
AI Hypercomputer es un sistema de supercomputación que te ayuda a implementar cargas de trabajo de Inteligencia Artificial (IA) y aprendizaje automático (AA) de varios hosts con máquinas con GPU. Los servicios de red subyacentes que usas en la implementación se determinan según el tipo de máquina de GPU que elijas.
Este documento tiene como objetivo ayudar a los arquitectos, ingenieros de redes y desarrolladores a comprender los servicios de red subyacentes relacionados con las máquinas con GPU. En este documento, se supone que tienes conocimientos básicos de redes en la nube y conceptos de procesamiento distribuido.
Comprender los servicios de redes de máquinas de GPU es el primer paso para implementar y administrar tus cargas de trabajo de manera exitosa, y es fundamental para optimizar el rendimiento y el rendimiento útil. El procesamiento útil mide el progreso eficaz que realiza un sistema en una tarea de entrenamiento de AA. Esta métrica ofrece estadísticas adicionales en comparación con otras métricas, como el tiempo total transcurrido o la tasa de procesamiento sin procesar.
Algunos tipos de máquinas con GPU presentan una jerarquía estratificada distinta que optimiza la comunicación en todos los niveles. Esta jerarquía abarca desde la estructura del centro de datos hasta los clústeres optimizados para IA y las instancias de Compute Engine. En las siguientes secciones, se explican estos componentes jerárquicos.
Arquitectura de red de GPU
AI Hypercomputer te ayuda a implementar máquinas con GPU que usan una arquitectura de red jerárquica y encarrilada. La conectividad predecible y de alto rendimiento de este diseño minimiza la sobrecarga de comunicación, lo que mejora directamente el procesamiento útil, ya que permite que las GPUs dediquen más tiempo al procesamiento en lugar de esperar los datos.
La disposición de las GPUs encarriladas consta de tres componentes principales:
- Subbloques: Son unidades fundamentales que se componen de un grupo de hosts ubicados físicamente en un solo rack. Un conmutador en la parte superior del rack (ToR) conecta estos hosts, lo que permite una comunicación de un solo salto extremadamente eficiente entre dos GPUs dentro del subbloque. El RDMA sobre Ethernet convergente (RoCE) facilita esta comunicación directa. Una biblioteca de NCCL mejorada y optimizada para la topología encarrilada de Google controla las comunicaciones colectivas de la GPU.
- Bloques: Están compuestos por múltiples subbloques interconectados con una estructura que no bloquea, lo que permite una interconexión de alto ancho de banda. Cualquier GPU dentro de un bloque es alcanzable en un máximo de dos saltos de red. El sistema expone los metadatos de los bloques y subbloques para permitir la ubicación óptima de los trabajos.
- Clústeres: Se forman con varios bloques interconectados, que pueden escalar a miles de GPUs y te permiten ejecutar cargas de trabajo de entrenamiento a gran escala. La comunicación entre diferentes bloques agrega solo un salto adicional, lo que mantiene el alto rendimiento y la predicción incluso a una escala masiva. Para habilitar la colocación inteligente de trabajos a gran escala, los orquestadores también tienen disponibles metadatos a nivel del clúster.
Tecnologías para la comunicación de GPU a GPU
Las máquinas con GPU usan una combinación de tecnologías para proporcionar alto rendimiento, alta capacidad de procesamiento y baja latencia para las cargas de trabajo. Estas tecnologías incluyen RDMA sobre Ethernet convergente (RoCE), las NIC de NVIDIA y la topología de red encarrilada a nivel de centro de datos de Google.
Estos tipos de máquinas usan la tecnología NVLink de NVIDIA para crear rutas de datos directas de ultraalta velocidad entre las NIC de NVIDIA en cada máquina. Además, RoCE permite una comunicación eficiente entre GPU en diferentes máquinas.
