를 배포할 수 있는 슈퍼컴퓨팅 시스템입니다. 배포에서 사용하는 기본 네트워크 서비스는 선택한 GPU 머신 유형에 따라 결정됩니다.
이 문서는 설계자, 네트워크 엔지니어, 개발자가 GPU 머신과 관련된 기본 네트워크 서비스를 이해하는 데 도움이 됩니다. 이 문서에서는 사용자가 클라우드 네트워킹 및 분산 컴퓨팅 개념에 대해 기본적인 지식을 갖추고 있다고 가정합니다.
GPU 머신 네트워킹 서비스를 이해하는 것은 워크로드를 성공적으로 배포하고 관리하는 첫 번째 단계이며 성능과 굿풋을 최적화하는 데 필수적입니다. 굿풋은 ML 학습 작업에서 시스템의 효과적인 진행 상황을 측정합니다. 이 측정항목은 경과된 총 시간 또는 원시 처리량 비율과 같은 측정항목과 비교할 때 추가적인 유용한 정보를 제공합니다.
일부 GPU 머신 유형에는 모든 수준에서 통신을 최적화하는 고유한 계층화된 계층 구조가 있습니다. 이 계층 구조는 데이터 센터 패브릭에서 AI 최적화 클러스터 및 Compute Engine 인스턴스에 이르기까지 다양합니다. 다음 섹션에서는 이러한 계층적 구성요소를 설명합니다.
GPU 네트워크 아키텍처
AI 하이퍼컴퓨터를 사용하면 계층적 레일 정렬 네트워크 아키텍처를 사용하는 GPU 머신을 배포할 수 있습니다. 이 설계의 예측 가능하고 고성능 연결은 통신 오버헤드를 최소화하므로 GPU가 데이터를 기다리는 대신 계산에 더 많은 시간을 할애할 수 있어 굿풋이 직접적으로 개선됩니다.
레일 정렬 GPU 배열은 세 가지 기본 구성요소로 이루어집니다.
- 하위 블록: 단일 랙에 물리적으로 공동 배치된 호스트 그룹으로 구성된 기본 단위입니다. 랙 상단 (ToR) 스위치는 이러한 호스트를 연결하여 하위 블록 내의 두 GPU 간에 매우 효율적인 단일 홉 통신을 지원합니다. 컨버지드 이더넷 (RoCE)을 통한 RDMA는 이러한 직접 통신을 지원합니다. Google의 레일 정렬 토폴로지에 최적화된 향상된 NCCL 라이브러리가 GPU 통신 집합을 처리합니다.
- 블록: 차단되지 않는 패브릭으로 상호 연결된 여러 하위 블록으로 구성되어 있어 고대역폭 상호 연결이 가능합니다. 블록 내의 모든 GPU는 최대 2개의 네트워크 홉으로 연결할 수 있습니다. 시스템은 최적의 작업 배치를 지원하기 위해 블록 및 하위 블록 메타데이터를 노출합니다.
- 클러스터: 서로 연결된 여러 블록으로 구성되며, 수천 개의 GPU로 확장하여 대규모 학습 워크로드를 실행할 수 있습니다. 다양한 블록 간 통신은 홉을 하나만 추가하므로 대규모에서도 높은 성능과 예측 가능성을 유지합니다. 지능적인 대규모 작업 배치를 지원하기 위해 클러스터 수준 메타데이터는 조정자가 사용할 수도 있습니다.
GPU 간 통신 기술
GPU 머신은 여러 기술을 조합하여 워크로드에 고성능, 높은 처리량, 짧은 지연 시간을 제공합니다. 이러한 기술에는 RDMA over Converged Ethernet (RoCE), NVIDIA NIC, Google의 데이터 센터 전체에 걸친 레일 정렬 네트워크 토폴로지가 포함됩니다.
이러한 머신 유형은 NVIDIA의 NVLink 기술을 사용하여 각 머신의 NVIDIA NIC 간에 초고속 직접 데이터 경로를 만듭니다. 또한 RoCE는 여러 머신에 있는 GPU 간에 효율적인 RDMA를 지원합니다.
GPU 네트워킹 스택
네트워킹 스택은 GPU 간 통신을 구현하기 위해 함께 작동하는 소프트웨어 프로토콜, 드라이버, 레이어의 모음입니다. GPU 머신 유형에 따라 다른 네트워킹 스택이 사용됩니다. 다음 표에서는 네트워킹 스택과 관련 머신 유형을 정의합니다.
