
AI Hypercomputer è un sistema di supercomputing che ti aiuta a eseguire il deployment di workload di intelligenza artificiale (AI) e machine learning (ML) multi-host utilizzando macchine GPU. I servizi di rete sottostanti che utilizzi nel deployment sono determinati dal tipo di macchina GPU che scegli.
Questo documento è destinato ad aiutare architetti, ingegneri di rete e sviluppatori a comprendere i servizi di rete sottostanti correlati alle macchine GPU. Questo documento presuppone che tu abbia una conoscenza di base dei concetti di networking cloud e computing distribuito.
Comprendere i servizi di networking delle macchine GPU è il primo passo per eseguire il deployment e gestire correttamente i workload ed è essenziale per ottimizzare le prestazioni e il goodput. Il goodput, o throughput effettivo, misura i progressi effettivi di un sistema in un'attività di addestramento ML. Questa metrica offre ulteriori approfondimenti rispetto a metriche come il tempo totale trascorso o la velocità di throughput non elaborata.
Alcuni tipi di macchine GPU presentano una gerarchia a livelli distinta che ottimizza la comunicazione a ogni livello. Questa gerarchia va dalla struttura del data center ai cluster ottimizzati per l'AI e alle istanze Compute Engine. Le sezioni seguenti spiegano questi componenti gerarchici.
Architettura di rete GPU
AI Hypercomputer ti aiuta a eseguire il deployment di macchine GPU che utilizzano un'architettura di rete gerarchica e con allineamento ai rail . La connettività prevedibile e ad alte prestazioni di questa progettazione riduce al minimo l'overhead di comunicazione, il che migliora direttamente il goodput consentendo alle GPU di dedicare più tempo al calcolo anziché all'attesa dei dati.
La disposizione delle GPU con allineamento ai rail è costituita da tre componenti principali:
- Sub-blocchi: si tratta di unità fondamentali, costituite da un gruppo di host fisicamente collocate su un singolo rack. Uno switch top-of-rack (ToR) collega questi host, consentendo una comunicazione a hop singolo estremamente efficiente tra due GPU qualsiasi all'interno del sub-blocco. RDMA su Converged Ethernet (RoCE) facilita questa comunicazione diretta. Una libreria NCCL avanzata ottimizzata per la topologia con allineamento ai rail di Google gestisce i collettivi di comunicazione GPU.
- Blocchi: sono costituiti da più sub-blocchi interconnessi con una struttura non bloccante, che consente un'interconnessione a larghezza di banda elevata. Qualsiasi GPU all'interno di un blocco è raggiungibile in un massimo di due hop di rete. Il sistema espone i metadati di blocchi e sub-blocchi per consentire il posizionamento ottimale dei job.
- Cluster: sono formati da più blocchi interconnessi, che possono scalare a migliaia di GPU e consentono di eseguire workload di addestramento su larga scala. La comunicazione tra blocchi diversi aggiunge un solo hop aggiuntivo, mantenendo prestazioni e prevedibilità elevate anche su larga scala. Per consentire il posizionamento intelligente dei job su larga scala, i metadati a livello di cluster sono disponibili anche per gli orchestratori.
Tecnologie per la comunicazione da GPU a GPU
Le macchine GPU utilizzano una combinazione di tecnologie per fornire prestazioni elevate, throughput elevato e bassa latenza per i workload. Queste tecnologie includono RDMA su Converged Ethernet (RoCE), NIC NVIDIA e la topologia di rete con allineamento ai rail a livello di data center di Google.
Questi tipi di macchine utilizzano la tecnologia NVLink di NVIDIA per creare percorsi dati diretti ad altissima velocità tra le NIC NVIDIA su ogni macchina. Inoltre, RoCE consente un RDMA efficiente tra le GPU su macchine diverse.