Pilas de red de GPU
Una pila de red es un conjunto de protocolos de software, controladores y capas que trabajan en conjunto para implementar la comunicación de GPU a GPU. Los diferentes tipos de máquinas con GPU usan diferentes pilas de redes. En la siguiente tabla, se definen las pilas de redes y sus tipos de máquinas asociados:
| Pila de redes | Descripción | Tipo de máquina de GPU |
|---|---|---|
| RDMA de GPUDirect | El RDMA de GPUDirect habilita una ruta directa para el intercambio de datos entre una GPU y otro dispositivo. En el caso de las instancias A4X Max y A4X, esta pila de redes usa RDMA sobre Ethernet convergente (RoCE). Esta tecnología permite que los dispositivos pares lean y escriban directamente en la memoria de la GPU, sin pasar por la CPU, para crear una conexión más eficiente para el intercambio de datos de alto rendimiento. Para obtener más información, consulta Opciones de configuración del clúster con GPUDirect RDMA. | |
| GPUDirect-TCPXO | GPUDirect-TCPXO mejora GPUDirect-TCPX descargando el protocolo TCP. Con GPUDirect-TCPXO, el tipo de máquina A3 Mega duplica el ancho de banda de la red en comparación con los tipos de máquina A3 High y A3 Edge. Para obtener información sobre cómo maximizar el ancho de banda de la red en clústeres de GKE que usan GPUDirect-TCPXO, consulta Maximiza el ancho de banda de red de la GPU en clústeres en modo estándar y selecciona la pestaña GPUDirect-TCPXO. | |
| GPUDirect-TCPX | GPUDirect-TCPX aumenta el rendimiento de la red, ya que permite que las cargas útiles de los paquetes de datos se transfieran directamente de la memoria de GPU a la interfaz de red. Para obtener información sobre cómo maximizar el ancho de banda de la red en clústeres de GKE que usan GPUDirect-TCPX, consulta Maximiza el ancho de banda de red de la GPU en clústeres en modo estándar y selecciona la pestaña GPUDirect-TCPX. |
Red del plano de datos de host y almacenamiento
Es una ruta de red independiente que controla todo el tráfico que no es comunicación directa de GPU a GPU. Este tráfico incluye el acceso a Cloud Storage, la administración a nivel del host y la comunicación con otros Google Cloud servicios. Para administrar este tráfico, los tipos de máquinas con GPU usan NICs Google Titanium.
Las NIC de Titanium transfieren las tareas de procesamiento de red de la CPU, lo que la libera para que se concentre en tus cargas de trabajo. Esta separación garantiza que el tráfico de uso general y el tráfico dedicado de GPU a GPU usen diferentes interfaces físicas, lo que evita que compitan por los mismos recursos del sistema.
Entorno de múltiples VPC
Todas las cargas de trabajo operan dentro de la nube privada virtual (VPC) de Google Cloud.
Las máquinas de aceleradores de alto rendimiento cuentan con un diseño de hardware especializado que usa varias interfaces de red físicas para controlar diferentes tipos de tráfico. Para administrar este diseño de hardware especializado, se requiere un entorno de múltiples VPC, independientemente de si usas Slurm, GKE o Compute Engine para ejecutar tus cargas de trabajo.
La configuración específica de varias VPC depende del tipo de máquina de GPU y de su pila de redes:
A4X Max, A4X, A4 y A3 Ultra con GPUDirect RDMA: Estas máquinas están respaldadas por dos NIC físicas: una que admite tráfico de uso general y otra que admite tráfico de RDMA. Las vNIC de la instancia que se asignan a la NIC física de uso general (la interfaz
nic0y una interfaz de red adicional) se adjuntan a las redes de VPC normales. Las vNIC de RDMA que se asignan a la NIC física compatible con RDMA se conectan a una red de VPC independiente con un perfil de red de RDMA para aprovechar el RDMA de GPUDirect. En total, estos tipos de máquinas requieren tres redes de VPC. Para obtener información sobre cómo configurar esta infraestructura de red, consulta Crea VPCs y subredes.A3 Mega con GPUDirect-TCPXO: Estas máquinas requieren ocho VPC independientes para las NIC de GPU, que se dedican a la comunicación de gran ancho de banda. Para obtener información detallada sobre cómo completar esta configuración, consulta Crea VPCs y subredes.
A3 High con GPUDirect-TCPX: Estas máquinas requieren cuatro VPC independientes para las NIC de GPU, que se dedican a la comunicación de gran ancho de banda. Para obtener información detallada sobre cómo completar esta configuración, consulta Crea VPCs y subredes.
Esta configuración de varias VPC ayuda a garantizar que las operaciones de almacenamiento y otras tareas del sistema no compitan por el ancho de banda con las comunicaciones críticas de GPU a GPU.
La configuración de red de múltiples VPC que debes establecer difiere según el tipo de máquina con GPU. Si deseas obtener una guía detallada sobre la disposición de la red, las velocidades de ancho de banda y las NIC para todos los tipos de máquinas de GPU compatibles, consulta Redes y máquinas de GPU.
En el siguiente diagrama, se muestra la arquitectura de red para una máquina con GPU, en la que se destaca la separación del tráfico de uso general y el tráfico dedicado de GPU a GPU en diferentes planos de red.