| 네트워킹 스택 | 설명 | GPU 머신 유형 |
|---|---|---|
| GPUDirect RDMA | GPUDirect RDMA는 GPU와 다른 기기 간의 데이터 교환을 위한 직접 경로를 지원합니다. A4X Max 및 A4X 인스턴스의 경우 이 네트워킹 스택은 RDMA over Converged Ethernet (RoCE)을 사용합니다. 이 기술을 사용하면 피어 기기가 GPU의 메모리에서 직접 읽고 쓸 수 있으므로 CPU를 우회하여 고성능 데이터 교환을 위한 더 효율적인 연결을 만들 수 있습니다. 자세한 내용은 GPUDirect RDMA를 사용한 클러스터 구성 옵션을 참고하세요. | |
| GPUDirect-TCPXO | GPUDirect-TCPXO는 TCP 프로토콜을 오프로드하여 GPUDirect-TCPX를 개선합니다. GPUDirect-TCPXO를 사용하면 A3 Mega 머신 유형의 네트워크 대역폭이 A3 High 및 A3 Edge 머신 유형에 비해 두 배가 됩니다. GPUDirect-TCPXO를 사용하는 GKE 클러스터에서 네트워크 대역폭을 극대화하는 방법에 관한 자세한 내용은 Standard 모드 클러스터에서 GPU 네트워크 대역폭 극대화를 참고하고 GPUDirect-TCPXO 탭을 선택하세요. | |
| GPUDirect-TCPX | GPUDirect-TCPX는 데이터 패킷 페이로드가 GPU 메모리에서 네트워크 인터페이스로 직접 전송될 수 있게 하여 네트워크 성능을 향상시킵니다. GPUDirect-TCPX를 사용하는 GKE 클러스터에서 네트워크 대역폭을 극대화하는 방법에 관한 자세한 내용은 Standard 모드 클러스터에서 GPU 네트워크 대역폭 극대화를 참고하고 GPUDirect-TCPX 탭을 선택하세요. |
호스트 및 스토리지 데이터 영역 네트워크
별도의 네트워크 경로는 GPU 간 직접 통신이 아닌 모든 트래픽을 처리합니다. 이 트래픽에는 Cloud Storage 액세스, 호스트 수준 관리, 다른 Google Cloud 서비스와의 통신이 포함됩니다. 이 트래픽을 관리하기 위해 GPU 머신 유형은 Google Titanium NIC를 사용합니다.
Titanium NIC는 CPU에서 네트워크 처리 작업을 오프로드하여 CPU가 워크로드에 집중할 수 있도록 합니다. 이렇게 분리하면 범용 트래픽과 전용 GPU 간 트래픽이 서로 다른 물리적 인터페이스를 사용하여 동일한 시스템 리소스를 놓고 경쟁하지 않습니다.
멀티 VPC 환경
모든 워크로드는 Google Cloud의 가상 프라이빗 클라우드 (VPC) 내에서 작동합니다.
고성능 가속기 머신은 여러 물리적 네트워크 인터페이스를 사용하여 다양한 유형의 트래픽을 처리하는 특수 하드웨어 설계를 갖추고 있습니다. 이 특수 하드웨어 설계를 처리하려면 워크로드를 실행하는 데 Slurm, GKE, Compute Engine 중 무엇을 사용하는지와 관계없이 멀티 VPC 환경이 필요합니다.
구체적인 다중 VPC 구성은 GPU 머신 유형과 네트워킹 스택에 따라 달라집니다.
GPUDirect RDMA를 사용하는 A4X Max, A4X, A4, A3 Ultra: 이러한 머신은 범용 호스트 트래픽 (gVNIC)에 기본 VPC 네트워크를 사용하며 범용 호스트 트래픽용 추가 VPC 네트워크 1개와 모든 GPU 간 트래픽용 공유 VPC 네트워크 1개가 필요합니다. GPU 트래픽 VPC에서 RDMA 네트워크 프로필이 사용 설정되어 있어야 합니다. A4 VM 및 A3 Ultra VM의 이 구성에 대한 자세한 내용은 VPC 및 서브넷 만들기를 참고하세요.
GPUDirect-TCPXO가 적용된 A3 Mega: 이러한 머신에는 고대역폭 통신 전용인 GPU NIC를 위한 별도의 VPC가 8개 필요합니다. 이 구성을 완료하는 방법에 관한 자세한 단계는 VPC 및 서브넷 만들기를 참고하세요.
GPUDirect-TCPX가 있는 A3 High: 이러한 머신에는 고대역폭 통신 전용인 GPU NIC를 위한 별도의 VPC가 4개 필요합니다. 이 구성을 완료하는 방법에 관한 자세한 단계는 VPC 및 서브넷 만들기를 참고하세요.
이 다중 VPC 구성을 사용하면 스토리지 작업과 기타 시스템 작업이 중요한 GPU 간 통신과 대역폭을 두고 경쟁하지 않습니다.
설정해야 하는 필수 멀티 VPC 네트워크 구성은 GPU 머신 유형에 따라 다릅니다. 지원되는 모든 GPU 머신 유형의 네트워크 구성, 대역폭 속도, NIC에 관한 자세한 가이드는 네트워킹 및 GPU 머신을 참고하세요.
다음 다이어그램은 GPU 머신의 네트워크 아키텍처를 보여주며, 범용 트래픽과 전용 GPU-GPU 트래픽이 서로 다른 네트워크 평면으로 분리되어 있음을 강조합니다.