Stack di networking GPU
Uno stack di networking è una raccolta di protocolli software, driver e livelli che funzionano insieme per implementare la comunicazione da GPU a GPU. Tipi di macchine GPU diversi utilizzano stack di networking diversi. La tabella seguente definisce gli stack di networking e i tipi di macchine associati:
| Stack di networking | Descrizione | Tipo di macchina GPU |
|---|---|---|
| GPUDirect RDMA | GPUDirect RDMA consente un percorso diretto per lo scambio di dati tra una GPU e un altro dispositivo. Per le istanze A4X Max e A4X, questo stack di networking utilizza RDMA su Converged Ethernet (RoCE). Questa tecnologia consente ai dispositivi peer di leggere e scrivere direttamente nella memoria della GPU, bypassando la CPU per creare una connessione più efficiente per lo scambio di dati ad alte prestazioni. Per ulteriori informazioni, consulta Opzioni di configurazione del cluster con GPUDirect RDMA. | |
| GPUDirect-TCPXO | GPUDirect-TCPXO migliora GPUDirect-TCPX eseguendo l'offload del protocollo TCP. Utilizzando GPUDirect-TCPXO, il tipo di macchina A3 Mega raddoppia la larghezza di banda della rete rispetto ai tipi di macchine A3 High e A3 Edge types. Per informazioni su come massimizzare la larghezza di banda della rete sui cluster GKE che utilizzano GPUDirect-TCPXO, consulta Massimizzare la larghezza di banda della rete GPU nei cluster in modalità Standard e seleziona la scheda GPUDirect-TCPXO. | |
| GPUDirect-TCPX | GPUDirect-TCPX aumenta le prestazioni della rete consentendo il trasferimento dei payload dei pacchetti di dati direttamente dalla memoria della GPU all'interfaccia di rete. Per informazioni su come massimizzare la larghezza di banda della rete sui cluster GKE che utilizzano GPUDirect-TCPX, consulta Massimizzare la larghezza di banda della rete GPU nei cluster in modalità Standard e seleziona la scheda GPUDirect-TCPX. |
Rete del piano dati host e di archiviazione
Un percorso di rete separato gestisce tutto il traffico che non è comunicazione diretta da GPU a GPU. Questo traffico include l'accesso a Cloud Storage, la gestione a livello di host e la comunicazione con altri Google Cloud servizi. Per gestire questo traffico, i tipi di macchine GPU utilizzano NIC Google Titanium.
Le NIC Titanium eseguono l'offload delle attività di elaborazione di rete dalla CPU, liberandola per concentrarsi sui workload. Questa separazione garantisce che il traffico per uso generico e il traffico dedicato da GPU a GPU utilizzino interfacce fisiche diverse, impedendo loro di competere per le stesse risorse di sistema.
Ambiente multi-VPC
Tutti i workload operano all'interno di Google Cloud's Virtual Private Cloud (VPC).
Le macchine con acceleratore ad alte prestazioni sono dotate di una progettazione hardware specializzata che utilizza più interfacce di rete fisiche per gestire diversi tipi di traffico. Per gestire questa progettazione hardware specializzata, è necessario un ambiente multi-VPC, indipendentemente dal fatto che tu utilizzi Slurm, GKE o Compute Engine per eseguire i workload.
La configurazione multi-VPC specifica dipende dal tipo di macchina GPU e dal relativo stack di networking:
A4X Max, A4X, A4 e A3 Ultra con GPUDirect RDMA: queste macchine sono supportate da due NIC fisiche: una che supporta il traffico per uso generico e una che supporta il traffico RDMA. Le vNIC dell'istanza che eseguono il mapping alla NIC fisica per uso generico (l'interfaccia
nic0e un'interfaccia di rete aggiuntiva) sono collegate alle reti VPC regolari. Le vNIC RDMA che eseguono il mapping alla NIC fisica compatibile con RDMA sono collegate a una rete VPC separata con un profilo di rete RDMA per sfruttare GPUDirect RDMA. In totale, questi tipi di macchine richiedono tre reti VPC. Per scoprire come configurare questa infrastruttura di rete, consulta Creare VPC e subnet.A3 Mega con GPUDirect-TCPXO: queste macchine richiedono otto VPC separati per le NIC GPU, che sono dedicate alla comunicazione a larghezza di banda elevata. Per la procedura dettagliata su come completare questa configurazione, consulta Creare VPC e subnet.
A3 High con GPUDirect-TCPX: queste macchine richiedono quattro VPC separati per le NIC GPU, che sono dedicate alla comunicazione a larghezza di banda elevata. Per la procedura dettagliata su come completare questa configurazione, consulta Creare VPC e subnet.
Questa configurazione multi-VPC contribuisce a garantire che le operazioni di archiviazione e altre attività di sistema non competano per la larghezza di banda con le comunicazioni critiche da GPU a GPU.
La configurazione di rete multi-VPC richiesta che devi configurare varia in base al tipo di macchina GPU. Per una guida dettagliata sulla disposizione della rete, sulle velocità della larghezza di banda e sulle NIC per tutti i tipi di macchine GPU supportati, consulta Networking e macchine GPU.
Il seguente diagramma mostra l'architettura di rete per una macchina GPU, evidenziando la separazione del traffico per uso generico e del traffico dedicato da GPU a GPU su piani di rete diversi.