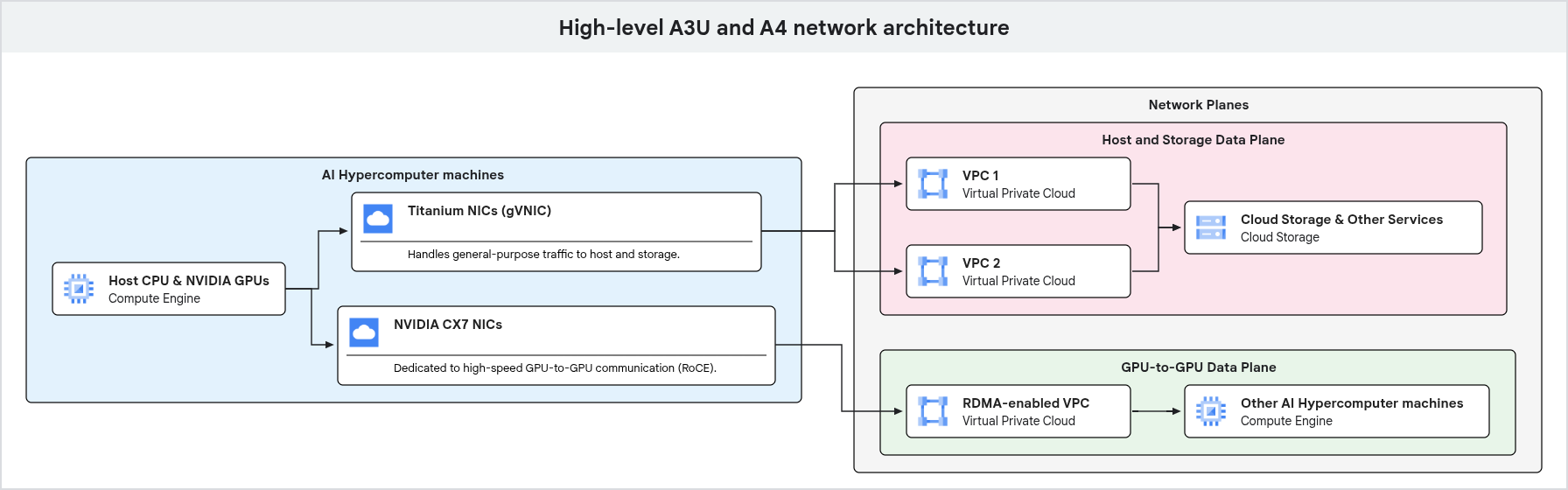
Como se muestra en el diagrama anterior, las máquinas con GPU usan rutas de red dedicadas para diferentes tipos de tráfico. El tráfico de uso general, incluido el acceso a la administración y al almacenamiento, fluye a través de las NIC de Google Titanium, que están conectadas a una VPC. La comunicación de alto rendimiento entre GPU usa interfaces de red y VPC independientes, optimizadas con tecnologías como RDMA, lo que garantiza un alto ancho de banda y una baja latencia para las cargas de trabajo de IA y AA.
Bibliotecas y componentes de red
Para maximizar el ancho de banda y el rendimiento de la red, las siguientes bibliotecas y componentes de redes te permiten usar GPUs con la pila de redes de Google:
- gVNIC: La NIC virtual de Google (gVNIC) es una interfaz de red virtual diseñada específicamente para Compute Engine. gVNIC mejora el rendimiento, aumenta la coherencia y reduce los problemas de vecinos ruidosos. Es compatible y se recomienda en todas las familias, tipos y generaciones de máquinas, y es la vNIC recomendada para la comunicación de host a host. Para obtener más información, consulta Usa la NIC virtual de Google.
- NCCL: La biblioteca de comunicaciones colectivas de NVIDIA (NCCL) proporciona primitivas optimizadas para las operaciones de comunicación colectiva. Está diseñado específicamente para entornos de varias GPUs y varios nodos, y utiliza GPUs y redes de NVIDIA. Ejecuta pruebas de NCCL para evaluar el rendimiento de los clústeres implementados. Para obtener más información, consulta Cómo probar el rendimiento de la red.
- Redes múltiples de GKE: La compatibilidad con varias redes para Pods permite varias interfaces en nodos y Pods en un clúster de GKE. Para obtener detalles sobre cómo configurar varias redes en el contexto de GPUDirect, consulta Maximiza el ancho de banda de red de la GPU en clústeres en modo estándar y Opciones de configuración del clúster con RDMA de GPUDirect.
Para obtener más detalles sobre las pilas de software disponibles, consulta Imágenes de SO y Docker.
¿Qué sigue?
- Obtén más información sobre los servicios de red para implementaciones de clústeres y VMs.
- Obtén más información sobre las prácticas recomendadas para las redes en AI Hypercomputer.
- Obtén información sobre los tipos de máquinas con GPU y los servicios de almacenamiento para la IA Hypercomputer.