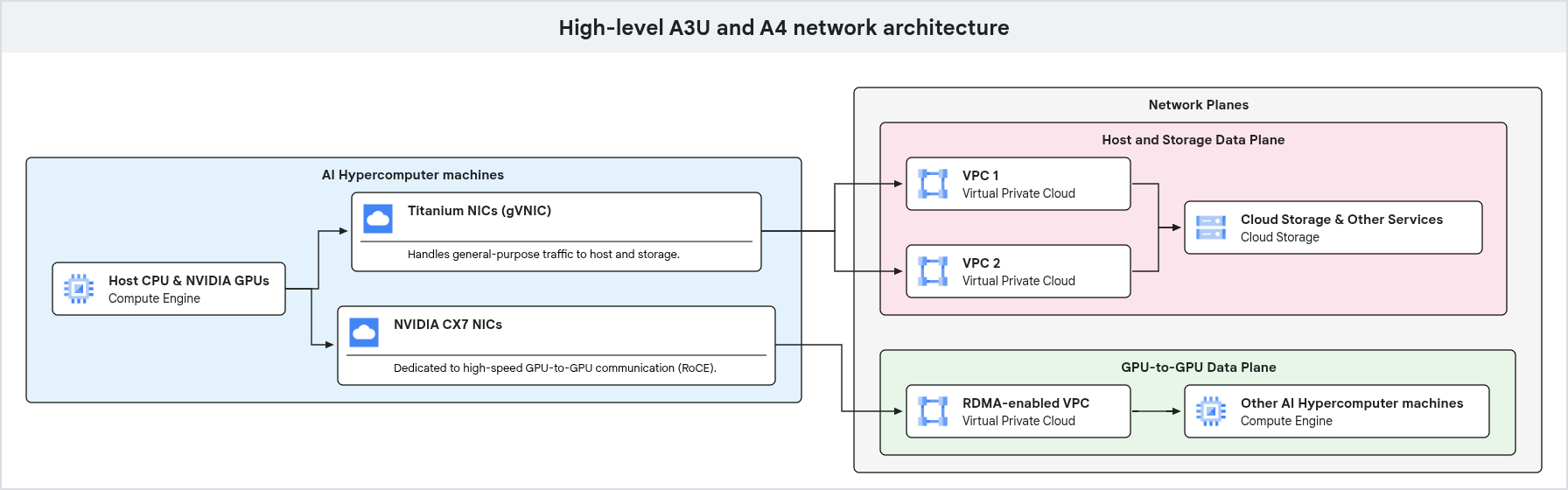
위 다이어그램에 표시된 대로 GPU 머신은 다양한 유형의 트래픽에 전용 네트워크 경로를 사용합니다. 관리 및 스토리지 액세스를 비롯한 범용 트래픽은 VPC에 연결된 Google Titanium NIC를 통해 흐릅니다. 고성능 GPU 간 통신은 별도의 네트워크 인터페이스와 VPC를 사용하며, RDMA와 같은 기술로 최적화되어 AI 및 ML 워크로드의 높은 대역폭과 짧은 지연 시간을 보장합니다.
네트워킹 라이브러리 및 구성요소
네트워크 대역폭과 성능을 극대화하기 위해 다음 네트워킹 라이브러리와 구성요소를 사용하면 Google의 네트워킹 스택으로 GPU를 사용할 수 있습니다.
- gVNIC: Google 가상 NIC (gVNIC)는 Compute Engine을 위해 특별히 설계된 가상 네트워크 인터페이스입니다. gVNIC는 성능을 향상하고 일관성을 높이며 노이즈가 심한 이웃 문제를 줄입니다. 모든 머신 계열, 머신 유형, 세대에서 지원되고 권장되며 호스트 간 통신에 권장되는 vNIC입니다. 자세한 내용은 Google 가상 NIC 사용을 참고하세요.
- NCCL: NVIDIA Collective Communications Library (NCCL)는 집합 통신 작업을 위한 최적화된 기본 요소를 제공합니다. NVIDIA GPU와 네트워킹을 사용하여 멀티 GPU 및 멀티 노드 환경을 위해 특별히 설계되었습니다. NCCL 테스트를 실행하여 배포된 클러스터의 성능을 평가합니다. 자세한 내용은 NCCCL 테스트 배포 및 실행을 참고하세요.
- GKE 멀티 네트워킹: 포드에 대한 멀티 네트워크 지원을 통해 GKE 클러스터의 노드와 포드에서 여러 인터페이스를 사용할 수 있습니다. GPUDirect 컨텍스트에서 멀티 네트워킹을 설정하는 방법에 관한 자세한 내용은 Standard 모드 클러스터에서 GPU 네트워크 대역폭 극대화 및 GPUDirect RDMA를 사용한 클러스터 구성 옵션을 참고하세요.
사용 가능한 소프트웨어 스택에 대한 자세한 내용은 OS 및 Docker 이미지를 참고하세요.
다음 단계
- 클러스터 및 VM 배포용 네트워크 서비스에 대해 알아봅니다.
- AI 하이퍼컴퓨터의 네트워킹 권장사항에 대해 알아봅니다.
- AI 하이퍼컴퓨터의 GPU 머신 유형 및 스토리지 서비스에 대해 알아봅니다.