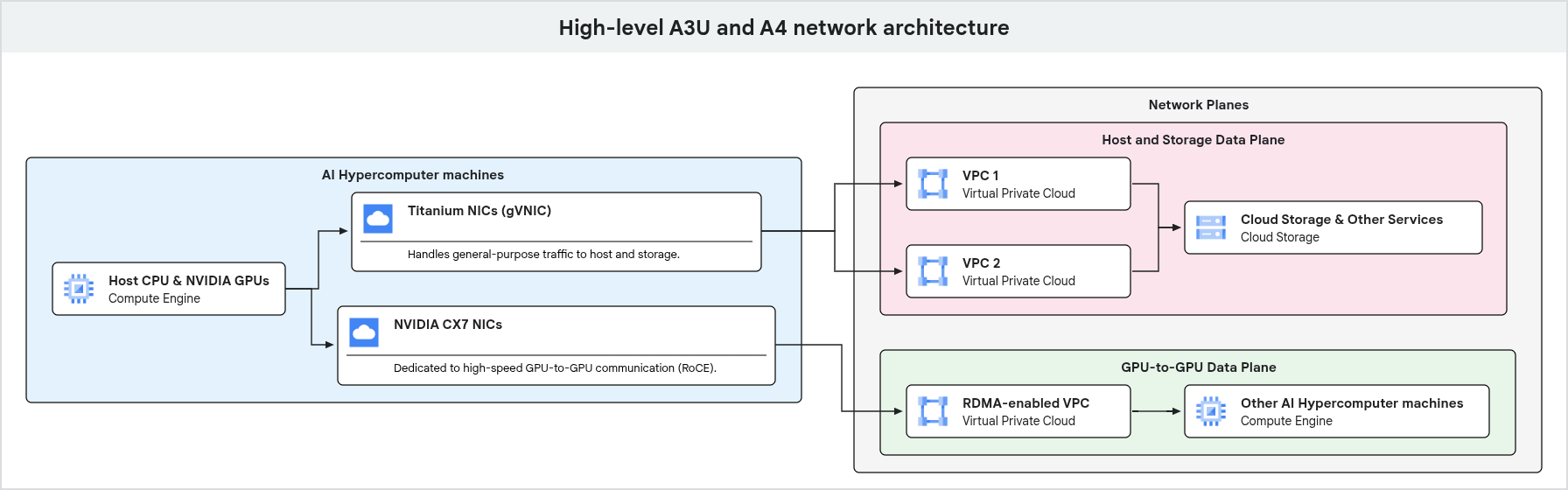
Come mostrato nel diagramma precedente, le macchine GPU utilizzano percorsi di rete dedicati per diversi tipi di traffico. Il traffico per uso generico, inclusi l'accesso alla gestione e all'archiviazione, passa attraverso le NIC Google Titanium collegate a un VPC. La comunicazione da GPU a GPU ad alte prestazioni utilizza interfacce di rete e VPC separati, ottimizzati con tecnologie come RDMA, garantendo larghezza di banda elevata e bassa latenza per i workload di AI e ML.
Librerie e componenti di networking
Per massimizzare la larghezza di banda e le prestazioni della rete, le seguenti librerie e componenti di networking consentono di utilizzare le GPU con lo stack di networking di Google:
- gVNIC: Google Virtual NIC (gVNIC) è un'interfaccia di rete virtuale progettata specificamente per Compute Engine. gVNIC migliora le prestazioni, aumenta la coerenza e riduce i problemi di vicini rumorosi. È supportata e consigliata su tutte le famiglie, i tipi e le generazioni di macchine ed è la vNIC consigliata per la comunicazione host-host. Per ulteriori informazioni, vedi Utilizzo di Google Virtual NIC.
- NCCL: la NVIDIA Collective Communications Library (NCCL) fornisce primitive ottimizzate per le operazioni di comunicazione collettiva. È progettata specificamente per ambienti multi-GPU e multi-nodo, utilizzando GPU e networking NVIDIA. Esegui i test NCCL per valutare le prestazioni dei cluster di cui è stato eseguito il deployment. Per ulteriori informazioni, consulta Testare le prestazioni di rete.
- Multi-networking GKE: il supporto di più reti per i pod consente di utilizzare più interfacce su nodi e pod in un cluster GKE. Per informazioni dettagliate su come configurare il multi-networking nel contesto di GPUDirect, consulta Massimizzare la larghezza di banda della rete GPU nei cluster in modalità Standard e Opzioni di configurazione del cluster con GPUDirect RDMA.
Per ulteriori dettagli sugli stack software disponibili, consulta Immagini del sistema operativo e Docker.
Passaggi successivi
- Scopri di più sui servizi di rete per i deployment di cluster e VM .
- Scopri di più sulle best practice per il networking in AI Hypercomputer.
- Scopri di più sui tipi di macchine GPU e sui servizi di archiviazione per AI Hypercomputer.